






Treebert:一种基于树的编程语言预训练模型
TreeBERT: A Tree-Based Pre-Trained Model for Programming Language
Accepted for the 37th Conference on Uncertainty in Artificial Intelligence (UAI 2021).
arXiv:2105.12485v2 [cs.LG] 15 Jul 2021

Abstract
源代码可以根据定义的语法规则解析为抽象语法树(AST)。然而,在预训练中,很少有工作考虑将树结构结合到学习过程中。在本文中,我们提出了一个基于树的预训练模型TreeBert,用于改进面向编程语言的生成任务。为了利用树结构,Treebert将代码对应的AST表示为一组合成路径,并引入节点位置嵌入。该模型采用树屏蔽语言模型(TMLM)和节点顺序预测(NOP)相结合的混合目标来训练。TMLM使用一种根据树的特征设计的新颖的掩蔽策略来帮助模型理解AST并推断AST的缺失语义。利用NOP,Treebert通过学习AST中节点的顺序约束来提取句法结构。我们在涵盖多种编程语言的数据集上预先训练了Treebert。在代码摘要和代码文档任务上,Treebert优于其他预先训练的模型和为这些任务设计的最先进的模型。此外,Treebert在转换到预先训练的未见编程语言时表现良好。
1 INTRODUCTION
随着诸如Bert[Devlin et al.,2019]的预训练模型的发展,在许多自然语言处理任务上已经实现了最先进的性能。使用预先训练的模型减少了下游任务的预算,同时实现了高精度和快速的训练速度。自然语言处理(NLP)中预训练模型的成功也推动了编程语言(PL)预训练模型的出现,如Cubert[Kanade et al.,2020]和Codebert[Feng et al.,2020],它们通过预训练任务学习通用代码表示,然后使用它们来增强面向PL的下游任务,如代码摘要和代码分类。
然而,现有的面向PL的预训练模型面临两个主要挑战。
1)设计用于学习程序句法结构的适当机制。面向PL的预训练模型都采用类似自然语言的处理方式,将代码建模为单词序列,并且只考虑代码的语言性质。然而,代码也是强结构化的,并且代码的语义依赖于要表示的具有不同语法结构的程序语句和表达式的组合。因此,不能忽视程序的结构特征。通常,可以根据定义的语法规则将代码片段解析为唯一对应的抽象语法树(AST)。先前的工作[Rabinovich et al.,2017,Mou et al.,2016]已经注意到AST在程序表示中的关键作用。然而,用于预训练模型的标准变压器[Vaswani et al.,2017]架构不能利用树结构。如何使用AST作为预训练模型的输入是一个具有挑战性的问题。
2)探索树形结构的预训练任务。现有的面向PL的预训练模型直接遵循NLP预训练任务。将面向序列的任务直接应用于非序列结构的AST存在一些不恰当的应用。因此,应该为树设计新的预训练任务,以便预训练的模型能够从AST中提取句法和语义信息。
在本文中,我们提出了一种基于树的编程语言预训练模型TreeBert。Treebert遵循Transformer编码器-解码器架构。为了使转换器能够利用树结构,我们将代码片段对应的AST表示为根节点到终端节点路径的集合,然后引入节点位置嵌入来获得节点在树中的位置。我们提出了一种适用于AST学习句法和语义知识的混合目标,即树屏蔽语言建模(TMLM)和节点顺序预测(NOP)。在TMLM中,我们设计了一种新的屏蔽策略来屏蔽编码器和解码器的输入,在编码器端输入具有屏蔽节点的AST路径集合,并在解码器端使用AST中的上下文信息来预测完整的代码片段。由于路径中节点的顺序表达了程序结构信息,NOP通过预测节点是否无序来提高模型捕获句法结构信息的能力。因此,Treebert可以通过微调应用于广泛的面向PL的生成任务,而无需对特定任务架构进行大量修改。
我们的贡献概述如下:
- 我们提出 treebert 一个面向 pl 的基于树的预训练模型。Treebert 对多种编程语言数据集进行了预训练,可以进行微调以提高面向 pl 的生成任务的准确性。我们的源代码和模型可在 https://github.com/17385/treebert 上找到。
