







系列文章目录
【x264编码器】章节1——x264编码流程及基于x264的编码器demo
【x264编码器】章节2——x264的lookahead流程分析
【x265编码器】章节2——编码流程及基于x265的编码器demo
目录
1.用于向前向预测模块添加图片x264_lookahead_put_frame
2.将帧数据推入输入帧列表x264_sync_frame_list_push
4.确定每个视频帧的类型lookahead_slicetype_decide
6.实际帧类型分析处理x264_slicetype_analyse
12.帧结构路径成本计算slicetype_path_cost
14.传递宏块树信息mbtree_propagate_list
一、模块功能
在x264中,前向预测(lookahead)是一种技术,用于改善视频编码的效率和质量。x264的前向预测功能涉及分析未来的视频帧,以在当前帧的编码过程中做出更好的决策。
同时也会进行帧内预测和帧间预测,不同点有两点:
1.在1/4的低分辨率情况下(宽和高各是原始的一半),以8x8块进行帧内和帧间预测;
2.帧内和帧间预测时,宏块遍历顺序是逆序的,即从下到上,从右到左,具体可以看slicetype_slice_cost;
代码框架如下:
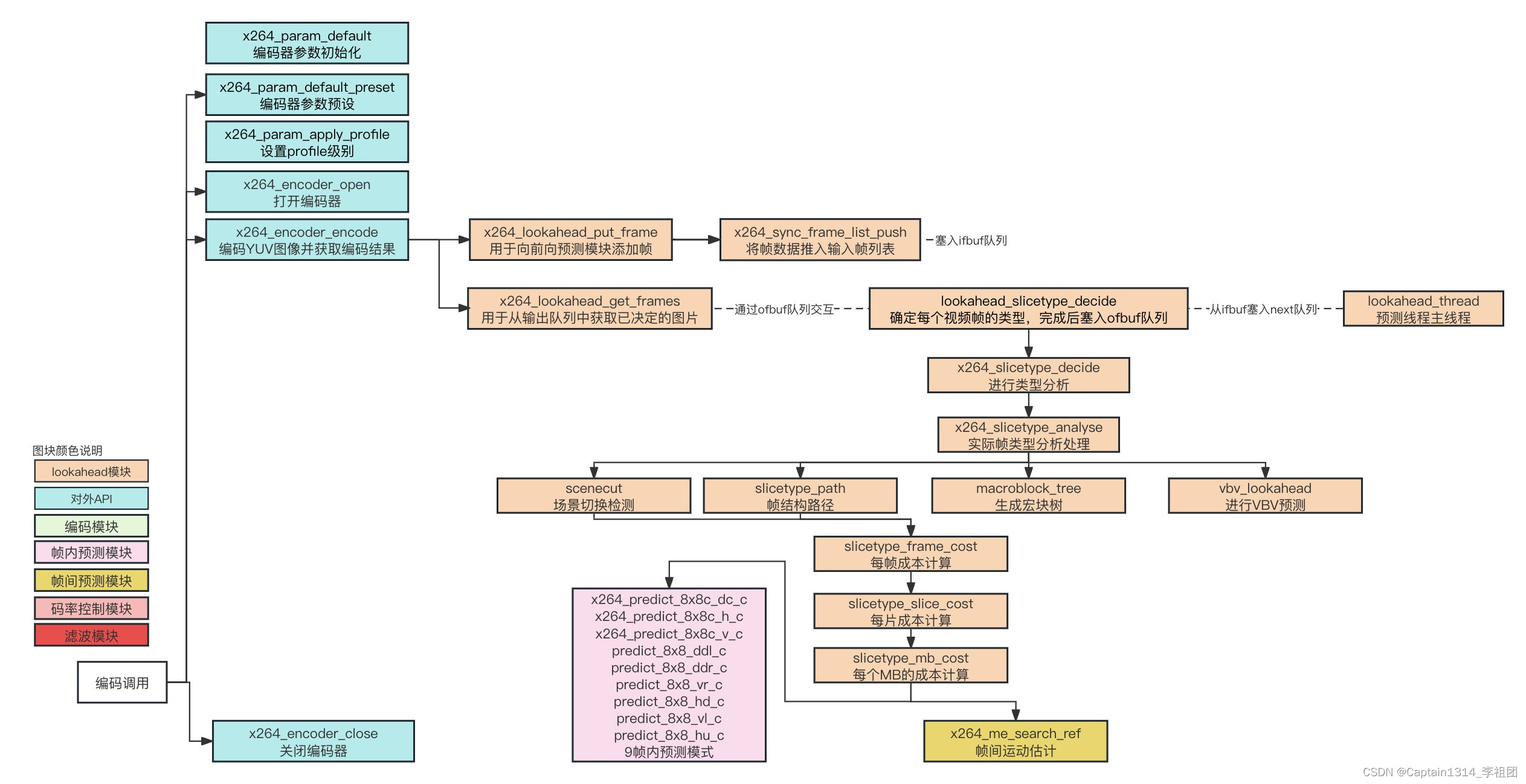
x264完整的流程框架如下:
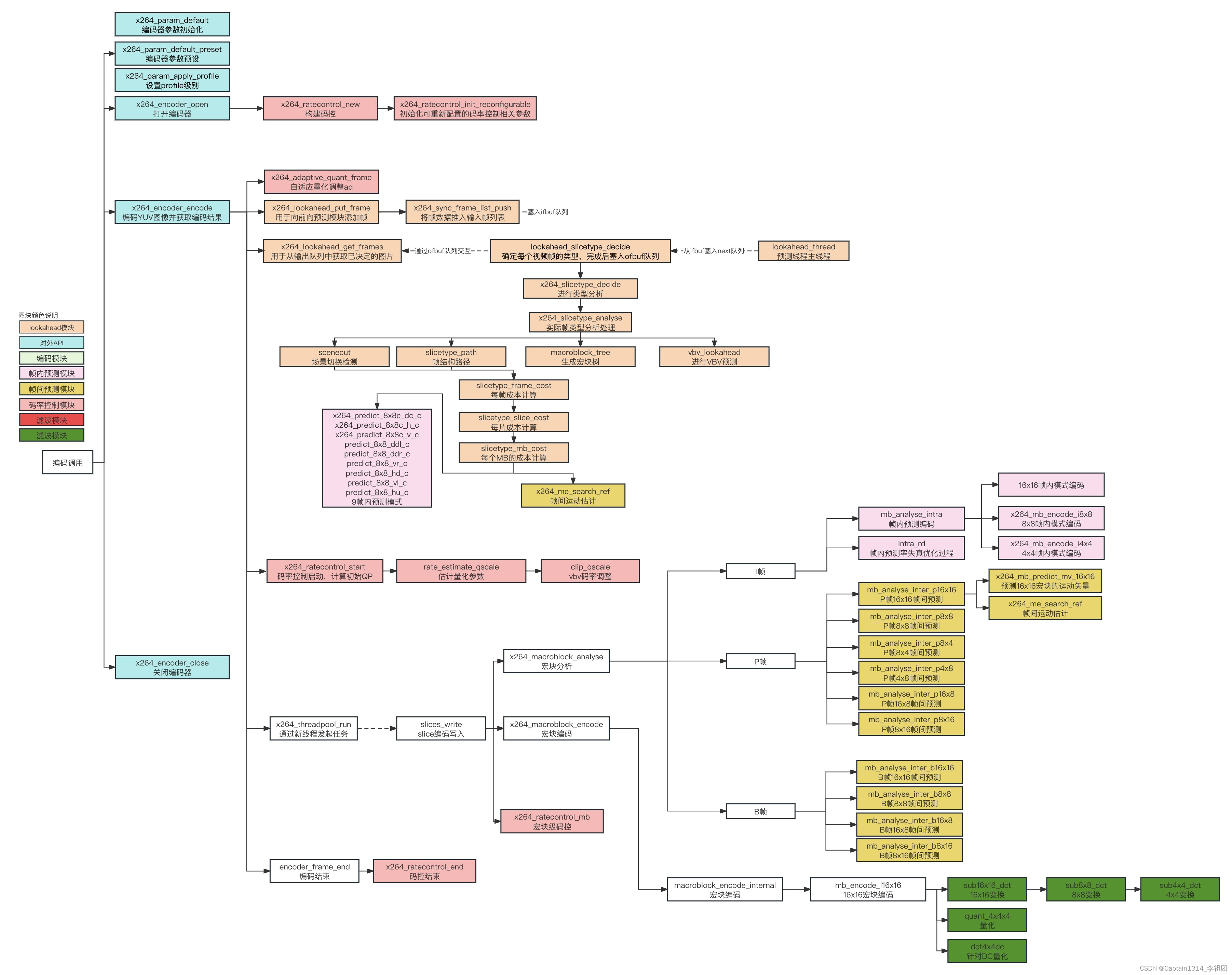
主要实现下面4项处理:
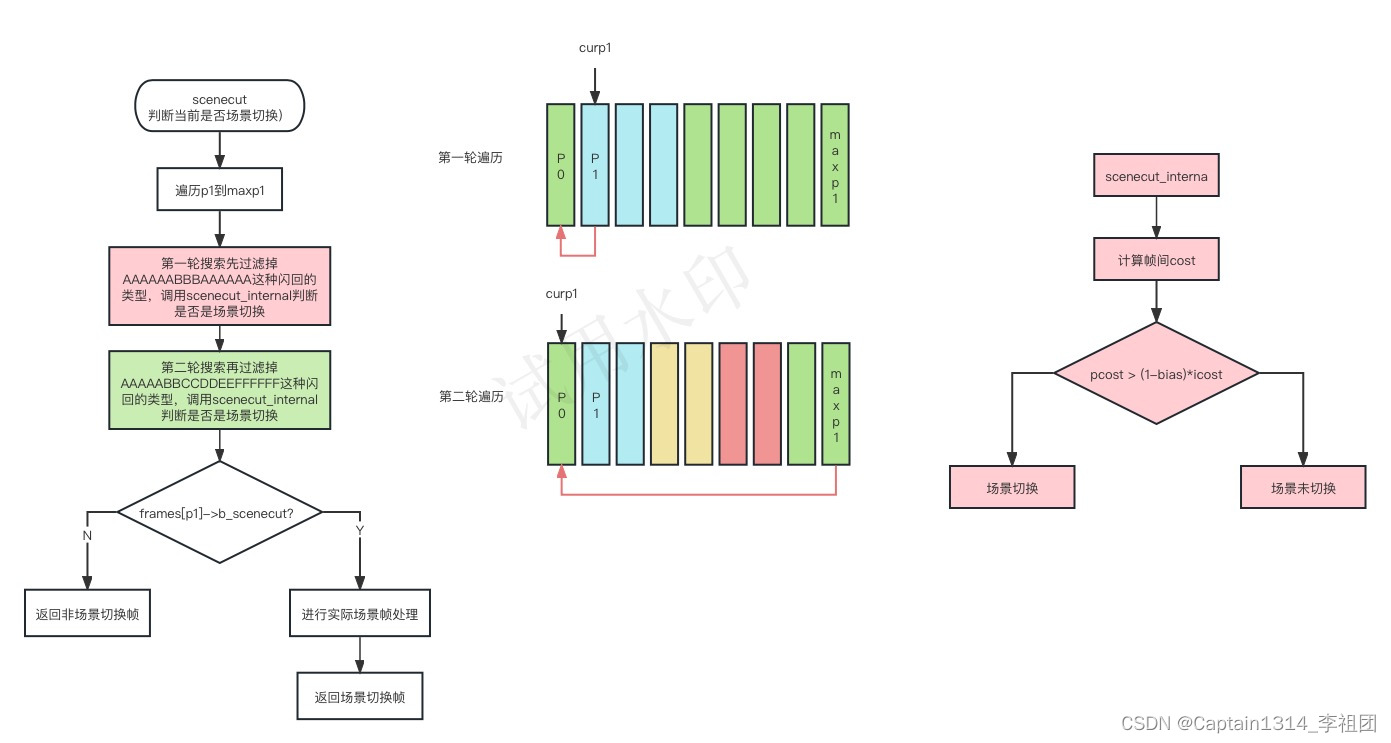
1.场景切换检测
场景切换检测的大体流程如下,详细代码分析见“2-8场景检测scenecut”;
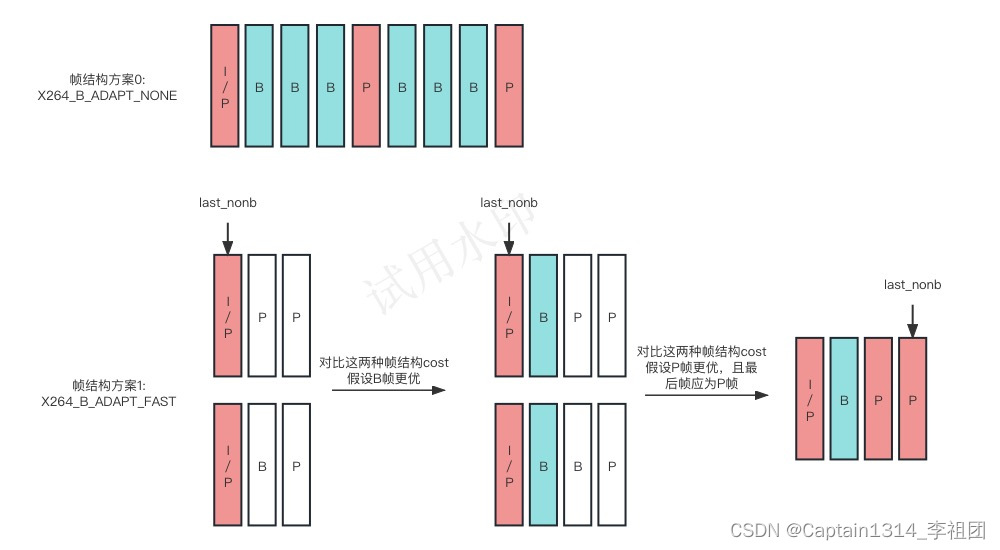
2.帧结构确定
帧结构方案目前有三种,分别是X264_B_ADAPT_NONE、X264_B_ADAPT_FAST和X264_B_ADAPT_TRELLIS,对应的大体流程如下:
X264_B_ADAPT_NONE方案:主要就是按照固定IBBBPBBBP进行展开,对应代码见x264_slicetype_analyse;
X264_B_ADAPT_FAST方案:会每次计算当前帧为B或者P,选取cost最低的帧类型,之后重复往后展开,对应代码见x264_slicetype_analyse;
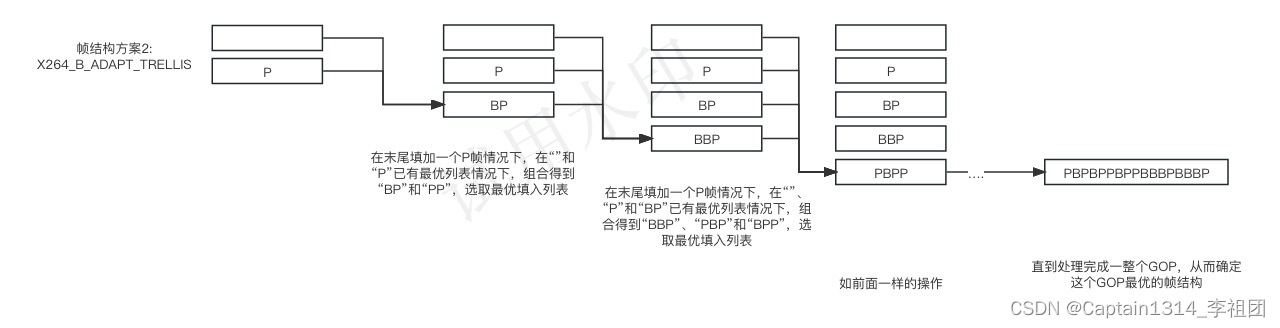
X264_B_ADAPT_TRELLIS方案:会保留前面每次计算得到的最优帧结构方案,从而插入0到bframes逐次的B帧,求得当前长度最优方案,之后再这个基础上,计算长度+1的最优方案,不断迭代,直到处理完整个GOP,对应代码见slicetype_path_cost;
3.MB tree
宏块树比较简单的解释作用就是:帧与帧之间存在参考的关系,如果被参考的帧拥有更高的质量,那么通过调整一个帧,就可以改善一批帧质量,因此MB tree是根据帧被引用得程度,也可以认为是遗传给了其他帧多少信息,作为衡量该帧的重要性;
因为考虑到遗传是可以累加的,所以采用的逆序遍历的方式进行MB tree中遗传信息的计算,比如b参考p0,则p0的遗传信息对应的公式如下:
遗传信息公式 =(propagate_in + intra_cost * inv_qscales*fps_factor) * (1 - inter_cost / intra_cost) * dist_scale_factor
遗传信息要求正值,所以只有inter_cost<intra_cost即选择了帧间预测的CU块才会有,inter_cost越小,intra_cost越大,越会体现遗传信息的重要,因此遗传信息值越大,采用了帧内预测模式的CU块,遗传信息为0;
propagate_in:为当前帧b帧作为其他帧的参考帧,遗传给其他帧的信息,在计算p0的遗传信息的时候,需要加上作为修正;
dist_scale_factor:距离比例,上面公式需要一个距离来修正;
inv_qscales:量化系数,变得模糊的MB携带的信息更少,理应再加一个修正因素。量化的过程就是把系数除以QStep;
fps_factor:针对可变帧率,这每帧占比的时间不同,占比时间长的帧,理应更重要,因此提出这个参数对公式做修正;
对应代码如下,以及mbtree_propagate_list函数中:
//函数接受一些输入参数,包括目标数组dst,传播输入数组propagate_in,帧内成本数组intra_costs,帧间成本数组inter_costs,反量化系数数组inv_qscales,帧率因子fps_factor,以及长度len
/* Estimate the total amount of influence on future quality that could be had if we
* were to improve the reference samples used to inter predict any given macroblock. */
static void mbtree_propagate_cost( int16_t *dst, uint16_t *propagate_in, uint16_t *intra_costs,
uint16_t *inter_costs, uint16_t *inv_qscales, float *fps_factor, int len )
{
float fps = *fps_factor;//获取帧率因子fps
for( int i = 0; i < len; i++ )//遍历一行中的每个宏块
{
