



阿拉伯科学与工程杂志https://doi.org/10.1007/s13369‐020‐04564‐w
研究论文‐电气工程
基于模糊聚类方案与汇聚节点选择算法的无线传感器网络监测应用
阿纳加·拉朱特1 ·维诺斯·巴布·库马拉维鲁1
收到日期:2018年5月7日/接受日期:2020年 4月24日©2020年国王法赫德石油与矿业大学
无摘线要传感器网络(WSN)主要用于监测应用。传感器节点是资源受限的设备,因此这些节点的能量高效利用是主要挑战之一。通信距离直接影响传感器节点的能耗。聚类方法被广泛用于减少通信距离并延长网络寿命。多汇聚节点部署是另一种减少通信距离的方法,它还能解决拥塞和热点问题。在多汇聚节点无线传感器网络中,需要考虑的汇聚节点数量是一个具有挑战性的任务,因为它会影响网络拓扑、寿命和部署成本。在本研究工作中,联合提出了多汇聚节点部署和聚类方案以及汇聚点选择算法,以最大化网络寿命并最小化部署成本。提出了一种迭代滤波模型来估计最优汇聚节点数量,而汇聚节点位置则基于模糊逻辑推理系统(FLIS)确定。采用模糊C均值算法在网络中形成均衡簇。簇代表和汇聚节点选择过程均基于FLIS。所提出的最优多汇聚点部署方案降低了系统的部署成本和传播延迟,同时增强了网络寿命。该方案在高节点密度情况下也具有较高的能量效率。因此,所提出的方案可适用于无线传感器网络的大规模监测应用。
Keywords
环境监测应用·模糊C均值(FCM)·模糊逻辑推理系统(FLIS)·多汇聚节点部署 ·无线传感器网络( WSN)
1 引言
无线传感器网络是特定应用的自组织网络,可部署在无人和恶劣区域。新兴的物联网(IoT)技术为无线传感器网络开辟了新的研究领域。这些网络被视为物联网系统的物理基础设施。一些应用包括环境监测系统、电子医疗、工业物联网、智能家居等。[1–3]。这些应用预期将使用大规模的无线传感器网络。根据应用需求,传感器节点的数量可从几个到数百个不等。传感器节点是先进的微机电系统(MEMS)设备,集成了传感器、处理器和无线射频电路。这些节点依靠
B Vinoth BabuKumaravelu vinothbab@gmail.com
电子工程学院,韦洛尔理工学院,韦洛尔,泰米尔纳德邦,印度
电池电量。对于大规模无线传感器网络,更换节点或其电池是非常不切实际的。因此,无线传感器网络的主要挑战之一是高效利用这些节点的能量,以延长网络寿命[4, 5]。
在传统无线传感器网络中,传感器节点直接将感知数据传输到汇聚节点。远离汇聚节点的节点由于长距离数据传输而消耗更多能量。因此,这些节点过早地耗尽能量,从而降低了网络寿命[6, 7]。该问题由低能耗自适应聚类分层(LEACH)协议[8]加以解决。在此协议中,传感器节点被划分为多个簇,并由簇头代表(CR)负责每个簇的数据聚合与传输。聚类方法被广泛用于减小通信距离并延长网络寿命。文献中的许多无线传感器网络协议均考虑单汇聚节点[9–13]。但单汇聚节点无线传感器网络存在拥塞和热点问题[14]。
多汇聚节点无线传感器网络是另一种减少通信距离的方法。此外,多汇聚节点无线传感器网络的能耗低于单汇聚节点无线传感器网络[15]。聚类的
123
本文档由funstory.ai的开源PDF翻译库BabelDOCv0.5.10(http://yadt.io)翻译,本仓库正在积极的建设当中,欢迎star和关注。
阿拉伯科学与工程杂志
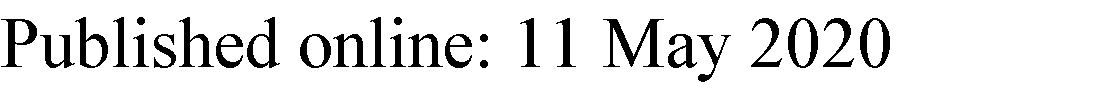
表1
单汇聚节点与多汇聚节点无线传感器网络的比较[16,17]
| 序号 | 网络 参数 | 单汇聚节点无线传感器网络 | 多汇聚节点无线传感器网络 |
| — | — | — | — |
| 1 | 能量 能耗 | 更高 | 更低 |
| 2 | 拥塞 | 更高 | 更低 |
| 3 | 端到端延迟 | 更高 | 更低 |
| 4 | 数据传输 | 更低 | 更高 |
| 5 | 覆盖范围 | 更低 | 更高 |
| 6 | 连接性 | 更低 | 更高 |
| 7 | 部署成本 | 更低 | 更高 |
用于基于物联网的监控系统的多汇聚节点部署无线传感器网络如图1所示。该监控系统由传感器节点、汇聚节点和Web服务器组成。传感器节点将感知数据共同传输到附近的汇聚节点。汇聚节点是Web服务器与无线传感器网络之间的网关,具有较高的处理能力和可充电电源。在Web服务器上收集到的感知数据随后可通过互联网方便地提供给远程用户。在多汇聚节点无线传感器网络中,通过选择邻近的汇聚节点可减少传感器节点的通信距离,从而相应地降低能耗。同时,由于节点更靠近汇聚节点,因此也提供了更高的连接性。由于网络流量由多个汇聚节点分担,所有汇聚节点处的拥塞均可最小化。表 1[16, 17]给出了单汇聚节点与多汇聚节点无线传感器网络之间的比较。可以看出,在多汇聚节点无线传感器网络中,能耗(最终体现为通信距离)与部署成本之间存在权衡。
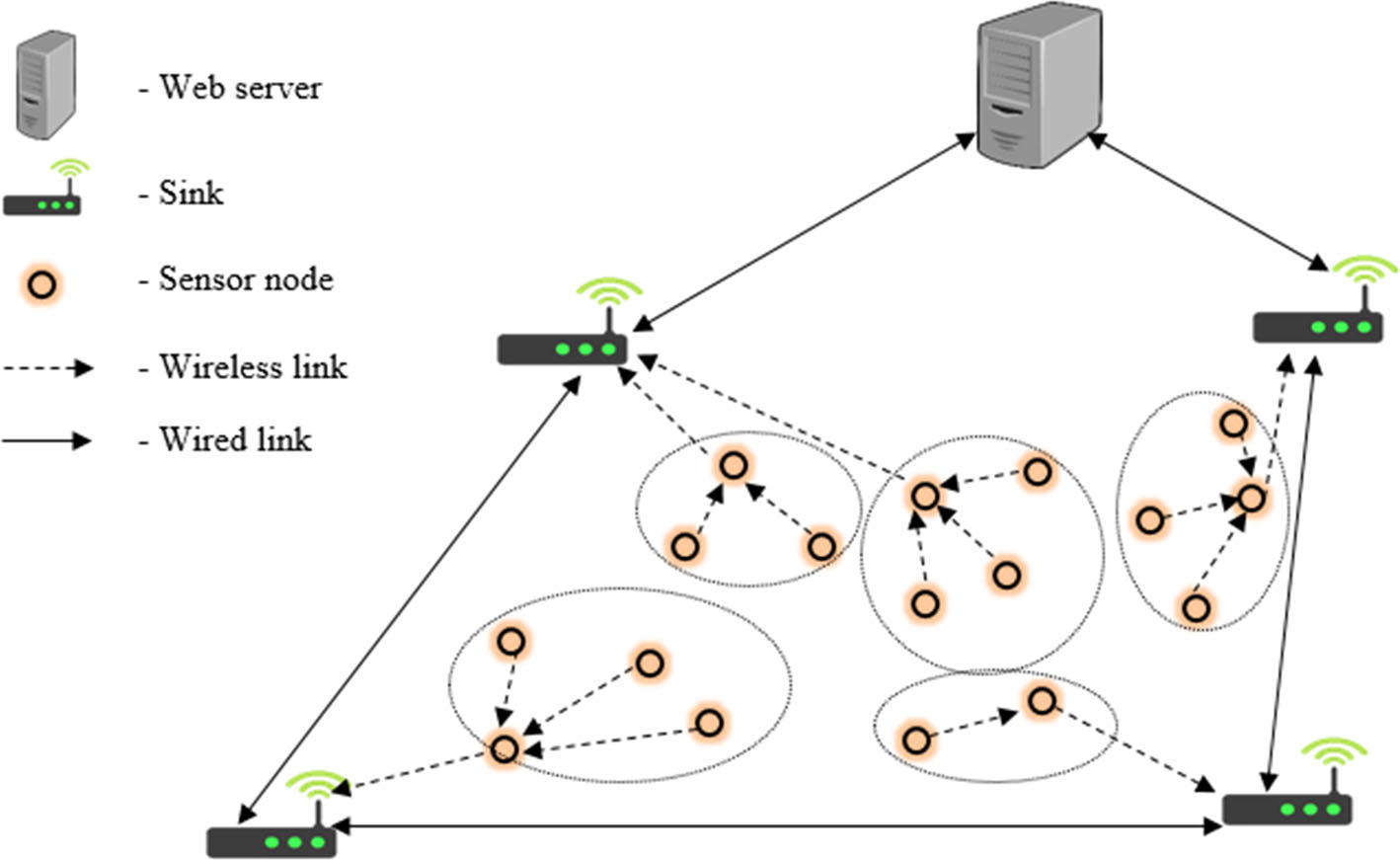
在本研究工作中,联合提出了多汇聚节点部署和带有汇聚节点选择算法的聚类方案,以平衡能量效率与部署成本之间的权衡。模糊逻辑处理模糊性的特性促使我们采用基于模糊的算法来实现所提出的方案。所提出方案的系统模型如图2所示。该方案包含两个阶段——初始设置阶段和传输阶段。初始设置阶段在 Web服务器上执行,而传输阶段在传感器节点上独立执行。因此,所提出的方案以半分布式方式进行操作。提出了迭代滤波模型,用于估计能够覆盖整个无线传感器网络的最少数量的汇聚节点。然后建模FLIS以确定估计数量的汇聚节点的最优位置。簇的形成基于模糊C均值(FCM)算法,而簇头和汇聚节点的选择则基于FLIS。以下是所提出方案的主要贡献:
- 在多汇聚节点无线传感器网络中,网络拓扑和部署成本随汇聚节点数量的不同而变化。我们提出了一种迭代滤波模型,用于确定覆盖所有传感器节点所需的最少数量的汇聚节点。根据给定的可能候选汇聚节点位置数量,确定每个候选位置下被覆盖的节点集合。然后,对所有被覆盖的节点进行迭代筛选,以计算所需的汇聚节点位置数量。这确保了以最少数量的汇聚节点实现对网络的完全覆盖。
