






学更好的别人,
做更好的自己。
——《微卡智享》

本文长度为17309字,预计阅读5分钟
前言
上一篇《pyTorch入门(一)——Minist手写数据识别训练全连接网络》搭建了全连接层和训练的文件,做了一个最简单的Minist训练,最终的训练结果达到了97%,这篇就来介绍一下pyTorch网络层比较常用的Api和卷积层

| # | 常用网络层函数 |
|---|---|
| nn.Linear | 对信号进行线性组合 |
| nn.Conv2d | 对多个二维信号进行二维卷积 |
| nn.MaxPool2d | 对二维信号进行最大值池化 |
| nn.ReLU | 最常用的激活函数 |
| nn.CrossEntropyLoss | 损失函数,瘵nn.LogSoftmax()与nn.NLLLoss()结合,进行交叉熵计算 |
| optim.SGD | 优化器,随机梯度下降法 |
| optim.zero_grad | 清空所管理的参数梯度(张量梯度不自动清零,而是累加) |
| optim.step | 更新一次权值参数 |
| nn.Sequential | 用于按顺序包装一层网络层 |
上面几个是用到最多的函数,我们Minist训练用这几个就足够完成了,重点介绍下几个需要输入参数的函数:
nn.Linear(参数) 对信号进行线性组合
-
in_features:输入节点数
-
out_features:输出节点数
-
bias :是否需要偏置
nn.Conv2d(参数) 对多个二维信号进行二维卷积
-
in_channels:输入通道数
-
out_channels:输出通道数,等价于卷积核个数
