







1.请求网页
import requests
# 请求头,对python爬虫进行伪装
# user-agent:浏览器的身份标识
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
# 由于vmgirls这个网站打开开发者工具会自动退出,可以在网址url前加“view-source:”,如:view-source:https://www.vmgirls.com/12985.html查看网页源代码
# 1.请求网页
response = requests.get('https://www.vmgirls.com/12985.html', headers=headers)
html = response.text
print(html)
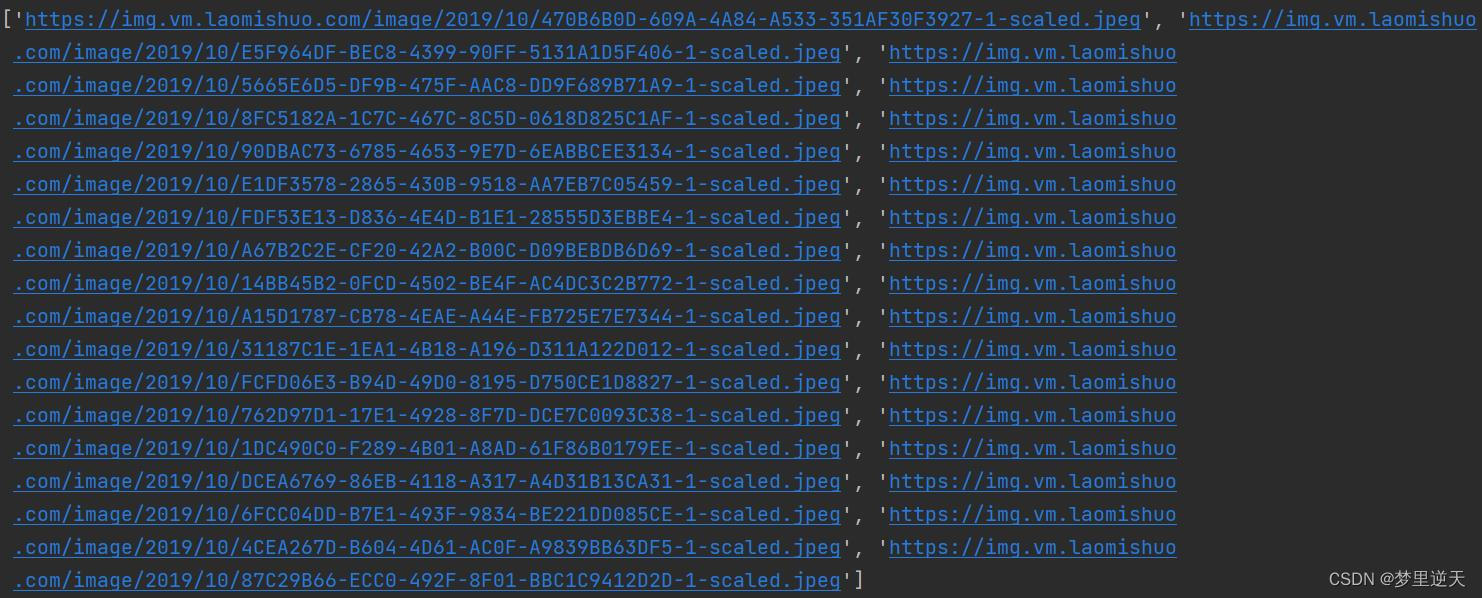
2.解析网页,提取我们需要的数据
我们想要的是网页上的图片链接。

# 2.解析网页
# 使用正则表达式匹配网页文本中满足特定条件的内容
urls = re.findall('<a rel="nofollow" href="(.*?)" alt=".*?">', html)
print(urls)
3.保存数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 9064
9064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











