






随着技术不断发展,在元宇宙时代,AI 将从根本上改变 3D 数字资产的生产方式。在第四届中国计算机教育大会上,Unity 中国高级技术经理兼跨端移植技术负责人孙志鹏先生分享了 AIGC 如何赋能元宇宙时代 3D 内容创作。

非常荣幸今天能够和大家分享我们在 AIGC 方面的思考和观察。我的演讲主题是《 AIGC 赋能元宇宙时代 3D 内容创作》。
我们将从以下几个方面讨论这个问题。第一,AIGC 领域的关键技术;第二,自动化的生产流程;第三,讨论 AIGC 和传统生产流程应该会有一种融合方式,像微软的 copilot,让我们更好地使用工具;最后会简单讨论引擎在这个过程中发挥的作用。
现在 AIGC 关键技术有几个点值得和大家分享:
第一是通用人工智能大模型。大模型最开始是大语言模型,现在大语言模型已经走向多模态了。一个足够大的模型,它具备像 scaling law、涌现能力、推理能力等,是不是通往通用人工智能的道路?现在我们似乎看到了一些曙光。
第二是人机交互接口,会讨论人类使用工具过去是什么样子,现在会演变成什么样子。随后我们会一起回顾多模态的发展历程,多模态要到 3D 领域其实涉及很多模态,除了模型之外,还有动画、特效、灯光等等,这些模态未来要怎样让 AI 理解并生产?多模态的主要发展历程可能会给我们一些启发。
最后,所有 AI 的技术和发展,数据都在其中扮演至关重要的角色。大模型先从语言的模态开始,是因为数据多;多模态先讨论图和文,也是因为搜索引擎直接可以用文字搜到图。数据是一个关键,3D 的数据是很贵的,促使 AI 在模态领域的发展要解决数据拟合的问题。

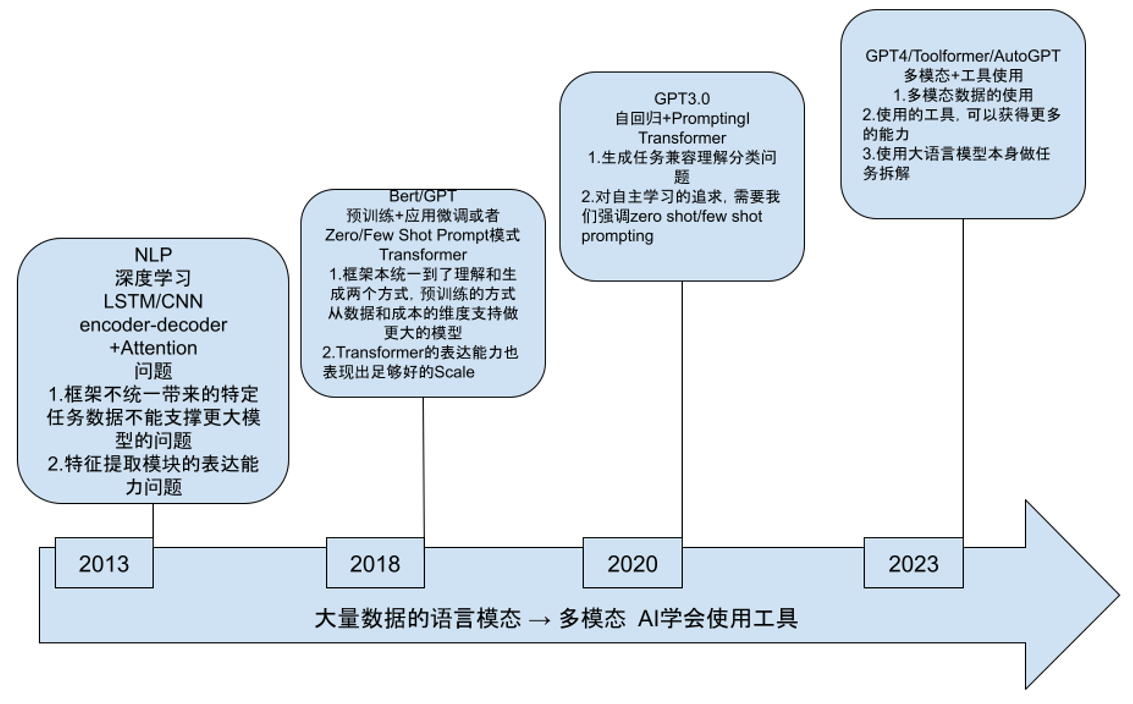
先来看通用人工智能的发展历程,我把它定义成四个比较关键的阶段。