-
汇聚节点的位置对节点的传输距离有重大影响。在本研究工作中,使用FLIS从给定的候选位置中确定最佳汇聚点位置。FLIS通过两个输入进行建模——候选位置附近的节点密度和
123
阿拉伯科学与工程杂志

候选位置与其所覆盖节点之间的平均通信距离。模糊规则的设计旨在选择覆盖适中数量节点的候选位置进行汇聚节点部署。这将避免汇聚节点处的拥塞,并减少汇聚节点的网络负载。
3. 在簇头选择过程中,大多数研究人员使用聚类中心点来计算节点的中心性[9, 38, 39]。聚类中心点是簇的几何意义上的均值点,并非实际参数。我们不使用中心点来计算节点的中心性,而是通过计算节点到其簇成员的传输距离的平均值,从而找出簇成员中最中心的节点。
4. 在提出的汇聚点选择算法中,汇聚点选择标准从两个角度进行考虑。首先,从节点的角度来看,节点根据其能量水平以及到汇聚节点的通信距离来选择汇聚节点。其次,从汇聚节点的角度来看,考虑上一轮中汇聚节点所处理的负载,以确定非拥塞汇聚点。该提出的汇聚点选择算法基于FLIS,其中设计了27条规则以覆盖大多数关键情况。
本文其余部分组织如下:第2节回顾了相关文献。第3节说明了所提出的系统模型和能耗估计。第4节解释了所提出的方案。第5节给出了仿真结果与讨论。第6节对全文进行总结。
2 文献综述
无线传感器网络协议根据网络架构和应用需求具有特定的特征。无线传感器网络应用的分类可以研究如下 [18]。例如,文献[19, 20]中提出了一种基于无线传感器网络的目标跟踪系统。针对滑坡的关键监测系统和地理空间图像恢复分别在文献[21]和[22],中被提出。文献[23]中提出了一种用于家庭监控系统的多汇聚节点能量高效无线传感器网络。为了实现此类监测系统,重要的是仔细分析应用的特性需求,并据此设计合适的聚类方案。本节从网络的能量效率角度对无线传感器网络协议进行了研究。能量高效无线传感器网络协议的分类如图3所示。无线传感器网络可以是聚类的或非聚类的网络。
2.1 非聚类无线传感器网络
非聚类无线传感器网络是传统无线传感器网络,其中所有传感器节点直接将其数据传输到远程汇聚节点。文献[15]提出了一种支持单一及多汇聚节点的路由协议。作者分析了部署汇聚节点数量对传感器节点能耗的影响。类似地,文献[16, 17]提出了多汇聚点部署协议以优化传感器节点的能量利用。虽然汇聚点布局得到了优化,但汇聚节点数量却是随机选择的,这增加了网络的部署成本。如果此类网络的节点密度较高,则
123
阿拉伯科学与工程杂志
随着无线传感器网络的增加,汇聚节点处可能会出现拥塞问题。为了降低能量消耗,另一种路由协议在[24]中得到了有效实施。该路由减少了直接向汇聚节点传输的数量,但在靠近汇聚节点的区域产生了热点区域。这是因为靠近汇聚节点区域的节点因转发大量数据流量而负载过重。
在[25],中提出了一种单汇聚节点布局策略。该策略采用树形结构将数据路由至汇聚节点。靠近汇聚节点的节点跳数减少,但转发数据的中继节点数量增加。另一种非聚类多汇聚节点部署方案被提出以避免汇聚节点处的拥塞,见[26]。在此方案中,每个节点独立选择非拥塞的汇聚节点进行数据传输。汇聚节点的部署是随机的,因此在密集区域的节点可能需要将数据传输到较远的汇聚节点,以避免附近汇聚节点的拥塞。这最终减轻了拥塞,但在高节点密度情况下增加了节点的通信距离。
2.2 聚类无线传感器网络
聚类算法在过去十年中出现,旨在提高能量受限的无线传感器网络的吞吐量。在环境监测应用中,传感器节点可能被部署在恶劣区域,这会影响节点之间的无线通信链路。无线链路的随机性和气候影响是导致无线传感器网络不确定性的主要原因。模糊逻辑适用于解决此类不确定性。根据所研究的文献,聚类无线传感器网络进一步分为经典聚类方案和模糊聚类方案。涉及汇聚节点部署策略的协议在这两类中也被考虑。
2.2.1 经典聚类方案
聚类最初在LEACH协议[8]中引入。它采用概率方法选择簇头(CL)。该方法未考虑能量参数,因此低能量节点也可能被选为簇头(CL),从而降低了网络寿命。文献[11]解决了孤立节点的问题,其簇头(CL)的选择基于簇的平均能量水平,孤立节点将其数据发送给附近位置的簇头(CL)。在[12],中,针对整体数据传输路径优化了节点的能量利用。节点可能选择较远的簇头(CL)以缩短到汇聚节点的数据传输路径,但这将增加簇头(CL)的负载,并在网络中形成非均匀簇。为了提高能量效率,已开发出多种LEACH变体。文献[27, 28]从能量效率、热点问题、数据聚合以及节点间连接性等方面系统地讨论了这些LEACH变体。
一种在监测区域内并发圆形划分中的扇形簇形成方法在[29]中被提出。汇聚节点位于区域内部中心位置。通过在特定角度方向上移动簇来实现重新分簇。该方案限制了网络区域的扩展,因为远距离节点会过早耗尽能量,从而降低整个网络的寿命。在[30]中提出的一种聚类方案说明了聚类与路由策略之间的相互依赖性。该方案解决了连通性问题。采用泛洪技术传递查询消息以寻找最优路径。转发节点基于静态梯度进行选择。这限制了网络规模和节点密度,以获得最优吞吐量,适用于小规模无线传感器网络。在[31]中提出了一种负载感知的簇头轮换(LAR‐CH)协议。簇的形成基于 k‐means算法。簇头节点因需为下一轮选择簇头而过载。簇头节点还需执行簇分裂算法,当节点能量水平过低无法处理整个簇的数据时。这在网络中形成了非均匀簇。最终导致网络性能下降。
在[32]中提出了两种分布式聚类方案。第一种方案是单跳高效节能聚类协议(SEECP),其中簇头( CL)基于加权概率进行选择。第二种方案是多跳高效节能聚类协议(MEECP),该协议包含数据的簇间路由。在这两种情况下,协议都针对网络的异构特性进行了比较。汇聚节点是无线传感器网络操作的最终目的地和初始化器。由于汇聚节点是高能量设备,部署多汇聚节点有助于延长网络寿命[5, 33]。在[34],中提出了一种具有多汇聚节点的聚类算法。簇头根据其剩余能量进行选择。簇内数据通过簇间路由协议转发给一跳邻居簇头节点。然后汇聚节点被随机选择。路由过程可能