- 我们将AST表示为一组组成路径,并引入节点位置嵌入。我们提出了树结构的混合目标,包括TMLM和NOP。前者设计了一种新的掩蔽策略来帮助模型理解AST和推断语义。后者可以提取更多的程序语法结构特征。
- 我们在Python、Java和C#数据集上进行了大量实验,以验证Treebert在代码摘要和代码文档方面实现了最先进的性能,并更好地推广到另一种在预训练阶段尚未出现的编程语言。
2 MOTIVATION
在本节中,我们描述了我们提出Treebert的动机,包括程序语法结构和预训练任务。
1.程序语法结构
程序语法结构Cubert[Kanade et al.,2020]首次尝试对源代码的Bert上下文嵌入进行预训练,并展示了其在五个分类任务上的有效性。Codebert[Feng et al.,2020]是第一个能够处理编程语言(PL)和自然语言(NL)的双模态预训练模型。使用混合目标函数对其进行训练,包括标准屏蔽语言建模[Devlin等人,2019]和替换标记检测[Clark等人,2020],以在NL-PL理解任务(例如,代码检索)和生成任务(例如,代码文档)中实现最先进的性能。然而,Cubert和Codebert都完全基于序列。他们从序列中学到的知识并不充分,因为他们没有考虑到程序中句法结构信息的学习。此外,Codebert指出,与使用AST相比,使用代码序列会导致部分精度损失。Hu等人[2018]使用线性遍历方法将AST表示为序列。勒克莱尔等人[2019]将代码中的标记与AST中的代码结构相结合。Alon等人[2019]将给定的代码片段表示为AST中K对随机终端节点之间的路径集,这使得他们的模型在代码摘要和代码字幕任务中优于其他最先进的技术。这些任务特定的非预训练模型中的每一个都表明,与顺序表示相比,基于树的表示可以有效地从源代码中提取信息。
Transformer [Vaswani等人,2017]在NLP任务上展示了强大的特征学习能力,并且使用大量数据进行预训练的策略已经成功。解决如何使变压器利用树结构是使预训练模型能够学习语法结构的第一步。Sun等人[2020]试图通过将结构卷积子层添加到前几个变压器解码器块来解决这个问题。TreeBERT使用从根节点到终端节点的路径集来序列化AST,而不是更改变压器结构。与其他遍历方法(如前序遍历)相比,此方法唯一地表示树。我们还引入了节点位置嵌入,它获取层次信息和节点的父节点和兄弟节点的相对位置信息。这些操作确保变压器最大限度地利用树中的所有信息。
2.预训练任务
训练前的任务对于学习语言的类属表征是至关重要的。在自然语言处理中,掩蔽语言建模[Devlin et al.,2019]、下一句预测[Devlin et al.,2019]、句子顺序预测[Lan et al,2020]、替换标记检测[Clark et al,2020]、置换语言建模[Yang et al。这些特别设计的预训练任务使模型能够使用大量数据来学习输入句子的每个成员的上下文相关表示,从而使模型隐式地学习语言中的一般知识。
Cubert和Codebert的预训练任务遵循NLP的预训练任务。这些预训练任务是为序列设计的,而非序列结构的AST具有比序列更复杂的结构。需要为AST设计预训练任务以有效地学习代码表示。我们的工作基于MASS[Song et al.,2019]和T5[Raffel et al.,2020]中使用的SEQ2SEQ MLM,并已证明有利于SEQ2SEQ风格的下游任务。具体来说,我们设计TMLM。考虑到AST路径中节点的重复性和终端节点的重要性,我们采用了一种新的屏蔽策略来屏蔽AST中的节点和代码片段中的令牌。编码器的输入是屏蔽的AST路径集合,解码器的输出是预测的完整代码片段,便于Treebert理解AST并推断缺失的语义。此外,为了学习AST中的节点顺序约束,例如,“if”节点后面必须跟着“body”节点,我们开发了NOP来捕获关于程序的底层句法结构的更多信息。
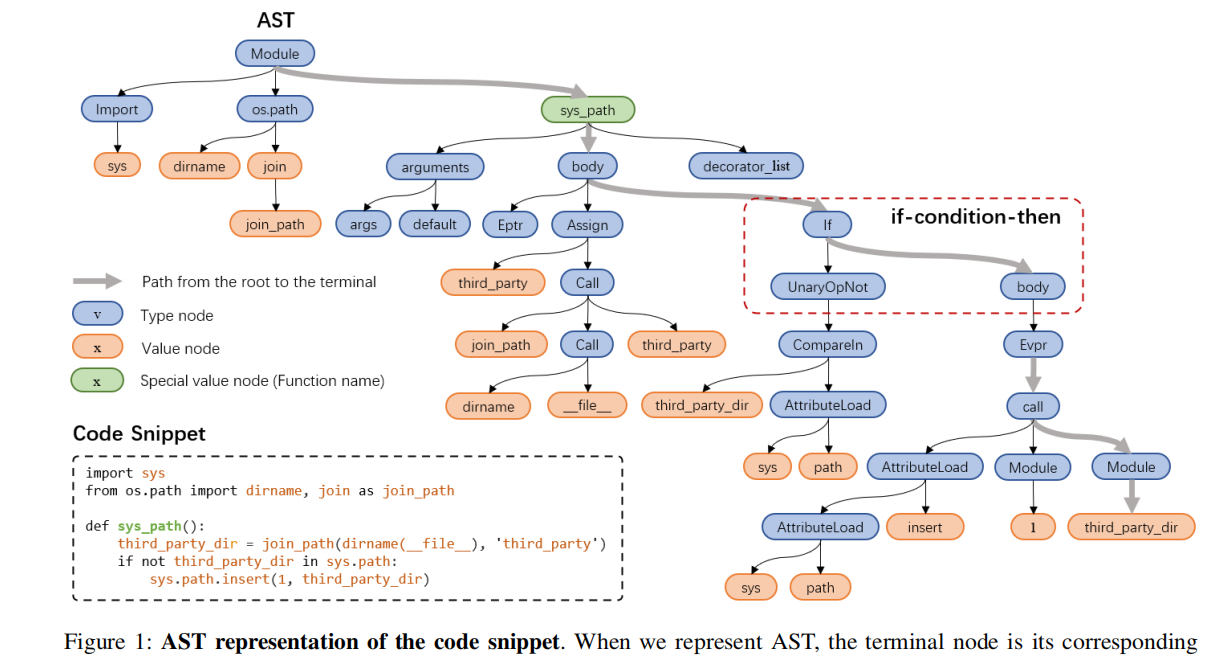