第一阶段是从深度学习进入 NLP 这个领域开始,在自然语言领域开始用 LSTM (Long Short-Term Memory) 结构存储信息,用 CNN 这种特征提取的编码器解码器来提取特征,也有注意力机制。这个时期整个 NLP 领域还有很多下游任务,很多子问题要去解决,我们用不同的结构去解决不同的子问题,用不同的数据集去训练不同的结构。这个时期框架不统一,像 CNN 这种特征提取模块的表达能力有问题,模型做不了很大,有太多下游任务,数据集也很难归集到一起。
到 2018 年,从 BERT/GPT 开始,这个框架基本上统一到了两种任务,一个是生成的任务,一个是理解的任务。也因为 Transformer 结构引入到 NLP 领域,作为一个特征提取器比 CNN 的提取和表达能力都强了很多。这个时候大量的下游任务被整合了,数据和研究的人也就被整合了,统一到 Transformer 结构上面又有了更好的表达,所以模型开始越来越大了。
再到 GPT3.0 发布的时候,自回归模型统一了,所有上千亿级参数的大模型基本都是 GPT 的方式。也是因为下游任务的统一,我们用生成的任务统一理解的任务(用生成对这个描述的理解的方式解决理解的任务),所有的 NLP 任务基本上都可以用 GPT 这样的自回归模型解决。模型做大之后,就会想要解决 Zero Shot 或 Few Shot 的问题,即提高 AI 模型对没见过的问题的处理能力。这种自回归模型就比 BERT 这种双向表示的模型好很多。
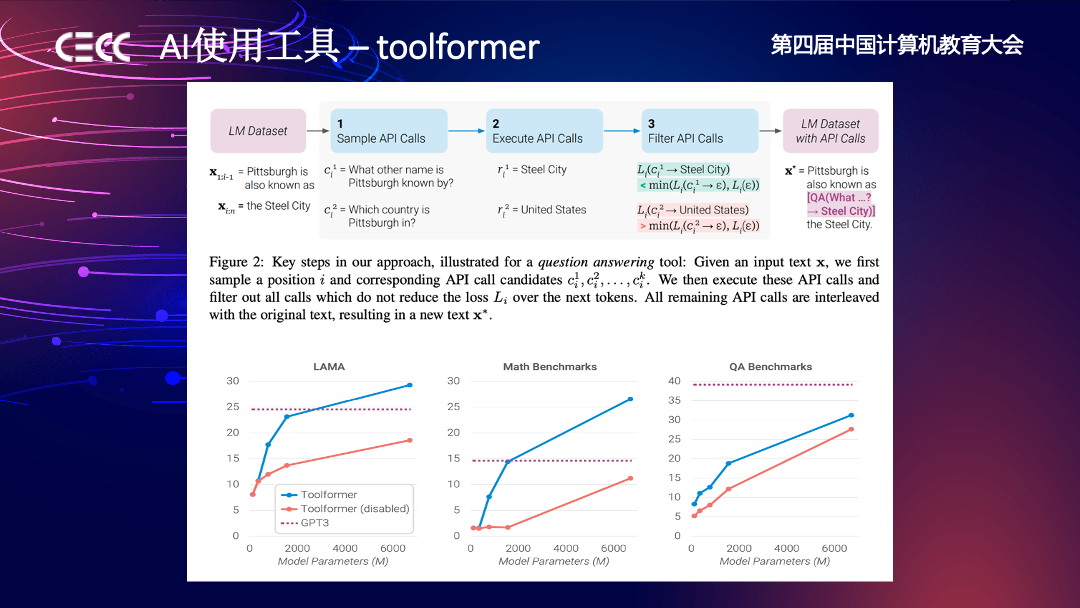
到今年 AIGC 爆发,可以理解成以 GPT4 的发布为标志,让我们知道了大模型以后一定是往多模态发展。 Toolformer 这篇论文主要讲的是如何让 AI 学会使用工具,像 ChatGPT Plugin,Copilot 等这些想法都是基于这篇论文的发展。首先我们可以让模型更大,从更多模态的数据提取知识,然后让它通过 Toolformer 这样的 pattern 控制传统工具或其他 AI 模型来工作。