int intra_cost = intra_costs[i];//计算帧内成本intra_cost
int inter_cost = X264_MIN(intra_costs[i], inter_costs[i] & LOWRES_COST_MASK);
float propagate_intra = intra_cost * inv_qscales[i];//算帧内遗传量propagate_intra,即帧内成本乘以反量化系数
float propagate_amount = propagate_in[i] + propagate_intra*fps;//计算遗传量propagate_amount,即遗传输入量propagate_in加上帧内传播量乘以帧率因子
float propagate_num = intra_cost - inter_cost;//计算遗传分子propagate_num,即帧内成本减去帧间成本
float propagate_denom = intra_cost;//计算遗传分母propagate_denom,即帧内成本
dst[i] = X264_MIN((int)(propagate_amount * propagate_num / propagate_denom + 0.5f), 32767);//计算目标数组dst[i],即将传播量乘以传播分子除以传播分母并四舍五入后取整,保证结果不超过32767
}
}根据遗传信息调整QP,公式如下:
其中propagate表示遗传给后续帧的信息;intra表示自身的信息;qcompress对外参数代表调整QP的强度,qcompress=0表示完成ABR,QP任意调整,qcompress=1,完全的CBR,固定QP;fpsFactor主要针对可变码率视频,当前帧停留的越久越重要;
对应代码:
static void macroblock_tree_finish( x264_t *h, x264_frame_t *frame, float average_duration, int ref0_distance )
{ //根据平均帧间时长和当前帧的时长,计算帧率因子fps_factor。这个因子用于根据时长的比例来调整传播成本
int fps_factor = round( CLIP_DURATION(average_duration) / CLIP_DURATION(frame->f_duration) * 256 / MBTREE_PRECISION );
float weightdelta = 0.0;
if( ref0_distance && frame->f_weighted_cost_delta[ref0_distance-1] > 0 )//根据参考帧距离和当前帧的加权成本变化,计算权重差值weightdelta
weightdelta = (1.0 - frame->f_weighted_cost_delta[ref0_distance-1]);
/* Allow the strength to be adjusted via qcompress, since the two
* concepts are very similar. *///根据参数中的qcompress(量化压缩)值,计算强度strength。这个强度用于调整log2_ratio的影响
float strength = 5.0f * (1.0f - h->param.rc.f_qcompress);
for( int mb_index = 0; mb_index < h->mb.i_mb_count; mb_index++ )
{ //MB的intra_cost(MB自身包含的信息)
int intra_cost = (frame->i_intra_cost[mb_index] * frame->i_inv_qscale_factor[mb_index] + 128) >> 8;
if( intra_cost )
{ //propagate(遗传给后续帧的信息)
int propagate_cost = (frame->i_propagate_cost[mb_index] * fps_factor + 128) >> 8;
float log2_ratio = x264_log2(intra_cost + propagate_cost) - x264_log2(intra_cost) + weightdelta;
frame->f_qp_offset[mb_index] = frame->f_qp_offset_aq[mb_index] - strength * log2_ratio;
}
}
}4.VBV
通过vbv_lookahead计算低分辨率情况下的i_planned_satd,为实际编码vbv码控时提供数据;
5.大体流程

二、模块代码分析
1.用于向前向预测模块添加图片x264_lookahead_put_frame
用于将帧数据放入预测缓冲区,代码如下:
void x264_lookahead_put_frame( x264_t *h, x264_frame_t *frame )
{ //如果存在预测线程,则调用 x264_sync_frame_list_push 函数,将帧数据 frame 推入预测缓冲区的输入帧列表
if( h->param.i_sync_lookahead )
x264_sync_frame_list_push( &h->lookahead->ifbuf, frame );
else//如果不存在预测线程,则调用 x264_sync_frame_list_push 函数,将帧数据 frame 推入预测缓冲区的下一个帧列表
