






文章目录
摘要
GAN网络全称generative adversarial network,在许多生成任务中显示出很好的结果,以复制真实世界的丰富内容,例如图像、文字和语音。GAN受到博弈论的启发:一个生成器和一个判别器,在互相竞争的同时让彼此变得更强大。然而,训练 GAN 模型相当具有挑战性,因为人们面临训练不稳定或无法收敛等问题。
Abstract
GAN(generative adversarial network) shows good results in many generating tasks, so as to copy the rich contents of the real world, such as images, words and voices. GAN is inspired by game theory: a generator and a discriminator make each other stronger while competing with each other. However, training GAN model is quite challenging, because people are faced with problems such as unstable training or inability to converge.
Generative Adversarial Network(生成式对抗网络)
generated model概念
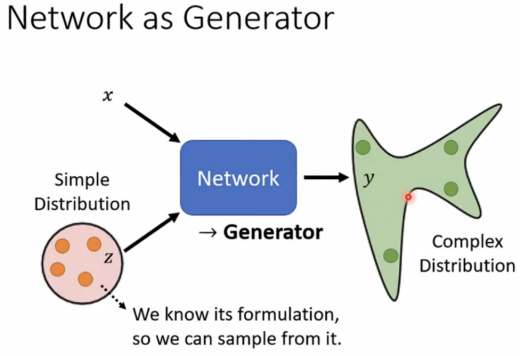
将network 当作 generator,同时考虑x和z,得出的y是一个complex distribution
要求z是从simple distribution(知道分布情况,如高斯分布,伯努利分布)中sample出来。
为什么需要生成模型
在进行创造活动时,同样的输入需要有不同的结果,例如绘画、聊天机器人等等。
在小精灵游戏中,面对交叉路口时,如果不使用GAN,小精灵会分裂,出现同时向左和向右转的情形。
解决方法:可以引入一个binary distribution,即sample 到0左转,1右转。

GAN
Anime Face Generation
GAN是生成模型中很重要的一种,以anime face生成为例来理解GAN,首先考虑unconditional generation:

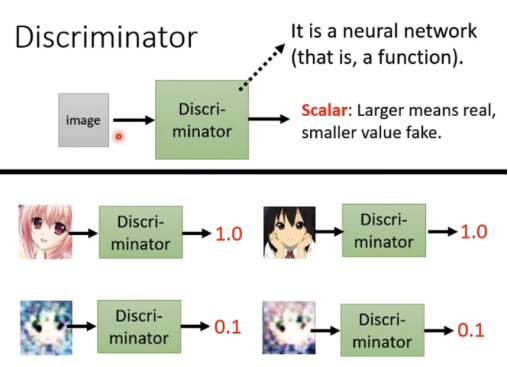
Discriminator的概念:
在进行anime face生成时,还需要将image作为输入放入discriminator(a neural network,可以选择CNN),输出一个scalar,该值越大,代表image越接近anime face。
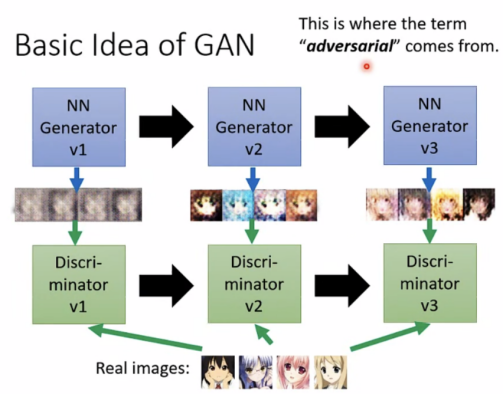
GAN的概念:
Generator和discriminator处于一种“对抗”的关系,以anime face举例,generator需要不断生成出能通过上一代discriminator的image。也因此,GAN较难train,因为有一方不再提高,另一方也会不再进步。
Algorithm(算法):
(1)初始化generator和discriminator
(2)在每次迭代中:
step 1:
固定generator G,更新discriminator D。
discriminator学习给real objects高分,给generated objects低分。
在anime face生成中,给动漫头像1,给生成的图片0(可使用分类或是回归的方法)。
step 2:
固定discriminator D,更新 generator G,
generator学习“fool”discriminator。
(3)反复多次迭代。
补充说明:
(1)step 1中train discriminator的具体方法如下:
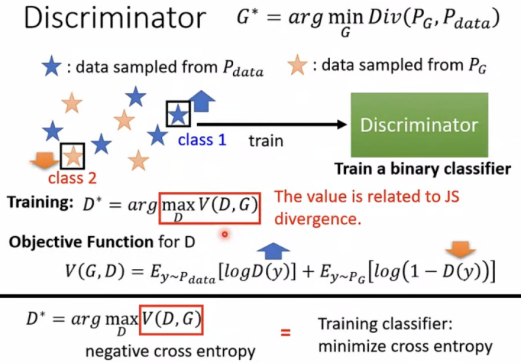
从直观上理解,small divergence,train的时候large divergence较难分辨,故maxV(D,G)也很小;small divergence容易训练,maxV(D,G)会很大。
The maximum objective value is related to JS divergence。
(2)也可以使用其他divergence,但不管用哪种,GAN is difficult to train。