图1:代码片段的AST表示。当我们表示AST时,终端节点是其对应的值属性,非终端节点是其对应的类型属性,除了充当非终端节点但使用值属性的函数名。
3 提出的模型
在本节中,我们将描述TreeBERT的细节,包括模型体系结构、输入表示和TreeBERT所使用的训练前任务。
3.1 模型架构
Treebert的模型架构基于Vaswani等人描述的基于转换器的编码器-解码器的原始实现。[2017].我们省略了变压器架构的详细描述,因为变压器的使用已经非常广泛[Dong等人,2019,Lan等人,2020,Liu等人,2019]。我们的模型修改了变压器的编码器侧,只添加了一个完全连接的层来调整输入的维度。
3.2 输入表示
在训练前阶段,我们将输入设置为相应的AST中的一组组成路径,并给定一个代码片段。在添加节点位置嵌入后,连接路径中的所有节点嵌入来表示路径。解码器侧的输入是经过令牌化后从代码片段中获得的令牌序列。特别是,AST中的值节点和代码片段中的标记节点可以通过对子单词嵌入的求和来表示。
3.2.1 AST表示
每个代码片段都被转换为一个AST,如图1所示,它以树的形式显示了程序的语法结构。树中的每个节点都表示代码中的一个结构。例如,一个条件跳转语句,如if-条件-那么,可以用一个有两个分支的节点来表示。
AST节点分为两类:AST类型节点,如“参数”和“Eptr”,记为v;AST值节点(即代码中的标记),如“sys_path”和“join_path”,记为x。请注意,值节点几乎都是终端节点。我们使用从根节点到终端节点的路径集来表示AST,A={p1、p2、···、pN},其中N是AST中包含的路径数。
3.2.2 Code Representation
将AST对应的代码片段分成一系列令牌,在开头和结尾分别添加令牌[LT]和[CLS],即C=[LT]、x1、x2、x2、...,xM、[CLS],其中[LT]为[LT]的表示向量,[CLS]为[CLS]的表示向量,M为代码片段的长度。C将被用作解码器的输入,如图2所示。[EOS]是解码器侧的句尾标识符。[LT]不仅作为解码器侧的句开头标识符,而且它的值表示目标编程语言的类型,例如,当语言类型为Python时,[LT]=[PLT],当语言类型为Java时,[LT]=[JLT],当解码器生成的语言在训练前阶段看不到时,[LT]=[UNK]。这是因为当代码片段转换为AST时,不同类型语言的实现细节会被隐藏。我们需要提示模型的语言类型,以学习不同编程语言之间的差异。[CLS]用作NOP的聚合表示。
3.2.3 Path Representation
每个路径都是一个节点序列,![]() ,其中路径的终端节点
,其中路径的终端节点![]() 是相应代码片段中的一个标记,L是路径的长度。我们连接路径中的节点向量来表示路径
是相应代码片段中的一个标记,L是路径的长度。我们连接路径中的节点向量来表示路径
![]()
请注意,路径集合中的路径表示向量之间没有顺序关系。因此,与标准变压器不同的是,我们的模型编码器侧没有添加位置编码来为路径向量分配位置信息的向量,而是在形成节点表示时使用节点位置嵌入的方法来添加树中节点的位置信息。
3.2.4 Token Representation
程序中大量的用户定义的标识符通常会导致词汇表外的标记或稀疏向量表示。为了缓解这个问题,我们使用字节对编码(BPE)[Sennrich等人,2016]从AST中的值节点中学习最常见的子标记,并将其切片,例如,“third_party”可能被切成“third”、“_”、“party”。跟随Alon等人。[2019],我们使用构成每个标记的所有子标记的向量和来表示完整的标记。
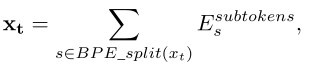
其中,![]() 子标记是一个学习到的嵌入矩阵来表示每个子标记。AST中类型节点数量固定且小,通过嵌入将其表示为实值向量。
子标记是一个学习到的嵌入矩阵来表示每个子标记。AST中类型节点数量固定且小,通过嵌入将其表示为实值向量。
为了训练更通用的预训练模型,我们共享Python和Java的词汇和权重。这种方法可以减少整体词汇量大小,最大化语言之间的令牌重叠,从而提高模型的跨语言性能[Conneau and Lample,2019, Devlin et al.,2019, Lample et al.,2018]。
