






 文章介绍了自注意力机制(self-attention)如何减少对外部信息的依赖,更好地捕捉数据内部关联,以及它在序列标注(SequenceLabeling)、情感分析和翻译等任务中的应用。同时,对比了RNN在处理序列数据时的特点,如LSTM和GRU等门控机制,强调了self-attention在效率和处理长距离依赖上的优势。
文章介绍了自注意力机制(self-attention)如何减少对外部信息的依赖,更好地捕捉数据内部关联,以及它在序列标注(SequenceLabeling)、情感分析和翻译等任务中的应用。同时,对比了RNN在处理序列数据时的特点,如LSTM和GRU等门控机制,强调了self-attention在效率和处理长距离依赖上的优势。
文章目录
摘要
In the real world, many elements are interconnected.The essence of RNN is: having the ability to remember like humans. Therefore, the output depends on the current input and memory.
Attention actually comes from humans’ ability to process external information. When processing information, people will focus on the information that needs attention and filter other irrelevant external information. The Self-attention is an improvement of the Attention , which reduces the dependence on external information and is better at capturing the internal correlation of data or characteristics.
Many applications of Recurrent Neural Networks are gradually being replaced by Self-attention .
现实世界中,很多元素都是相互连接的,循环神经网络本质是:像人一样拥有记忆的能力。因此,它的输出就依赖于当前的输入和记忆。
注意力机制其实是源自于人对于外部信息的处理能力。人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤。而自注意力机制是对注意力机制的改进,减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
很多循环神经网络的应用正逐渐被自注意力机制取代。
self-attention(自注意力机制)
之前都是在研究只输入一个向量的情况,现在研究输入多个向量,且每个向量的长度可变的情形。
vector set as input,
例如:识别语句,有one-hot Encoding、Word Encoding(考虑语义)等方法。
语音识别、分子研究。
Graph(图):每个结点当作一个向量。
Output的情况如下:
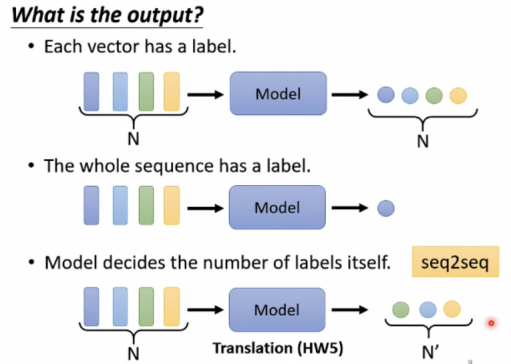
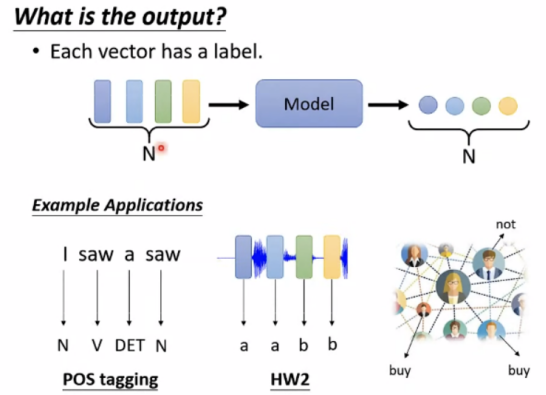
(1)Each vector has a label(输入和输出数量一致)(Sequence labeling)
词性分析:
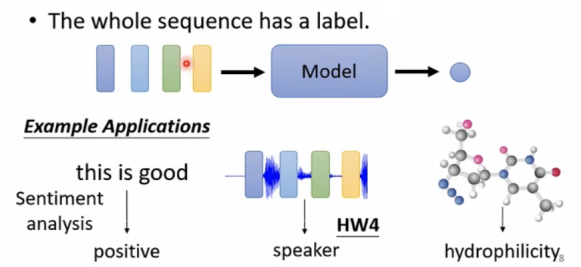
(2)The whole sequence has a label(多个输入只有一个输出)