x264_sync_frame_list_push( &h->lookahead->next, frame );
}2.将帧数据推入输入帧列表x264_sync_frame_list_push
代码如下:
void x264_sync_frame_list_push( x264_sync_frame_list_t *slist, x264_frame_t *frame )
{ //锁定同步帧列表的互斥锁
x264_pthread_mutex_lock( &slist->mutex );
while( slist->i_size == slist->i_max_size )//在同步帧列表的大小达到最大值 slist->i_max_size 时,等待空闲条件变量的信号
x264_pthread_cond_wait( &slist->cv_empty, &slist->mutex );
slist->list[ slist->i_size++ ] = frame;//将帧数据 frame 添加到同步帧列表的末尾,然后递增列表的大小 slist->i_size++
x264_pthread_mutex_unlock( &slist->mutex );//解锁同步帧列表的互斥锁
x264_pthread_cond_broadcast( &slist->cv_fill );//广播填充条件变量的信号,以通知等待该变量的线程可以继续执行
}3.预测线程主线程lookahead_thread
这段代码实现了预测缓冲区线程的主要逻辑,包括帧数据的移动、切片类型的决策以及线程的同步操作,代码如下:
REALIGN_STACK static void *lookahead_thread( x264_t *h )
{
while( 1 )//进入一个无限循环,表示预测缓冲区线程的运行
{
x264_pthread_mutex_lock( &h->lookahead->ifbuf.mutex );//锁定输入帧列表的互斥锁
if( h->lookahead->b_exit_thread )//检查是否需要退出线程
{
x264_pthread_mutex_unlock( &h->lookahead->ifbuf.mutex );
break;
}
x264_pthread_mutex_lock( &h->lookahead->next.mutex );//锁定下一步帧列表的互斥锁
int shift = X264_MIN( h->lookahead->next.i_max_size - h->lookahead->next.i_size, h->lookahead->ifbuf.i_size );//计算需要移动的帧数 shift,取预测缓冲区的帧数和下一步帧列表的剩余空间的较小值
lookahead_shift( &h->lookahead->next, &h->lookahead->ifbuf, shift );//调用 lookahead_shift 函数将帧数据从输入帧列表移动到下一步帧列表
x264_pthread_mutex_unlock( &h->lookahead->next.mutex );//解锁下一步帧列表的互斥锁
if( h->lookahead->next.i_size <= h->lookahead->i_slicetype_length + h->param.b_vfr_input )
{//检查下一个、步帧列表的大小是否小于等于切片类型长度加上参数 b_vfr_input
while( !h->lookahead->ifbuf.i_size && !h->lookahead->b_exit_thread )//在输入帧列表的大小为零且线程不需要退出的情况下,等待填充条件变量的信号
x264_pthread_cond_wait( &h->lookahead->ifbuf.cv_fill, &h->lookahead->ifbuf.mutex );
x264_pthread_mutex_unlock( &h->lookahead->ifbuf.mutex );
}
else
{ //如果下一个帧列表的大小大于切片类型长度加上参数 b_vfr_input
x264_pthread_mutex_unlock( &h->lookahead->ifbuf.mutex );
lookahead_slicetype_decide( h );//进行切片类型的决策
}
} /* end of input frames */
x264_pthread_mutex_lock( &h->lookahead->ifbuf.mutex );//再次锁定输入帧列表和下一步帧列表的互斥锁
x264_pthread_mutex_lock( &h->lookahead->next.mutex );//调用 lookahead_shift 函数将剩余的输入帧移动到下一步帧列表
lookahead_shift( &h->lookahead->next, &h->lookahead->ifbuf, h->lookahead->ifbuf.i_size );
x264_pthread_mutex_unlock( &h->lookahead->next.mutex );//解锁下一步帧列表的互斥锁
x264_pthread_mutex_unlock( &h->lookahead->ifbuf.mutex );//解锁输入帧列表的互斥锁
while( h->lookahead->next.i_size )
lookahead_slicetype_decide( h );//当下一步帧列表仍有帧时,执行切片类型的决策,即调用 lookahead_slicetype_decide 函数