另外还有 AutoGPT,它解决的问题是让大语言模型来拆解任务。首先有一个足够大的模型存储很多知识,解决问题的时候调用传统生产流程的工具;当遇到复杂的问题时,可以用大语言模型拆解任务,从而指挥语言模型一步一步调用工具完成。
从整个发展历程可以看到,也许这就是通往通用人工智能的路径。
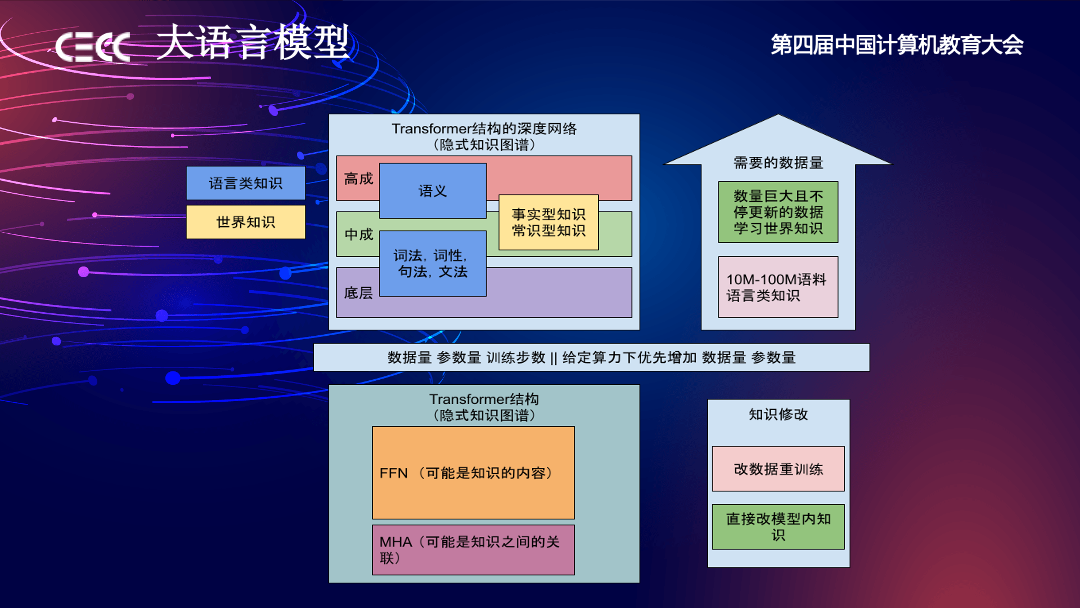
大语言模型里面就是一个 Transformer 结构。在一个生成的 Transformer 网络里面,一般存在着词法、文法、语义、事实、常识类的知识,分布在底层、中层、高层。
也有研究表明,训练 GPT 学会语言类知识需要的语料是有限的,但要让它不断掌握事实类、常识类的知识所需数据量是非常大的,而且需要不断更新数据。比如 GPT3.0 只能掌握到训练结束之前的知识,再往后需要不断移植给它更多的知识。
在大模型这个领域,如何有效把模型做大?大模型的性能有三个比较重要的参数——数据量、参数量和训练步数。它们也有优先级,数据量是第一位的,参数量是第二位的。
如果单纯看一个 Transformer 结构,可以归结为两种东西,一个是多头自注意力机制(MHA),另一个是前馈神经网络(FFN)。FFN 中存取知识主体内容,多头自注意里面存着知识的关系。举个例子,“我们今天在厦门”这件事,“我们”和“厦门”就是知识,“在”就是关系,它们分别存在于不同的地方。知识本身是可以跨模态的,自注意力可以跨模态提取知识。也是说“我们在厦门”可以是文字,也可以是图片,自注意力都可以把知识提取出来,存在于结构里面成为“我们在厦门”这个事实。
也有一个非常重要的研究领域,即怎么改大模型里面的知识。大模型训练很贵,它的知识要实时更新,可能还包含从互联网上得到的需要勘误的信息,我们不能每次都 fine-tuning 预训练大模型。Fine-tuning 会让大模型的泛化能力降低,反复 Fine-tuning 可能大模型就什么都不会了。如何定位知识、修改知识也是目前大语言模型领域比较火热的研究。