sentiment analysis(判断语句是正面还是负面)
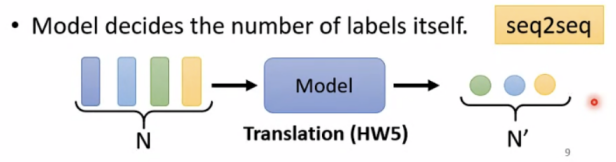
(3)Model decides the number of labels itself(机器自己决定输出的数量)
翻译、语音辨识
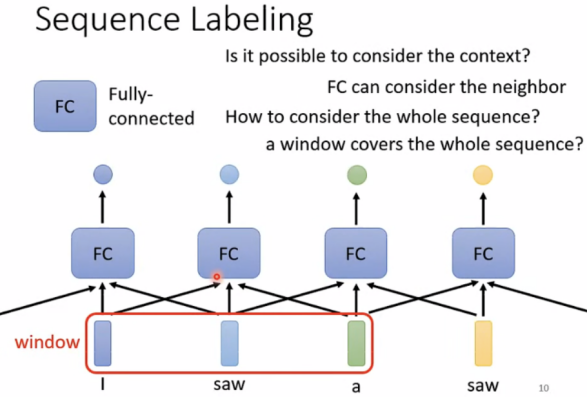
Sequence Labeling
如果使用fully-connected做词性判断,当输入I saw a saw时,无法识别两个saw的不同词性。
改进: 联系上下文(window)或者考虑整个sequence
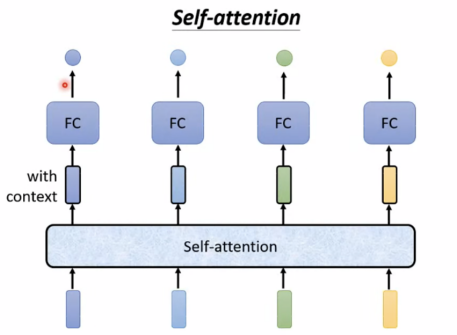
Self-attention
可叠加使用:
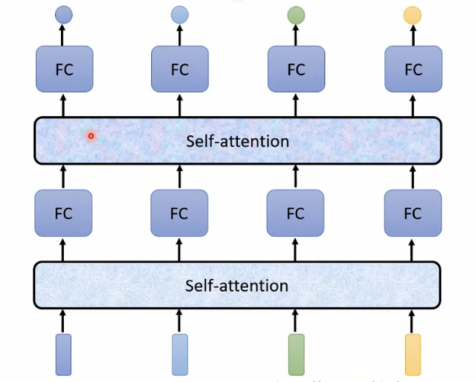
具体如下:
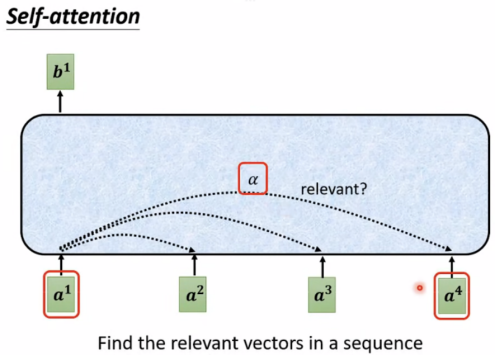
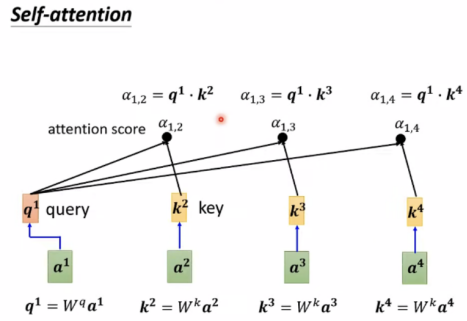
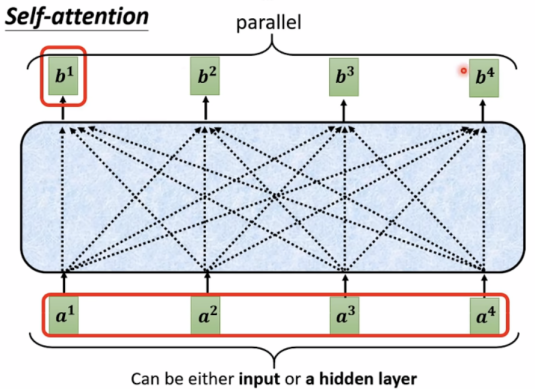
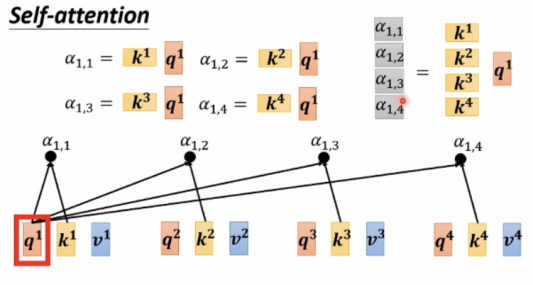
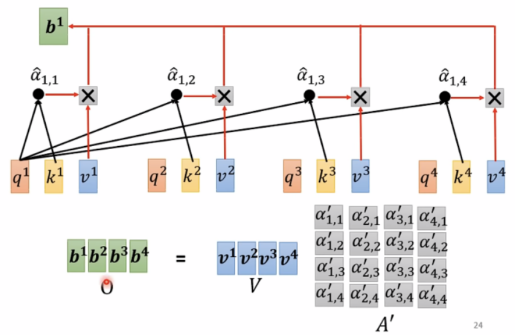
要想得到b,首先考虑a2、a3、a4与a1的关联度α。
计算α的方法有Dot-product,Additive等,这里使用Dot-product:
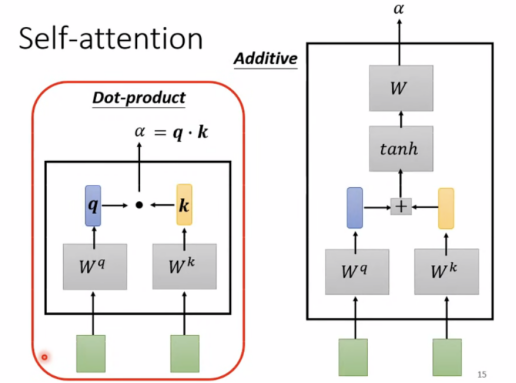
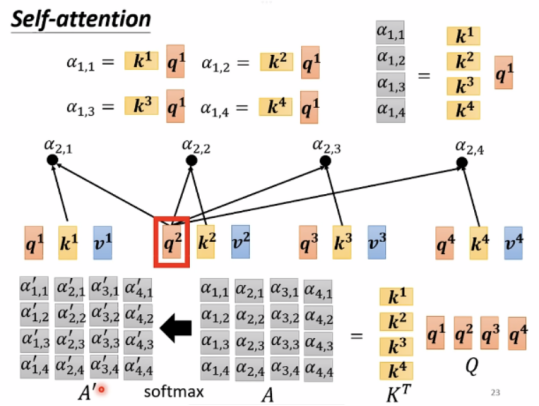
此外,还有α1,1 = q1*k1,接下来做soft-max,也可以用其他function,一般使用soft-max。