x264_pthread_mutex_lock( &h->lookahead->ofbuf.mutex );//锁定输出帧缓冲区的互斥锁
h->lookahead->b_thread_active = 0;//将预测缓冲区的线程活跃标志 h->lookahead->b_thread_active 设置为0
x264_pthread_cond_broadcast( &h->lookahead->ofbuf.cv_fill );//广播填充条件变量的信号,以通知等待该变量的线程可以继续执行
x264_pthread_mutex_unlock( &h->lookahead->ofbuf.mutex );//解锁输出帧缓冲区的互斥锁
return NULL;
}4.确定每个视频帧的类型lookahead_slicetype_decide
这段代码的作用是在预测缓冲区中对帧进行切片类型的决策,并将决策后的帧移动到输出帧缓冲区中,代码如下:
static void lookahead_slicetype_decide( x264_t *h )
{
x264_slicetype_decide( h );//对当前帧进行切片类型的决策
lookahead_update_last_nonb( h, h->lookahead->next.list[0] );//更新最后一个非 B 帧(非 B-frame)的信息,参数为预测缓冲区的下一步帧列表的第一个帧
int shift_frames = h->lookahead->next.list[0]->i_bframes + 1;//计算需要移动的帧数 shift_frames,取下一步帧列表的第一个帧的 B 帧数加1
//锁定输出帧缓冲区的互斥锁
x264_pthread_mutex_lock( &h->lookahead->ofbuf.mutex );
while( h->lookahead->ofbuf.i_size == h->lookahead->ofbuf.i_max_size )//当输出帧缓冲区的大小达到最大值 h->lookahead->ofbuf.i_max_size 时,等待空闲条件变量的信号
x264_pthread_cond_wait( &h->lookahead->ofbuf.cv_empty, &h->lookahead->ofbuf.mutex );
//锁定下一步帧列表的互斥锁
x264_pthread_mutex_lock( &h->lookahead->next.mutex );
lookahead_shift( &h->lookahead->ofbuf, &h->lookahead->next, shift_frames );//将帧数据从下一步帧列表移动到输出帧缓冲区,移动的帧数为 shift_frames
x264_pthread_mutex_unlock( &h->lookahead->next.mutex );//解锁下一步帧列表的互斥锁
//如果预测缓冲区启用了关键帧分析(MB-tree和VBV lookahead),并且最后一个非 B 帧为 I 帧(帧类型为 I-frame)
/* For MB-tree and VBV lookahead, we have to perform propagation analysis on I-frames too. */
if( h->lookahead->b_analyse_keyframe && IS_X264_TYPE_I( h->lookahead->last_nonb->i_type ) )
x264_slicetype_analyse( h, shift_frames );
x264_pthread_mutex_unlock( &h->lookahead->ofbuf.mutex );//解锁输出帧缓冲区的互斥锁
}5.进行类型分析x264_slicetype_decide
对每帧进行类型分析,代码如下:
void x264_slicetype_decide( x264_t *h )
{
x264_frame_t *frames[X264_BFRAME_MAX+2];
x264_frame_t *frm;
int bframes;
int brefs;
//如果前瞻缓冲区的下一步帧大小为0,就直接返回
if( !h->lookahead->next.i_size )
return;
//获取前瞻缓冲区的下一个步帧的数量,并将其保存在lookahead_size变量中
int lookahead_size = h->lookahead->next.i_size;
//对于前瞻缓冲区中的每个帧
for( int i = 0; i < h->lookahead->next.i_size; i++ )
{
if( h->param.b_vfr_input )
{ //如果使用可变帧率输入 (b_vfr_input),则根据下一个帧的时间戳和当前帧的时间戳计算帧的持续时间
if( lookahead_size-- > 1 )
h->lookahead->next.list[i]->i_duration = 2 * (h->lookahead->next.list[i+1]->i_pts - h->lookahead->next.list[i]->i_pts);
else
h->lookahead->next.list[i]->i_duration = h->i_prev_duration;
}
else//根据帧的i_pic_struct属性选择帧的持续时间
h->lookahead->next.list[i]->i_duration = delta_tfi_divisor[h->lookahead->next.list[i]->i_pic_struct];
