







 本文是Spark初学者教程,详细介绍了Spark的安装、环境配置,以及使用Python进行Spark开发。接着讲解了Spark的RDD操作,包括转换和行动,通过案例展示了如何进行日志挖掘。最后,通过Spark MLlib实现电影推荐系统的搭建,涵盖了数据准备、参数设置、模型训练和预测,展示了如何使用ALS算法进行隐式和显式评分的预测。
本文是Spark初学者教程,详细介绍了Spark的安装、环境配置,以及使用Python进行Spark开发。接着讲解了Spark的RDD操作,包括转换和行动,通过案例展示了如何进行日志挖掘。最后,通过Spark MLlib实现电影推荐系统的搭建,涵盖了数据准备、参数设置、模型训练和预测,展示了如何使用ALS算法进行隐式和显式评分的预测。
Spark Beginner Step by Step
Chapter 1. Spark Installation
Download
进入spark的下载页面,选择你需要的Spark release和package type,如下图所示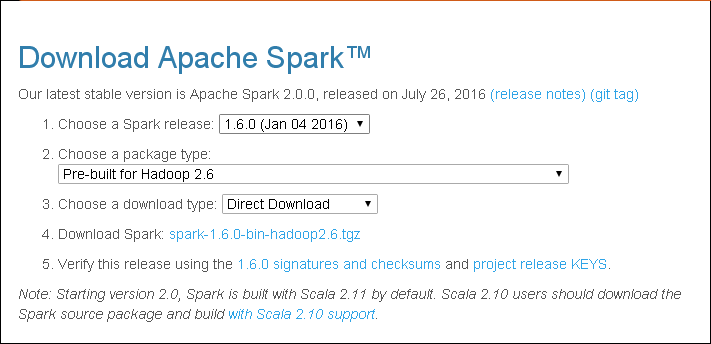
Install
将下载的spark安装包直接解压
XXXXXX@ubuntu:~/spark$ pwd
/home/XXXXXX/spark
XXXXXX@ubuntu:~/spark$ ls
spark-1.6.0-bin-hadoop2.6.tgz
XXXXXX@ubuntu:~/spark$ tar xvf spark-1.6.0-bin-hadoop2.6.tgz解压后,进入对应目录,目录结构如下
XXXXXX@ubuntu:~/spark$ cd spark-1.6.0-bin-hadoop2.6/
XXXXXX@ubuntu:~/spark/spark-1.6.0-bin-hadoop2.6$ ls
bin conf ec2 lib licenses python README.md sbin
CHANGES.txt data examples LICENSE NOTICE R RELEASEStart Python Shell
在spark的根目录下,运行bin目录下的脚本pyspark,
XXXXXX@trusty:~/software/spark/spark-1.6.0-bin-hadoop2.6$ ./bin/pyspark可以启动spark的python shell
16/09/14 11:11:49 INFO NettyBlockTransferService: Server created on 59474
16/09/14 11:11:49 INFO BlockManagerMaster: Trying to register BlockManager
16/09/14 11:11:49 INFO BlockManagerMasterEndpoint: Registering block manager localhost:59474 with 511.1 MB RAM, BlockManagerId(driver, localhost, 59474)
16/09/14 11:11:49 INFO BlockManagerMaster: Registered BlockManager
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.6.0
/_/
Using Python version 2.7.6 (default, Mar 22 2014 22:59:56)
SparkContext available as sc, HiveContext available as sqlContext.
>>>在shell启动的过程中,client打印的信息较多,可以修改配置文件来改变打印级别。首先,我们结束Spark的python shell(ctrl+d),然后修改conf下的配置文件。
XXXXXX@trusty:~/software/spark/spark-1.6.0-bin-hadoop2.6/conf$ cp log4j.properties.template log4j.properties编辑log4j.properties,将INFO替换为WARN,
# Set everything to be logged to the console
log4j.rootCategory=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Settings to quiet third party logs that are too verbose
log4j.logger.org.eclipse.jetty=WARN
log4j.logger.org.eclipse.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=WARN
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=WARN修改后,再次启动Spark python shell,显示如下。下面的client的打印信息中已经没有了INFO级别信息,只留下了WARN级别的,
XXXXXX@trusty:~/software/spark/spark-1.6.0-bin-hadoop2.6$ ./bin/pyspark
Python 2.7.12 |Anaconda 4.1.1 (64-bit)| (default, Jul 2 2016, 17:42:40)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-1)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Anaconda is brought to you by Continuum Analytics.
Please check out: http://continuum.io/thanks and https://anaconda.org
16/09/14 16:00:52 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/09/14 16:00:52 WARN Utils: Your hostname, trusty resolves to a loopback address: 127.0.1.1; using 192.168.1.254 instead (on interface eth0)
16/09/14 16:00:52 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.6.0
/_/
Using Python version 2.7.12 (default, Jul 2 2016 17:42:40)
SparkContext available as sc, HiveContext available as sqlContext.
>>>Building Spark Cluster
start-master.sh
我们使用脚本start-master.sh启动spark的master节点,命令如下
XXXXXX@trusty:~/spark/spark-1.6.0-bin-hadoop2.6$ ./sbin/start-master.sh --ip XXXXXX其中,IP地址XXXXXX是由下面的命令中的inet addr获得。
XXXXXX@trusty:~/spark/spark-1.6.0-bin-hadoop2.6$ ifconfigstart-slave.sh
Spark Cluster中的Worker可由脚本start-slave.sh来启动,命令如下,
XXXXXX@trusty:~/software/spark/spark-1.6.0-bin-hadoop2.6/sbin$ ./start-slave.sh XXXXXX:7077其中,IP地址XXXXXX指的就是master的IP地址。
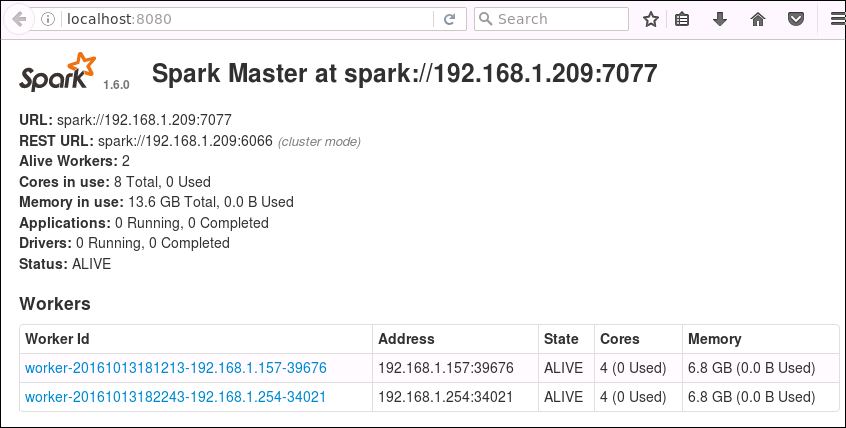
Cluster Information
通过脚本start-master.sh和start-slave.sh可创建Spark Cluster。相关的信息,可在master节点通过网址localhost:8080查看。
Chapter 2. “Hello World!” in Spark
Spark环境搭建完毕以后,自然需要来测试一下。大数据领域的第一个程序是wordcount,就好像我们新接触一门编码语言,第一个程序就是hello world一样。接下来,我们就尝试用python shell在spark里实现word count的功能。
XXXXXX@trusty:~/software/spark/spark-1.6.0-bin-hadoop2.6$ ls
bin data examples licenses NOTICE README.md work
CHANGES.txt derby.log lib logs python RELEASE workspace
conf ec2 LICENSE metastore_db R sbin
XXXXXX@trusty:~/software/spark/spark-1.6.0-bin-hadoop2.6$ ./bin/pyspark
Python 2.7.12 |Anaconda 4.1.1 (64-bit)| (default, Jul 2 2016, 17:42:40)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-1)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Anaconda is brought to you by Continuum Analytics.