123
阿拉伯科学与工程杂志
表2
无线传感器网络协议比较
| 参考编号 | 方法论 | 聚类方案 | 汇聚节点部署 | 优点 | 缺点 |
| — | — | — | — | — | — |
| [8] | CR节点轮换基于概率模型 | 经典 | 单汇点 | 高效节能的分布式协议;减少的数量传输次数向汇聚节点;简单且临时的节点的配置 | 非由于随机性导致的形成 簇头选择 |
| [9] | 基于FLIS的簇头选择算法 | 模糊 | 单汇点 | 在节点密度方面具有可扩展性 减少 簇通信距离 | 节点孤立问题 常因簇头节点 从高 节点密度区域 |
| [11] | 簇头选择基于簇的平均能量 | 经典 | 单汇点 | 解决节点孤立问题 | 簇的数量不是确定的;方案仅对高运行的节点密度 |
| [12] | 聚类依赖于整体数据传输路径的节点 | 经典 | 单汇点 | 减少整体节点的通信距离 | 可能由于动态数据路由路径形成非均匀簇 |
| [13] | 集式式协议是提出的;簇是基于FCM算法 | 模糊 | 单汇点 | 更适用于关键状态监控(火灾检测应用) | 簇头选择是随机的;在高节点密度下性能下降 高节点密度 |
| [14] | 扩散粒子群基于优化的汇聚点部署算法 | 经典 | 多汇聚节点 | 静态路由减少开销显著;减少的跳数 | 协议仅限于汇聚点部署的情况在监测区域 |
| [22] | 空间信息是使用模糊优化进行聚类并进一步通过模因算法优化 | 经典 | 多汇聚节点 | 提高视觉精度;大数据计算即使对于小的地理空间图像;实时未考虑的场景 | - |
| [29] | 扇形簇 | 汇聚节点位于监测区域中心的区域 | 经典 | 单汇点 | 簇内距离是显著降低 | 汇聚节点拥塞;不可扩展,因为汇聚节点位于区域 |
| [30] | 聚类与路由是基于梯度估计 | 经典 | 单汇点 | 最优路径缩短了通信距离 | 不可扩展;高计算成本 |
| [31] | 簇头节点根据能量和簇负载;簇是基于采用k‐means算法形成的 | 经典 | 单汇点 | 在节点密度;均匀簇被形成 | 簇头节点被随机选择;簇分裂技术可能创建非均匀簇 |
| [34] | 加权概率模型基于能量和距离用于簇头选择 | 基于区域的聚类方法被使用 | 经典 | 多汇聚节点 | 解决能量空洞问题;增强网络寿命 | 如果区域无人值守,所有来自该处的节点区域耗尽;数量汇聚节点未经过优化;它不是通过试验估计实验 |
| [40] | 感知概率模型基于距离被使用选择簇头(CL);簇是基于模糊C均值形成算法 | 模糊 | 单汇点 | 减少簇内距离;增强网络寿命 | 很少有节点过早死亡,原因在于不恰当的簇头选择 |
| [41] | 簇头选择基于FLIS分两个步骤进行两个步骤基于FLIS | 模糊 | 单汇点 | 鲁棒的簇头选择方案;考虑通信和节点的硬件参数 | 生成的CR数量为未优化;非均匀簇形成会降低网络寿命 |
以及在现实场景中出现的不精确网络参数。在这项工作中,使用基于RSS的测距技术来估计通信距离,如 [48]所示。RSS值可能因环境条件而具有不确定性。因此,采用FLIS对这些不确定性进行系统性推断。
网络的能量效率取决于传感器节点的能耗。以下图示表示传感器节点的能量消耗估计。要将k比特的数据传输d米的距离,其能量消耗计算为[26],
$$ ETx(d) = \begin{cases}
k(E_{elect} + E_{fs}d^2), & d < d_{ref} \
k(E_{elect} + E_{mp}d^4), & d \geq d_{ref}
\end{cases} $$
(1)
其中,$ETx(d)$表示节点传输距离为d米时所需消耗的
。$E_{elect}$表示电子电路所需的
。$E_{fs}$和$E_{mp}$分别为自由空间和多径衰落信道模型下功率放大器的
参数。$d_{ref}$是用于区分信号不同信道模型的参考
,其计算公式如下
$$ d_{ref} = \sqrt{\frac{E_{fs}}{E_{mp}}} $$
(2)
接收k比特数据时,能量消耗为
$$ ERx = kE_{elect} $$
(3)
其中$ERx$是接收数据所需的能量。簇头(CL)在将数据传输到汇聚节点之前,将簇内数据聚合为单一数据包。同时,它执行汇聚点选择算法以寻找附近未拥塞的汇聚节点,从而实现成功的数据传输。该过程需要消耗一定的能量。因此,簇头(CL)将簇数据传送到汇聚节点所需的能量消耗为
$$ ECRTx(d) = \begin{cases}
k(E_{elect} + E_p + E_{fs}d^2), & d < d_{ref} \
k(E_{elect} + E_p + E_{mp}d^4), & d \geq d_{ref}
\end{cases} $$
(4)
其中,$ECRTx(d)$表示簇头(CL)在距离为d米时传输数据所需的能量。$E_p$表示簇头处理数据并执行汇聚点选择算法所需的能量。在一个包含N个节点和M个簇的网络中,一次数据传输轮次的总能量消耗估计为
$$ E_{round} = (N - M)(ETx + ERx) + M ECRTx $$
(5)
以下是本研究工作所考虑的假设:
1. 传感器节点在监测区域内随机部署,并在部署后保持静止。
2. 传感器节点本质上是异构的。一部分传感器节点为锚节点,其余为普通节点。锚节点配备有全球定位系统(GPS)。
3. 普通节点的位置假设通过锚节点和某些定位技术进行估计[45]。
4. 所有汇聚节点和Web服务器通过网状拓扑互连。
5. 传感器节点不具有已部署无线传感器网络的全局知识,其功能依赖于局部信息。
6. 传感器节点使用基于接收信号强度(RSS)的测距技术来估计通信距离[48]。
7. 簇头节点与位于其最大传输范围内的汇聚节点进行通信。
3 系统模型