h->i_prev_duration = h->lookahead->next.list[i]->i_duration;//更新先前帧的持续时间,并计算帧的时长(f_duration)
h->lookahead->next.list[i]->f_duration = (double)h->lookahead->next.list[i]->i_duration
* h->sps->vui.i_num_units_in_tick
/ h->sps->vui.i_time_scale;
if( h->lookahead->next.list[i]->i_frame > h->i_disp_fields_last_frame && lookahead_size > 0 )
{ //如果帧的帧号大于最后一个显示的帧号,并且前瞻缓冲区还有更多帧,则更新帧的字段计数(i_field_cnt)和最后一个显示的帧号(i_disp_fields_last_frame)
h->lookahead->next.list[i]->i_field_cnt = h->i_disp_fields;
h->i_disp_fields += h->lookahead->next.list[i]->i_duration;
h->i_disp_fields_last_frame = h->lookahead->next.list[i]->i_frame;
}
else if( lookahead_size == 0 )
{ //如果前瞻缓冲区没有更多帧,则更新帧的字段计数(i_field_cnt)和持续时间(i_duration)
h->lookahead->next.list[i]->i_field_cnt = h->i_disp_fields;
h->lookahead->next.list[i]->i_duration = h->i_prev_duration;
}
}
if( h->param.rc.b_stat_read )
{
/* Use the frame types from the first pass */
for( int i = 0; i < h->lookahead->next.i_size; i++ )
h->lookahead->next.list[i]->i_type =
x264_ratecontrol_slice_type( h, h->lookahead->next.list[i]->i_frame );
}
else if( (h->param.i_bframe && h->param.i_bframe_adaptive)//启用了自适应B帧 (i_bframe_adaptive)
|| h->param.i_scenecut_threshold//设置了场景切换阈值
|| h->param.rc.b_mb_tree//启用了宏块树
|| (h->param.rc.i_vbv_buffer_size && h->param.rc.i_lookahead) )//启用了VBV缓冲区大小和前瞻
x264_slicetype_analyse( h, 0 );//使用切片类型分析函数 (x264_slicetype_analyse)对帧进行分析
//通过循环对帧进行处理,直到满足退出条件
for( bframes = 0, brefs = 0;; bframes++ )
{ //获取当前帧 (frm)
frm = h->lookahead->next.list[bframes];
//如果帧的强制类型 (i_forced_type)不是自动类型 (X264_TYPE_AUTO),并且帧的类型与强制类型不匹配,同时不满足特定情况下的类型转换限制,输出警告信息
if( frm->i_forced_type != X264_TYPE_AUTO && frm->i_type != frm->i_forced_type &&
!(frm->i_forced_type == X264_TYPE_KEYFRAME && IS_X264_TYPE_I( frm->i_type )) )
{
x264_log( h, X264_LOG_WARNING, "forced frame type (%d) at %d was changed to frame type (%d)\n",
frm->i_forced_type, frm->i_frame, frm->i_type );
}
//如果帧的类型是B参考帧 (X264_TYPE_BREF),并且B帧金字塔 (i_bframe_pyramid)小于普通模式 (X264_B_PYRAMID_NORMAL),并且当前的B参考帧数已经达到了B帧金字塔的限制,将帧类型更改为B帧,并输出警告信息
if( frm->i_type == X264_TYPE_BREF && h->param.i_bframe_pyramid < X264_B_PYRAMID_NORMAL &&
brefs == h->param.i_bframe_pyramid )
{
frm->i_type = X264_TYPE_B;
x264_log( h, X264_LOG_WARNING, "B-ref at frame %d incompatible with B-pyramid %s \n",
frm->i_frame, x264_b_pyramid_names[h->param.i_bframe_pyramid] );
}
/* pyramid with multiple B-refs needs a big enough dpb that the preceding P-frame stays available.