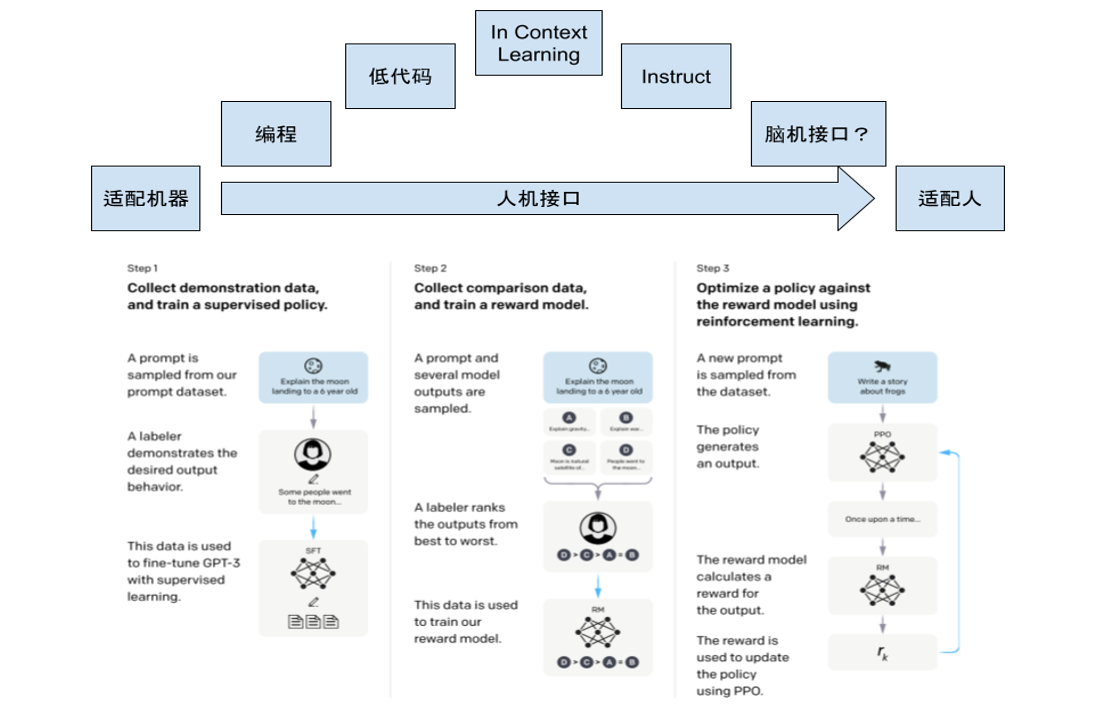
讲完了大模型的发展历程以及内部结构,我们来看一下人机交互接口。最近 ChatGPT 为什么比较火,我理解是它的人机交互接口做得比较好。它最早是源于 OpenAI InstructGPT 的论文,里面介绍了让大模型更好地和人交互的方法,通过三个步骤:第一,先让人标注数据,比如怎样提问、怎样回答,让专业的人写好提问与回答,但这种数据是很贵的。先用这种数据训练模型,让模型生成很多回答,再让人对这些回答进行 Rank。
第二,提供 Rank 之后,我们就对模型建立了奖励机制。Rank 的过程包含了人的 policy,人去衡量什么样的回答更贴心。第三,这种 Policy 就可以由强化模型训练出来,让强化学习模型更懂人希望怎样和大模型交互。所有这些从概念上来理解就是人机接口的发展过程。
最开始我们定义编程语言,定义各种低代码编辑器,都是从开发者或写工具的人的角度制定规则,人遵从规则才可以和工具交互,进而支配机器的算力。这个规则即使不断被定义得更好,不断降低使用门槛,也依然是人适应机器,人适应预先定义好的规则。
到 In Context Learning,我理解它是一个人和大模型交互的折中阶段。它的方式是人虽然很难和大语言模型直接交互,但是可以举例说明。先举几个问答例子让大模型学会,它就知道怎么更好地回答其他问题。
另外像 Instruct,先有大量非常好的例子,且训练了大量人的 policy,让 GPT 更懂你,就更知道怎么和人交流。
这个趋势可以看出,从人需要适配机器,到现在以 AI 为媒介,机器和工具需要适配人。甚至,自然语言真的是和机器打交道的终极状态吗?脑机接口是不是一个更终极的表达,也是一个值得思考的点。