所提出方案的系统模型如图2所示。在Web服务器上,根据网络架构参数执行汇聚节点的最优部署和簇形成。通过迭代滤波模型来估计实现网络完全覆盖所需的最少数量的汇聚点。然后使用FLIS确定该估计数量下的汇聚节点的最优位置。基于FCM算法形成静态簇。该算法是一种无监督方法,可用于聚类、数据分析和模型构建[47]。每个节点在网络中的各个簇中被赋予0到1之间的隶属度。随后,每个节点被分配给隶属度最高的那个簇。
在传感器节点层,进行簇头选择、汇聚节点选择和能耗估计。假设传感器节点配备有模糊控制器,并执行FLIS以实现其簇头和汇聚节点选择功能。FLIS针对系统输入可能遇到的大多数情况具有一系列条件规则。该模糊逻辑特性被用于解决无线链路的随机性问题。
以及在现实场景中出现的不精确网络参数。在这项工作中,使用基于RSS的测距技术来估计通信距离,如 [48]所示。RSS值可能因环境条件而具有不确定性。因此,采用FLIS对这些不确定性进行系统性推断。
网络的能量效率取决于传感器节点的能耗。以下图示表示传感器节点的能量消耗估计。要将k比特的数据传输d米的距离,其能量消耗计算为[26],
$$ ETx(d) = \begin{cases}
k(E_{elect} + E_{fs}d^2), & d < d_{ref} \
k(E_{elect} + E_{mp}d^4), & d \geq d_{ref}
\end{cases} $$
(1)
其中,$ETx(d)$表示节点传输距离为d米时所需消耗的
。$E_{elect}$表示电子电路所需的
。$E_{fs}$和$E_{mp}$分别为自由空间和多径衰落信道模型下功率放大器的
参数。$d_{ref}$是用于区分信号不同信道模型的参考
,其计算公式如下
$$ d_{ref} = \sqrt{\frac{E_{fs}}{E_{mp}}} $$
(2)
接收k比特数据时,能量消耗为
$$ ERx = kE_{elect} $$
(3)
其中$ERx$是接收数据所需的能量。簇头(CL)在将数据传输到汇聚节点之前,将簇内数据聚合为单一数据包。同时,它执行汇聚点选择算法以寻找附近未拥塞的汇聚节点,从而实现成功的数据传输。该过程需要消耗一定的能量。因此,簇头(CL)将簇数据传送到汇聚节点所需的能量消耗为
$$ ECRTx(d) = \begin{cases}
k(E_{elect} + E_p + E_{fs}d^2), & d < d_{ref} \
k(E_{elect} + E_p + E_{mp}d^4), & d \geq d_{ref}
\end{cases} $$
(4)
其中,$ECRTx(d)$表示簇头(CL)在距离为d米时传输数据所需的能量。$E_p$表示簇头处理数据并执行汇聚点选择算法所需的能量。在一个包含N个节点和M个簇的网络中,一次数据传输轮次的总能量消耗估计为
$$ E_{round} = (N - M)(ETx + ERx) + M ECRTx $$
(5)
以下是本研究工作所考虑的假设:
1. 传感器节点在监测区域内随机部署,并在部署后保持静止。
2. 传感器节点本质上是异构的。一部分传感器节点为锚节点,其余为普通节点。锚节点配备有全球定位系统(GPS)。
3. 普通节点的位置假设通过锚节点和某些定位技术进行估计[45]。
4. 所有汇聚节点和Web服务器通过网状拓扑互连。
5. 传感器节点不具有已部署无线传感器网络的全局知识,其功能依赖于局部信息。
6. 传感器节点使用基于接收信号强度(RSS)的测距技术来估计通信距离[48]。
7. 簇头节点与位于其最大传输范围内的汇聚节点进行通信。
4 所提出的方案
该提出的方案包含两个阶段,如图4所示。在初始设置阶段,Web服务器执行汇聚节点的最优部署和簇形成。此阶段仅在方案开始时执行一次。传输阶段以轮次形式周期性进行。每个簇通过FLIS分布式地选择一个簇头(CL)。所有簇成员将其感知数据传输给各自的簇头(CL),然后进入睡眠模式,直到接收到下一轮的信标报警。随后,簇头节点执行基于FLIS的汇选择算法,选择一个附近的非拥塞汇聚点。各簇头节点随后将簇内数据转发至所选的汇聚节点。这两个阶段将在以下小节中详细说明。
4.1 初始设置阶段
传感器节点在监测区域中随机部署,且具有异构性。在该方案中,总节点中有0.1比例为锚节点,这些锚节点已知其地理位置。网络中其余的普通节点被认为可通过锚节点及某些定位技术[45, 49]来确定自身位置。同时假设,通过一些轨迹辅助汇聚节点[19]将节点的位置信息收集到Web服务器。随后,Web服务器依次计算汇聚节点的最优数量以及估计数量下的最优位置,并执行簇形成。
4.1.1 用于确定最优汇聚点数量的迭代过滤模型
所提出的迭代滤波模型估计了对给定监测区域实现完全覆盖所需的最小汇聚节点数量。设在Web服务器上收集的节点位置用矩阵X表示。
$$ X = {x_1, x_2,…, x_a,…, x_N} $$
(6)
其中,X 是存储节点位置的矩阵,这些位置由二维坐标表示。N 是网络中的节点总数。xa 表示第a个节点的位置。一组可能的候选汇聚点位置被先验地固定,以限定监测区域。这些位置的位置由矩阵Y 表示
$$ Y = {y_1, y_2,…, y_b,…, y_U} $$
(7)
其中,Y是存储所有可能的候选汇聚点位置的矩阵。U是候选汇聚点位置的总数。yb是第b个候选位置的位置。计算每个节点xa与所有U个候选汇聚点位置之间的距离。如果节点xa与候选位置yb之间的距离小于该节点的最大传输范围,则称该节点xa被该位置yb所覆盖。这意味着,若将汇聚节点放置在位置yb,则该节点具有传输数据的潜在汇聚节点;否则,该节点未被覆盖。部分节点可能被多个候选汇聚点位置所覆盖。
这里,我们定义三个集合Y′ V和Z。Y ′是候选汇聚点位置中已确定的汇聚点位置的集合,即Y ′ ⊆Y。初始时,X中的所有节点均未被覆盖,且已确定的汇聚节点集合Y′为空。集合Z初始为空,并在迭代过程中填入被覆盖的节点。另一个集合V由Y导出,表示每个候选位置yb下所覆盖节点的集合。其表示为