Please check out: http://continuum.io/thanks and https://anaconda.org
16/09/14 16:00:52 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/09/14 16:00:52 WARN Utils: Your hostname, trusty resolves to a loopback address: 127.0.1.1; using 192.168.1.254 instead (on interface eth0)
16/09/14 16:00:52 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.6.0
/_/
Using Python version 2.7.12 (default, Jul 2 2016 17:42:40)
SparkContext available as sc, HiveContext available as sqlContext.
>>> textFile = sc.textFile("README.md")
>>>上面命令读取README,用textFile方法创建RDD数据集,下面的命令使用RDD count方法获取文件行数,
>>> textFile.count()
95然后,使用filter方法创建一个新的RDD数据集(包含有’Spark’的行),
>>> linesWithSpark = textFile.filter(lambda line: "Spark" in line)最后,使用RDD count方法获取文件内容包含”Spark”的行数
>>> linesWithSpark.count()
17Chapter 3. Understand RDD Operations: Transformations and Actions
无论是工业界还是学术界,都已经广泛使用高级集群编程模型来处理日益增长的数据,如MapReduce和Dryad。这些系统将分布式编程简化为自动提供位置感知性调度、容错以及负载均衡,使得大量用户能够在商用集群上分析超大数据集。
大多数现有的集群计算系统都是基于非循环的数据流模型。从稳定的物理存储(如分布式文件系统)中加载记录,记录被传入由一组确定性操作构成的DAG,然后写回稳定存储。DAG数据流图能够在运行时自动实现任务调度和故障恢复。
尽管非循环数据流是一种很强大的抽象方法,但仍然有些应用无法使用这种方式描述,它们的特点是在多个并行操作之间重用工作数据集。这类应用包括:
+ 机器学习和图应用中常用的迭代算法(每一步对数据执行相似的函数);
+ 交互式数据挖掘工具(用户反复查询一个数据子集);
为解决上述问题,弹性分布式数据集(RDD,Resilient Distributed Datasets)应运而生。它支持基于工作集的应用,同时具有数据流模型的特点:自动容错、位置感知调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。与分布式共享内存系统需要付出高昂代价的检查点和回滚机制不同,RDD通过Lineage来重建丢失的分区:一个RDD中包含了如何从其他RDD衍生所必需的相关信息,从而不需要检查点操作就可以重构丢失的数据分区。尽管RDD不是一个通用的共享内存抽象,但却具备了良好的描述能力、可伸缩性和可靠性,但却能够广泛适用于数据并行类应用。
Spark通过微基准和用户应用程序来评估RDD。实验表明,在处理迭代式应用上Spark比Hadoop快高达20多倍,计算数据分析类报表的性能提高了40多倍,同时能够在5-7秒的延时内交互式扫描1TB数据集。
本部分描述RDD(弹性分布式数据集)和编程模型。首先讨论设计目标和RDD定义,然后讨论Spark的编程模型,并给出一个示例,最后举例分析下Spark中RDD的操作。
RDD Abstraction
RDD目标是为基于工作集的应用(即多个并行操作重用中间结果的这类应用)提供抽象,同时保持MapReduce及其相关模型的优势特性:即自动容错、位置感知性调度和可伸缩性。RDD比数据流模型更易于编程,同时基于工作集的计算也具有良好的描述能力。
虽然只支持粗粒度转换限制了编程模型,但RDD仍然可以很好地适用于很多应用,特别是支持数据并行的批量分析应用,包括数据挖掘、机器学习和图算法等,因为这些程序通常都会在很多记录上执行相同的操作。RDD不太适合那些异步更新共享状态的应用,例如并行web爬行器。
RDD是只读的、分区记录的集合。RDD只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建。这些确定性操作称之为转换,如map、filter、groupBy、join(转换不是程开发人员在RDD上执行的操作)。
RDD不需要物化。RDD含有如何从其他RDD衍生(即计算)出本RDD的相关信息(即Lineage),据此可以从物理存储的数据计算出相应的RDD分区。
Spark Programming Interface
在Spark中,RDD被表示为对象,通过这些对象上的方法(或函数)调用转换。
定义RDD之后,程序员就可以在动作中使用RDD了。动作是向应用程序返回值,或向存储系统导出数据的那些操作,例如,count(返回RDD中的元素个数),collect(返回元素本身),save(将RDD输出到存储系统)。在Spark中,只有在动作第一次使用RDD时,才会计算RDD(即延迟计算)。这样在构建RDD的时候,运行时通过管道的方式传输多个转换。
程序员还可以从两个方面控制RDD,即缓存和分区。用户可以请求将RDD缓存,这样运行时将已经计算好的RDD分区存储起来,以加速后期的重用。缓存的RDD一般存储在内存中,但如果内存不够,可以写到磁盘上。
另一方面,RDD还允许用户根据关键字(key)指定分区顺序,这是一个可选的功能。目前支持哈希分区和范围分区。例如,应用程序请求将两个RDD按照同样的哈希分区方式进行分区(将同一机器上具有相同关键字的记录放在一个分区),以加速它们之间的join操作。在Pregel和HaLoop中,多次迭代之间采用一致性的分区置换策略进行优化,我们同样也允许用户指定这种优化。
Example: Console Log Mining
本部分我们通过一个具体示例来阐述RDD。假定有一个大型网站出错,操作员想要检查Hadoop文件系统(HDFS)中的日志文件(TB级大小)来找出原因。通过使用Spark,操作员只需将日志中的错误信息装载到一组节点的内存中,然后执行交互式查询。首先,需要在Spark解释器中输入如下Python命令:
# SparkContext available as spark
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.cache()第1行从HDFS文件定义了一个RDD(即一个文本行集合),第2行获得一个过滤后的RDD,第3行请求将errors缓存起来。
这时集群还没有开始执行任何任务。但是,用户已经可以在这个RDD上执行对应的动作,例如统计错误消息的数目:
errors.count()用户还可以在RDD上执行更多的转换操作,并使用转换结果,如:
# Count errors mentioning MySQL:
errors.filter(_.contains("MySQL")).count()
# Return the time fields of errors mentioning
# HDFS as an array (assuming time is field
# number 3 in a tab-separated format):
errors.filter(_.contains("HDFS"))
.map(_.split('\t')(3))