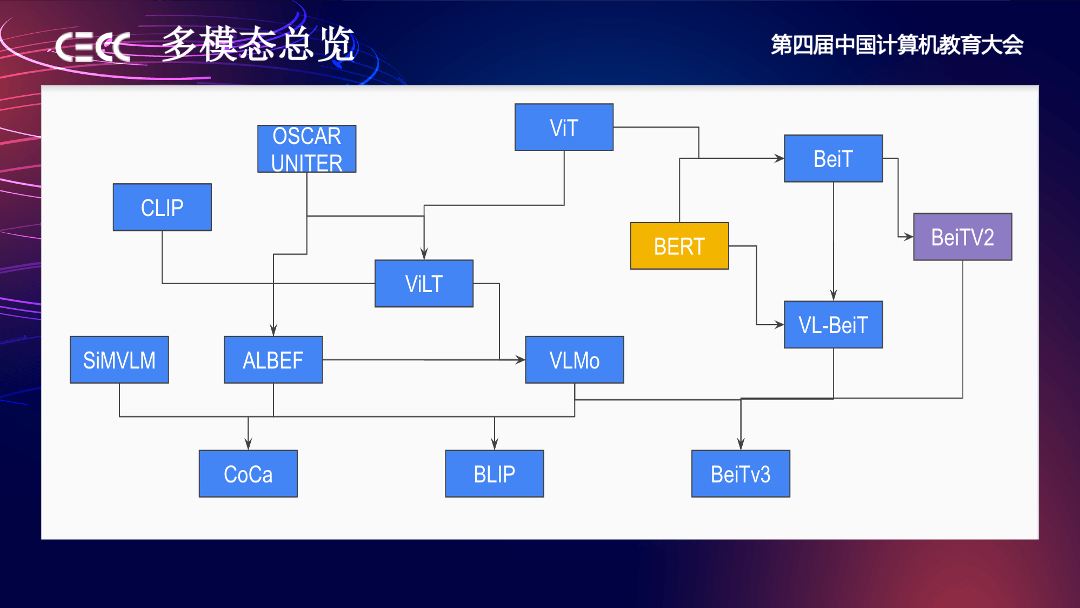
接下来回顾一下多模态的发展历程。我们作为 3D 工具方拥抱 AIGC,有必要回顾在图文模态的发展历程中到底经历了些什么。
我截取了多模态从 Transformer 进入计算机视觉——ViT 开始的发展。Transformer 进入计算机视觉领域做特征提取器,让我们更好地提取图的信息。从 ViT 开始,靠 class embedding 的方式提取特征。紧接着在 ViLT 强调多模态的融合。
另外有 CLIP 和 DALL·E 2,DALL·E 2 最早论文叫 unCLIP,本质上是 CLIP 的一个反向操作,用 CLIP 指导生成模型去生成图片。CLIP 是基于对比学习的,它知道很多图文特征的匹配,可以很好地作为监督信号指挥生成模块。CLIP 论文对多模态的贡献在于展示了对比学习的强大,当数据比较有限时,可以考虑用对比学习加速。
接下来一个关键点是,ALBEF 的这篇文章展现了做多模态、模态特征空间的 aline,模态融合非常重要。
紧接着,VLMo 这篇文章展示了知识的内容是可以跨模态的。BeiTv3 的这篇文章基于此用一个统一的框架处理多模态,比如虽然可能用不同的自注意力机制特征提取图像文本或者图像加文本数据,但都可以归结到一个 Transformer 网络层中存取知识。所以,多模态下游任务也进一步统一了,数据、研究人员都被归集起来,解决所有下游问题,模型进一步做大,能力做强。
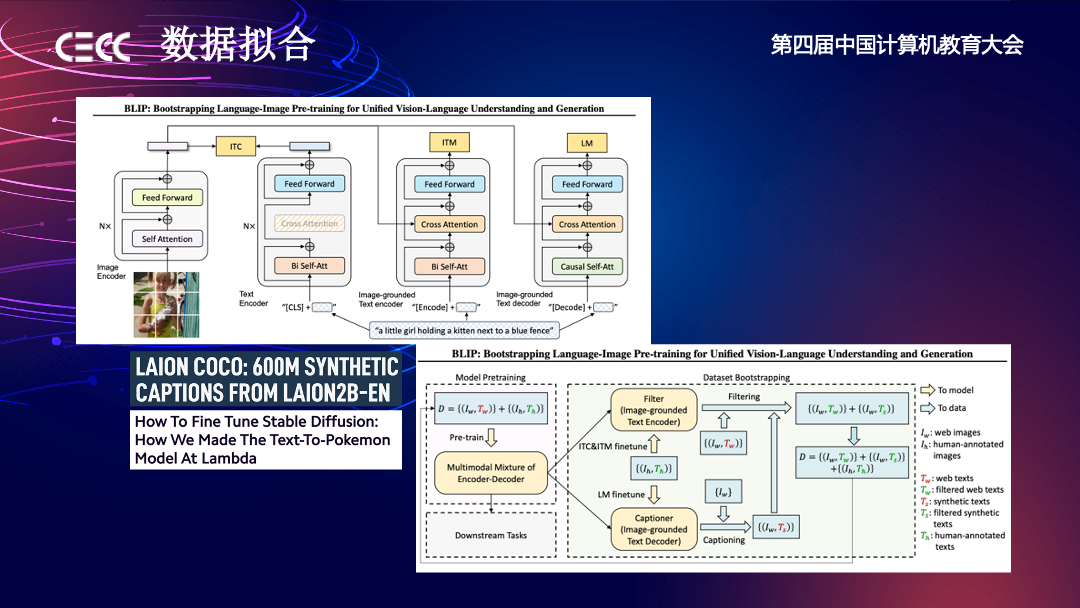
多模态的发展历程中有一篇 BLIP 的文章,带给我们一个非常重要的启示——数据拟合。BLIP 这篇文章是用网络上爬到的数据训练多模态模型,但网络上图文信息匹配度并不是很高,搜索引擎中可能有很多广告因素干扰,导致对图片内容的描述并不精确。
