







第二章 联邦学习的安全机制
2.1 基于同态加密
同态加密(HE)最早由Rivest等人在1978年提出,是一种允许对密文进行计算生成加密结果的技术。(结果解密后和明文计算结果一样)
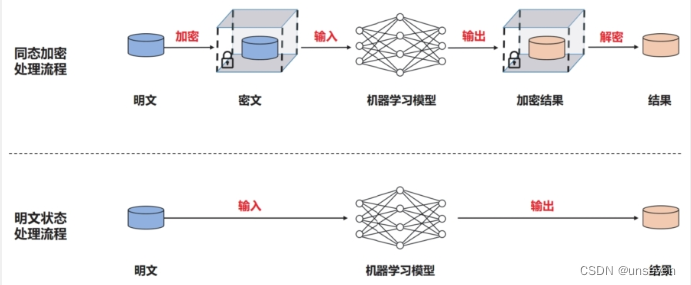
同态加密能在不对密文进行解密的情况下进行计算,不需要了解明文,很好地保护了隐私。
2.1.1 定义
一个同态加密方案H由一个四元组组成:
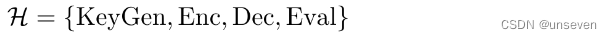
- KeyGen表示密钥生成函数。对于非对称同态加密,一个密钥生成元g被输入KeyGen,并输出一个密钥对{pk,sk}=KeyGen(g),),其中pk表示用于对明文进行加密的公钥(public key),sk表示用于对密文进行解密的私钥(secret key)。对于对称同态加密,只生成一个密钥sk=KeyGen(g),用于加密和解密操作。
- Enc表示加密函数。对于非对称同态加密,一个加密函数以公钥pk和明文m作为输入,并产生一个密文 c = E n c p k ( m ) c=Enc_{pk}(m) c=Encpk(m)作为输出。对于对称同态加密,加密过程会使用公共密钥sk和明文m作为输入,并生成密文 c = E n c s k ( m ) c=Enc_{sk}(m) c=Encsk(m)
- Dec表示解密函数。对于非对称和对称同态加密,私钥sk和密文c被用来作为计算相关明文 m = D e c s k ( c ) m=Dec_{sk}(c) m=Decsk(c)的输入。
- Eval表示评估函数。评估函数Eval将密文c和公共密钥pk(对于非对称同态加密)作为输入,并输出与明文对应的密文,用于验证加密算法的正确性。
同态安全密码系统满足以下条件:
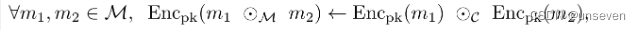
其中,
⊙
M
和
⊙
C
\odot _{M}和\odot _{C}
⊙M和⊙C分别表示操作符
⊙
\odot
⊙在明文空间M和密文空间C上的运算。对于在明文空间M中中的任意两个元素
m
1
m_1
m1和
m
2
m_2
m2,在对于它们执行运算符
⊙
\odot
⊙操作后,对得到的结果进行加密,其结果与
m
1
m_1
m1和
m
2
m_2
m2分别进行加密再执行运算符
⊙
C
\odot _{C}
⊙C操作的结果一致;
←
\gets
←符号表示左边项等于或可以直接由右边项计算出来,而不需要任何中间解密运算。
即运算后加密和加密后再运算的结果保持一致。
用[[v]]表示对明文v的同态加密结果。我们来定义同态加密的两个基本操作,即加法同态加密和乘法同态加密。
对于在明文空间M中的任意两个元素u和v,其加密结果分别为[[u]]和[[v]],满足:
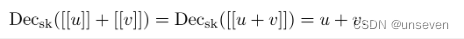
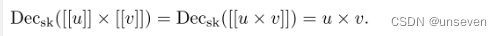
2.1.2 分类
同态加密算法分为三类:部分同态加密(Partially Homomorphic Encryp-tion,PHE),些许同态加密(Somewhat Homomorphic Encryption,SHE),全同态加密(Fully Homomorphic Encryption,FHE)。不同的同态加密方案的计算复杂度区别很大。
- 部分同态加密(PHE)
也称半同态加密,(M, ⊙ M \odot _{M} ⊙M)和(C, ⊙ C \odot _{C} ⊙C)都属于一个群,以(C, ⊙ C \odot _{C} ⊙C)为例,它满足四个特性:
