







一、urllib简介
1、urllib介绍
urllib是Python自带的标准库中用于网络请求的库,无需安装,直接引用即可
通常用于爬虫开发、API(应用程序编程接口)数据获取和测试-
2、urllib库的4大模块
urllib.request :用于打开和读取URL
urllib.error:包含提出的例外(异常)urllib.request
urllib.parse:用于解析URL
urllib.robotparser:用于解析robots.txt文件
3、urllib.parse库
(1)实验
# urllib.parse 用于解析Url
import urllib.parse
kw = {'wd': 'https://www.baidu.我爱你.com'}
# 对字符进行编码
result = urllib.parse.urlencode(kw)
print(result)
# 对结果进行解码
res = urllib.parse.unquote(result)
print(res)
4、urllib.request库
(1)urllib.request库
1、urllib.request库的作用
发送请求,模拟浏览器发起一个HTTP请求,并获取请求响应结果
2、urllib.request.urlopen的语法格式
urlopen(url,data=None, [timeout,]*, cafile=None, capath=None,cadefault=False, context=None)
url: url参数是str类型的地址,也就是要访问的URL,例如: 百度一下,你就知道
data:默认值为None,即代表请求方式为Get,反之请求方式为Post。发送Post请求时,参数data以字典形式存储数据,并将参数data由字典类型转换成字节类型才能完成Post请求
3、返回的结果
urlopen函数返回的结果是一个http.client.HTTPResponse对象
(2)Get请求实验
爬取的网站:教务处
1、查看爬取的网站返回的类型,如下'utf-8'另外还有'gbk'等其他类型
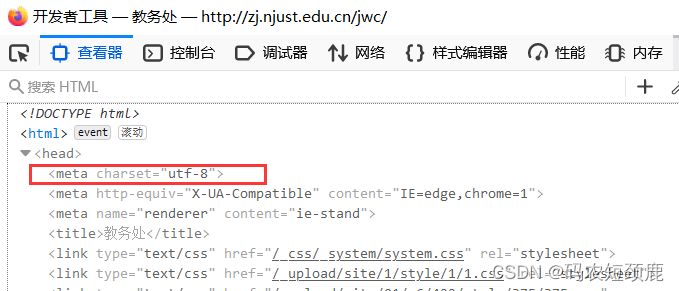
- 编写代码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









