







前情回顾:类加载机制

双亲委派
parent只是一个成员变量,不是继承关系

上节课遗留问题
parent是怎么指定的?
手动指定parent:

双亲委派机制可以被打破吗?
双亲委派机制是在ClassLoader类里的LoadClass()方法已经写死的,你只需重写FingClass()方法就可以了。那怎么打破它呢?

热加载的实现原理
Tomcat把整个ClassLoader全部干掉,再用自己实现的ClassLoader把新修改过的类的Class重新Load一遍。
package com.mashibing.jvm.c2_classloader;
import com.mashibing.jvm.Hello;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class T012_ClassReloading2 {
private static class MyLoader extends ClassLoader {
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
File f = new File("C:/work/ijprojects/JVM/out/production/JVM/" + name.replace(".", "/").concat(".class"));
if(!f.exists()) return super.loadClass(name);
try {
InputStream is = new FileInputStream(f);
byte[] b = new byte[is.available()];
is.read(b);
return defineClass(name, b, 0, b.length);
} catch (IOException e) {
e.printStackTrace();
}
return super.loadClass(name);
}
}
public static void main(String[] args) throws Exception {
MyLoader m = new MyLoader();
Class clazz = m.loadClass("com.mashibing.jvm.Hello");
m = new MyLoader();
Class clazzNew = m.loadClass("com.mashibing.jvm.Hello");
System.out.println(clazz == clazzNew);
}
}
Linking

证明默认值的存在
输出结果为2. 如果交换10 11行,输出结果为3
package character03;
public class T001_ClassLoadingProcedure {
public static void main(String[] args) {
System.out.println(T.count);
}
}
class T {
public static T t = new T(); // 执行到这一步时,下一行的count仍然是默认值0,调用构造方法后,count变为1,
public static int count = 2; // 执行到这一步时,上一行的count=1被这一行的count=2覆盖
private T() {
count ++;
}
}
New 一个对象的过程
- 先分配内存
- 再赋默认值
- 再赋初始值
面试题:DCL(Double Check Lock)单例要不要加Volitile?
需要。因为有指令重排的问题。
初始化一半的时候,单例已经存在了,处于半初始化的状态。此时另外一个线程来了,直接把半初始化的对象取走了,出现值的问题。
package com.mashibing.jvm.c0_basic;
public class C {
public static void main(String[] args) {
Object o = new Object();
}
}
下图4、7可能会发生重排

new: Create new object
dup: 复制操作数堆栈上的顶部值,并将复制的值压入操作数堆栈。
invoke special: 调用实例方法; 对超类、私有和实例初始化方法调用的特殊处理
astore _< n >: 将引用存储到局部变量中。操作数堆栈顶部的objectref的类型必须是returnAddress或reference类型。它从操作数堆栈中弹出,并将处的局部变量的值设置为objectref。
JMM(Java Memory Model)
硬件层的并发优化基础知识

这个金字塔,从最上层L0开始,越往下 速度越慢,成本越低,空间越大
L0 L1 L2是CPU内部的缓存,每个CPU或者CPU的核心独享
读取速度:CPU 远大于 内存 远大于 磁盘
这个远大于大概就是100倍+

产生数据的不一致问题:两个CPU之间的缓存怎么保持一致?

老的CPU,总线锁:效率偏低

新的CPU:缓存锁: 各种各样的一致性协议,例如,intel的MESI协议
4种状态的含义:我改过、只有我在用(独享)、我读别人也在读、失效

现代CPU的数据一致性实现=缓存锁(MESI…)+总线锁
缓存行
简单理解是我要读取一个数据,CPU不止装载这个数据,还会装载很多其他可能会用到的数据进来
读取缓存以cacheline为基本单位,多数的实现为64kB(64字节,512位)
可能导致伪共享问题
伪共享:位于同一缓存行的两个不同数据被两个不同CPU锁定,产生相互影响的问题。
示例1:两个线程修改同一个数组中的值。执行时间约250
package character03;
import java.util.Random;
public class T01_CacheLinePadding {
private static class T {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
示例2:使用7个long类型的数字(7个*8字节=56字节)将缓存行填起来,加上变量x本身占用的空间,使两个T对象恰巧不在统一缓存行。耗时80
通过缓存行对齐后,效率提升了。
package character03;
public class T02_CacheLinePadding {
private static class Padding {
public volatile long p1, p2, p3, p4, p5, p6, p7;
}
private static class T extends Padding {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start) / 100_0000);
}
}
开源的disruptor就考虑到了缓存行问题。

CPU乱序执行
乱序执行:CPU为了提高效率,会在一条指令执行过程中(比如去内存读数据,慢100倍),去同时执行另一条指令。前提是两条指令没有依赖关系。
CPU乱序执行的根源,参考 cpu乱序执行