3.2.5 Node Position Embedding
为了获得AST中节点的相对位置信息,我们将嵌入到节点编码器侧的节点位置中。
节点的位置嵌入是其父节点的位置嵌入及其相应的级别嵌入的线性组合。有H+1级嵌入作为参数,即![]() ,其中H为树的高度。我们使用
,其中H为树的高度。我们使用![]() 作为根节点的父位置嵌入。如果j级有一个节点的位置嵌入为
作为根节点的父位置嵌入。如果j级有一个节点的位置嵌入为![]() ,有c个子节点,则其第i个子节点的位置嵌入为
,有c个子节点,则其第i个子节点的位置嵌入为
![]()
而![]() 是可学习的权重矩阵。节点位置嵌入可以获得节点的父节点和兄弟节点的层次信息和相对位置信息。
是可学习的权重矩阵。节点位置嵌入可以获得节点的父节点和兄弟节点的层次信息和相对位置信息。
节点位置嵌入的优点是较少的参数(实验中约1/200的学习位置嵌入[Gehringetal.,2017])和可推性。如果使用n个参数,学习到的位置嵌入可以编码n个节点,而节点位置嵌入为高度为n-1的树中的所有节点,其数量远远大于n。学习到的位置嵌入为每个位置分配不同的权重矩阵作为参数,但无法放大。与学习到的位置嵌入相比,节点位置嵌入允许模型推断出比训练过程中遇到的节点更多的节点。
3.3 PRE-TRAINING TASKS
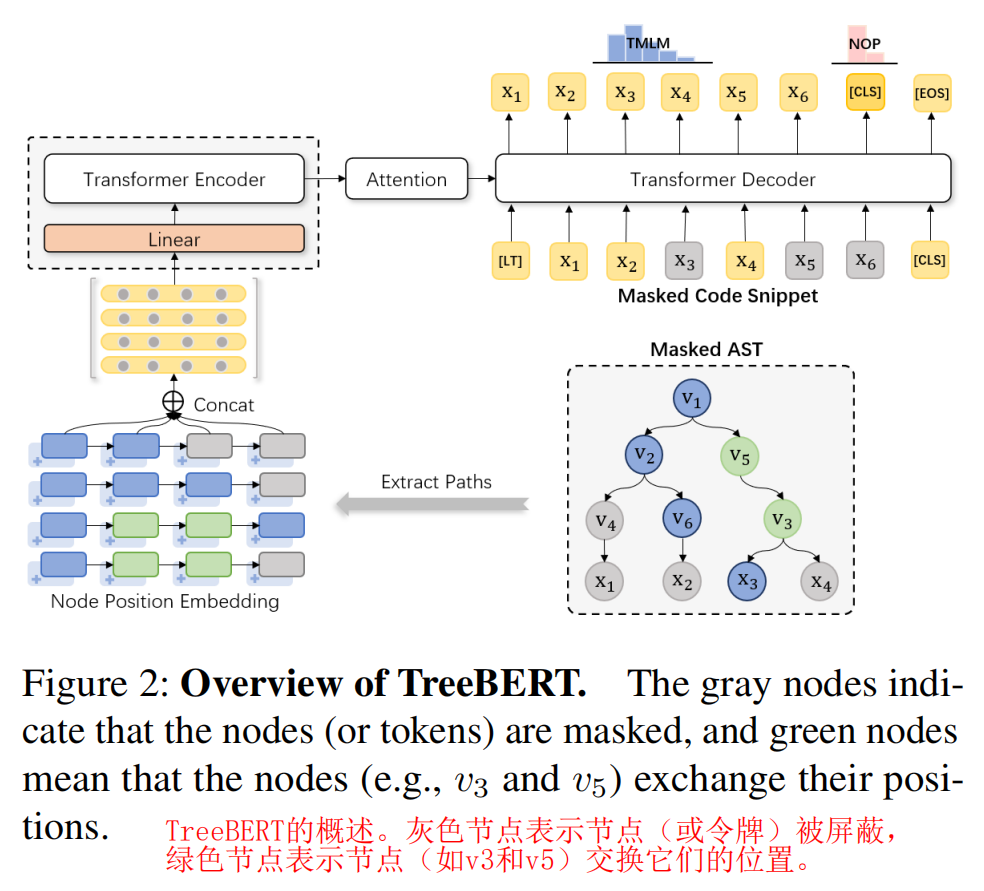
我们设计了两个任务,TMLM和NOP,用于训练TreeBERT。Seq2SeqMLM在之前的研究中已被证明是有效的[Song等人,2019,Raffel等人,2020]。我们通过将Seq2SeqMLM扩展到AST来设计TMLM。NOP考虑AST中的节点顺序约束来进一步提取程序结构信息。这两个训练前的任务如图2所示。
3.3.1 Tree Masked Language Modeling (TMLM)
给定一个AST代码片段对(A,C),我们提出了一种屏蔽AST中的节点和代码片段中的令牌的策略。
在编码器端,我们首先根据概率![]() 的分布对路径pi中的节点进行采样,并使用TOPK()操作选择概率较高的前k个节点
的分布对路径pi中的节点进行采样,并使用TOPK()操作选择概率较高的前k个节点![]() ,然后替换路径中的节点圆周率与一个特殊的令牌[mask]来获得
,然后替换路径中的节点圆周率与一个特殊的令牌[mask]来获得![]()
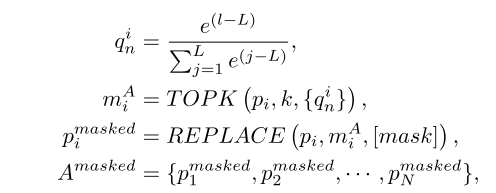
其中![]() 为掩蔽路径集,l为当前节点级别,L为路径中的最大节点级别,N为AST中包含的路径数,i=1···N。请注意,系统将减去L,以防止数字溢出。这确保了路径中级别较大的节点被屏蔽的可能性更高。
为掩蔽路径集,l为当前节点级别,L为路径中的最大节点级别,N为AST中包含的路径数,i=1···N。请注意,系统将减去L,以防止数字溢出。这确保了路径中级别较大的节点被屏蔽的可能性更高。
TMLM 以更高的概率掩蔽了路径中更接近终端的节点。主要原因是1)由于每条路径都是从根节点到终端节点的,因此节点与根节点越近,在路径集中重复的次数就越多。如果我们使用标准的MLM掩蔽策略,那么许多相同类型的节点都会被掩蔽。重复学习这类节点的表示方式会损害模型的性能。2)AST的终端节点通常是指用户定义的值,它们表示代码中具有丰富含义的标识符和名称。因此,更频繁地屏蔽这些节点可以迫使我们的模型学习它们的表示。
在解码器侧,解码器的输入![]() 是通过根据以下等式掩蔽代码片段中的令牌而获得的:
是通过根据以下等式掩蔽代码片段中的令牌而获得的:

式中,![]() 是需要在代码段中屏蔽的集合
是需要在代码段中屏蔽的集合![]() 的元素。
的元素。
我们保留与M^A中的值节点相对应的令牌,并屏蔽代码片段C中的其他节点。这样,通过进行下一个令牌预测,TMLM可以强制解码器依赖于AST的特征表示,而不是代码片段中的前一个令牌。