.collect()使用errors的第一个action运行以后,Spark会把errors的分区缓存在内存中,极大地加快了后续计算速度。注意,最初的RDD lines不会被缓存。因为错误信息可能只占原数据集的很小一部分(小到足以放入内存)。
最后,为了说明模型的容错性,下图给出了第3个查询的Lineage图。在lines RDD上执行filter操作,得到errors,然后再filter、map后得到新的RDD,在这个RDD上执行collect操作。Spark调度器以流水线的方式执行后两个转换,向拥有errors分区缓存的节点发送一组任务。此外,如果某个errors分区丢失,Spark只在相应的lines分区上执行filter操作来重建该errors分区。
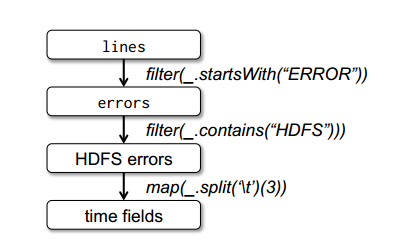
RDD Operations
下图中列出了Spark中的RDD转换和动作。每个操作都给出了标识,其中方括号表示类型参数。前面说过转换是延迟操作,用于定义新的RDD;而动作启动计算操作,并向用户程序返回值或向外部存储写数据。

注意,有些操作只对键值对可用,比如join。另外,函数名与Scala及其他函数式语言中的API匹配,例如map是一对一的映射,而flatMap是将每个输入映射为一个或多个输出(与MapReduce中的map类似)。
除了这些操作以外,用户还可以请求将RDD缓存起来。而且,用户还可以通过Partitioner类获取RDD的分区顺序,然后将另一个RDD按照同样的方式分区。有些操作会自动产生一个哈希或范围分区的RDD,像groupByKey,reduceByKey和sort等。
Example
Flatmap Operation
此操作,首先对每一个分区进行一个映射,然后返回一个新的flattening后的RDD数据。
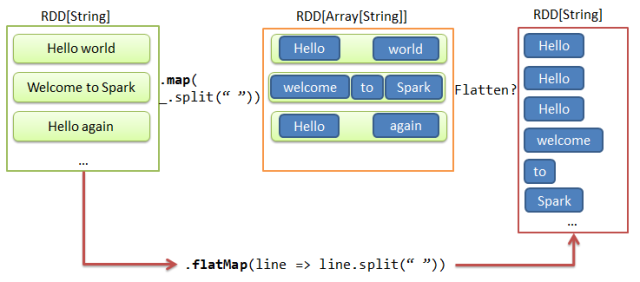
参考如下的代码,
# 读入一个txt文件
# SparkContext available as spark
lines = spark.textFile("hdfs://input.txt");
# 产生RDD数据
words = lines.flatMap(line => line.split(" "));Transformation & Lazy Evaluation will Bring us More Chance of Optimizing Our Job
那么RDD在Spark架构中是如何运行的呢?从高层次来看,主要分为三步:
- 创建RDD对象;
- DAGScheduler模块介入运算,计算RDD之间的依赖关系。RDD之间的依赖关系就形成了DAG;
- 每一个JOB被分为多个Stage,划分Stage的一个主要依据是当前计算因子的输入是否是确定的。如果是则将其分在同一个Stage,避免多个Stage之间的消息传递开销;
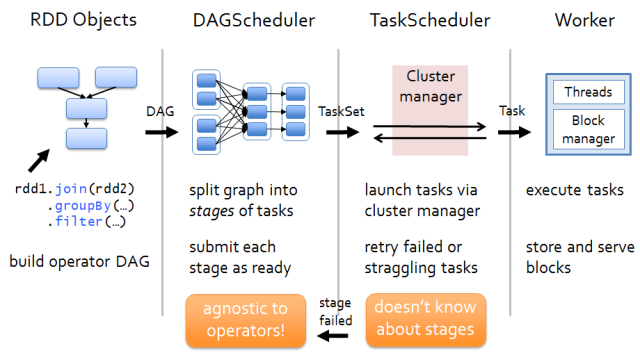
根据下面的例子,分析其在spark中流程,
logFile = "YOUR_SPARK_HOME/README.md"
conf = new SparkConf().setAppName("Simple Application")
sc = new SparkContext(conf)
logData = sc.textFile(logFile, 2).cache()
numAs = logData.filter(line => line.contains("a")).count()
print 'Lines with a: ' numAs首先,我们创建一个RDD通过SparkContext。然后,我们使用filter转换对RDD进行转换操作,并且使用count操作对RDD进行计数。
在计数操作的过程中,SparkContext首先向DAG Scheduler提交对应的Job。当DAG Scheduler获取到相关的数据和操作信息之后,
1. 创建Stages;
2. 然后将Stages提交到Task Scheduler;
3. 如果有Stages失败,DAG Scheduler将从新提交错误的Stages。
Task Scheduler负责将对应的Tasks提交到集群中的任务执行者,并将对应的计算结果返回给DAG Scheduler。
RDD Dependency Types and the Optimization at DAG Scheduler
RDD之间的依赖关系可以分为两类,即:
1. 窄依赖(narrow dependencies):子RDD的每个分区依赖于常数个父分区(即与数据规模无关);
2. 宽依赖(wide dependencies):子RDD的每个分区依赖于所有父RDD分区。例如,map产生窄依赖,而join则是宽依赖(除非父RDD被哈希分区)。
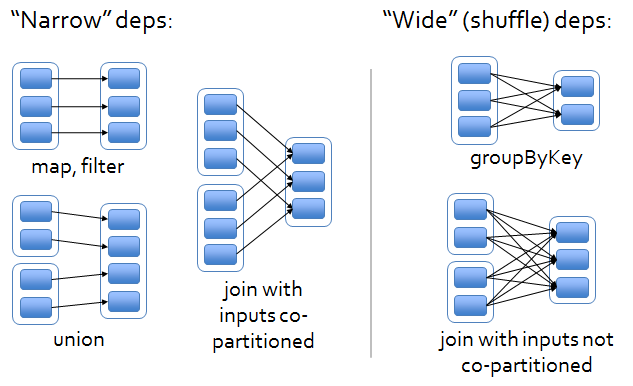
Chapter 4. Film Recommendation System with Spark MLlib
推荐算法就是利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西。随着电子商务规模的不断扩大,商品数量和种类不断增长,用户对于检索和推荐提出了更高的要求。由于不同用户在兴趣爱好、关注领域、个人经历等方面的不同,以满足不同用户的不同推荐需求为目的、不同人可以获得不同推荐为重要特征的个性化推荐系统应运而生。
推荐系统成为一个相对独立的研究方向一般被认为始自1994年明尼苏达大学GroupLens研究组推出的GroupLens系统。该系统有两大重要贡献:一是首次提出了基于协同过滤(Collaborative Filtering)来完成推荐任务的思想,二是为推荐问题建立了一个形式化的模型。基于该模型的协同过滤推荐引领了之后推荐系统在今后十几年的发展方向。
目前,推荐算法已经已经被广泛集成到了很多商业应用系统中,比较著名的有Netflix在线视频推荐系统、Amazon网络购物商城等。实际上,大多数的电子商务平台尤其是网络购物平台,都不同程度地集成了推荐算法,如淘宝、京东商城等。Amazon发布的数据显示,亚马逊网络书城的推荐算法为亚马逊每年贡献近三十个百分点的创收。
Moive Recommend System Introduction
我们将在Spark上搭建一个简单的小型的电影推荐系统,实践下Spark的相关知识。
整个系统的工作流程描述如下:
+ 某电影网站拥有可观的电影资源和用户数,通过各个用户对各个电影的评分,汇总得到了海量的用户-电影-评分数据;
+ 用户在一个电影网站上看了几部电影,并都为其做了评分操作(0-5分);
+ 该电影网站的推荐系统根据用户对那几部电影的评分,要预测出在该网站的电影资源库中,有哪些电影是适合该用户,并推荐给用户后续看;
Movie Data
在此将采用显式评级数据,这样所需的输入数据就只需包括每个评级对应的用户ID、影片ID和具体的星级。本文中使用显式数据也就是用户对movie的rating信息,这个数据来源于网络上的MovieLens标准数据集。首先,我们下载此数据文件,
curl -O http://files.grouplens.org/papers/ml-1m.zip
unzip -j ml-1m.zip "*.dat"电影数据结构如下所示,
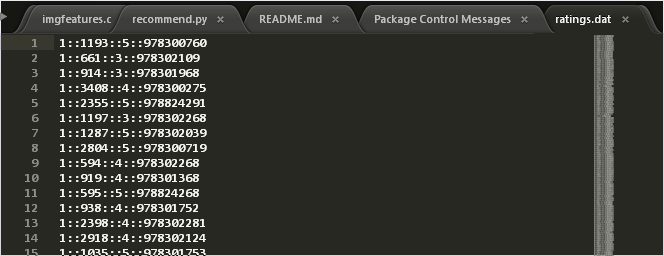
在Spark的python shell中,
Using Python version 2.7.12 (default, Jul 2 2016 17:42:40)
SparkContext available as sc, HiveContext available as sqlContext.