$$ V = {V(y_b)|y_b \in Y} $$
(8)
其中,V(y_b) 是位于位置yb的最大传输范围内的节点集合。V 是集合对于所有V(y_b)的候选位置数量U。从集合V中选择一个集合V(y_b),使得该集合V(y_b)包含最大数量的被覆盖节点。将该选定集合对应的候选位置yb移至集合Y′,并将V(yb)中相应的被覆盖节点移至集合Z。某些节点可能被多个候选汇聚点位置所覆盖,因此,添加到集合Z中的节点需从各个V集合中移除。在下一次迭代中,选择下一个具有最多被覆盖节点数的V(y_b)。此过程不断迭代,直到所有节点都被移至集合Z,从而确保以最少数量的汇聚点实现网络的全面覆盖,该结果由 ∣ ∣Y ′ ∣∣给出。因此,通过迭代过滤被覆盖节点,最终得到所需的最少数量的汇聚点。
4.1.2 基于FLIS的最优汇聚节点位置识别
一旦获得最少数量的汇聚节点,Web服务器将执行 FLIS,以从给定的候选位置中估算最优位置。所建模的FLIS如图5所示。Mamdani推理逻辑系统用于模糊化,质心法用于去模糊化。该系统具有两个模糊输入和一个模糊输出。第一个模糊输入是候选位置与其所覆盖的所有节点之间的平均距离(AD)。传输距离是能量消耗的主要原因,因此将AD作为输入之一。它由三个语言变量——较少、中等和远——来描述。这些语言变量的特性在表3中定义。第二个模糊输入是邻近密度比(NDR)。它是某个候选位置所覆盖的节点数量与网络中节点总数之比。它表示与汇聚节点相关的节点密度。如果密度过高,可能会导致汇聚节点处发生拥塞。因此,NDR也被视为输入之一。它同样由三个语言变量——低、中、高——来描述。这些语言变量也在表3中描述。
模糊输出是位置选择因子(PSF)。它由四个语言变量定义——非常低、低、高和非常高。PSF的隶属函数如图6所示。PSF的范围为0到1。梯形隶属
 | |||SinkDeployment
| |||SinkDeployment
(Mamdani)||| | —|—|—|—|—|—| | 广告(3)|广告(3)|广告(3)|SinkDeployment
(Mamdani)||| | 广告(3)|广告(3)|广告(3)|SinkDeployment
(Mamdani)||| | 广告(3)|广告(3)|广告(3)|SinkDeployment
(Mamdani)||| | 广告(3)|广告(3)|广告(3)|SinkDeployment
(Mamdani)||| | |||9条规则||| | |||9条规则||| | |||9条规则||| | |||9条规则|PSF(4)|PSF(4)| | |||||)
表3
用于FLIS中最佳汇聚点位置选择的模糊输入描述
| 模糊输入 | 语言学变量 | 类型 | 成员资格函数的传播 | 成员资格函数 |
| — | — | — | — | — |
| AD | Less | 梯形 | [0, 0, 10, 30] | |
| AD | 中等 | 梯形 | [10, 30, 60, 80] | |
| AD | 远 | 梯形 | [60, 80, 150, 150] | |
| NDR | Low | 梯形 | [0, 0, 0.1, 0.4] | |
| NDR | 中 | 梯形 | [0.2, 0.4, 0.6, 0.8] | |
| NDR | High | 梯形 | [0.6, 0.9, 1, 1] | |
隶属度函数用于表示PSF的最小和最大范围。中间范围使用三角函数定义,以获得精确的输出。
表4
用于汇聚节点位置选择的If‐Then规则集
| 规则编号 | 模糊输入 AD | 模糊输入 NDR | 模糊输出 PSF |
| — | — | — | — |
| 1 | Less | Low | Low |
| 2 | Less | 中 | High |
| 3 | Less | High | 非常高 |
| 4 | 中等 | Low | 非常低 |
| 5 | 中等 | 中 | Low |
| 6 | 中等 | High | High |
| 7 | 远 | Low | 非常低 |
| 8 | 远 | 中 | Low |
| 9 | 远 | High | High |
模糊输出通过如果-那么规则与输入相关联。输出使用质心法进行去模糊化[41]。每个模糊输入由三个语言变量定义,因此总共可以得到9种输入组合。这些规则的设定原则是:具有最小化平均距离和中等节点密度的候选汇聚节点位置应具有更高的PSF值。规则如表4所示。
从FLIS获得的所有PSF值的集合中, ∣ ∣Y ′ ∣∣个PSF被迭代地选出。 ∣ ∣Y ′ ∣∣是通过第4.1.1节中讨论的迭代滤波方法得到的。在每次迭代中,选择具有最高PSF的候选位置作为最终汇点位置,并将其对应的PSF值置为零。因此,在下一次迭代中,将选择下一个PSF最高的候选位置。因此,对于给定的无线传感器网络,在监测区域中选择最优数量的汇聚节点并将其部署在最优位置上。
4.1.3 基于模糊C均值的簇形成
在计算出最优汇聚节点数量及其位置后,将汇聚节点部署在网络中。所有汇聚节点随后广播SINK_HELLO数据包以启动通信。这是一种包含Sink ID的简短激活数据包。节点接收到这些数据包后,利用基于RSS的测距技术[48]估算其到各汇聚节点的距离,并向最近的汇聚节点发送NODE_INFO数据包进行响应。该数据包包含节点ID及其位置信息。基于节点位置, Web服务器执行FCM算法,形成具有最小化簇内距离的节点簇。在Web服务器上集中执行簇形成更加现实且可行,即使在可扩展网络中也是如此,因为信息是在网络中的多个汇聚节点之间交换的。
使用FCM算法将N个传感器节点划分为M个簇。该算法首先设置M个随机聚类中心点,然后对N个节点位置进行处理迭代考虑每个节点,以计算其对每个簇中心点的隶属度。隶属度的取值范围为0到1。然后以优化目标函数至最小收敛阈值的方式移动聚类中心点。根据节点与各簇中心点之间的距离,分配该节点相对于所有簇中心点的隶属度。以下是FCM算法的数学描述。在 Web服务器上收集的N个节点位置为二维坐标,表示为(N ×2)矩阵