smaller dpb could be supported by smart enough use of mmco, but it's easier just to forbid it. */
else if( frm->i_type == X264_TYPE_BREF && h->param.i_bframe_pyramid == X264_B_PYRAMID_NORMAL &&
brefs && h->param.i_frame_reference <= (brefs+3) )
{ //如果帧的类型是B参考帧 (X264_TYPE_BREF),并且B帧金字塔 (i_bframe_pyramid)为普通模式,并且当前的B参考帧数已经达到了帧参考帧的限制,将帧类型更改为B帧,并输出警告信息
frm->i_type = X264_TYPE_B;
x264_log( h, X264_LOG_WARNING, "B-ref at frame %d incompatible with B-pyramid %s and %d reference frames\n",
frm->i_frame, x264_b_pyramid_names[h->param.i_bframe_pyramid], h->param.i_frame_reference );
}
//如果帧的类型是关键帧 (X264_TYPE_KEYFRAME),将其类型更改为I帧 (X264_TYPE_I)或IDR帧 (X264_TYPE_IDR),具体取决于是否启用了开放式GOP (b_open_gop)
if( frm->i_type == X264_TYPE_KEYFRAME )
frm->i_type = h->param.b_open_gop ? X264_TYPE_I : X264_TYPE_IDR;
/* Limit GOP size *///限制GOP大小,如果不是帧内刷新 (b_intra_refresh) 或者当前帧与上一个关键帧的间隔超过了最大关键帧间隔 (i_keyint_max),则根据不同情况调整帧的类型,如果需要输出警告信息
if( (!h->param.b_intra_refresh || frm->i_frame == 0) && frm->i_frame - h->lookahead->i_last_keyframe >= h->param.i_keyint_max )
{
if( frm->i_type == X264_TYPE_AUTO || frm->i_type == X264_TYPE_I )
frm->i_type = h->param.b_open_gop && h->lookahead->i_last_keyframe >= 0 ? X264_TYPE_I : X264_TYPE_IDR;
int warn = frm->i_type != X264_TYPE_IDR;
if( warn && h->param.b_open_gop )
warn &= frm->i_type != X264_TYPE_I;
if( warn )
{
x264_log( h, X264_LOG_WARNING, "specified frame type (%d) at %d is not compatible with keyframe interval\n", frm->i_type, frm->i_frame );
frm->i_type = h->param.b_open_gop && h->lookahead->i_last_keyframe >= 0 ? X264_TYPE_I : X264_TYPE_IDR;
}
}//如果帧类型是X264_TYPE_I(即关键帧)并且当前帧的帧号减去前一个关键帧的帧号大于等于参数i_keyint_min(关键帧之间的最小间隔),则执行以下操作
if( frm->i_type == X264_TYPE_I && frm->i_frame - h->lookahead->i_last_keyframe >= h->param.i_keyint_min )
{
if( h->param.b_open_gop )
{ //如果参数b_open_gop为真(开放式GOP),则更新lookahead结构体中的i_last_keyframe为当前帧的帧号,并根据需要进行bluray_compat调整。然后将当前帧标记为关键帧(b_keyframe = 1)
h->lookahead->i_last_keyframe = frm->i_frame; // Use display order
if( h->param.b_bluray_compat )
h->lookahead->i_last_keyframe -= bframes; // Use bluray order
frm->b_keyframe = 1;
}
else//将当前帧的帧类型设置为X264_TYPE_IDR(即即帧间刷新)
frm->i_type = X264_TYPE_IDR;
}
if( frm->i_type == X264_TYPE_IDR )//如果当前帧的帧类型是X264_TYPE_IDR
{
/* Close GOP *///关闭GOP(组图像预测结构)。更新lookahead结构体中的i_last_keyframe为当前帧的帧号,并将当前帧标记为关键帧
h->lookahead->i_last_keyframe = frm->i_frame;
frm->b_keyframe = 1;
if( bframes > 0 )
{ //如果存在B帧(bframes > 0),则减少bframes计数,并将lookahead中下一个帧的类型设置为X264_TYPE_P
bframes--;
h->lookahead->next.list[bframes]->i_type = X264_TYPE_P;
}
}
//如果bframes等于h->param.i_bframe(最大B帧数)或者lookahead->next.list[bframes+1]为空
if( bframes == h->param.i_bframe ||
!h->lookahead->next.list[bframes+1] )
{ //如果当前帧的类型是B帧(IS_X264_TYPE_B(frm->i_type)为真),则输出警告信息,指定的帧类型与最大B帧数不兼容
if( IS_X264_TYPE_B( frm->i_type ) )
x264_log( h, X264_LOG_WARNING, "specified frame type is not compatible with max B-frames\n" );
if( frm->i_type == X264_TYPE_AUTO
|| IS_X264_TYPE_B( frm->i_type ) )
frm->i_type = X264_TYPE_P;//如果当前帧的类型是X264_TYPE_AUTO(自动选择帧类型)或者是B帧类型,则将帧类型设置为X264_TYPE_P
}
//如果当前帧的类型是X264_TYPE_BREF,则增加brefs计数
if( frm->i_type == X264_TYPE_BREF )
brefs++;
//如果当前帧的类型是X264_TYPE_AUTO,则将帧类型设置为X264_TYPE_B
if( frm->i_type == X264_TYPE_AUTO )
frm->i_type = X264_TYPE_B;
//否则,如果当前帧的类型不是B帧类型,则跳出循环(结束处理)
else if( !IS_X264_TYPE_B( frm->i_type ) ) break;
}
//如果bframes大于0,则将lookahead中的前一个帧(h->lookahead->next.list[bframes-1])的b_last_minigop_bframe标志设置为1。这个标志用于表示前一个帧是minigop中的最后一个B帧
if( bframes )
h->lookahead->next.list[bframes-1]->b_last_minigop_bframe = 1;
h->lookahead->next.list[bframes]->i_bframes = bframes;//设置当前帧(h->lookahead->next.list[bframes])的i_bframes为bframes,表示当前帧之后的B帧数
//如果参数i_bframe_pyramid为真,且bframes大于1且brefs为0,则在minigop序列中插入一个B帧参考帧(X264_TYPE_BREF)。这个操作用于构建B帧金字塔结构
/* insert a bref into the sequence */
if( h->param.i_bframe_pyramid && bframes > 1 && !brefs )
{