图2中示出了一个示例。在AST中,根据上述策略,对于四条路径要被屏蔽的节点的集合是M^A1={v4,x1}、M^A2={x2}、M^A3={}和M^A4={x4}。在代码片段中,给出了路径中的屏蔽值节点x1,x2,x4,并屏蔽了其他节点,即M^C={X3,X5}。解码器需要预测完整的代码片段x1,x2,X3,x4,X5,x6。
在TMLM中,编码器读取屏蔽AST路径集,然后解码器推断与AST对应的代码段。值得注意的是,当代码转换为AST时,一些语义信息被隐藏,例如“+”、“>”、“<=”和其他二进制运算符在AST中使用“BinOpSub”节点表示。在这种情况下,如果解码器被设计为预测AST,则上述语义信息将被忽略。因此,我们设计解码器来预测代码片段,以鼓励模型推断此类语义信息,从而增强其在下游任务中的泛化能力。MTLM的目标函数如下所示:
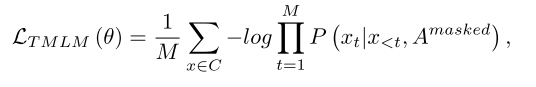
其中,m是代码段的长度,X是代码段中的标记。
总之,TMLM可以强制编码器理解AST并推断隐藏在AST中的语义信息。它还鼓励解码器从编码器中提取信息,以帮助进行代码段预测,从而实现编码器-解码器框架的联合训练
3.3.2 Node Order Prediction 节点顺序预测 (NOP)
TMLM能够学习丰富的语义知识。为了进一步提高从程序中提取语法结构信息的能力,我们设计了二值化预训练任务NOP。
AST中节点的顺序有一些隐式约束。以图1中的路径“模块 ->· · · -> if->body->EXEXR ->· · · -> third_party_dir”为例,“if”节点下面必须有一个“body”节点,“body”节点必须有一个“在它下面的"节点"。为了捕获这种语法结构信息,我们以一定的概率决定是否随机交换路径中一些节点的位置,然后训练模型来区分AST中节点的顺序是否正确。如图2所示,我们交换节点v3和v5的位置。[CLS]的隐藏向量将被完全连接的层压缩到1维,然后通过Sigmoid函数获得AST路径中存在无序节点的概率![]() 。NOP的目标函数如下:
。NOP的目标函数如下:

其中,当AST具有无序节点时,y取值为1,否则为0。
由于TMLM和NOP起着不同的作用,我们采用超参数α来调整损失函数。
![]()
4 EXPERIMENTS
在本节中,我们首先介绍TreeBERT的预训练设置。然后,我们提供了一些生成任务的精调TreeBERT结果。最后,进行消融研究来评估TreeBERT各种成分的有效性。
4.1 PRE-TRAINING
1.Pre-training Data
我们使用的预训练数据集是由Cubert发布的Python和Java语料库。已删除微调数据集中的重复数据。Python数据集由720万个Python文件组成,其中包含超过20亿个令牌,这些令牌被处理为具有大约5亿条路径和70亿个节点的AST。Java数据集由1410万个Java文件组成,其中包含大约45亿个令牌,这些令牌被处理为包含大约11亿条路径和165亿个节点的AST。
2.Training Details
TreeBERT将编码器层(即变压器块)的数量设置为6,隐藏大小设置为1024,自我关注标题的数量设置为8。解码器使用与编码器相同的设置。对于预训练,根据数据集的统计信息,最大路径数、最大节点数和最大代码长度分别设置为100、20和200。我们采取了32KBPE合并操作。我们使用Adam[Kingma和Ba,2015],其学习率为{1e-3,1e-4,1e-5},β1=0.9,β2=0.999,L2权重衰减为0.01,学习率在前10%的步骤中预热,之后线性衰减。我们使用GELU激活,批次大小为{2048, 4096, 8192}。我们还在所有层上应用了0.1 Dropout[Srivastava等人,2014]。在TMLM中,每个路径随机掩蔽15%的节点。在NOP中,每个AST有50%的机会交换一对节点。
我们用不同的权重α(0.25, 0.5, 0.75, 1)值训练TreeBERT,并在代码摘要和代码留档两个下游任务中测试TreeBERT的性能。结果表明,TreeBERT的性能随着α值的增加而提高,在0.75时表现最佳,但当α值进一步增加时,模型性能开始恶化。因此,我们将损失函数中的权重α设置为0.75。
4.2 FINE-TUNING