>>> rawData = sc.textFile("ratings.dat")
>>> print rawData.first()
1::1193::5::978300760
>>> rawRatings = rawData.map(lambda x: x.split('::'))
>>> rawRatings.take(5)
[[u'1', u'1193', u'5', u'978300760'], [u'1', u'661', u'3', u'978302109'], [u'1', u'914', u'3', u'978301968'], [u'1', u'3408', u'4', u'978300275'], [u'1', u'2355', u'5', u'978824291']]
>>>导入Rating和ALS模块,生成相关的用户ID-电影ID-评分三元组数据,用于电影评价系统建模,
>>> from pyspark.mllib.recommendation import Rating, ALS
>>> ratings = rawRatings.map(lambda x: Rating(int(x[0]),int(x[1]),float(x[2])))
>>> print ratings.take(5)
[Rating(user=1, product=1193, rating=5.0), Rating(user=1, product=661, rating=3.0), Rating(user=1, product=914, rating=3.0), Rating(user=1, product=3408, rating=4.0), Rating(user=1, product=2355, rating=5.0)]Parameters of ALS in Spark MLlib
对于Spark中的ALS算法模型参考下图,
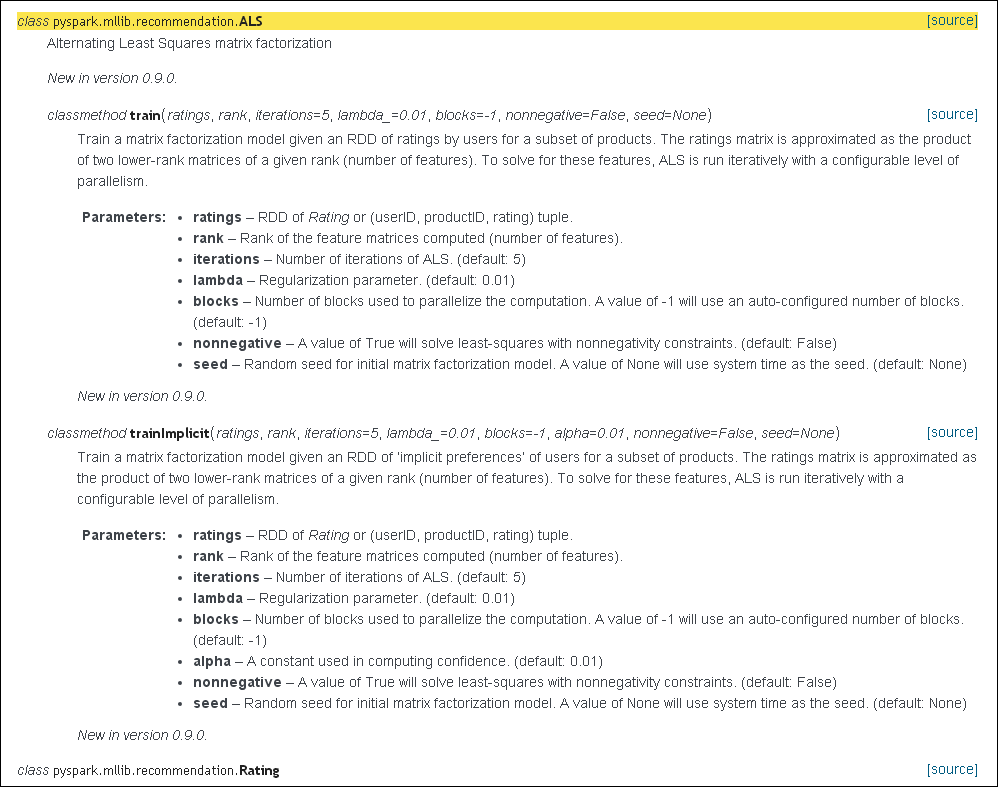
对于图中所示的相关参数,简要说明如下,
+ blocks:用于并行化计算的分块个数(-1为自动分配);
+ rank:对应ALS模型中的因子个数,也就是在低阶近似矩阵中的隐含特征个数。因子个数一般越多越好。但它也会直接影响模型训练和保存时所需的内存开销,尤其是在用户和物品很多的时候。因此实践中该参数常作为训练效果与系统开销之间的调节参数。通常,其合理取值为10到200;
+ iterations:对应运行时的迭代次数。ALS能确保每次迭代都能降低评级矩阵的重建误差,但一般经少数次迭代后ALS模型便已能收敛为一个比较合理的好模型。这样,大部分情况下都没必要迭代太多次;
+ lambda:该参数控制模型的正则化过程,从而控制模型的过拟合情况。其值越高,正则化越严厉。该参数的赋值与实际数据的大小、特征和稀疏程度有关。和其他的机器学习模型一样,正则参数应该通过用非样本的测试数据进行交叉验证来调整;
作为示例,这里将使用的rank、iterations和lambda参数的值分别为50、10和0.01
>>> model = ALS.train(ratings, 50, 10, 0.01)
16/09/20 14:43:06 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
16/09/20 14:43:06 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS
16/09/20 14:43:07 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeSystemLAPACK
16/09/20 14:43:07 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeRefLAPACK
>>> userFeatures = model.userFeatures()
>>> print userFeatures.take(2)
[(4, array('d', [0.7637861967086792, -0.2737080156803131, -0.17861029505729675, -0.15782339870929718, 0.5641644597053528, -0.7890649437904358, 0.030582157894968987, -0.5173158049583435, -0.3407333791255951, 0.6648253798484802, 0.3050779402256012, -0.21968813240528107, 0.173197939991951, -0.6081686019897461, 0.4522302448749542, -0.7958189845085144, -0.08689826726913452, -0.09954997152090073, -0.3353758156299591, -0.4138887822628021, -0.7452021241188049, -0.031780023127794266, 0.5922057032585144, 0.7325875163078308, 0.4383866488933563, 0.01752650924026966, 0.19423671066761017, 0.6452142000198364, -0.237614706158638, 0.4996830224990845, 0.433722585439682, -0.527918815612793, -0.06985001266002655, 0.3345005214214325, -0.455691397190094, 0.6103637218475342, -0.4949045479297638, -0.29415786266326904, 0.1458829641342163, -0.13409490883350372, -0.7043140530586243, -0.3189659118652344, 0.9378584027290344, 0.3959159255027771, -0.4623756408691406, 0.48755812644958496, -0.6423717737197876, -0.74339359998703, -0.12484308332204819, 0.7191870808601379])),
(8, array('d', [0.18474148213863373, -0.058425139635801315, -0.44903039932250977, 0.19399809837341309, 0.32332539558410645, 0.4514048397541046, -0.2615528404712677, 0.4042547643184662, 0.24401091039180756, 0.22522710263729095, 0.003954704850912094, -0.6550437808036804, -0.10648829489946365, -0.08467081934213638, -0.35362696647644043, -0.0243882704526186, -0.49195241928100586, -0.015496794134378433, -0.6088727712631226, -0.7618396282196045, -0.5728880763053894, -0.08133324980735779, -0.2797628343105316, 0.6432862281799316, -0.37794432044029236, 0.2251107096672058, 0.4254800081253052, 0.07602629065513611, 0.29608646035194397, -0.025677282363176346, 0.20981505513191223, -0.11121115833520889, -0.40469440817832947, -0.6033666133880615, 0.10213682055473328, 0.6090074181556702, 0.14255429804325104, 0.4098706841468811, -0.12171165645122528, -0.5418315529823303, -0.7681489586830139, -0.17904889583587646, 0.4459456503391266, 0.2680012583732605, -0.432824969291687, 0.2132682204246521, -0.5714149475097656, -0.26383259892463684, 0.06570298224687576, -0.07780900597572327]))]
>>>注意,MLlib中ALS的实现里所用的操作都是延迟性的转换操作。所以,只在当用户因子或物品因子结果RDD调用了执行操作时,实际的计算才会发生。
>>> print model.userFeatures().count()
6040
>>> print model.productFeatures().count()
3706
>>>Using Implicit Training
MLlib中标准的矩阵分解模型用于显式评级数据的处理。若要处理隐式数据,则可使用trainImplicit函数。其调用方式和标准的train模式类似,但多了一个可设置的alpha参数(也是一个正则化参数,alpha应通过测试和交叉验证法来设置)。Alpha参数指定了信心权重所应达到的基准线。该值越高则所训练出的模型越认为用户与他所没评级过的电影之间没有相关性。
Predict Model
有了训练好的模型后便可用它来做预测。预测通常有两种:为某个用户推荐物品或找出与某个物品相关或相似的其他物品。