$$ P = {p_1, p_2,...., p_i,…, p_N} $$
(9)
其中P是存储所有N个节点位置的矩阵。pi表示第i个节点的坐标。M个随机中心点由(M ×2)矩阵表示
$$ Q = {q_1, q_2,...., q_j,…, q_M} $$
(10)
矩阵Q存储迭代过程中的M个簇中心点。qj表示第j个中心点的当前位置。这些值在每次迭代中都会发生变化,以最小化目标函数。使用矩阵P和Q计算每个节点与M个簇中心点之间的距离。这些距离随后用于构建该算法的目标函数。
$$ F_{obj} = \sum_{i=1}^{N} \sum_{j=1}^{M} (W_{ij})^\alpha d(p_i, q_j)^2 $$
(11)
其中$F_{obj}$是当前迭代的目标函数。值$W_{ij}$表示第i个传感器节点相对于第j个中心点的隶属度。隶属度以 α,表示,该值为模糊因子,取值范围为1到∞。项$d(p_i,q_j)$表示第i个传感器节点到第j个中心点的距离。隶属度矩阵 $W_{ij}$和迭代中心点$q_i$的计算公式如下
$$ W_{ij} = \frac{1}{\sum_{k=1}^{M} \left( \frac{|p_i - q_j|}{|p_i - q_k|} \right)^{\frac{2}{\alpha - 1}}}, \quad i = 1, 2,…, N \text{ and } j = 1, 2,…, M $$
(12)
$$ q_j = \frac{\sum_{i=1}^{N} W_{ij}^\alpha p_i}{\sum_{i=1}^{N} W_{ij}^\alpha}, \quad j = 1, 2,…, M $$
(13)
为了使算法输出收敛到最优值,需在每次迭代中使用(12)和(13)对目标函数$F_{obj}$关于$W_{ij}$和$q_j$求偏导数。$q_k$是上一次迭代中估计的第j个簇的聚类中心点。(12)的分母使用上一次迭代中估计的簇中心点集合来计算。在每次迭代中,算法在计算成员资格度时需遵循以下条件:
$$ \sum_{j=1}^{M} W_{ij} = 1, \quad i = 1, 2,…, N $$
(14)
$$ 0 \leq W_{ij} \leq 1, \quad i = 1, 2,…, N \text{ and } j = 1, 2,…, M $$
(15)
节点具有与所有M个簇中心点相关的隶属度。这种隶属度分为三种表示方式——零隶属度、完全隶属度和部分隶属度。完全隶属度意味着该节点非常接近簇中心点。为了便于数学计算,零隶属度值设为0,完全隶属度值设为1,如公式(15)所示。分配方式使得单个节点对所有簇中心的隶属度之和等于1,如公式(14)所示。节点将与其隶属度最高的簇中心点相关联,从而确保每个节点仅关联到一个簇中心点。每次迭代都会计算算法的收敛改进,并与最小收敛阈值进行比较。当达到最小收敛阈值或最大迭代次数时,FCM算法停止。收敛改进是当前$F_{obj}$值与上一次$F_{obj}$值之间的差值。FCM算法的整体功能总结于表5。
表5
FCM算法
| 步骤 | 描述 |
| — | — |
| 1 | 初始化M个聚类中心点 |
| 2 | 计算每个节点对每个聚类中心点的隶属度$W_{ij}$ |
| 3 | 更新聚类中心点$q_j$ |
| 4 | 计算目标函数$F_{obj}$的收敛改进 |
| 5 | 若收敛改进小于最小收敛阈值或达到最大迭代次数,则停止;否则返回步骤2 |
簇形成后,Web服务器向所有汇聚节点发送 CLUSTER_INFO数据包。共形成了M个簇,因此生成了M个CLUSTER_INFO数据包。这些数据包包含簇ID和相应的簇成员ID。所有汇聚节点将CLUSTER_INFO数据包多播到网络中。采用多播的原因是每个节点仅接收发往自身的CLUSTER_INFO数据包,并丢弃其他数据包。这避免了节点在接收无关数据包时的能量浪费。每个节点从此数据包中获知其所属的簇ID以及簇成员的节点ID。在初始设置阶段结束时,节点虽然没有关于部署的无线传感器网络的全局信息,但已知晓其簇ID和簇成员ID。随后,每个节点多播 NODE_HELLO数据包,以与其簇成员进行通信。在接收到NODE_HELLO数据包后,每个节点利用接收信号强度(RSS)计算其到所有簇成员的距离。这些距离信息将在簇头选择过程中被使用。所提出的方案中使用的信令数据包列于表6中。
表6
所提出的方案中使用的信令数据包
| 信令分组 | 分组内容 | 节点操作 | 分组 |
| — | — | — | — |
| SINK HELLO | Sink ID | 来自汇聚节点的接收 | |
| NODE_INFO | 节点ID, node位置 | 向…传输 sink | |
| CLUSTER INFO | 簇ID,关联的节点ID | 来自汇聚节点的接收 | |
| NODE HELLO | 簇ID,簇集群成员ID | 由…进行的收发节点 | |
| SINK INFO | Sink ID,sink负载在上一轮 | 来自汇聚节点的接收 | |
| NODE CRSF | 节点ID,节点的CR选择因子(CRSF) | 由…进行的收发节点 | |
4.2 传输阶段
该阶段在连续的轮次中进行。所有汇聚节点广播SINK_INFO数据包以启动每一轮次。该数据包包含Sink ID以及汇聚节点在上一轮中的网络负载。所有节点在其最大传输范围内接收来自汇聚节点的SINK_INFO数据包。每个节点从这些数据包中获取汇聚节点负载的值。对于第一轮,所考虑的汇聚节点负载是在初始设置阶段观察到的负载。每个节点还根据接收信号强度(RSS)计算其到汇聚节点的距离。传输阶段包含两个过程:簇头选择和汇聚节点选择。在每一轮中,使用FLIS从每个簇中选出一个簇头[51]。然后每个簇头执行基于FLIS的汇选择算法,为其簇的数据传输寻找附近的非拥塞汇聚点。这两个过程将在以下小节中详细阐述。