WGAN
背景:在大部分例子中,Pg和Pdata是不重叠的,JS divergence在这种情况下不适用。
(1)Pdata和Pg是高维空间中的低维manifold,重叠部分小到可以忽略。
(2)即使有重叠,也可能sample不够多。

JS divergence会出现问题,算出的结果总是log2,discriminator总能区分real和generator,正确率高达100%。这样并不能令人满意,因此为了在之前使用人眼判断图片是否在变好。
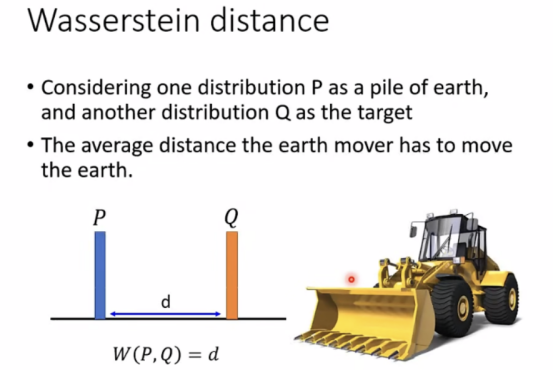
Wassertein distance(推土机距离)
简单情形W(P,Q)=d:
复杂情形:
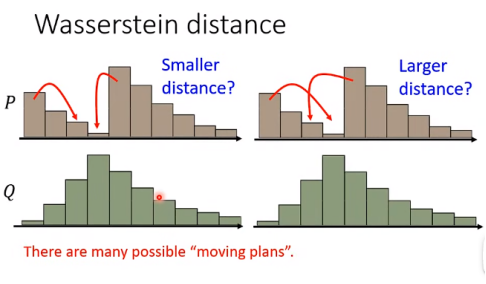
推土机距离的概念:
穷举所有情形,最小的平均距离才是推土机距离。
WGAN概念:使用Wassertein distance代替JS divergence的GAN。