为了验证TreeBERT的有效性,TreeBERT针对两代任务进行了优化,并与基线进行了比较。生成任务是代码摘要和代码留档。我们还评估了TreeBERT在C# 数据集上的性能,并通过实验证明TreeBERT可以很好地推广到预训练阶段没有见过的编程语言。
4.2.1 Code Summarization
代码摘要是指预测给定函数体的函数名,它可以粗略地描述函数并帮助程序员命名函数。
1.Datasets and Training Details
在代码摘要任务中,我们评估Python和Java数据集上的TreeBERT,其中Python数据集使用ETH Py150[Raychev等人,2016],Java数据集[Allamanis等人,2016]使用Java small、Java med和Java large。补充材料中提供了数据集的统计信息。
我们将学习率和批量大小分别设置为1e-5和64。我们使用Adam update参数,将历元数设置为100。如果模型性能在几个时期内没有改善,我们将提前结束培训,并选择验证集中损失最低的模型进行后续评估。
2.Model Comparison
选择的比较基线是基于序列的转换器[Vaswani等人,2017年]、基于图形的Graph2Seq[Xu等人,2018年]、基于AST的Code2Seq[Alon等人,2019年]、以及基于AST和sequencebased的Code+Gnn+GRU[LeClair等人,2020年]。Transformer在翻译任务方面取得了最先进的性能。Graph2Seq介绍了一种新的图到序列神经编码器-解码器模型,该模型将输入图映射到向量序列,并使用基于注意的LSTM从这些向量解码目标序列。Code2Seq将代码片段表示为AST中终端节点之间的k路径,并在解码时注意选择相关路径。Code+Gnn+GRU使用ConvGNN处理AST,并将ConvGNN编码器的输出与Code-token编码器的输出相结合。
还将TreeBERT与其他预训练模型进行了比较,即NL导向的质量(Le=6,Ld=1024,A=8)和PL导向的CuBERT(Le=24,H=1024,A=16)以及CodeBERT(Le=12,H=768,A=12),其中Le是编码器层的数量,Ld是解码器层的数量,H是隐藏的大小,A是自我注意头的数量。我们使用与TreeBERT相同的参数设置和预训练数据重新训练质量。此外,我们使用CuBERT和CodeBERT的参数初始化变压器的编码器。在本任务中,我们使用三个指标评估每个模型的性能:精确度、召回率和F1分数,这是计算方法的补充材料。

表1列出了代码摘要任务的结果,补充材料中显示了数据的可视化。Treebert的表现明显优于其他模型,包括在所有四个数据集上进行预训练和未进行预训练的模型。Graph2Seq、Code2Seq和Code+GNN+GRU优于Transformer,这些结果表明基于树或基于图的表示在从代码中提取信息方面比序列更有效。在使用代码数据集重新训练后,MASS的性能优于预先训练的模型Cubert和Codebert,这表明联合编码器-解码器训练提高了生成能力。然而,MASS的性能不如CODE+GNN+GRU,后者是专门为此任务设计的。与MASS相比,Treebert更多地使用了代码的语法结构,其性能优于CODE+GNN+GRU。
在F1评分方面,与最佳基线Code+Gnn+GRU相比,TreeBERT在小型数据集上表现更好,在Java小型数据集上相对提高了7.95%。在较小的ETH Py150数据集上,TreeBERT实现了13.29%的相对改进。相对差异随着数据集的变大而变小,但在Java大数据集上仍实现了2.45%的相对改进。这些结果表明,TreeBERT在没有注释数据的情况下表现更好,并且随着数据大小的增加,它更具鲁棒性。
4.2.2 Code Documentation
代码文档是指为代码生成注释,通过阅读注释而不是代码本身来理解代码的功能。
1.Datasets and Training Details
我们使用DeepCom[Hu等人,2018]提供的Java数据集来优化TreeBERT。由于存在一些无法转换为AST的代码,原始数据集的大小减小。补充资料中提供了已处理数据集的统计信息。