- 封闭性:即对于任意的两个元素 c 1 , c 2 ∈ C c_1,c_2∈C c1,c2∈C以及操作符 ⊙ C \odot _{C} ⊙C,满足 ( c 1 ⊙ C c 2 ) ∈ C (c_1 \odot _{C} c_2)∈C (c1⊙Cc2)∈C
- 结合律对任意三个元素 c 1 , c 2 , c 3 ∈ C c_1,c_2,c_3∈C c1,c2,c3∈C以及操作符 ⊙ C \odot _{C} ⊙C,满足 ( c 1 ⊙ C c 2 ) ⊙ C c 3 ) = c 1 ⊙ C ( c 2 ⊙ C c 3 ) (c_1 \odot _{C} c_2) \odot _{C} c_3) = c_1 \odot _{C} (c_2 \odot _{C} c_3) (c1⊙Cc2)⊙Cc3)=c1⊙C(c2⊙Cc3)
- 单位元:存在C中的一个元素e,使得对于所有C中的元素a,总有等式 ( e ⊙ C a ) = ( a ⊙ C e ) = a (e \odot _{C} a) = (a \odot _{C} e) = a (e⊙Ca)=(a⊙Ce)=a成立
- 逆元: 对于每个C中的元素a,总存在C中的一个元素b,使得总有 ( a ⊙ C b ) = ( b ⊙ C a ) = 1 (a \odot _{C} b) = (b \odot _{C} a) = 1 (a⊙Cb)=(b⊙Ca)=1成立
加法同态。若在明文上的运算符 ⊙ M \odot _{M} ⊙M是加法运算符,且满足加法同态加密定义,则该方案可被称为加法同态的(additively homomorphic)。Paillier在1999年提出了一种可证的安全加法同态加密系统,且对应的密文上的运算符 ⊙ C \odot _{C} ⊙C也是加法运算符。满足加法同态的加密算法一般也满足标量乘法同态,因为标量乘法运算可以转换为有限次的加法运算。
**乘法同态。**若在明文上的运算符 ⊙ M \odot _{M} ⊙M是乘法运算符,且满足乘法同态定义,则该方案被称为乘法同态的(multiplicative homomorphic)。如RSA加密算法和ElGamal加密算法,且对应的密文上的运算符 ⊙ C \odot _{C} ⊙C也是乘法运算符。
- 些许同态加密(SHE)
些许同态加密(SHE)是指经过同态加密后的密文数据,在其上执行的操作(如加法、乘法等)只能是有限的次数。一些文献中也定义SHE为只有包含有限数量的某些电路(如跳转程序,混淆电路)能够支持进行任意次数的运算,例如BV、BGN和IP。SHE方案为了安全性使用了噪声(noise)数据。密文上的每一次操作都会增加密文上的噪声量,而乘法操作是增长噪声量的主要技术手段。当噪声量超过一个上限值之后,解密操作就不能得出正确结果了。这就是为什么绝大多数的SHE方案会要求限制计算操作次数的原因,正是这些缺点导致它在实际应用中受到很多限制。
- 全同态加密(FHE)
全同态加密算法允许对密文进行无限次的加法和乘法运算操作。我们知道,要实现任意的函数计算,加法和乘法运算是仅需的操作,即任意一个函数都可以转化为只包含加法和乘法的形式。设 A , B ∈ F 2 A,B ∈F_2 A,B∈F2(即取值空间为0,1域),与非门可以通过公式“1+A×B”计算得到。由于功能上的完备性,与非门能够用来构建任何逻辑门电路,因此,FHE能够计算任何函数功能。
但值得注意的是,虽然FHE从理论上能够解决任何函数的加密计算问题,但是要设计一个真正意义上的全同态加密算法是非常困难的,直到2009年才由斯坦福大学的博士生Craig Gentry提出了世界上第一个FHE算法。自此之后,全同态加密算法的设计成为密码学的热门研究方向。从整体上看,FHE算法的设计又可以进一步分为以下四种