D必须足够平滑,有以下几种WGAN,其中谱归一化的SNGAN最为有效。

Conditional Generation
Text-to-image,此时discriminator打分时需要同时考虑x和y,训练时放入好文字+好图片,好文字+坏图片,以及坏文字+好图片的组合。
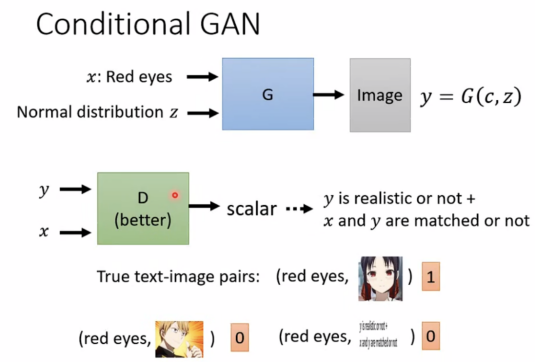
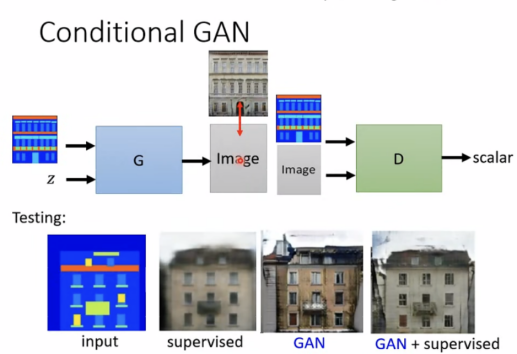
Image translation/pix2pix:
Conditional Generation也可以用于图片产生图片,如用设计图产生实际图,用黑白照片产生彩色照片,素描图变实景,去雾,白天变黑夜等等。
其他应用如听声音想象画面,静止的图片变成动图。
Cycle GAN(Unsupervised conditional Generation)
这种GAN Learning from unpaired Data,并且是双向的。
如Image Style Transfer,将真人变成动漫风格:

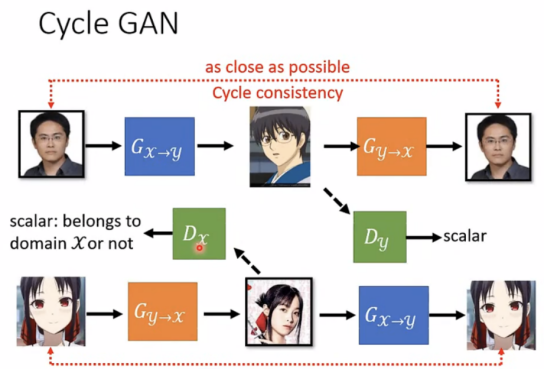
Evaluation of generation
判断quality的好坏:
早期使用人眼看Generation生成的图片,现在将单张图片放入CNN,用影像识别系统分析,如果结果比较集中,说明生成图片可能较好(high quality)。
可能出现的问题:
(1)Mode Collapse(模式坍塌)
重复生成相同或者类似的图片来骗过CNN。遇到这种情况,可以将之前的图片sample出。
(2)Mode Dropping(模式丢失)
Generated data仅仅是real data的一部分,丢失了部分data。

判断diversity的好坏:
将一堆图片放入CNN,如果结果比较平坦,说明多样性较好。
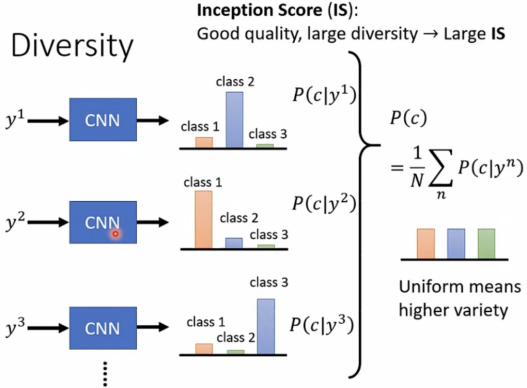
结合上述,评判整体的标准如下:
(1)Inception Score(IS)
Good quality,large diversity -> Large IS
(2)Frechet Inception Distance(FID)
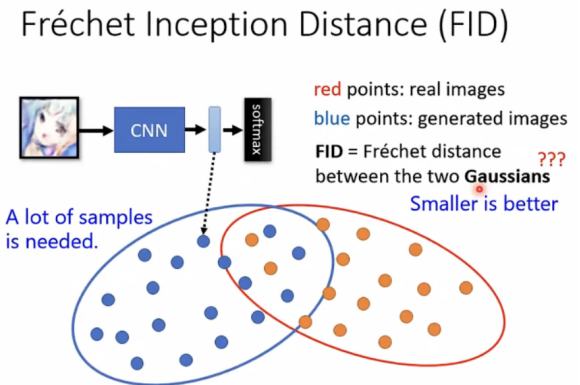
总结
本周学习了GAN等相关内容,下周将学习Self-supervised Learning有关内容。















 174
174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