从MovieLens 100k数据集生成电影推荐。MLlib的推荐模型基于矩阵分解,因此可用模型所求得的因子矩阵来计算用户对物品的预计评级。下面只针对利用MovieLens中显式数据做推荐的情形,使用隐式模型时的方法与之类似。
>>> print len(userFeatures.first()[1])
50
>>> predictRating = model.predict(789, 123)
>>> print predictRating
2.22793962877可以看到,该模型预测用户789对电影123的评级为2.2279。
predict函数同样可以以(user, item)ID对类型的RDD对象为输入,这时它将为每一对都生成相应的预测得分。我们可以借助这个函数来同时为多个用户和物品进行预测。要为某个用户生成前K个推荐物品,可借助MatrixFactorizationModel所提供的recommendProducts函数来实现。该函数需两个输入参数:user和num。其中user是用户ID,而num是要推荐的物品个数。返回值为预测得分最高的前num个物品。这些物品的序列按得分排序。该得分为相应的用户因子向量和各个物品因子向量的点积。
计算给用户789推荐的前10个物品,代码如下:
>>> topKRecs = model.recommendProducts(789,10)
>>> for rec in topKRecs:
... print rec
...
Rating(user=789, product=2301, rating=6.0918980985395965)
Rating(user=789, product=72, rating=5.944789814994465)
Rating(user=789, product=3235, rating=5.678107122287396)
Rating(user=789, product=2021, rating=5.57785308220733)
Rating(user=789, product=2872, rating=5.5128742571509495)
Rating(user=789, product=1220, rating=5.452961264362774)
Rating(user=789, product=3327, rating=5.4298917773861115)
Rating(user=789, product=678, rating=5.410994833670508)
Rating(user=789, product=3677, rating=5.4040372563053225)
Rating(user=789, product=3552, rating=5.396600269052178)到此,我们就已经实现了一个简单电影推荐系统。上说所有的操作,我已经打包写成了相关的python服务,其中主要功能文件的代码如下,
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Collaborative Filtering ALS Recommender System using Spark MLlib adapted from
the Spark Summit 2014 Recommender System training example.
Usage:
./recommend.py train <training_data_file> [--partitions=<n>]
[--ranks=<n>] [--lambdas=<n>] [--iterations=<n>]
./recommend.py recommend <training_data_file> <movies_meta_data>
[--ratings=<n>] [--partitions=<n>] [--rank=<n>]
[--iteration=<n>] [--lambda=<n>]
./recommend.py metrics <training_data_file> <movies_meta_data>
./recommend.py (-h | --help)
Options:
-h, --help Show this screen and exit.
--partitions=<n> Partition count [Default: 4]
--ranks=<n> List of ranks [Default: 6,8,12]
--lambdas=<n> List of lambdas [Default: 0.1,1.0,10.0]
--iterations=<n> List of iterations [Default: 10,20]
--ratings=<n> Ratings for 5 popular films [Default: 5,4,5,5,5]
--rank=<n> Rank value [Default: 12]
--lambda=<n> Lambda value [Default: 0.1]
--iteration=<n> Iteration value [Default: 20]
Examples:
bin/spark-submit recommend.py train ratings.dat
bin/spark-submit recommend.py metrics ratings.dat movies.dat
bin/spark-submit --driver-memory 2g \
recommend.py recommend ratings.dat movies.dat
"""
import contextlib
import itertools
from math import sqrt
from operator import add
import sys
from docopt import docopt
from pyspark import SparkConf, SparkContext
from pyspark.mllib.recommendation import ALS
SPARK_EXECUTOR_MEMORY = '2g'
SPARK_APP_NAME = 'movieRecommender'
SPARK_MASTER = 'local'
@contextlib.contextmanager
def spark_manager():
conf = SparkConf().setMaster(SPARK_MASTER) \
.setAppName(SPARK_APP_NAME) \
.set("spark.executor.memory", SPARK_EXECUTOR_MEMORY)
spark_context = SparkContext(conf=conf)
try:
yield spark_context
finally:
spark_context.stop()
def parse_rating(line):
"""
Parses a rating record that's in MovieLens format.
:param str line: userId::movieId::rating::timestamp
"""
fields = line.strip().split("::")
# The data is divided into three parts for training, validation, and
# testing. This is why the sets were keyed with integers < 10. These
# methods are very quick and scalable big-data tricks to make random
# key-value buckets without using any randomizing functions.
return long(fields[3]) % 10, (int(fields[0]), # User ID
int(fields[1]), # Movie ID
float(fields[2])) # Rating
def compute_rmse(model, data, validation_count):
"""
Compute RMSE (Root Mean Squared Error).
:param object model:
:param list data:
:param integer validation_count:
"""
predictions = model.predictAll(data.map(lambda x: (x[0], x[1])))
predictionsAndRatings = \
predictions.map(lambda x: ((x[0], x[1]), x[2])) \
.join(data.map(lambda x: ((x[0], x[1]), x[2]))) \
.values()
return sqrt(
predictionsAndRatings.map(
lambda x: (x[0] - x[1]) ** 2
).reduce(add) / float(validation_count)
)
def metrics(training_data_file, movies_meta_data):
"""
Print metrics for the ratings database
:param str training_data_file: file location of ratings.dat
:param str movies_meta_data: file location of movies.dat
"""
movies = {}
with open(movies_meta_data, 'r') as open_file:
movies = {int(line.split('::')[0]): line.split('::')[1]