-
kernel_size:卷积核尺寸
-
stride:步长
-
padding :填充个数
-
dilation:空洞卷积大小
-
groups:分组卷积设置
-
bias:偏置
nn.MaxPool2d(参数) 对二维信号进行最大值池化
-
kernel_size:池化核尺寸
-
stride:步长
-
padding :填充个数
-
dilation:池化核间隔大小
-
ceil_mode:尺寸向上取整
-
return_indices:记录池化像素索引
optim.SGD(参数) 优化器,随机梯度下降法
-
params:管理的参数组
-
lr:初始学习率
-
monentum:动量系数,β
-
weight_decay:L2正则化系数
-
nesterov:是否采用NAG
nn.Sequential(参数) 按顺序包装一组网络层
-
顺序性:各网络层之间严格按照顺序构建
-
自带forward():自带的forward里,通过for循环依次执行前向传播运算

微卡智享
卷积层网络
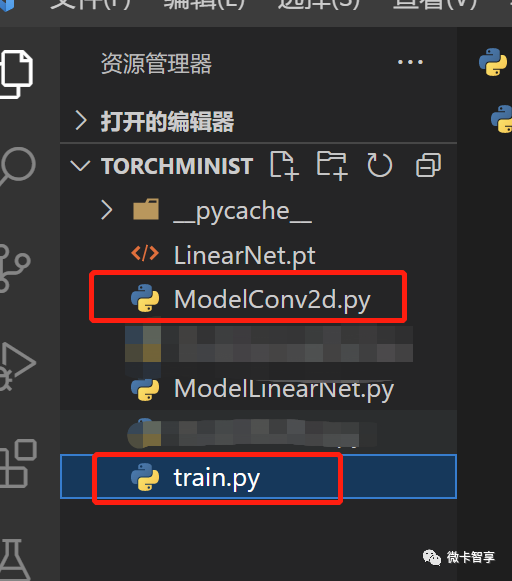
上图中,我们将上一篇里ministmodel.py改为为train.py了,因为整个是训练文件,这样标识还比较清晰一点,然后新建一个ModelConv2d.py的文件。
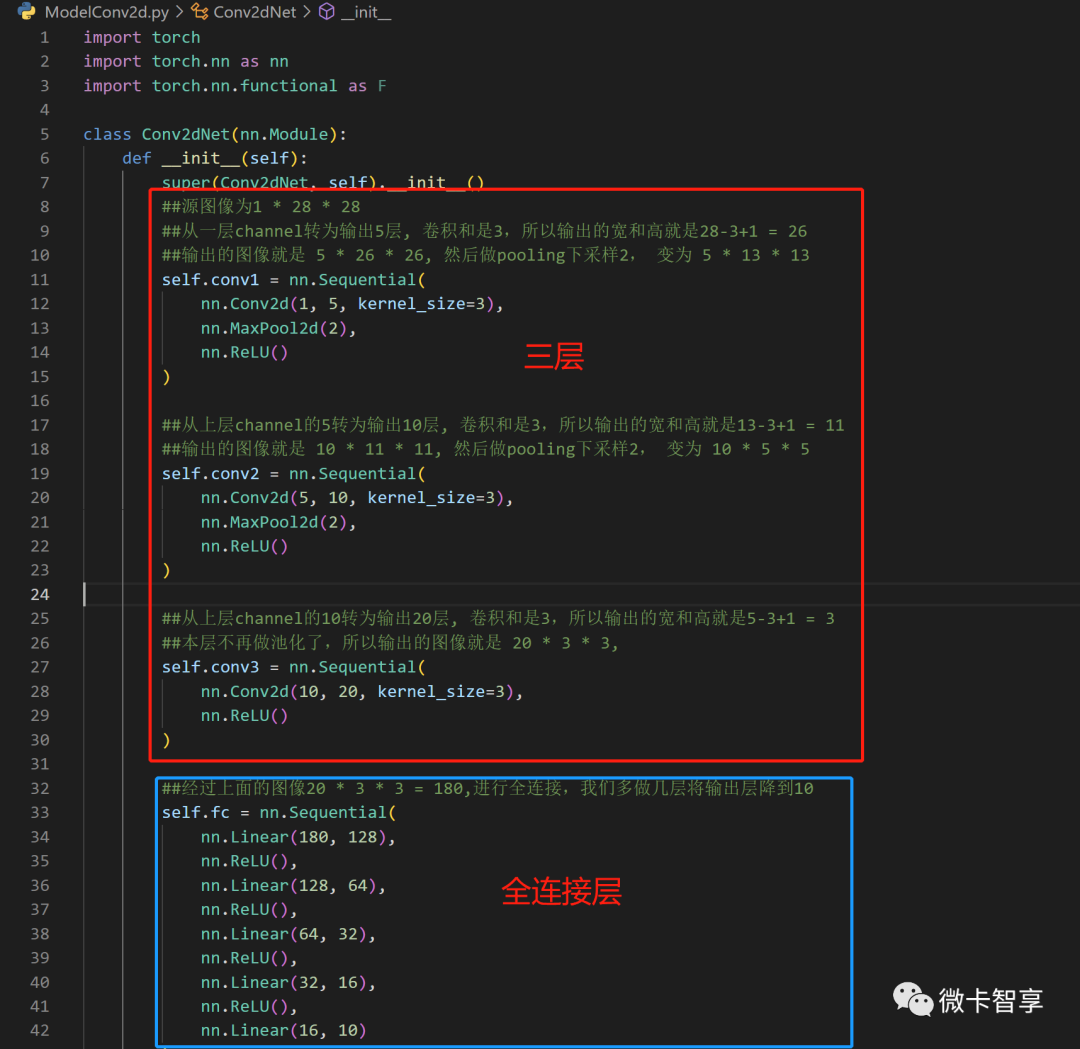
设置Conv2dNet的网络结构,从上图中可以看出,我们做了三层,每层的顺序都是先用3X3的卷积核处理,然后池化,再激活,经过三层处理后再用全连接从180的输入降到最终10,这里全连接层里面用了5次降下来的,可以减少这里的次数。