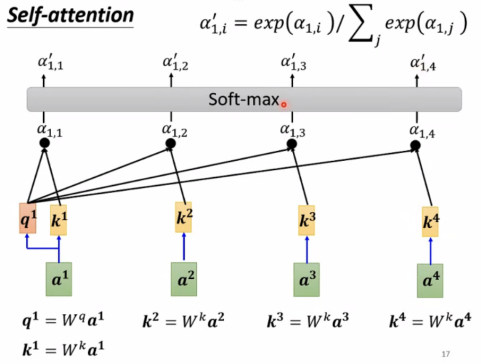
Extract information based on attention scores
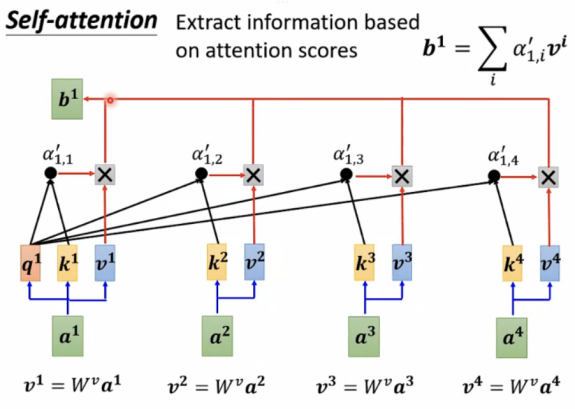
b1-b4是同时计算出的,无先后顺序。
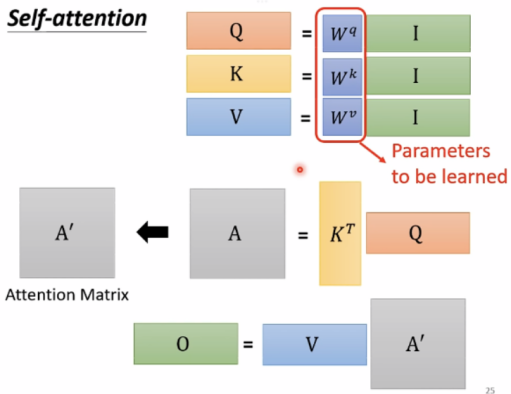
接下来使用线性代数的方法研究q,k,v等参数
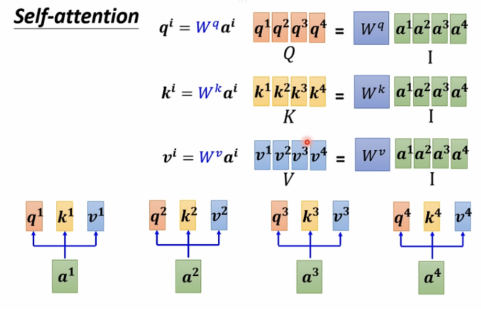
由以上过程可知,只有Wq、Wk、Wv是parameters to be learned。
Multi-head Self-attention
此时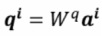 ,以2 heads 为例,
,以2 heads 为例,
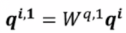
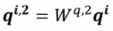
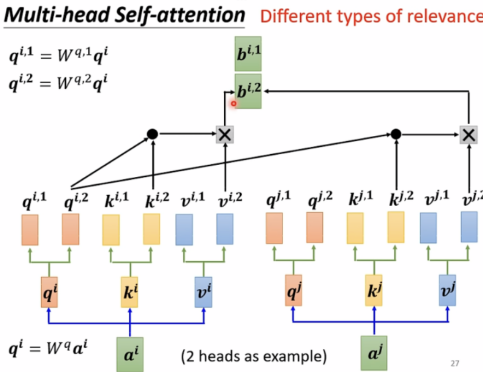
Positional Encoding
当序列位置比较重要,可使用positional encoding,用ei来标记每个位置,有很多种方法来实现。
Application
Self-attention广泛应用与NLP(自然语言处理)
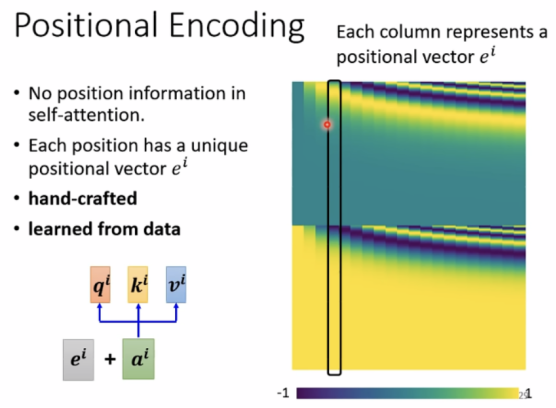
Truncated Self-attention在语音中的应用,只看部分,不看全部句子:
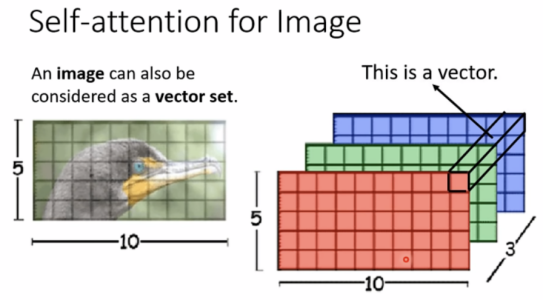
Self-attention for image(图像)
CNN将image当成一个vectoe,也可以将image当成vector set.