for line in open_file
if len(line.split('::')) == 3}
# with open(movies_meta_data, 'r') as open_file:
# movies_index = [int(line.split('::')[0]) for line in open_file]
# open_file.seek(0)
# movies_name = [line.split('::')[1] for line in open_file]
# movies = dict(zip(movies_index, movies_name))
# The training file with all the rating is loaded as a spark Resilient
# Distributed Dataset (RDD), and the parse_rating method is applied to
# each line that has been read from the file. RDD is a fault-tolerant
# collection of elements that can be operated on in parallel.
with spark_manager() as context:
ratings = context.textFile(training_data_file) \
.filter(lambda x: x and len(x.split('::')) == 4) \
.map(parse_rating)
most_rated = ratings.values() \
.map(lambda r: (r[1], 1)) \
.reduceByKey(add) \
.map(lambda r: (r[1], r[0])) \
.sortByKey(ascending=False) \
.collect()[:10]
print
print '10 most rated films:'
for (ratings, movie_id) in most_rated:
print '{:10,} #{} {}'.format(ratings, movie_id, movies[movie_id])
def train(training_data_file, numPartitions, ranks, lambdas, iterations):
"""
Print metrics for the ratings database
:param str training_data_file: file location of ratings.dat
:param int numPartitions: number of partitions
:param list ranks: list of ranks to use
:param list lambdas: list of lambdas to use
:param list iterations: list of iteration counts
"""
# The training file with all the rating is loaded as a spark Resilient
# Distributed Dataset (RDD), and the parse_rating method is applied to
# each line that has been read from the file. RDD is a fault-tolerant
# collection of elements that can be operated on in parallel.
with spark_manager() as context:
ratings = context.textFile(training_data_file) \
.filter(lambda x: x and len(x.split('::')) == 4) \
.map(parse_rating)
numRatings = ratings.count()
numUsers = ratings.values() \
.map(lambda r: r[0]) \
.distinct() \
.count()
numMovies = ratings.values() \
.map(lambda r: r[1]) \
.distinct() \
.count()
training = ratings.filter(lambda x: x[0] < 6) \
.values() \
.repartition(numPartitions) \
.cache()
validation = ratings.filter(lambda x: x[0] >= 6 and x[0] < 8) \
.values() \
.repartition(numPartitions) \
.cache()
test = ratings.filter(lambda x: x[0] >= 8) \
.values() \
.cache()
numTraining = training.count()
numValidation = validation.count()
numTest = test.count()
# We will test 18 combinations resulting from the cross product of 3
# different ranks (6, 8, 12), 3 different lambdas (0.1, 1.0, 10.0),
# and two different numbers of iterations (10, 20). We will use
# compute_rmse to compute the RMSE (Root Mean Squared Error) on the
# validation set for each model. The model with the smallest RMSE on the
# validation set becomes the one selected and its RMSE on the test set
# is used as the final metric.
bestValidationRmse = float("inf")
bestModel, bestRank, bestLambda, bestNumIter = None, 0, -1.0, -1
# Collaborative filtering is commonly used for recommender systems.
# These techniques aim to fill in the missing entries of a user-item
# association matrix, in our case, the user-movie rating matrix. MLlib
# currently supports model-based collaborative filtering, in which
# users and products are described by a small set of latent factors
# that can be used to predict missing entries. In particular, we
# implement the alternating least squares (ALS) algorithm to learn
# these latent factors.
for rank, lmbda, numIter in itertools.product(ranks,
lambdas,
iterations):
model = ALS.train(ratings=training,
rank=rank,
iterations=numIter,
lambda_=lmbda)
validationRmse = compute_rmse(model, validation, numValidation)
if validationRmse < bestValidationRmse:
bestModel, bestValidationRmse = model, validationRmse
bestRank, bestLambda, bestNumIter = rank, lmbda, numIter
# Evaluate the best model on the test set
testRmse = compute_rmse(bestModel, test, numTest)
print
print 'Ratings: {:10,}'.format(numRatings)
print 'Users: {:10,}'.format(numUsers)
print 'Movies: {:10,}'.format(numMovies)
print
print 'Training: {:10,}'.format(numTraining)
print 'Validation: {:10,}'.format(numValidation)
print 'Test: {:10,}'.format(numTest)
print