h->lookahead->next.list[(bframes-1)/2]->i_type = X264_TYPE_BREF;
brefs++;
}
//如果参数rc.i_rc_method不等于X264_RC_CQP(码率控制方法不是恒定QP模式),则在仍然有低分辨率图像的情况下,预先计算帧的成本信息,以供后续的x264_rc_analyse_slice函数使用
/* calculate the frame costs ahead of time for x264_rc_analyse_slice while we still have lowres */
if( h->param.rc.i_rc_method != X264_RC_CQP )
{
x264_mb_analysis_t a;
int p0, p1, b;
p1 = b = bframes + 1;
lowres_context_init( h, &a );
//根据B帧数和P帧数的数量,初始化frames数组。frames[0]为最后一个非B帧,后续的元素为B帧和P帧
frames[0] = h->lookahead->last_nonb;
memcpy( &frames[1], h->lookahead->next.list, (bframes+1) * sizeof(x264_frame_t*) );
if( IS_X264_TYPE_I( h->lookahead->next.list[bframes]->i_type ) )
p0 = bframes + 1;
else // P
p0 = 0;
//调用slicetype_frame_cost函数计算帧的成本信息。根据p0、p1和b的取值,计算不同类型帧的成本
slicetype_frame_cost( h, &a, frames, p0, p1, b );
//如果p0不等于p1或者bframes大于0,并且参数rc.i_vbv_buffer_size不为0(表示使用了VBV缓冲区),则继续计算帧的成本信息
if( (p0 != p1 || bframes) && h->param.rc.i_vbv_buffer_size )
{
/* We need the intra costs for row SATDs. */
slicetype_frame_cost( h, &a, frames, b, b, b );
/* We need B-frame costs for row SATDs. */
p0 = 0;
for( b = 1; b <= bframes; b++ )
{ //在计算B帧成本时,根据B帧的位置,使用循环逐个计算不同B帧的成本
if( frames[b]->i_type == X264_TYPE_B )
for( p1 = b; frames[p1]->i_type == X264_TYPE_B; )
p1++;
else
p1 = bframes + 1;
slicetype_frame_cost( h, &a, frames, p0, p1, b );
if( frames[b]->i_type == X264_TYPE_BREF )
p0 = b;
}
}
}
//如果条件满足,即参数rc.b_stat_read为假、next帧的类型为X264_TYPE_P(P帧)且参数analyse.i_weighted_pred大于等于X264_WEIGHTP_SIMPLE,则进行加权P帧的分析
/* Analyse for weighted P frames */
if( !h->param.rc.b_stat_read && h->lookahead->next.list[bframes]->i_type == X264_TYPE_P
&& h->param.analyse.i_weighted_pred >= X264_WEIGHTP_SIMPLE )
{
x264_emms();
x264_weights_analyse( h, h->lookahead->next.list[bframes], h->lookahead->last_nonb, 0 );//调用x264_weights_analyse函数对P帧进行加权预测分析
}
//将帧序列按照编码顺序进行移动。为了避免整个next缓冲区的移动,使用一个小的临时列表进行操作
/* shift sequence to coded order.
use a small temporary list to avoid shifting the entire next buffer around */
int i_coded = h->lookahead->next.list[0]->i_frame;
if( bframes )//然后根据B帧和B帧参考帧的数量,将帧按照类型的顺序放入frames数组中
{
int idx_list[] = { brefs+1, 1 };
for( int i = 0; i < bframes; i++ )
{ //对于B帧参考帧,放在idx_list[0]位置;对于B帧,放在idx_list[1]位置
int idx = idx_list[h->lookahead->next.list[i]->i_type == X264_TYPE_BREF]++;
frames[idx] = h->lookahead->next.list[i];
frames[idx]->i_reordered_pts = h->lookahead->next.list[idx]->i_pts;
}
frames[0] = h->lookahead->next.list[bframes];
frames[0]->i_reordered_pts = h->lookahead->next.list[0]->i_pts;
memcpy( h->lookahead->next.list, frames, (bframes+1) * sizeof(x264_frame_t*) );//后将frames数组中的帧复制回lookahead->next.list数组
}
for( int i = 0; i <= bframes; i++ )
{ //对于每个帧,设置i_coded值为递增的i_coded++
h->lookahead->next.list[i]->i_coded = i_coded++;
if( i )//如果不是第一个帧
{ //则计算帧的持续时间,并更新h->lookahead->next.list[0]->f_planned_cpb_duration[i-1]的值
calculate_durations( h, h->lookahead->next.list[i], h->lookahead->next.list[i-1], &h->i_cpb_delay, &h->i_coded_fields );
h->lookahead->next.list[0]->f_planned_cpb_duration[i-1] = (double)h->lookahead->next.list[i]->i_cpb_duration *
h->sps->vui.i_num_units_in_tick / h->sps->vui.i_time_scale;
}
else//如果是第一个帧(i = 0),则只计算帧的持续时间
calculate_durations( h, h->lookahead->next.list[i], NULL, &h->i_cpb_delay, &h->i_coded_fields );
}
}6.实际帧类型分析处理x264_slicetype_analyse
代码如下:
void x264_slicetype_analyse( x264_t *h, int intra_minigop )
{
x264_mb_analysis_t a;
x264_frame_t *frames[X264_LOOKAHEAD_MAX+3] = { NULL, };
int num_frames, orig_num_frames, keyint_limit, framecnt;
int i_max_search = X264_MIN( h->lookahead->next.i_size, X264_LOOKAHEAD_MAX );
int b_vbv_lookahead = h->param.rc.i_vbv_buffer_size && h->param.rc.i_lookahead;
/* For determinism we should limit the search to the number of frames lookahead has for sure
* in h->lookahead->next.list buffer, except at the end of stream.
* For normal calls with (intra_minigop == 0) that is h->lookahead->i_slicetype_length + 1 frames.