- Ideal Lattice-based FHE:基于理想格的全同态加密,也就是由Gentry设计的第一个全同态加密算法
- Approximate-GCD based FHE:由Van Dijk等人提出的一种全同态加密方案,与Gentry的实现相似,该方案的安全性基于AGCD假设和稀疏子集和假设
- (R)LWE-based FHE:与上面两种方案相比,该实现也被称为第二代全同态加密技术。与基于理想格的实现不同,该方案基于(R)LWE构造,通过引入再线性化技术与维数模约减技术实现了乘法的同态加密,效率比第一代的加密方案有了很大提升。
- 基于近似特征向量技术实现的FHE:前面的加密方案都需要借助计算密钥的辅助来实现全同态加密,但计算密钥的大小制约了全同态加密的性能。为此,在2013年,Gentry等人利用近似特征向量技术设计了无须计算密钥的全同态加密方案GSW,标志着第三代全同态加密方案的诞生。
当前,FHE的研究仍在高速发展,在高效的自举算法、多密钥全同态加密等领域都有许多人在进行研究。目前的FHE建立在些许同态加密(SHE)方法的基础上,并通过代价高昂的自助法(bootstrap)操作实现。由于自助法的代价高昂,FHE方案计算十分缓慢且在实践中往往并不比传统的安全多方计算方法更好,因此,许多研究人员目前正着眼于发现满足特定需求的更有效的SHE方案,而非去发掘FHE方案。
2.2 基于差分隐私的安全机制
差分隐私(图2-2)采用了一种随机机制,使得当输入中的单个样本改变之后,输出的分布不会有太大的改变。例如,对于差别只有一条记录的两个数据集,查询它们获得相同的输出的概率非常接近。这将使用户即使获取了输出结果,也无法通过结果推测出输入数据来自哪一方。
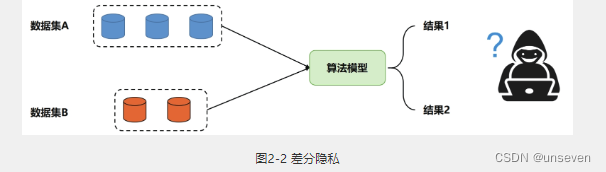
在现有的隐私保护方法中,由于差分隐私对隐私损失进行了数学上的定义,并且其实现过程比较简捷,系统开销更小,所以得到了广泛的应用。差分隐私最开始被开发用来促进在敏感数据上的安全分析。随着机器学习的发展,差分隐私再次成为机器学习社区中一个活跃的研究领域。来自差分隐私的许多令人激动的研究成果都能够被应用于面向隐私保护的机器学习。
2.2.1 定义
差分隐私是由Dwork在2006年首次提出的一种隐私定义,是在统计披露控制的场景下发展起来的。它提供了一种信息理论安全性保障,即函数的输出结果对数据集里的任何特定记录都不敏感。因此,差分隐私能被用于抵抗成员推理攻击。
按照数据收集方式的不同,当前的差分隐私可以分为中心化差分隐私和本地化差分隐私,它们的区别主要在于差分隐私对数据处理的阶段不同。
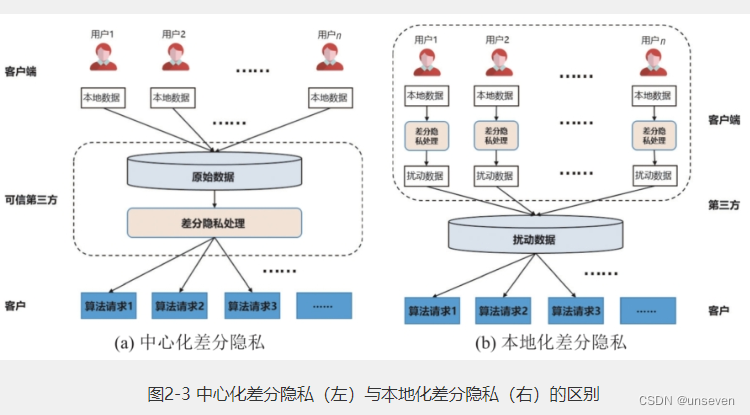
中心化差分隐私依赖一个可信的第三方来收集数据,用户将本地数据发送到可信第三方,然后在收集的数据中进行差分隐私处理。但可信的第三方在现实生活通常是很难获得的,因此本地化差分隐私将数据隐私化的工作转移到每个参与方,参与方自己来处理和保护数据,再将扰动后的数据发送到第三方,由于发送的数据不是原始数据,因此也就不要求第三方是可信的。
下面我们分别介绍这两种差分隐私的定义。图2-3展示的是中心化差分隐私和本地化差分隐私在处理流程上的区别。
中心化差分隐私
我们首先给出中心化差分隐私的(ϵ,δ)-差分隐私定义。
 式中,ϵ表示隐私预算(privacy budget),δ表示失败概率。当δ=0时,便得到了性能更好的ϵ-差分隐私。
式中,ϵ表示隐私预算(privacy budget),δ表示失败概率。当δ=0时,便得到了性能更好的ϵ-差分隐私。