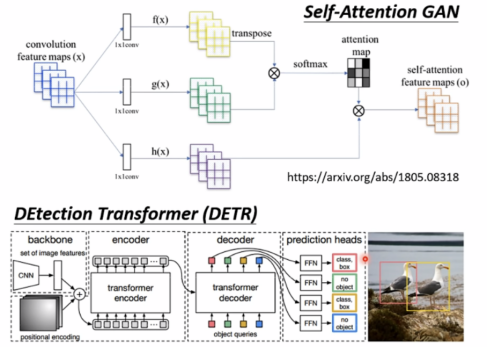
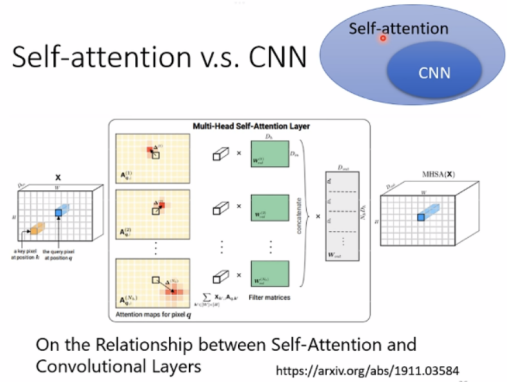
Self-attention 对比 CNN:
CNN是简化版的Self-attention,
在Self-attention中,receptive field不再是人工划定,而是可学习的。

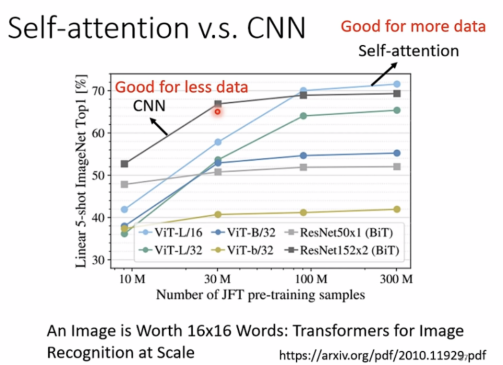
CNN: good for less data
Self-attention: good for more data
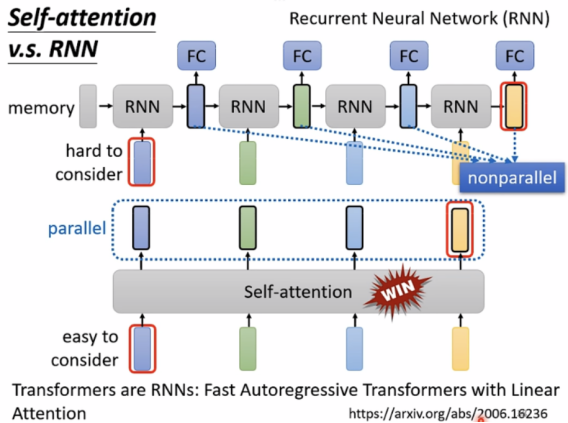
Self-attention 对比RNN:
RNN要考虑输入序列的顺序,且较难考虑最远处。
故self-attention效率更高,正逐渐取代很多RNN的应用。
Self-attention for graph(图形)
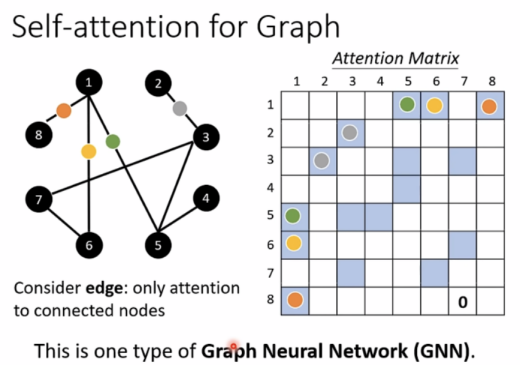
这是专门的GNN类型。
Recurrent Neural Network(RNN循环神经网络)
Example Application(处理输入是vector set(sequence)的情形)