4.2.1 基于FLIS的簇头选择
用于簇头选择的FLIS如图7所示。它有两个模糊输入——能量比(ER)和距离比(DR)。节点的能量是一个关键参数,必须加以保护以延长节点的寿命。如果选择一个能量较低的节点作为簇头,则该节点无法长时间持续工作。因此,将节点的能量作为一个输入考虑。ER是节点的剩余能量与其初始能量的比率,其公式为
$$ ER = \frac{E_{remain}}{E_{initial}} $$
(16)
| ||||簇头选择
(Mamdani)||| | —|—|—|—|—|—|—| | ER(3)|ER(3)|ER(3)|ER(3)|簇头选择
(Mamdani)||| | ER(3)|ER(3)|ER(3)|ER(3)|簇头选择
(Mamdani)||| | ER(3)|ER(3)|ER(3)|ER(3)|簇头选择
(Mamdani)||| | ||||9条规则||| | ||||9条规则||| | ||||9条规则||| | ||||9条规则||| | ||||9条规则|CRSF(6)|CRSF(6)| | ||||||)
表7
FLIS中用于簇头选择的模糊输入描述
| 模糊输入 | 语言变量 | 类型 | 成员资格函数的传播 | 成员资格函数 |
| — | — | — | — | — |
| ER | Low | 梯形 | [0, 0, 0.1, 0.4] | |
| ER | 中 | 梯形 | [0.1, 0.4, 0.6, 0.9] | |
| ER | High | 梯形 | [0.6, 0.9, 1, 1] | |
| DR | Less | 梯形 | [0, 0, 5, 15] | |
| DR | 中等 | 梯形 | [5, 15, 30, 40] | |
| DR | 远 | 梯形 | [30, 40, 88, 88] | |
其中$E_{remain}$是节点的剩余能量。$E_{initial}$的值取决于节点的类型(普通节点或锚节点)。ER是取值在0到1之间的比率。ER由三个语言变量定义——低、中和高。每个语言变量的特性列于表7中。
第二个模糊输入是DR。它是节点与其关联的簇成员之间计算出的距离的平均值。每个节点都会收到来自其所有簇成员的NODE_HELLO数据包。节点根据接收信号强度(RSS)计算其到每个簇成员的距离。该节点的DR值被表述为
$$ DR = \frac{\sum_c d(c)}{n} $$
(17)
其中n是与该节点相关联的簇成员数量。DR是节点与其簇成员之间的距离之和与n的比率。如果DR值较高,则表示该节点远离其簇成员;相反,如果DR值较少,则表示该节点位于其簇成员的大致中心区域。
DR值决定了节点的中心性,而无需像其他算法那样估计簇的中心点[9, 38, 39]。节点不了解全局信息,因此在本地估计簇中心点将增加计算和能量开销。相反,采用了一种更实际的方法,其中节点的中心性是基于节点之间的距离来计算的,而不是从节点到簇中心的距离。簇本身是静态的,但当节点因能量完全耗尽而失效时,n的值会发生变化。估计距离是近似值,因为它们基于RSS。DR的最大范围被认为是$d_{ref}$,如公式(2)中所计算。它是信号在自由空间中可以传播的最大距离。DR由三个语言变量定义——较少、中等和远。每个语言变量的特性如表7所示。
模糊输出为簇头选择因子(CRSF)。CRSF由六个语言变量定义,这些变量由三角形隶属函数定义,如图8所示。三角形隶属函数在CRSF的某一范围内没有恒定的隶属度值。这使得CRSF发生微小变化时,隶属度产生较大差异。因此,能够精确比较不同的 CRSF,从而实现合适的簇头选择。这些隶属函数用六个等级L1到L6表示。L1表示覆盖CRSF最低值的范围,而L6表示覆盖最高值的范围。其他等级位于L1和L6之间。CRSF的取值范围为0到1。
在该FLIS中,每个输入由三个语言变量定义。因此,共推导出九条模糊规则,使得具有高能量且更靠近簇中心的节点被赋予更高的CRSF值。这些规则列于表8中。每个节点计算其CRSF,并通过NODE_CRSF将其值多播给其簇成员
表8
簇头选择的If–Then规则集
| 规则编号 | 模糊输入 ER | 模糊输入 DR | 模糊输出 CRSF |
| — | — | — | — |
| 1 | High | Less | L6 |
| 2 | High | 中等 | L5 |
| 3 | High | 远 | L4 |
| 4 | 中 | Less | L5 |
| 5 | 中 | 中等 | L4 |
| 6 | 中 | 远 | L3 |
| 7 | Low | Less | L3 |
| 8 | Low | 中等 | L2 |
| 9 | Low | 远 | L1 |
数据包。该数据包包含节点ID及其CRSF值。节点随后将自身的CRSF与接收到的簇成员的CRSF进行比较。具有最高CRSF的节点宣布自己为当前轮次的簇头(CL),并为从簇成员进行数据收集安排时分多址(TDMA)时隙。簇成员在其指定的时隙中传输其感知数据,消耗的能量如(1)所示,然后切换到睡眠模式。每个簇头(CL)接收其所有簇成员的数据。它将接收到的数据聚合为单一数据包。该数据包将被传输至汇聚节点。
4.2.2 基于FLIS的汇选择算法
一旦簇头节点收集了簇内数据,每个簇头节点会对其最大传输范围内的所有汇聚节点执行FLIS。用于汇聚节点选择的 FLIS如图9所示。该系统具有三个模糊输入——能量比率( ER)、汇聚节点距离(SD)和汇聚节点负载(SL)。ER通过公式(16)计算得出,其特性与表7中所列相似。
第二个模糊输入是SD。它是簇头(CL)与汇聚节点之间的通信距离。考虑该参数的原因是,通信的能量消耗主要取决于发送端和接收端之间的距离[52]。簇头通过SINK_INFO数据包的接收信号强度(RSS)来计算距离。然后,它计算其最大传输范围内所有S个汇聚节点的SD。其计算公式如下:
$$ SD(s) = \frac{d(s)}{d_{max}}, \quad 1 \leq s \leq S $$