在差分隐私定义中,隐私保护预算ϵ用于控制算法M在邻近数据集D和D′上获得相同输出的概率比值。式(2.5)表明,ϵ的值越小,那么算法M在邻近数据集D和D′上获得相同输出的概率就越接近,因此,用户通过输出结果,无法区分输入数据到底是来自数据集D还是来自数据集D′,即无法察觉数据集的微小变化,从而达到隐私保护的目的。特别地,当ϵ=0时,算法M在D和D′上得到相同的输出的概率是一样的。反之,ϵ的值越大,其隐私保护的程度就越低。
中心化差分隐私在实际的应用中,有两个非常重要的性质:串行组合和并行组合。
 满足
满足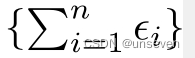 差分隐私保护。
差分隐私保护。

满足 m a x i max_i maxi{ ϵ i ϵ_i ϵi}-差分隐私保护。
这两个性质非常有用,如果一个攻击者想试图攻破一个差分隐私安全系统,那么最简单直接的方法是对该系统进行多次查询访问。从系统角度看,这样相当于增大了隐私保护预算值,从而降低了系统的隐私性;从攻击者的角度看,将多次查询访问获取的结果进行平均,根据大数定理,查询次数越多,这个均值的结果和真实值就越接近。这也是当前很多安全系统都设置查询上限的原因,目的就是为了防止恶意攻击。
本地化差分隐私
本地化差分隐私(Local Differential Privacy,LDP)可以将数据隐私化的工作转移到每个参与方,参与方自己来处理和保护数据,进一步降低了隐私泄露的可能性,它的定义如下。
 在本式中,ϵ表示隐私预算。
在本式中,ϵ表示隐私预算。
比较定义2-6和定义2-3,我们不难发现,中心化差分隐私是定义在任意两个相邻数据集的输出相似性上的,而本地化差分隐私是定义在本地数据任意两条记录的输出相似性上的。此外,本地化差分隐私同样继承了组合特性,即它同样满足并行组合和串行组合的性质。
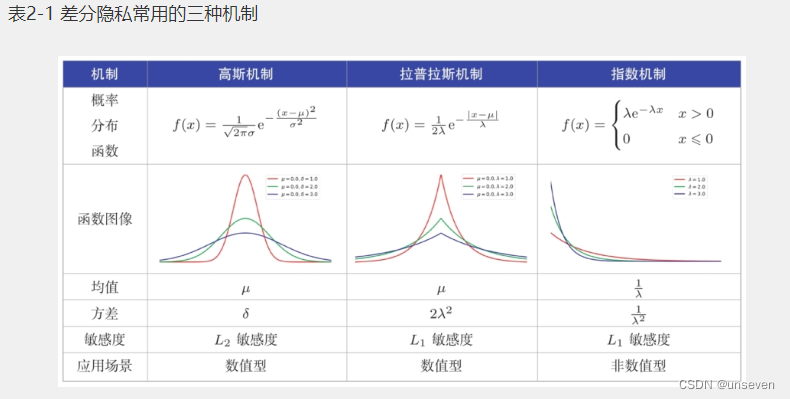
这种差异性,导致其实现方法也有很大的不同。中心化差分隐私需要保护全体数据的隐私,具有全局敏感性的概念,采用的扰动机制可以包括高斯噪声机制、拉普拉斯噪声机制、指数噪声机制等。在本地化差分隐私中,数据隐私化的工作转移到每个参与方,而每一个参与方并不知道其他参与方的数据,因此它并没有全局隐私敏感性的概念,它采用的扰动机制一般通过随机响应实现(Randomized Response,RR)。
本地化差分隐私的概念与联邦学习有点相似。事实上,在联邦学习的实现中,可以结合本地化差分隐私的思想,比如给每一参与方的上传梯度或者模型参数加上噪声来更好地保护模型参数。
2.2.2 差分隐私的实现机制
目前实现差分隐私保护的主流方法是添加扰动噪声数据。前面提到,差分隐私可以分为中心化差分隐私和本地化差分隐私,其中:中心化差分隐私采用的扰动机制可以包括拉普拉斯噪声机制、指数噪声机制等;而本地化差分隐私一般通过随机响应(Randomized Response)[277]来实现(随机响应是1965年由Warner提出的一种隐私保护技术)。
要想知道不同算法函数M需要添加多少噪声才能提供(ϵ,δ)-差分隐私保护,就需要先定义该算法在当前数据上的全局敏感度。全局敏感度根据计算距离的方式不同,一般可以区分为L1全局敏感度和L2全局敏感度。

即
L
1
L_1
L1全局敏感度反映了一个函数M在一对相邻数据集D和D′上进行操作时变化的最大范围。
当使用2-范数(即欧氏距离)来衡量函数在相邻数据集上的输出变化时,我们得到如下的L2全局敏感度定义。

不管是
L
1
L_1
L1敏感度还是
L
2
L_2