例: ticket booking system
需要slot filling(槽填充)
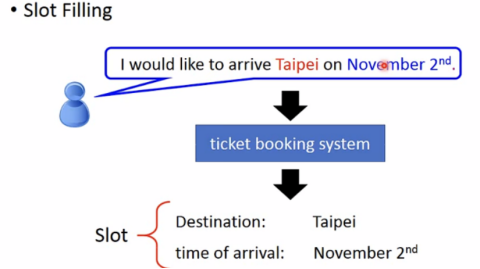
使用feedforward network解决slot filling

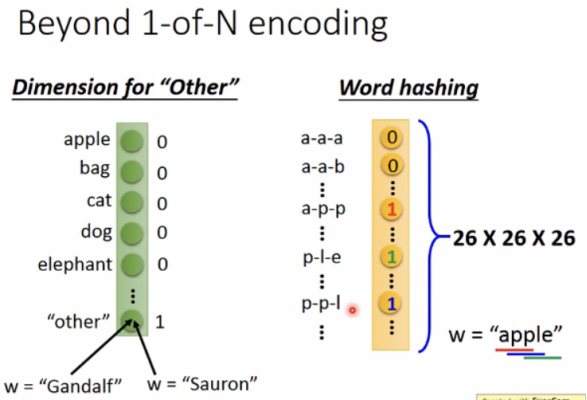
使用1-of-N encoding 将每个word编成vector:

也可用其他方法编码:
为了解决这个问题,还需要使用有记忆的neural network,这种network即为RNN。
RNN
可以叠加使用。

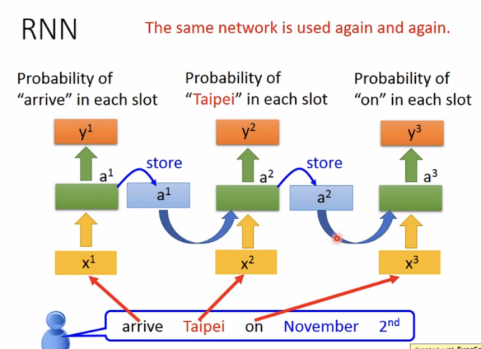
举例说明如何运用:
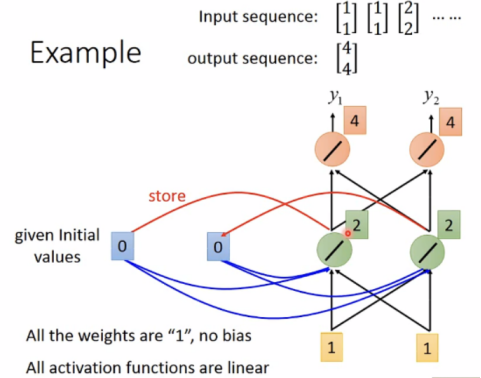
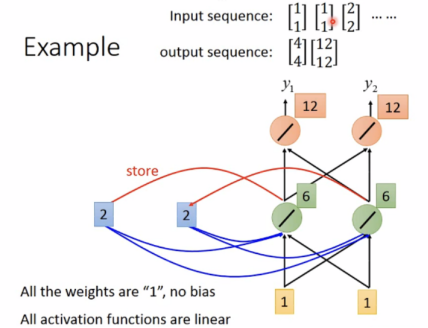
即输入同样的向量[1,1]时,output是可能不同的。
用RNN来实现ticket booking system
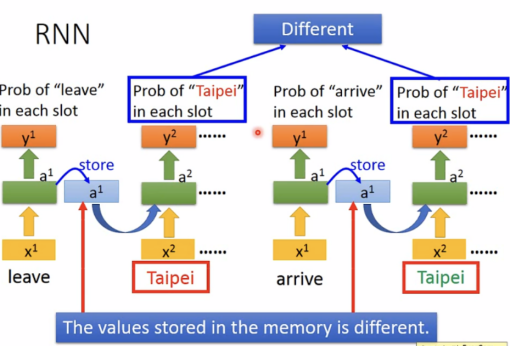
此时values stored in the memory is different.