读的乱序执行
比如CPU要去读L3中的一个数据,这个读的速度对CPU来说很慢,它就判断如果下面的指令和这个数据没有直接关系,就可能同时去执行下面的指令.
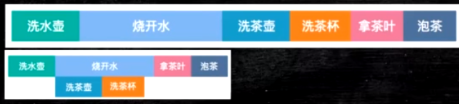
生活中的例子就是下main这个泡茶的过程:
合并写(WC)

提到乱序时,一般也会提到合并写,尽管合并写其实并不算是乱序执行,这里就简单了解一下.
WCBuffers: WriteCombiningBuffers,这个WCBuffers的个数依赖cpu模型,目前测试是和CPU的核数相等.
也就是CPU有几颗核心,那么WCBuffers一次就可以更新几个地址的数据
当cpu执行存储指令时,它会首先试图将数据写到离cpu最近的L1_cache, 如果此时cpu出现L1未命中,则会访问下一级缓存。速度上L1_cache基本能和cpu持平,其他的均明显低于cpu,L2_cache的速度大约比cpu慢20-30倍,而且还存在L2_cache不命中的情况,又需要更多的周期去主存读取。其实在L1_cache未命中以后,cpu就会使用一个另外的缓冲区,叫做合并写存储缓冲区(WCBuffers)。这一技术称为合并写入技术。
在请求L2_cache缓存行的所有权尚未完成时,cpu会把待写入的数据写入到合并写存储缓冲区.这个缓冲区允许cpu在写入或者读取该缓冲区数据的同时继续执行其他指令,这就缓解了cpu写数据时cache miss时的性能影响。
示例:
WCBuffers只有4个字节,runCaseOne一次填6个的话,要等下一次把剩下的2个填满。
而runCaseTwo一次填4个,就正好填满。
package character03;
public final class WriteCombining {
private static final int ITERATIONS = Integer.MAX_VALUE;
private static final int ITEMS = 1 << 24;
private static final int MASK = ITEMS - 1;
private static final byte[] arrayA = new byte[ITEMS];
private static final byte[] arrayB = new byte[ITEMS];
private static final byte[] arrayC = new byte[ITEMS];
private static final byte[] arrayD = new byte[ITEMS];
private static final byte[] arrayE = new byte[ITEMS];
private static final byte[] arrayF = new byte[ITEMS];
public static void main(final String[] args) {
for (int i = 1; i <= 3; i++) {
System.out.println(i + " SingleLoop duration (ns) = " + runCaseOne());
System.out.println(i + " SplitLoop duration (ns) = " + runCaseTwo());
}
}
public static long runCaseOne() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i; // 1Byte
arrayA[slot] = b; // 1Byte
arrayB[slot] = b; // 1Byte
arrayC[slot] = b; // 1Byte
arrayD[slot] = b; // 1Byte
arrayE[slot] = b; // 1Byte
arrayF[slot] = b; // 1Byte
}
return System.nanoTime() - start;
}
public static long runCaseTwo() { // 一次正好写满一个四字节的 Buffer,比上面的循环效率更高
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i; // 1Byte
arrayA[slot] = b; // 1Byte
arrayB[slot] = b; // 1Byte
arrayC[slot] = b; // 1Byte
}
i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
}
乱序执行的证明
package character03;
public class T04_Disorder {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
// private static volatile int x = 0, y = 0;
// private static volatile int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for (; ; ) {
i++;
x = 0;
y = 0;
a = 0;
b = 0;
Thread one = new Thread(new Runnable() {
public void run() {
//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.
//shortWait(100000);
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();
other.start();
one.join();
other.join();
String result = "第" + i + "次 (" + x + "," + y + ")";
if (x == 0 && y == 0) {
System.err.println(result);
break;
} else {
//System.out.println(result);
}
}
}
public static void shortWait(long interval) {
long start = System.nanoTime();
long end;
do {
end = System.nanoTime();
} while (start + interval >= end);
}
}
如果一直都是顺序执行的,那么有以下这几种可能:
- a=1;x=b;b=1;y=a --> x=0,y=1
- a=1;b=1;x=b;y=a --> x=1,y=1
- a=1;b=1;y=a;x=b --> x=1,y=1
- b=1;y=a;a=1;x=b --> x=1,y=0
- b=1;a=1;y=a;x=b --> x=1,y=1
- b=1;a=1;x=b;y=a --> x=1,y=1
并且无论如何都不会出现x=0,y=0的情况,如果出现了,那就是出现了乱序执行的情况,即x=b发生在b=1之前,并且y=a发生在a=1之前
如何保证这种情况下不乱序
使用volatile
硬件层面
以 intel CPU 为例:

store(储存)
load(装载)
modify/mix(混合)
也可以使用原子指令,比如lock指令,lock是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU
软件层面比如JVM通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
JVM层面
















 8032
8032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