L2敏感度,它的结果与提供的数据集无关,只由函数本身决定。从直观上理解,当全局敏感度比较大时,说明数据集的细微变化可能导致函数M的输出有很大的不同,我们需要添加较大的噪声数据,才能使函数M提供(ϵ,δ)-差分隐私保护;相反,当全局敏感度比较小时,说明数据集的细微变化不会对函数M的输出产生很大的影响,我们只需要添加较小的噪声数据,就能使函数M提供(ϵ,δ)-差分隐私保护。下面介绍在差分隐私中常用的三种添加噪声的机制。
 为添加的随机噪声概率密度函数,即服从参数µ=0,λ=
∆
f
ϵ
\cfrac{∆f}{ϵ}
ϵ∆f的拉普拉斯分布。
为添加的随机噪声概率密度函数,即服从参数µ=0,λ=
∆
f
ϵ
\cfrac{∆f}{ϵ}
ϵ∆f的拉普拉斯分布。
拉普拉斯机制实现非常简单,被广泛应用于数值型查询的隐私保护机制。对于查询结果,只需要加入一个满足拉普拉斯分布 L ( 0 , ∆ f ϵ ) L(0,\cfrac{∆f}{ϵ}) L(0,ϵ∆f)的噪声数据,就能实现(ϵ,0)-差分隐私保护。
高斯机制为数值型查询结果隐私保护提供了另一种实现。与拉普拉斯机制不同,高斯机制的定义使用的是L2全局敏感度,其定义如下。
 ,那么随机算法M=f(D)+L提供(ϵ,δ)-差分隐私保护,其中L~Gaussian(0,
σ
2
σ^2
σ2)为添加的随机噪声概率密度函数,即服从参数µ=0,
σ
=
2
I
n
1.25
δ
×
∆
(
f
)
ϵ
σ=\sqrt{2In\cfrac{1.25}{δ}} \times \cfrac{∆(f)}{ϵ}
σ=2Inδ1.25×ϵ∆(f)的高斯分布。
,那么随机算法M=f(D)+L提供(ϵ,δ)-差分隐私保护,其中L~Gaussian(0,
σ
2
σ^2
σ2)为添加的随机噪声概率密度函数,即服从参数µ=0,
σ
=
2
I
n
1.25
δ
×
∆
(
f
)
ϵ
σ=\sqrt{2In\cfrac{1.25}{δ}} \times \cfrac{∆(f)}{ϵ}
σ=2Inδ1.25×ϵ∆(f)的高斯分布。
指数机制是用于非数值型差分隐私保护的一种实现方式,它使用L1敏感度作为参数构造,其定义如下。

在定义2-11中,∆(q)表示
L
1
L_1
L1敏感度,若D和D′表示的是任意两个相邻数据集,r表示的是任意的一个输出,其定义为
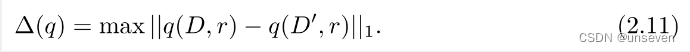
前面介绍的是在查询状态下对输出结果实现差分隐私保护的机制。在机器学习中应用差分隐私技术,其情况会更加复杂,因为我们要保护的信息,不仅包括输入数据和输出数据,还包括算法模型参数、算法的目标函数设计等。因此,在机器学习领域应用差分隐私算法,一个关键的问题是何时、何阶段添加噪声数据。为此,差分隐私算法根据噪声数据扰动使用的方式和使用阶段的不同,将其划分为下面几类。
(1)输入扰动:噪声数据被加入训练数据。
(2)目标扰动:噪声数据被加入学习算法的目标函数。
(3)算法扰动:噪声数据被加入中间值,例如迭代算法中的梯度。
(4)输出扰动:噪声数据被加入训练后的输出参数。
2.3 基于安全多方计算的安全机制
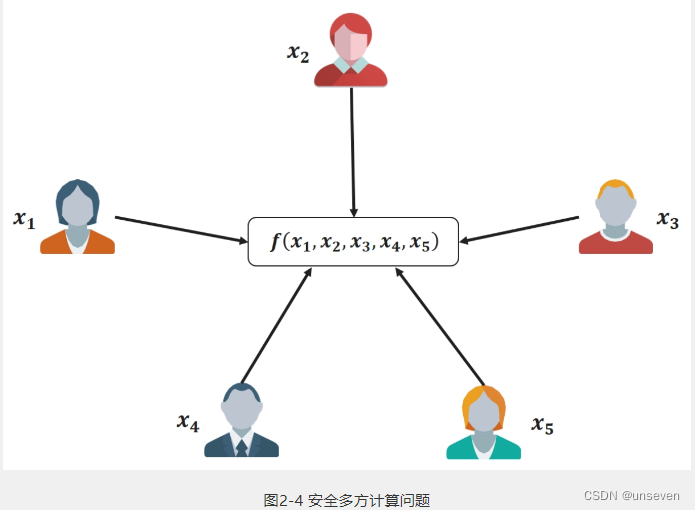
安全多方计算(MPC)是密码学的一个子领域,目的是多个参与方协同地从每一方的隐私输入中计算某个函数的结果,而不用将这些输入数据展示给其他方。基于MPC,对于任何函数功能需求,我们都可以在不泄露除输出以外的信息的前提下计算它。MPC最初针对的是一个安全两方计算问题(即著名的“百万富翁问题”)而被正式提出的。
定义2-12 百万富翁问题 ——两个百万富翁都想比较到底谁更富有,但是又都不想让别人知道自己有多少钱。如何在没有可信的第三方的情况下解决这个问题?