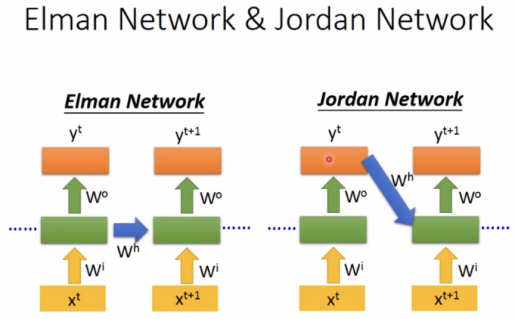
Elman Network存储hidden layer
Jordan Network存储output
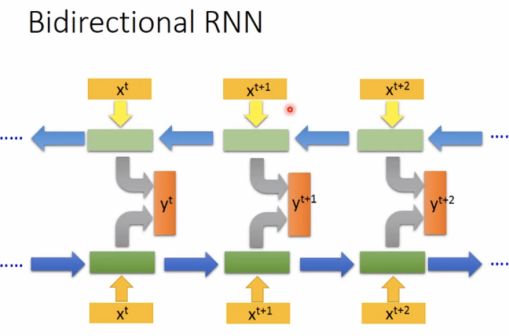
Bidrectional RNN(双向)
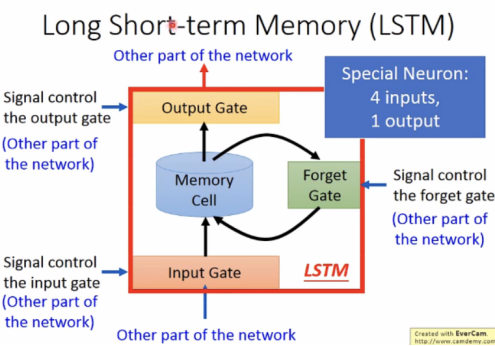
关于memory的补充:
long short-term memory(LSTM)
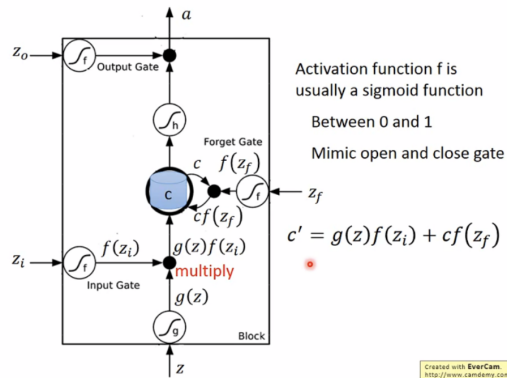
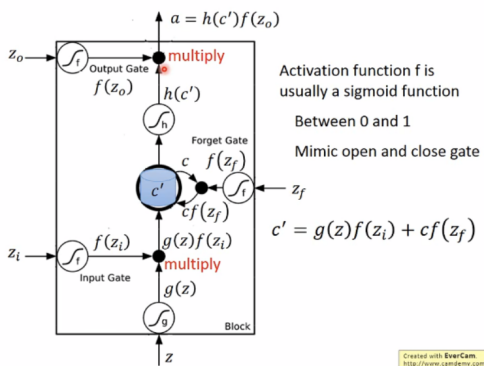
几个gate neuron通常使用sigmoid函数使结果映射在0和1之间。
如果f(zi)= 0,相当于没有输入。
f(zf)= 0,相当于将c’= g(z)f(zi)存入memory(遗忘原来的c)
f(zf)= 1,相当于将c’= c + g(z)f(zi)存入memory(保留原来的c)
LSTM-Example
当x2=1,将x1输入memory
当x2=-1,重置memory
当x3=0,将memory的值输出y

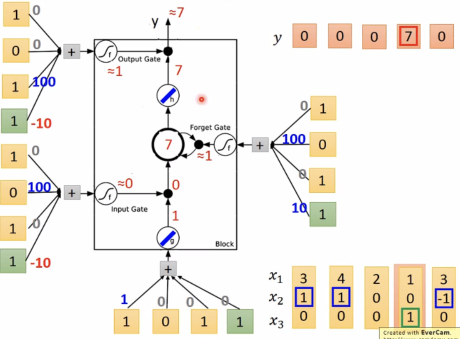
即LSTM需要的参数量是neural network的4倍。

标准的LSTM:
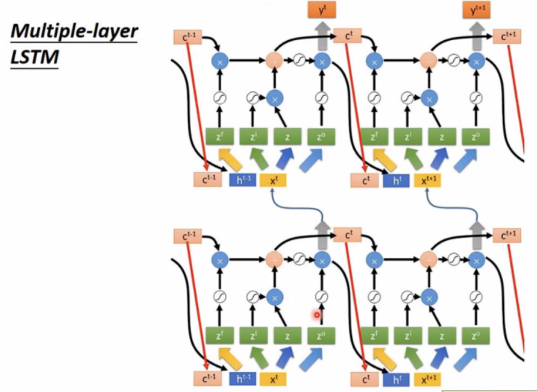
注:keras支持“LSTM”、“GRU”、“simpleRNN”等layers。
总结
本周学习了self-attention自注意力机制及其应用,并且学习了RNN部分内容,二者都是研究input为vector set的情形。下周将继续学习RNN剩下的内容以及transformer。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