多模态想要解决的问题是用文字和图片这两个模态做映射,找到精确描述图片的文本对。因此为了解决网络数据的影响,BLIP 采用了这样一种方式,即先用网络数据训练,使多模态模型有一定能力对图片进行描述。再用生成并过滤后的更好的图片文本对训练模型,再对图片进行描述,这样反复自我优化数据。
下图展示的 COCO 这种数据公司以及博客文章也用这种方式 fine-tuning Stable Diffusion,生成更高质量的数据。这带给我们的启示是,3D 模态的数据很贵,但也许我们可以用类似的方式生成更多所需的 3D 数据。
我们来小结一下,人工智能模型会往多模态发展,随着模态的增加会有更多的数据,模型会变得更大,进而出现像 Scaling law、涌现、推理这些很好的特性。
人机交互接口的发展会使得专业工具的使用门槛越来越低,人机交互会接渐渐趋同于迎合人的使用习惯。这是一个非常好的趋势,比如对于 coding 的能力比较困难的使用者来说,未来并不需要所有人学会使用工具,而是工具会学会和人打交道。
另外,图文多模态的发展历程非常值得我们借鉴它其中的一些细节,用以解决其他模态的问题。
3D 模态的信息量比 2D 大很多,多模态扩展到 3D 会需要更多数据,所以低成本获得数据也是一个关键技术,数据拟合也是非常值得探索的一点。

传统生产流程一直也在探索高效生产数据的方式,自动化生产流程就是其中的一个代表,其中包含程序化、自动化和工具脚本等关键技术,这些都是要解决数字资产生产的效率问题。
首先来介绍程序化。程序化是一种语言,程序化的方式是要对数字资产提供一种表达层,自然语言也是一种表达层,它们都是知识的表达方式。

这里展示了 Unity 收购的 Speedtree,它就是一个程序化的代表。可以通过一些规则定义植物应该怎么生长,通过数据驱动这个规则以生产各种各样的植物。它是一个非常高效的方式,通过定义生产规则实现植物批量建模。