(18)
其中$d(s)$是簇头与sth个汇聚节点之间的距离。$d_{max}$是节点的最大传输范围。SD(s)是相对于sth个汇聚节点计算的归一化汇聚节点距离。由于仅当汇聚节点位于$d_{max}$范围内时才计算SD,因此不同簇头的S值可能不同。SD的取值范围为0到1。SD由三个语言变量定义——低、中和高。各语言变量的特性如表9所示。
| ||汇聚节点选择
(Mamdani)||| | —|—|—|—|—| | 能量比率 (3)|能量比率 (3)|汇聚节点选择
(Mamdani)||| | 能量比率 (3)|能量比率 (3)|汇聚节点选择
(Mamdani)||| | ||汇聚节点选择
(Mamdani)||| | ||汇聚节点选择
(Mamdani)||| | 标准差
(3)|标准差
(3)|27条规则||| | 标准差
(3)|标准差
(3)|27条规则||| | 标准差
(3)|标准差
(3)|27条规则|SSF(4)|SSF(4)|)
表9
汇聚节点选择中FLIS所用模糊输入的描述
| 模糊输入 | 语言变量 | 类型 | 成员资格函数的传播 | 成员资格函数 |
| — | — | — | — | — |
| SD | Low | 梯形 | [0, 0, 0.1, 0.25] | |
| SD | 中 | 梯形 | [0.15, 0.25, 0.4, 0.5] | |
| SD | High | 梯形 | [0.4, 0.55, 1, 1] | |
| SL | 轻 | 梯形 | [0, 0, 0.1, 0.25] | |
| SL | 中等 | 梯形 | [0.15, 0.25, 0.4, 0.5] | |
| SL | 重 | 梯形 | [0.4, 0.55, 1, 1] | |
第三个模糊输入是SL。它是汇聚节点在上一轮中的网络负载。该值从SINK_INFO数据包中提取。如果汇聚节点的网络负载大于其容量,则数据包将被丢弃,这会导致簇头向汇聚节点重传数据,从而浪费簇头的能量。因此,该输入用于识别拥塞的汇聚节点。假设每个节点只有一个数据包。簇头将所有数据包聚合为单一帧。因此,从簇头到汇聚节点的一次传输计为一个数据帧。在汇聚节点处,通过将接收到的节点数据包数量与网络中的节点总数之比来估计SL。每个汇聚节点在每一轮中计算其SL,并在下一轮的信标中通知节点。因此,节点不计算SL,而是直接在算法中使用该值。SL由三个语言变量定义——轻、中等和重。每个语言变量的特性如表9所示。
模糊输出是汇聚节点选择因子(SSF)。SSF由四个语言变量定义——非常低、低、高和非常高。SSF的隶属度函数如图10所示。SSF的范围为0到1。
模糊输出通过如果-则规则映射到输入。每个输入由三个语言变量定义,因此共推导出27条模糊规则。这些规则基于节点和汇聚节点的感知。考虑节点的能量及其到汇聚节点的距离,以便节点能够以最小通信距离进行数据传输。如果节点能量较少,则优先选择最近汇聚点,而不考虑汇聚点的拥塞程度。若高能量节点发现较近的汇聚节点处于拥塞状态,则会将其数据路由至另一个远距离的非拥塞汇聚点。规则列于表 10中。每个簇头(CL)计算其最大传输范围内所有汇聚节点的SSF,并选择SSF最高的汇聚节点进行簇内数据传输。至此完成一轮数据传输。
表10
用于汇聚节点选择的If‐Then规则集
| 规则编号 | 模糊输入 ER | 模糊输入 SD | 模糊输入 SL | 模糊输出 SSF |
| — | — | — | — | — |
| 1 | Low | Low | 轻 | High |
| 2 | Low | Low | 中等 | Low |
| 3 | Low | Low | 重 | 非常低 |
| 4 | Low | 中 | 轻 | Low |
| 5 | Low | 中 | 中等 | 非常低 |
| 6 | Low | 中 | 重 | 非常低 |
| 7 | Low | High | 轻 | Low |
| 8 | Low | High | 中等 | 非常低 |
| 9 | Low | High | 重 | 非常低 |
| 10 | 中 | Low | 轻 | High |
| 11 | 中 | Low | 中等 | High |
| 12 | 中 | Low | 重 | Low |
| 13 | 中 | 中 | 轻 | High |
| 14 | 中 | 中 | 中等 | High |
| 15 | 中 | 中 | 重 | Low |
| 16 | 中 | High | 轻 | High |
| 17 | 中 | High | 中等 | Low |
| 18 | 中 | High | 重 | 非常低 |
| 19 | High | Low | 轻 | 非常高 |
| 20 | High | Low | 中等 | 非常高 |
| 21 | High | Low | 重 | High |
| 22 | High | 中 | 轻 | 非常高 |
| 23 | High | 中 | 中等 | 非常高 |
| 24 | High | 中 | 重 | High |
| 25 | High | High | 轻 | High |
| 26 | High | High | 中等 | High |
| 27 | High | High | 重 | Low |
4.3 部署成本
传感器节点是部署在监测区域内的不可更换设备。部署成本取决于设备的数量和类型[53, 54]。因此,本小节对无线传感器网络的一次性部署成本投入进行了研究。该无线传感器网络由普通节点、锚节点和汇聚节点组成。这些节点具有异构性,且具有不同的初始能量水平。节点的部署成本定义为
$$ D_{cost_n} = C_{Equip_n} + C_{Opr_n} $$
(19)
$$ D_{

















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