在本实验中,我们将学习率和批量大小分别设置为3e-5和64,并采用Adam优化器和提前停止。最后,我们在验证集上选择性能最好的模型。
2.Model Comparison
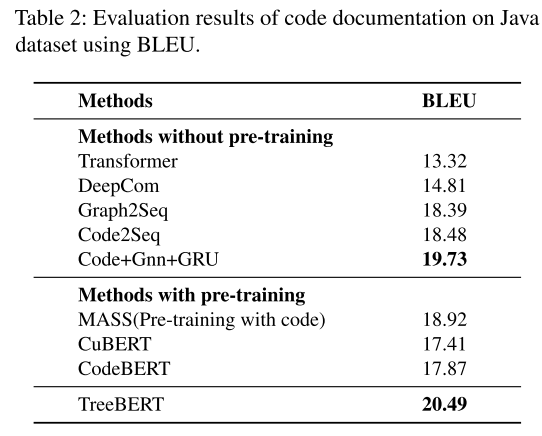
在代码文档任务中,我们使用与代码摘要相同的基线,但添加了与DeepCom的比较,DeepCom提出了一种AST遍历方法,该方法将AST转换为序列,以训练代码文档任务的seq2seq模型。与DeepCom一样,我们在本实验中采用BLEU作为度量,其计算在补充资料中进行了描述。
表2显示了代码文档任务的结果。TreeBERT的BLEU分数为20.49,比Transformer高7.17分。在这个任务中,Transformer产生的结果非常差,因为与没有预训练的其他方法相比,Transformer停留在浅文本标记级别,因此忽略了对程序重要的信息。变压器是从零开始训练的,其性能不如预训练的方法,这证明预训练的模型可以学习有价值的信息。由于使用AST对编码器-解码器进行联合训练,因此与其他基线相比,TreeBERT的性能显著提高。
4.2.3 Generalization to Programming Language not Seen during Pre-training 推广到预训练未看到的编程语言
我们现在评估TreeBERT在训练前阶段看不到的编程语言上的性能。我们使用CodeNN的[Iyer等人,2016] c# 数据集,其中包含关于从StackOverflow中获得的c#语言的编程问题和答案。数据集的统计数据在补充材料中提供。在这项任务中,我们将TreeBERT与CodeNN、MASS、CuBERT和CodeBERT进行了比较。此外,我们使用BLEU度量和与代码文档中使用的相同的超参数来评估模型。

表3显示了TreeBERT在 c# 数据集上的性能。实验结果表明,TreeBERT对训练前阶段没有的语言泛化良好。具体来说,TreeBERT通过微调实现了BLEU的17.94,比作者引入数据集的CodeNN好3.76分。我们认为TreeBERT可以很好地推广到新语言中,因为TreeBERT可以很好地推广到新语言中。
4.3 ABLATION STUDY 消融研究
为了更好地理解不同成分和掩蔽策略在模型中的作用,我们进行了广泛的消融研究。我们以不同的方式改变模型,并衡量每个变体的性能变化。该实验在以下场景下的Java代码文档任务数据集上进行。

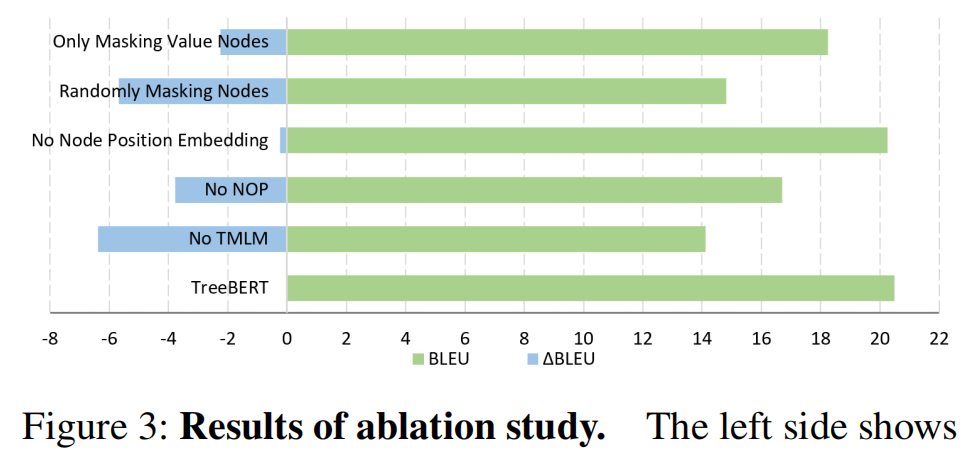
图3:消融研究结果。左侧显示BLEU值的损失,右侧显示总BLEU值。
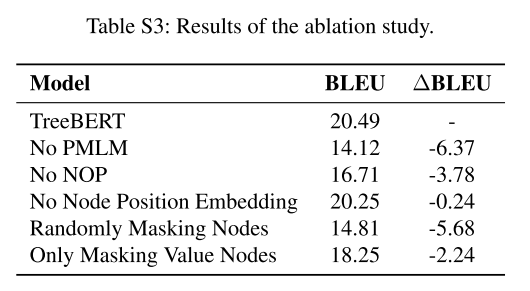
消融研究的详细结果见补充材料。 图3的实验结果表明,当TMLM缺失时,该模型损失的BLEU最多,可以证明其在TreeBERT中的重要作用。 虽然 NOP 缺失时损失较小,但 NOP 捕获的句法结构信息是必不可少的。 当我们使用节点位置嵌入而不是学习位置嵌入时,结果表明我们获得了与学习位置嵌入相当甚至更高的结果。 值得一提的是掩蔽策略在 TMLM 中的巨大作用。 如果使用MLM随机掩码策略,模型性能会很差,结果几乎和没有TMLM的差不多,因为掩码的大部分节点都是重复的AST非终端类型节点,导致大量的code token没有被 参与预训练,不利于代码中关键语义信息的提取。 值节点代表丰富的语义,但如果所有被屏蔽的节点都是值节点,则会造成一些损失。 这表明屏蔽少量类型节点是有用的,我们假设这种方法可用于提取结构信息并有助于提高模型的性能。
5 CONCLUSION
在本文中,我们提出了一种面向pl的基于树的预训练模型TreeBERT。为了学习使用AST的代码表示,TreeBERT使用AST的组成路径集作为输入,引入节点位置嵌入,然后使用混合目标训练模型,包括TMLM和NOP。实验结果表明,TreeBERT在代码摘要和代码文档任务方面取得了最先进的性能,并在转移到训练前看不见的编程语言时表现良好。为了进一步研究TreeBERT各部分的作用,我们进行了一项广泛的消融研究。