print 'The best model was trained with:'
print ' Rank: {:10,}'.format(bestRank)
print ' Lambda: {:10,.6f}'.format(bestLambda)
print ' Iterations: {:10,}'.format(bestNumIter)
print ' RMSE on test set: {:10,.6f}'.format(testRmse)
def recommend(training_data_file, movies_meta_data, user_ratings,
numPartitions, rank, iterations, _lambda):
"""
Recommend films to the user based on their ratings of 5 popular films
:param str training_data_file: file location of ratings.dat
:param str movies_meta_data: file location of movies.dat
:param list user_ratings: list of floats of ratings for 5 popular films
:param int numPartitions: number of partitions
:param int rank: rank amount
:param int iterations: iterations count
:param float _lambda: lambda amount
"""
# Collect the users ratings of 5 popular films
my_ratings = (
(0, 2858, user_ratings[0]), # American Beauty (1999)
(0, 480, user_ratings[1]), # Jurassic Park (1993)
(0, 589, user_ratings[2]), # Terminator 2: Judgement Day (1991)
(0, 2571, user_ratings[3]), # Matrix, The (1999)
(0, 1270, user_ratings[4]), # Back to the Future (1985)
)
films_seen = set([_rating[1] for _rating in my_ratings])
with spark_manager() as context:
training = context.textFile(training_data_file) \
.filter(lambda x: x and len(x.split('::')) == 4) \
.map(parse_rating) \
.values() \
.repartition(numPartitions) \
.cache()
model = ALS.train(training, rank, iterations, _lambda)
films_rdd = context.textFile(training_data_file) \
.filter(lambda x: x and len(x.split('::')) == 4) \
.map(parse_rating)
films = films_rdd.values() \
.map(lambda r: (r[1], 1)) \
.reduceByKey(add) \
.map(lambda r: r[0]) \
.filter(lambda r: r not in films_seen) \
.collect()
candidates = context.parallelize(films) \
.map(lambda x: (x, 1)) \
.repartition(numPartitions) \
.cache()
predictions = model.predictAll(candidates).collect()
# Get the top 50 recommendations
recommendations = sorted(predictions,
key=lambda x: x[2],
reverse=True)[:50]
# Map each film id and name to a key, value dictionary
movies = {}
with open(movies_meta_data, 'r') as open_file:
movies = {int(line.split('::')[0]): line.split('::')[1]
for line in open_file
if len(line.split('::')) == 3}
# with open(movies_meta_data, 'r') as open_file:
# movies_index = [int(line.split('::')[0]) for line in open_file]
# open_file.seek(0)
# movies_name = [line.split('::')[1] for line in open_file]
# movies = dict(zip(movies_index, movies_name))
for movie_id, _, _ in recommendations:
print movies[movie_id] if movie_id in movies else movie_id
def main(argv):
"""
:param dict argv: command line arguments
"""
opt = docopt(__doc__, argv)
if opt['train']:
ranks = [int(rank) for rank in opt['--ranks'].split(',')]
lambdas = [float(_lambda) for _lambda in opt['--lambdas'].split(',')]
iterations = [int(_iter) for _iter in opt['--iterations'].split(',')]
train(opt['<training_data_file>'],
int(opt['--partitions']),
ranks,
lambdas,
iterations)
if opt['metrics']:
metrics(opt['<training_data_file>'],
opt['<movies_meta_data>'])
if opt['recommend']:
ratings = [float(_rating) for _rating in opt['--ratings'].split(',')]
recommend(training_data_file=opt['<training_data_file>'],
movies_meta_data=opt['<movies_meta_data>'],
user_ratings=ratings,
numPartitions=int(opt['--partitions']),
rank=int(opt['--rank']),
iterations=int(opt['--iteration']),
_lambda=float(opt['--lambda']))
if __name__ == "__main__":
try:
main(sys.argv[1:])
except KeyboardInterrupt:
pass
使用如下的命令即可自动的获取推荐的电影名称,
XXXXXX@trusty:~/software/spark/spark-1.6.0-bin-hadoop2.6/workspace/recommend$ ../../bin/spark-submit recommend.py recommend ratings.dat movies.dat --rank=15 --lambda=0.33 --iteration=3
16/09/20 15:44:37 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/09/20 15:44:37 WARN Utils: Your hostname, trusty resolves to a loopback address: 127.0.1.1; using 192.168.1.254 instead (on interface eth0)
16/09/20 15:44:37 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
16/09/20 15:45:01 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
16/09/20 15:45:01 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS
16/09/20 15:45:02 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeSystemLAPACK
16/09/20 15:45:02 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeRefLAPACK
Goya in Bordeaux (Goya en Bodeos) (1999)
Slums of Beverly Hills, The (1998)
New Jersey Drive (1995)
Bottle Rocket (1996)
I'll Be Home For Christmas (1998)
Big Daddy (1999)
Kurt & Courtney (1998)
Kika (1993)
Forrest Gump (1994)
Reality Bites (1994)
Omega Man, The (1971)
Boogie Nights (1997)
Boiler Room (2000)
Miami Rhapsody (1995)
Bob Roberts (1992)Recommend Algorithms
推荐算法大致可分为如下几类,
+ 基于人口统计学的推荐(Demographic-Based Recommendation):该方法所基于的基本假设是“一个用户有可能会喜欢与其相似的用户所喜欢的物品”。当我们需要对一个User进行个性化推荐时,利用User Profile计算其它用户与其之间的相似度,然后挑选出与其最相似的前K个用户,之后利用这些用户的购买和打分信息进行推荐。
+ 基于内容的推荐(Content-Based Recommendation):Content-Based方法所基于的基本假设是“一个用户可能会喜欢和他曾经喜欢过的物品相似的物品”。
+ 基于协同过滤的推荐(Collaborative Filtering-Based Recommendation):是指收集用户过去的行为以获得其对产品的显式或隐式信息,即根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性、或用户的相关性,然后再基于这些关联性进行推荐。基于协同过滤的推荐可以分基于用户的推荐(User-based Recommendation),基于物品的推荐(Item-based Recommendation),基于模型的推荐(Model-based Recommendation)等子类。
Matrix Factorization
矩阵分解(decomposition, factorization)是将矩阵拆解为数个三角形矩阵(triangular matrix)的一种操作。
Explicit Matrix Factorization
User Ratings数据:
Tom, Star Wars, 5Jane, Titanic, 4Bill, Batman, 3Jane, Star Wars, 2Bill, Titanic, 3
以User为行,Movie为列构造对应Rating Matrix,
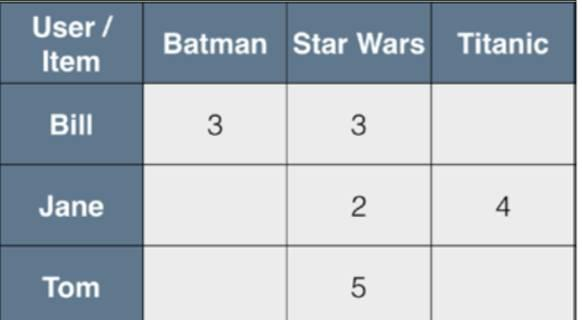
MF就是一种直接建模user-item矩阵的方法,利用两个低维度的小矩阵的乘积来表示,属于一种降维的技术。
如果我们有U个Users,I个Items,若不经过MF处理,它看来会使这样的:
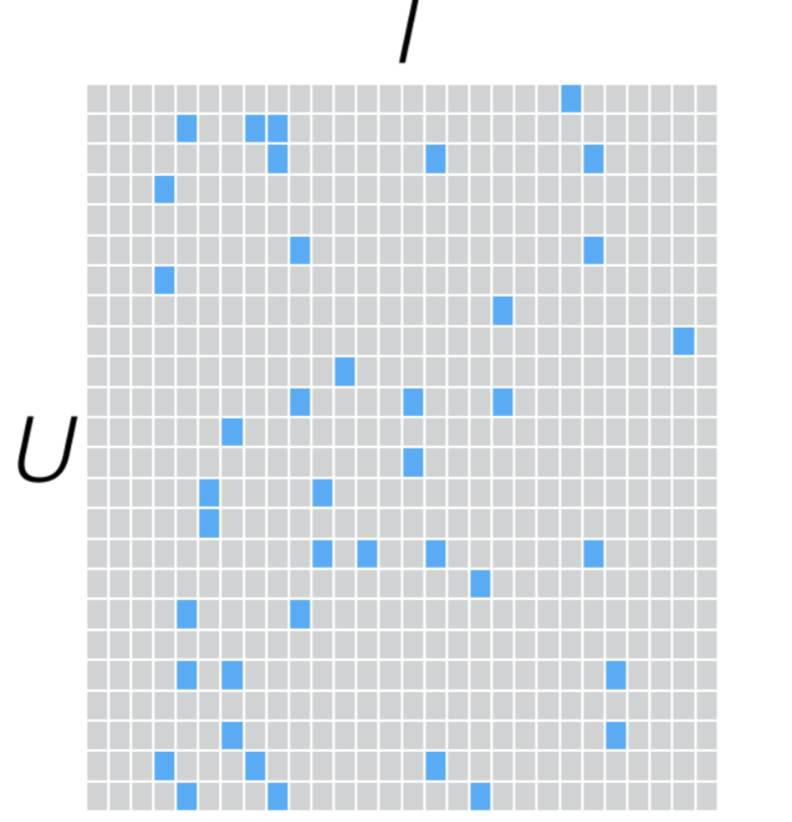
是一个极其稀疏的矩阵,经过MF处理后,表示为两个维度较小的矩阵相乘:
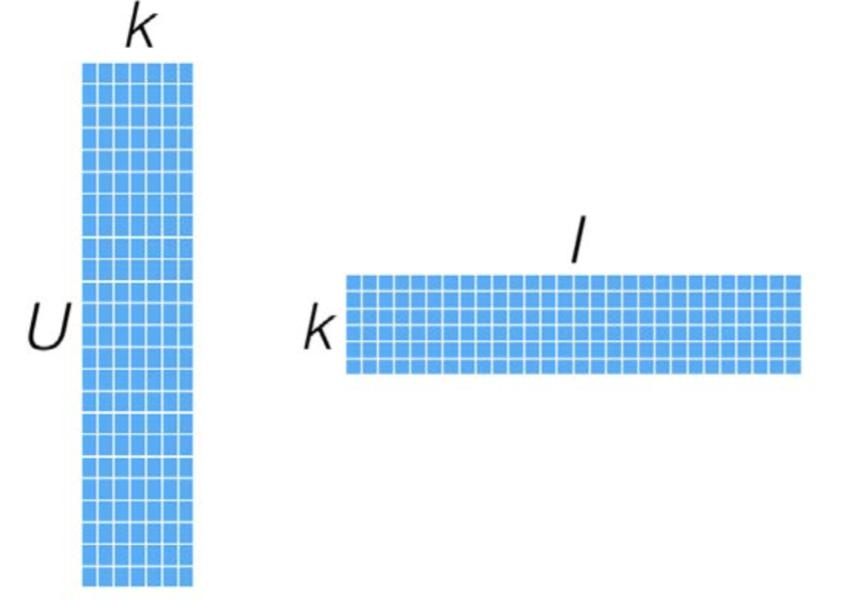
这类模型被称为Latent Feature Models,旨在寻找那些潜在的特征,来间接表示User-Item Rating的矩阵。这类潜在的Features并不直接建模User对Item的Rating关系,而是通过Latent Features更趋近于建模用户对某类Items的偏好,例如某类影片、风格等等,而这些事通过MF寻找其内在的信息,无需Items的详细描述。
MF模型如何计算一个User对某个Item的偏好,对应向量相乘即可:
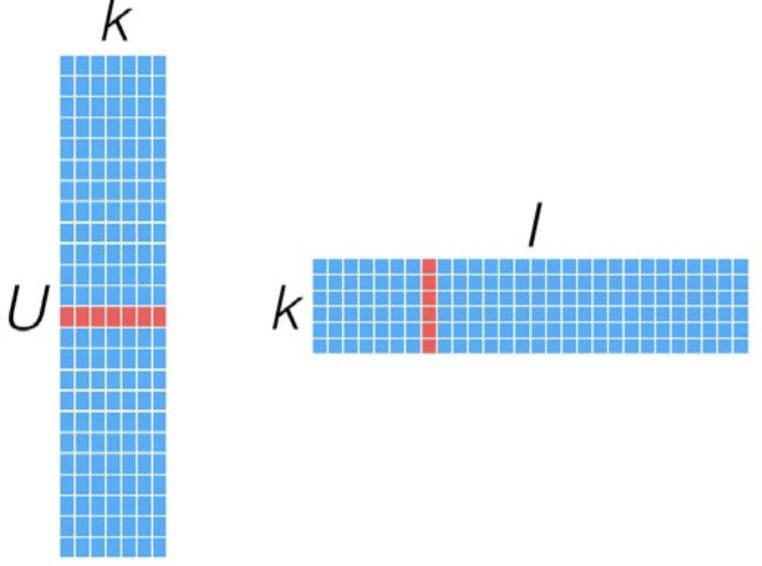
MF模型的好处是一旦模型创建好后,Predict变得十分容易,并且性能也很好.但是在海量的用户和Item Set时,存储和生产MF中的如上图的这两个矩阵会变得具有挑战性。
Implicit Matrix Factorization
前面我们都在讨论显式的一些偏好信息,比如Rating。但是在大部分应用中,拿不到这类信息,我们更多是搜集一些隐性的反馈信息,这类反馈信息没有明确地告诉某个用户对某个Item的偏好信息,但是却可以从用户对某个Item的交互信息中建模出来,例如一些二值特征,包括是否浏览过、是否购买过产品以及多少次看过某部电影等等。
MLlib中提供了一种处理这类隐性特征的方法,将前面的输入Ratings矩阵其实可以看做是两个矩阵:二值偏好矩阵P和信心权重矩阵C;
举个例子:假定我们的网站上面没有设计对Movie的Rating部分,只能通过log查看到用户是否观看过影片。然后通过后期处理,可以看出他观看到过多少次某部影片,这里P来表示影片是否被某用户看过,C来描述这里的Confidence Weighting也就是观看的次数:
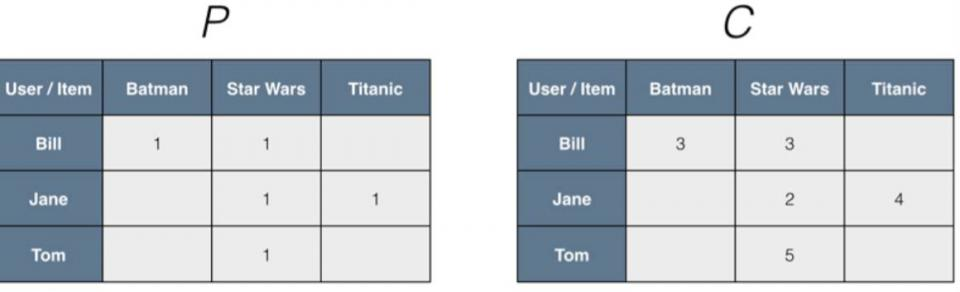
这里我们把P和C的点积来替代前面的rating矩阵,那么我们最终建模来预估某用户对Item的偏好。
ALS Algorithm
ALS是Alternating Least Squares的缩写,意为交替最小二乘法,该方法常用于基于矩阵分解的推荐系统中。
对于一个Users-Products-Rating的评分数据集,ALS会建立一个User和Product的 m×n 的矩阵。其中,m为Users的数量,n为Products的数量。但是在这个数据集中,并不是每个用户都对每个产品进行过评分,所以这个矩阵往往是稀疏的,用户 Ui 对产品 Pj 的评分往往是空的。ALS要解决的问题就是将这个稀疏矩阵通过一定的规律填满,这样就可以从矩阵中得到任意一个User对任意一个Product的评分,ALS填充的评分项也称为用户 Ui 对产品 Pj 的预测得分。所以说,ALS算法的核心就是通过什么样子的规律来填满(预测)这个稀疏矩阵。
例如:将用户(user)对商品(item)的评分矩阵分解为两个矩阵:
- 一个是用户对商品隐含特征的偏好矩阵;
- 另一个是商品所包含的隐含特征的矩阵;
在这个矩阵分解的过程中,评分缺失项得到了填充,也就是说我们可以基于这个填充的评分来给用户最商品推荐了。
由于评分数据中有大量的缺失项,传统的矩阵分解SVD(奇异值分解)不方便处理这个问题,而ALS能够很好的解决这个问题。对于 R(m×n) 的矩阵,ALS旨在找到两个低维矩阵 X(m×k) 和矩阵 Y(n×k) ,来近似逼近 R(m×n) ,即: R≈XYT ,其中, R(m×n) 代表用户对商品的评分矩阵, X(m×k) 代表用户对隐含特征的偏好矩阵, Y(n×k) 表示商品所包含隐含特征的矩阵,T表示矩阵Y的转置。实际中,一般取 k<<min(m,n) ,也就是相当于降维了。这里的低维矩阵,有的地方也叫低秩矩阵。
为了找到低维矩阵X,Y最大程度地逼近矩分矩阵R,最小化下面的平方误差损失函数,
其中, xu(1×k) 表示用户 xu 的偏好的隐含特征向量, yi(1×k) 表示商品 yi 包含的隐含特征向量, rui 表示用户 xu 对商品 yi 的评分,向量 xu 和 yi 的内积 xu×yTi 是用户 xu 对商品 yi 的评分的近似。
为防止过拟合给上述公式加上正则项,公式改下为:
其中, xu∈Rd , yi∈Rd , 1≤u≤m , 1≤i≤n , λ 是正则项的系数。
到这里,协同过滤就成功转化成了一个优化问题。由于变量 xu 和 yi 耦合到一起,这个问题并不好求解,所以我们引入了ALS,也就是说我们可以先固定Y(例如随机初始化X),然后利用公式(2)先求解X,然后固定X,再求解Y,如此交替往复直至收敛,即所谓的交替最小二乘法求解法。
具体的求解方法说明如下:
+ 先固定Y,将损失函数
L(X,Y)
对
xu
求偏导,并令导数等于零,得到:
xu=(YTY+λI)−1YTru
+ 同理固定X,可得:
yi=(XTX+λI)−1XTri
其中, ru(1×n) 是R的第u行, ri(1×m) 是R的第i列,I是 k×k 的单位矩阵。
Iteration Scenario
首先随机初始化Y,利用固定Y后得到的公式更新得到X,然后固定X得到的公式更新Y,直到均方根误差变RMSE化很小或者到达最大迭代次数。
Envaluation
当然,我们不能凭着自己的感觉评价模型的好坏,尽管我们直觉告诉我们,这个结果看上去不错。我们需要量化的指标来评价模型的优劣。我们可以通过计算均方根误差(Root Mean Squared Error, RMSE)来衡量模型的好坏。数理统计中均方根误差是指参数估计值与参数真值之差平方的期望值,记为RMSE,
RMSE是衡量“平均误差”的一种较方便的方法,RMSE可以评价数据的变化程度,RMSE的值越小,说明预测模型描述实验数据具有更好的精确度。
我们可以调整rank,numIterations,lambda,alpha这些参数,不断优化结果,使均方差变小。比如:iterations越多,lambda较小,均方差会较小,推荐结果较优。















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