这里展示的 Unity Weta Totara 和 Lumberjack 也是沿用了这种程序化逻辑生产成片的森林或世界。
如果需要让 AI 学会使用工具,自动化在软件测试行业是有大量成熟的框架的,可以用工具之外的东西使用工具得到预期结果。
另外,工具脚本在开发工具生态里面也是非常成熟的体系,比如我们基本可以在 Unity 的 C# 脚本里面做完所有 Unity 功能暴露出来的事情。假如工具脚本也是一种语言,AI 应该可以生成所有表达,控制工具干所有事情。
总结一下自动化生产流程的关键技术部分,我们应该看到程序化、自动化、工具脚本等领域成熟的现有流程对自动化生产的影响。与这些技术的现有流程结合会大大降低跨越模态的难度,也会让我们在成本可控的范围内获得大量高质量数据成为可能。

关于 AI 和传统内容生产流程的融合方式,现在有两个比较主要的观察,一个是 AI 使用工具,另一个是 AI 原生工具。
让 AI 使用工具,刚才提到的 Toolformer 这篇论文我认为是这一领域的开山之作,从这里开始讨论怎样教会大语言模型使用工具。
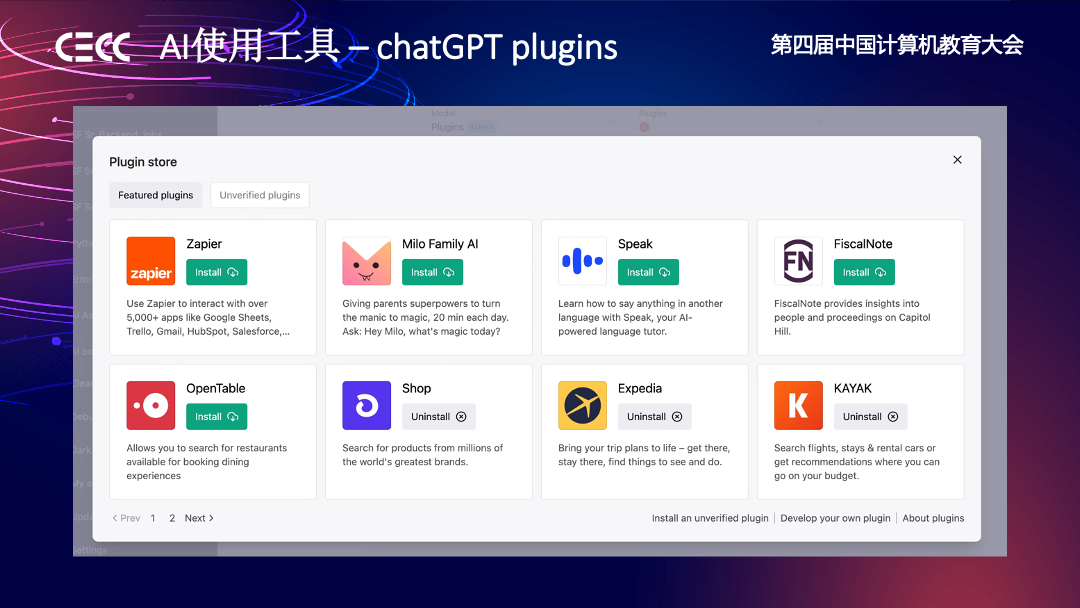
紧接着,如 ChatGPT Plugin 是让 ChatGPT 使用浏览器等各种各样的工具。
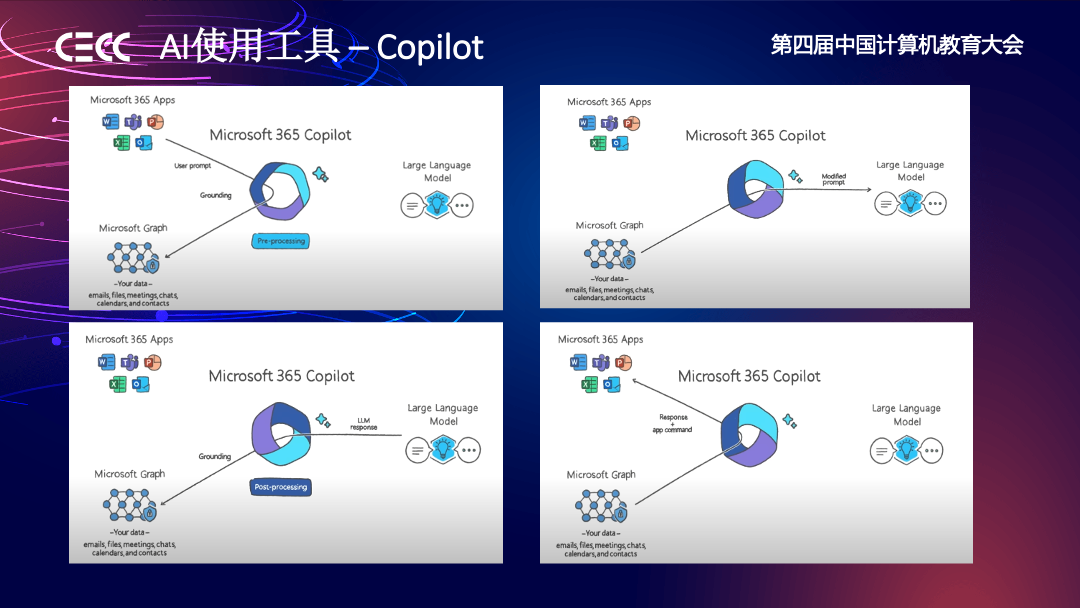
另一个例子是微软的 Copilot,它的广告里面有一句非常好的话:一个人使用 Office 可能只使用了它 10%、20% 的功能,但 Copilot 可以帮助我们使用这个工具功能的 70%-80%。普通用户使用工具是有门槛的,但引入 AI 作为人机交互层后,普通用户和专家的差距就没有那么大了。
另外一部分是 AI 原生工具,如 Stable Diffusion、DALL·E 2 以及最近重新被大家关注的 GAN 生成模型。它们也是一种工具,甚至没有传统的人机交互界面,用户直接和 AI 交互生产数字资产。