TreeBERT仍有相当大的改进空间。首先,TreeBERT不仅可以用于诸如代码摘要和代码文档等任务,还可以用于任何源语言构建为AST的任务中。我们将继续探索将TreeBERT应用于更多的PL任务的可能性。其次,我们将进一步改进TreeBERT,例如,通过向AST添加更多的程序信息,或同时使用AST、图、序列等多模态形式,从而从不同的角度提取有关程序的信息,从而使TreeBERT能够更好地解决PL下游任务。
补充材料
在本补充材料中,我们首先在A部分介绍了代码标记化。其次,我们在B部分提供了用于实验的数据集的详细统计信息。然后,我们在C部分描述了用于评估Treebert的指标。最后,我们在D部分展示了一些实验的详细结果。
A: CODE TOKENIZATION 代码标记化
由于代码的强结构,缩进在Python中是有意义的,不能简单地通过拆分代码来删除。遵循[Rozière et al.,2020],我们使用INDENT和DEDENT代替缩进来指示代码块的开始和结束。"NEWLINE"用于表示换行符。字符串中的空格被替换为“_”,代码注释被删除。一个处理过的Python代码片段的示例如图S1所示。

B: DATA STATISTICS
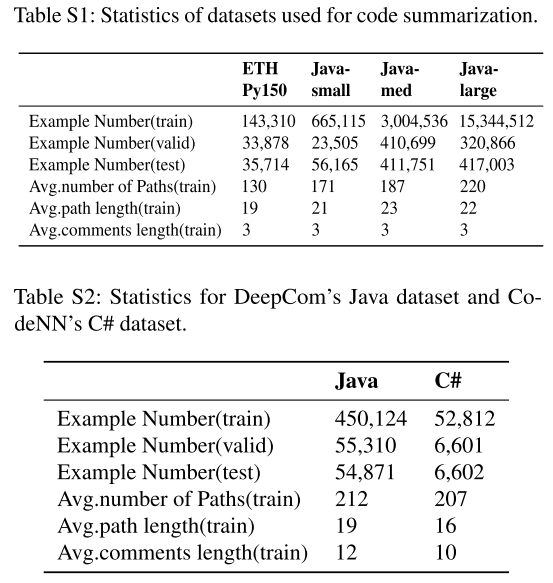
表S1显示了用于代码摘要的四个数据集的详细统计数据,即ETH PY150 (1)、Java-Small (2)、Java-Med (3)和Java-Large (4) 。表S2显示了两个数据集的详细统计数据,一个是来自DeepCom[Hu et al.,2018]的Java DataSet (5),用于代码文档,另一个是来自Codenn[Iyer et al.,2016]的C# DataSet (6),用于评估模型在预训练未知语言上的性能。
1 https://www.sri.inf.ethz.ch/py150
2 https://s3.amazonaws.com/code2seq/datasets/java-small.tar.gz
3 https://s3.amazonaws.com/code2seq/datasets/java-med.tar.gz
4 https://s3.amazonaws.com/code2seq/datasets/java-large.tar.gz
5 https://github.com/xing-hu/DeepCom/blob/master/data.7z
6 https://github.com/sriniiyer/codenn/tree/master/data/stackoverflow/csharp
C: EVALUATION METRICS
在本节中,我们将详细介绍代码摘要中使用的精确度、召回率和F1分数的计算,以及代码文档中使用的BLEU。
Precision,Recall,F1-Score 在代码摘要中,我们不使用Accuracy和Bleu,因为生成的函数名由子令牌组成,并且相对较短(平均长度为3个子令牌)。继Alon等人之后[2019].,我们使用精确度、召回率和F1作为指标。计算如下。

当预测的子标记在函数名中时,我们将其视为一个正正例(TP)。当预测的子标记不在函数名中时,我们将其视为假正例(FP)。当子标记在函数名中,但未被预测时,我们将其视为假反例(FN)。标签“UNK”被算作FN;因此,对这个词的预测会降低召回值。
BLEU BLEU分数可用于在句子级测量生成的注释和参考代码注释之间的相似性,其计算方法如下。
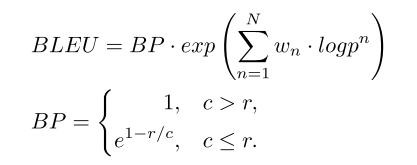
其中取N的上限为4,即最多计算4克,![]() ,pn为候选项中长度为n的子句与参考项中长度为n的子句的比值。
,pn为候选项中长度为n的子句与参考项中长度为n的子句的比值。
在简洁性惩罚(BP)中,r表示参考注释的长度,c表示模型生成的注释的长度。
D: MORE EXPERIMENTAL RESULTS
图S2显示了代码摘要的F1分数的可视化结果。表S3给出了消融研究的详细结果。
















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