当前主要有三种常用的隐私计算框架,可以用来实现安全多方计算,它们分别是:秘密共享(Secret Sharing,SS),不经意传输(Oblivious Transfer,OT),混淆电路(Garbled Circuit,GC)。
2.3.1 秘密共享
简单来说就是把一个秘密值分成n份,只有达到一定数量t组合在一起才能得到被共享的秘密值,少一个都不能重构原始数据。
定义2-13 (t,n) 门限秘密共享方案对于数据集合A,有n个用户集合(1,2,· · ·,n),一个(t,n)门限秘密共享方案包括分享(Share)和重构(Reconstruct)两个环节。
- 分享:分享是指借助一个算法M将原始数据m∈M拆分为n个部分(s1,· · ·,sn),并将它们分别下发给n个用户。
- 重构:是指借助一个算法F从n个用户中任意选取t个用户的秘密值,构成一个t元组,将这个t元组作为函数F的输入,能还原原始数据m∈M。更一般地,对于任意的m ∈ M,对于任意的t个用户集合(i1,i2,· · ·,it)⊆(1,2,· · ·,n),满足:
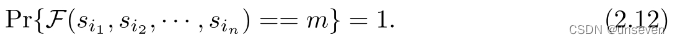
这里的t也被称为门限值。
当前的秘密共享方案研究,就在于如何高效地构造(t,n)门限秘密共享方案。这些方案包括算术秘密共享(Arithmetic Secret Sharing)、Shamir秘密共享(Shamir’s Secret Sharing)和二进制秘密共享(Binary Secret Sharing)等多种方式。
- t=1:这是最简单的形式,事实上,我们只需要将原始数据m∈M分发到n个用户即可。
- t=n:有多种方式可以实现(n,n)门限,较为常用的一种方案是,将原始数据m∈M编码为一个二进制表示s,对于前n-1个用户,任意生成和s长度相等的二进制表示si,si就是第i个用户的秘密值,对于第n个用户,我们将其秘密值设置为
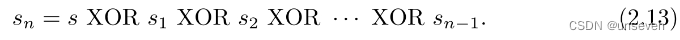
- t=k:这种方案的实现形式有很多,典型的实现包括Shamir的基于拉格朗日插值法的实现。Blakley的门限方案则是利用多维空间点的性质建立的。
在秘密共享系统中,攻击者必须同时获得一定数量的秘密碎片才能获得密钥,这种共享系统提高了系统的安全性。另外,当某些秘密碎片丢失或被毁时,利用其他的秘密份额仍然能够获得秘密,从而提高系统的可靠性。秘密共享的上述特征,使它在实际中得到了广泛的应用,包括通信密钥的管理、数据安全管理、银行网络管理、导弹控制发射、图像加密等。
此外,秘密共享没有中心节点的概念,因此有助于联邦学习的去中心化实现。
2.3.2 不经意传输
不经意传输(Oblivious Transfer,OT)是由Rabin在1981年提出的一种两方计算协议,被广泛应用于安全多方计算(MPC)等领域。
在不经意传输中,发送方拥有一个“消息-索引”对 ( M 1 , 1 ), ⋅ ⋅ ⋅ ,( M N , N ) (M_1,1),···,(M_N,N) (M1,1),⋅⋅⋅,(MN,N)。在每次传输时,接收方选择一个满足1≤i≤N的索引i,并接收Mi。接收方不能得知关于数据库的任何其他信息,发送方也不能了解关于接收方i的选择的任何信息。
我们给出“n个中取1”不经意传输的定义。
定义2-14 “n个中取1”不经意传输——设A方有一个输入表 ( x 1 , ⋅ ⋅ ⋅ , x n ) (x_1,· · ·,x_n) (x1,⋅⋅⋅,xn)作为输入,B方有i∈1,···,n作为输入。“n个中取1”不经意传输是一种安全多方计算协议,其中,A不能学习到关于i的信息,B只能学习到xi。