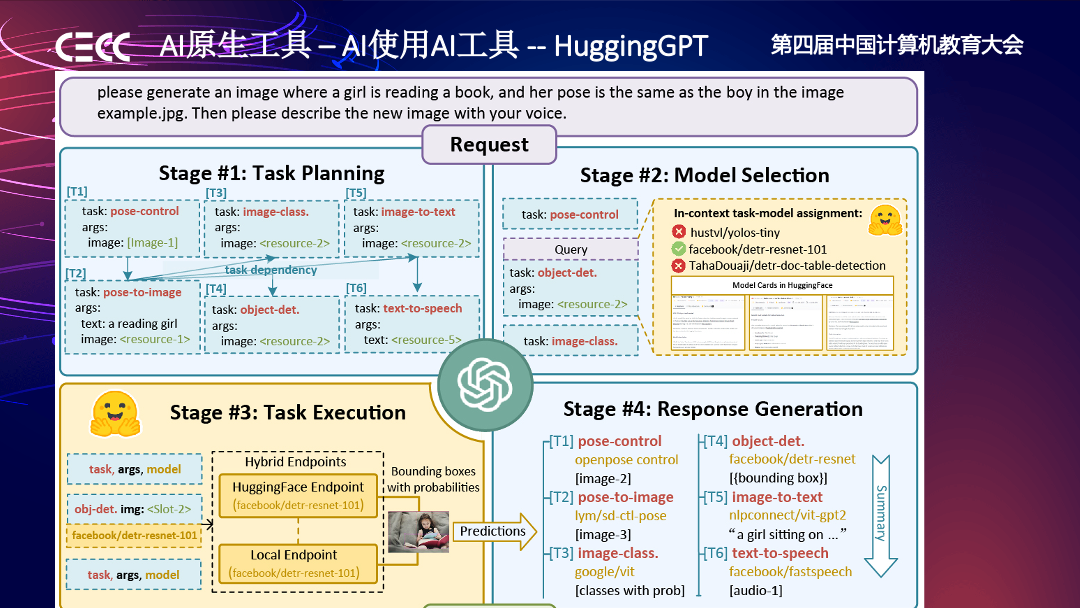
AI 原生工具最近也有一个更进一步的尝试,就像 Hugging Face 这个网站提供的 HuggingGPT。这个网站上面有大量的预训练模型,可以理解为现成的 AI 工具,用户可以用一个 GPT 模型指挥这些现成的 AI 工具做事情。也就是说,AI 工具不但可以指挥传统工具,也可以指挥其他 AI 工具。

最后讲一下引擎在 AIGC 3D 内容创作中的作用。
引擎应该是一个功能组织更完善的面向工作流的自动化工具集,集成自动化生产的工具;是一个高质量数据的制造机,帮我们跨越模态;是一个低成本的虚拟仿真环境的集成平台,让我们去验证算法;同时也是交互式体验内容的环境,接收用户的多模态数据反馈。
就像最近 OpenAI 的 CEO 在 TED Talk 上的演讲所说,传统界面在整个 AIGC 发展中也是非常重要的。我们可能会像 supervisor 一样指挥 AI 干活,但还是需要对结果进行检视或者微调,这个过程依然需要传统人机交互界面。引擎在为用户提供检视微调环境的同时,也能收集到更多反馈数据反哺 AI,使之更精确地执行指令。

总结来说,在通往通用人工智能大模型的道路上,多模态看起来是一个必经之路。AI 会进一步降低创作中专业技能的门槛。现成工具的能力生态和 AIGC 相关技术发展是相辅相成的,它们相辅以能力,相成以数据。无论是让 AI 用工具,还是 AI 原生工具,它们都会不断融合,在各种生产环节中展现或显式或隐式的最优解——显式的就是人定义的工具使用,隐式的是 AI 从数据里面训练出来的。所有的这些,提升生产效率是唯一衡量的标准。

今天的分享结束了,谢谢大家。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