ModelConv2dNet.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class Conv2dNet(nn.Module):
def __init__(self):
super(Conv2dNet, self).__init__()
##源图像为1 * 28 * 28
##从一层channel转为输出5层, 卷积和是3,所以输出的宽和高就是28-3+1 = 26
##输出的图像就是 5 * 26 * 26, 然后做pooling下采样2, 变为 5 * 13 * 13
self.conv1 = nn.Sequential(
nn.Conv2d(1, 5, kernel_size=3),
nn.MaxPool2d(2),
nn.ReLU()
)
##从上层channel的5转为输出10层, 卷积和是3,所以输出的宽和高就是13-3+1 = 11
##输出的图像就是 10 * 11 * 11, 然后做pooling下采样2, 变为 10 * 5 * 5
self.conv2 = nn.Sequential(
nn.Conv2d(5, 10, kernel_size=3),
nn.MaxPool2d(2),
nn.ReLU()
)
##从上层channel的10转为输出20层, 卷积和是3,所以输出的宽和高就是5-3+1 = 3
##本层不再做池化了,所以输出的图像就是 20 * 3 * 3,
self.conv3 = nn.Sequential(
nn.Conv2d(10, 20, kernel_size=3),
nn.ReLU()
)
##经过上面的图像20 * 3 * 3 = 180,进行全连接,我们多做几层将输出层降到10
self.fc = nn.Sequential(
nn.Linear(180, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, 10)
)
##定义损失函数
self.criterion = torch.nn.CrossEntropyLoss()
def forward(self, x):
in_size = x.size(0)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x微卡智享
训练文件的修改
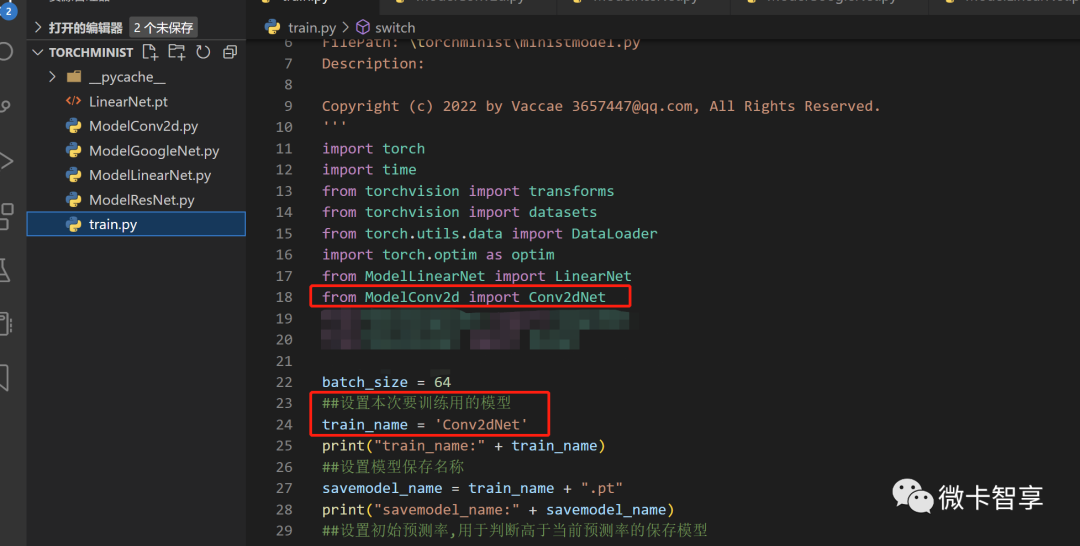
在train.py文件里,引入刚才创建的ModelConv2d,然后将变量train_name改为Conv2dNet
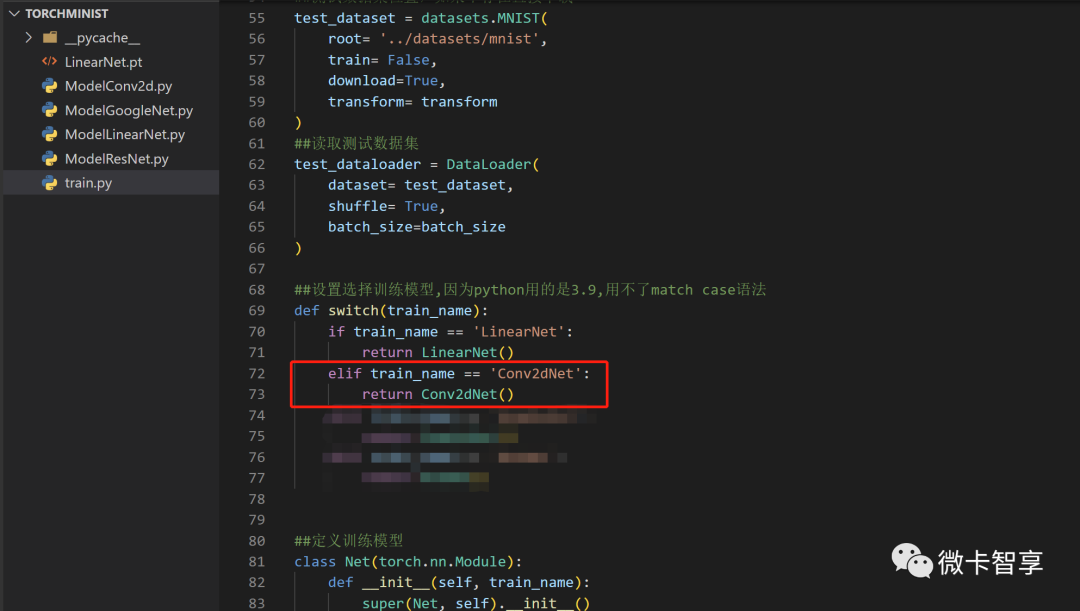
然后在switch函数中加入判断,如果是Conv2dNet的话,直接返回Conv2dNet(),别的代码就完全不用再动了,接下来就是运行训练看看效果
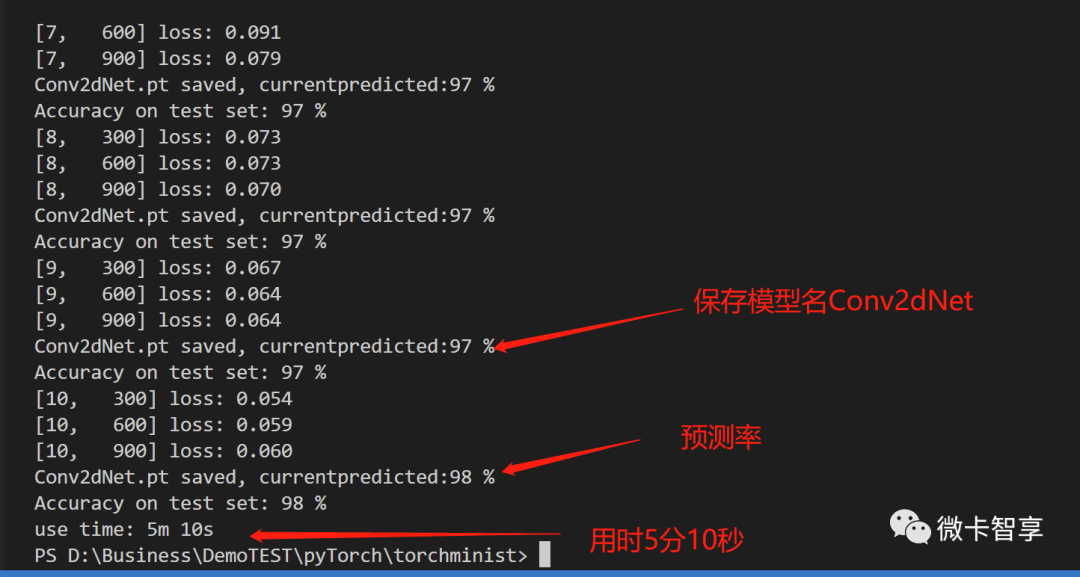
上图中可以看到这次我们训练的结果预测率为98%了。
完

往期精彩回顾
pyTorch入门(一)——Minist手写数据识别训练全连接网络

















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