当n=2时,我们得到了“2个中取1个”不经意传输(1-out-of-2不经意传输),“2个中取1个”不经意传输对两方安全计算是普适的。换言之,给定一个“2个中取1个”不经意传输,我们可以执行任何的安全两方计算操作。
在实际应用中,不经意传输的一种实施方式是基于RSA公钥加密技术。举例来说,“2个中取1个”不经意传输的一个简单的实施流程如下。
-
发送方生成两对不同的公钥和私钥对,并公开这两个公钥,记这两个公钥分别为公钥pk1和公钥pk2。假设接收方希望收到消息m1,但不希望发送方知道他想要收到的是消息m1。接收方生成一个随机数k,再用公钥pk1对k进行加密,并传给发送方。
-
发送方用他的两个私钥对这个加密后的k进行解密,用私钥sk1解密得到k1,用私钥sk2解密得到k2。只有k1是等于k的,k2是一个无意义的数。不过,因为发送方不知道接收方加密k时用的是哪个公钥,所以他并不知道解密出来的k1和k2中哪一个值才是真的k的值。
-
发送方把m1和k1进行异或,把m2和k2进行异或,并把两个异或结果都发送传给接收方。
-
接收方使用k与收到的消息进行异或。接收方只能算出m1,而无法推测出m2。这是因为接收方不知道私钥sk2,从而推不出k2的值,而且发送方也不知道接收方能算出哪一个消息。
-
接收方可以进一步通过校验信息(checksum,例如CRC校验码)来确定m1是正确收到的消息。
2.3.3 混淆电路
混淆电路(Garbled Circuit,GC)是姚期智教授提出的安全多方计算概念。GC的思想是通过布尔电路的观点构造安全函数计算,使得参与方可以针对某个数值来计算答案,而不需要知道它们在计算式中输入的具体数字。因为GC的多方的共同计算是通过电路的方式实现的,所以这里的关键词是“电路”。实际上,所有可计算问题都可以转化为各个不同的电路,例如加法电路、比较电路、乘法电路等。而电路是由一个个门(gate)组成的,例如与门、非门、或门、与非门等。
混淆电路可以看成一种基于不经意传输的两方安全计算协议,它能够在不依赖第三方的前提下,允许两个互不信任方在各自私有输入上对任何函数进行求值。由于与、或、非门组成的逻辑电路可以执行任何计算,所以GC使用电路表示待计算函数。
GC的中心思想是将计算电路分解为产生阶段和求值阶段。两个参与方各自负责一个阶段,而在每一阶段中电路都被加密处理,所以任何一方都不能从其他方获取信息,但仍然可以根据电路获取结果。GC由一个不经意传输协议和一个分组密码组成。电路的复杂度至少是随输入内容大小的增大而线性增长的。
2.4 全机制的性能效率对比
当前的很多文献都表明,从理论的角度,传输明文信息(如模型参数、参数梯度等)也是不安全的,攻击者可以通过窃取这些梯度信息来还原(或者部分还原)原始数据信息,从而导致数据隐私的泄露。这也是隐私保护机器学习提出的初衷。
联邦学习的训练模型以保证数据不出本地为前提,从而最大限度地减少数据的隐私泄露问题。但在联邦学习训练的过程中,客户端和服务端之间需要进行模型的信息(如模型参数、参数梯度等)交互,以便协同训练一个机器学习模型。如果直接传输明文信息,正如上面所分析的,也会存在信息泄露的风险。因此,联邦学习的安全机制设计是联邦学习一个非常重要的环节。
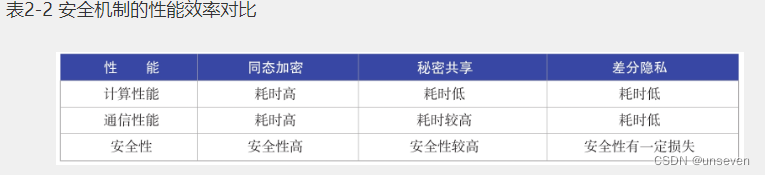
本章介绍了联邦学习常用的三大安全机制,即同态加密、差分隐私和安全多方计算,它们也是密码学领域常用的安全策略,在与联邦学习结合使用的过程中,各自有优点和缺点。本节将从计算性能、通信性能和安全性三个维度进行综合比较(注意由于安全多方计算包括多种不同的实现策略,这里主要以秘密共享来讲解)。
- 计算性能:从计算的角度看,计算主要耗时在求取梯度上。对于同态加密,计算在密文的状态下进行,密文的计算要比明文的计算耗时更长;而差分隐私主要通过添加噪声数据进行计算,其效率与直接明文计算几乎没有区别;同理,秘密共享是在明文状态下进行的,计算性能基本不受影响。
- 通信性能:从通信的角度看,同态加密传输的是密文数据,密文数据比明文数据占用的比特数要更大,因此传输效率要比明文慢;差分隐私传输的是带噪声数据的明文数据,其传输效率与直接明文传输几乎没有区别;秘密共享为了保护数据隐私,通常会将数据进行拆分并向多方传输,完成相同功能的迭代。同态加密和差分隐私需要一次,而秘密共享需要多次数据传输才能完成。
- 安全性:注意,由于安全性的范围很广,这里我们特指在联邦学习场景中本地数据隐私的安全。虽然在联邦学习的训练过程中,我们是通过模型参数的交互来进行训练的,而不是交换原始数据,但当前越来越多的研究都表明,即使只有模型的参数或者梯度,也能反向破解原始的输入数据。结合当前的三种安全机制来保护联邦学习训练时的模型参数传输:同态加密由于传输的是密文数据,因此其安全性是最可靠的;秘密共享通过将模型参数数据进行拆分,只有当恶意客户端超过一定的数目并且相互串通合谋时,才有信息泄露的风险,总体上安全性较高;差分隐私对模型参数添加噪声数据,但添加的噪声会直接影响模型的性能(当噪声比较小时,模型的性能损失较小,但安全性变差;相反,当噪声比较大时,模型的性能损失较大,但安全性变强)。
我们可以通过表2-2来总结本章介绍的三大安全机制与联邦学习相结合时的表现。读者也可以在实际的应用场景中,根据需求挑选安全机制来辅助实现联邦学习。
2.5 基于Python的安全计算库
前面介绍了联邦学习中常见的安全机制及实现。事实上,这些安全机制并非联邦学习所特有,它们各自在密码学领域中已经被广泛研究和使用,因此,当前也有很多开源的实现方案可供使用。本节简要介绍一些常用的基于Python实现的安全计算库。
Python开源程序包pycrypto提供了常用的加/解密算法的实现[2],不仅包括AES、DES、RSA、ElGamal等常用算法,还包括常用的散列函数。特别地,Python开源程序包pycryptodome是pycrypto项目的一个分支(fork),提供了更加丰富的加/解密算法的实现,包括秘密共享算法。在pycryptodome包里,对计算量大的操作还提供了高效的C语言扩展实现。
当前联邦学习系统里最常用的隐私保护机制是同态加密。开源的Python-Paillier程序包提供了支持部分同态加密(例如加法和标量乘法同态加密)的Python 3实现。Python-Paillier程序包主要是实现了基于Paillier算法的加法和标量乘法同态加密算法,支持对浮点数的加密运算。
差分隐私的主要实现机制是在输入或输出上加入随机化的噪声(数据),例如拉普拉斯噪声、高斯噪声、指数噪声等。开源的Python程序包differential-privacy提供了常用的差分隐私方法的实现。IBM公司提供的开源程序包diffprivlib是另外一个常用的Python差分隐私程序库。
开源的MPyC程序包提供了基于Python的安全多方计算的实现。MPyC程序包主要提供了基于有限域上的阈值秘密共享,即使用Shamir的门限阈值密码共享方案以及伪随机秘密共享。
常用的基于Python的安全计算程序包还有散列算法、ECC(Elliptic Curve cryptography)加密算法、ECDSA(Elliptic Curve Digital Signature Algorithm)加密算法和eth-keys秘钥生成算法等。
















 1807
1807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