* And for I-frame calls (intra_minigop != 0) we already removed intra_minigop frames from there. */
if( h->param.b_deterministic )
i_max_search = X264_MIN( i_max_search, h->lookahead->i_slicetype_length + 1 - intra_minigop );
int keyframe = !!intra_minigop;
assert( h->frames.b_have_lowres );
//检查是否需要进行分析。如果h->lookahead->last_nonb为空,即没有非B帧可用,则直接返回
if( !h->lookahead->last_nonb )
return;
frames[0] = h->lookahead->last_nonb;//设置frames数组的第一个元素为h->lookahead->last_nonb,后续元素为h->lookahead->next.list中的帧
for( framecnt = 0; framecnt < i_max_search; framecnt++ )
frames[framecnt+1] = h->lookahead->next.list[framecnt];
//初始化低分辨率分析上下文
lowres_context_init( h, &a );
if( !framecnt )
{ //如果没有要分析的帧(framecnt为0),并且启用了宏块树分析(h->param.rc.b_mb_tree),则执行宏块树分析(macroblock_tree)并返回
if( h->param.rc.b_mb_tree )
macroblock_tree( h, &a, frames, 0, keyframe );
return;
}
//计算关键帧的限制(keyint_limit),即离关键帧的最大帧数
keyint_limit = h->param.i_keyint_max - frames[0]->i_frame + h->lookahead->i_last_keyframe - 1;
orig_num_frames = num_frames = h->param.b_intra_refresh ? framecnt : X264_MIN( framecnt, keyint_limit );
/* This is important psy-wise: if we have a non-scenecut keyframe,
* there will be significant visual artifacts if the frames just before
* go down in quality due to being referenced less, despite it being
* more RD-optimal. *///根据情况更新要分析的帧的数量(num_frames)
if( (h->param.analyse.b_psy && h->param.rc.b_mb_tree) || b_vbv_lookahead )
num_frames = framecnt;
else if( h->param.b_open_gop && num_frames < framecnt )
num_frames++;
else if( num_frames == 0 )
{
frames[1]->i_type = X264_TYPE_I;
return;
}
//如果帧的类型为自动选择或I帧,并且启用了场景切换检测(h->param.i_scenecut_threshold),则执行场景切换检测
if( IS_X264_TYPE_AUTO_OR_I( frames[1]->i_type ) &&
h->param.i_scenecut_threshold && scenecut( h, &a, frames, 0, 1, 1, orig_num_frames, i_max_search ) )
{ //如果帧的类型为自动选择,并且场景切换检测结果需要选择I帧,则将帧的类型设置为I帧
if( frames[1]->i_type == X264_TYPE_AUTO )
frames[1]->i_type = X264_TYPE_I;
return;
}
#if HAVE_OPENCL
x264_opencl_slicetype_prep( h, frames, num_frames, a.i_lambda );
#endif
/* Replace forced keyframes with I/IDR-frames */
for( int j = 1; j <= num_frames; j++ )
{ //将强制关键帧(X264_TYPE_KEYFRAME)替换为I帧或IDR帧,具体取决于是否启用了开放式GOP(b_open_gop)
if( frames[j]->i_type == X264_TYPE_KEYFRAME )
frames[j]->i_type = h->param.b_open_gop ? X264_TYPE_I : X264_TYPE_IDR;
}
/* Close GOP at IDR-frames */
for( int j = 2; j <= num_frames; j++ )
{ //在IDR帧之前的帧中,如果前一帧是自动选择或B帧,则将其类型设置为P帧
if( frames[j]->i_type == X264_TYPE_IDR && IS_X264_TYPE_AUTO_OR_B( frames[j-1]->i_type ) )
frames[j-1]->i_type = X264_TYPE_P;
}
//更新分析的帧数
int num_analysed_frames = num_frames;
int reset_start;
//如果启用了B帧(h->param.i_bframe),则根据不同的B帧自适应模式执行不同的操作
if( h->param.i_bframe )
{ //如果B帧自适应模式为X264_B_ADAPT_TRELLIS
if( h->param.i_bframe_adaptive == X264_B_ADAPT_TRELLIS )
{
if( num_frames > 1 )
{ //初始化best_paths数组,用于存储最佳路径
char best_paths[X264_BFRAME_MAX+1][X264_LOOKAHEAD_MAX+1] = {"","P"};
int best_path_index = num_frames % (X264_BFRAME_MAX+1);
/* Perform the frametype analysis. */
for( int j = 2; j <= num_frames; j++ )//对帧进行分析,选择最佳路径
slicetype_path( h, &a, frames, j, best_paths );
//根据最佳路径的结果,更新帧的类型
/* Load the results of the analysis into the frame types. */
for( int j = 1; j < num_frames; j++ )
{ //因为best_paths的计数和frames是不一样的,所以是从j-1上获取进行赋值
if( best_paths[best_path_index][j-1] != 'B' )
{
if( IS_X264_TYPE_AUTO_OR_B( frames[j]->i_type ) )
frames[j]->i_type = X264_TYPE_P;
}
else
{
if( frames[j]->i_type == X264_TYPE_AUTO )
frames[j]->i_type = X264_TYPE_B;
}
}
}
}//如果B帧自适应模式为X264_B_ADAPT_FAST
else if( h->param.i_bframe_adaptive == X264_B_ADAPT_FAST )
{
int last_nonb = 0;
int num_bframes = h->param.i_bframe;
char path[X264_LOOKAHEAD_MAX+1];
for( int j = 1; j < num_frames; j++ )
{ //检查前一帧的类型是否为 B 帧(B-frame),如果是,则减少 num_bframes 的计数
if( j-1 > 0 && IS_X264_TYPE_B( frames[j-1]->i_type ) )
num_bframes--;
else
{ //如果前一帧的类型不是 B 帧,则将 last_nonb 设置为前一帧的索引,并将 num_bframes 重置为参数 i_bframe 的值
last_nonb = j-1;
num_bframes = h->param.i_bframe;
}
if( !num_bframes )
{ //如果 num_bframes 为零,则检查当前帧的类型是否为自动或 B 帧。如果是,则将当前帧的类型设置为 P 帧(P-frame),然后继续下一次循环
if( IS_X264_TYPE_AUTO_OR_B( frames[j]->i_type ) )
frames[j]->i_type = X264_TYPE_P;
continue;
}
//如果当前帧的类型不是自动类型,则继续下一次循环
if( frames[j]->i_type != X264_TYPE_AUTO )
continue;
if( IS_X264_TYPE_B( frames[j+1]->i_type ) )
{ //如果当前帧的下一帧类型为 B 帧,则将当前帧的类型设置为 P 帧,然后继续下一次循环
frames[j]->i_type = X264_TYPE_P;
continue;
}
//对帧进行分析,选择最佳路径
int bframes = j - last_nonb - 1;
memset( path, 'B', bframes );
strcpy( path+bframes, "PP" );
uint64_t cost_p = slicetype_path_cost( h, &a, frames+last_nonb, path, COST_MAX64 );
strcpy( path+bframes, "BP" );
uint64_t cost_b = slicetype_path_cost( h, &a, frames+last_nonb, path, cost_p );
//根据最佳路径的结果,更新帧的类型
if( cost_b < cost_p )
frames[j]->i_type = X264_TYPE_B;
else
frames[j]->i_type = X264_TYPE_P;
}
}
else//如果B帧自适应模式为其他值
{
int num_bframes = h->param.i_bframe;
for( int j = 1; j < num_frames; j++ )
{ //对帧进行分析,根据规则更新帧的类型
if( !num_bframes )
{
if( IS_X264_TYPE_AUTO_OR_B( frames[j]->i_type ) )
frames[j]->i_type = X264_TYPE_P;
}
else if( frames[j]->i_type == X264_TYPE_AUTO )
{
if( IS_X264_TYPE_B( frames[j+1]->i_type ) )
frames[j]->i_type = X264_TYPE_P;
else
frames[j]->i_type = X264_TYPE_B;
}
if( IS_X264_TYPE_B( frames[j]->i_type ) )
num_bframes--;
else
num_bframes = h->param.i_bframe;
}
}//检查最后一帧的类型,如果是自动选择或B帧,则将其类型设置为P帧
if( IS_X264_TYPE_AUTO_OR_B( frames[num_frames]->i_type ) )
frames[num_frames]->i_type = X264_TYPE_P;
//计算连续B帧的数量(num_bframes)
int num_bframes = 0;
while( num_bframes < num_frames && IS_X264_TYPE_B( frames[num_bframes+1]->i_type ) )
num_bframes++;
//在第一个minigop中检查场景切换
/* Check scenecut on the first minigop. */
for( int j = 1; j < num_bframes+1; j++ )
{ //如果当前帧和下一帧的强制类型为自动选择或I帧,并且启用了场景切换阈值(h->param.i_scenecut_threshold),则进行场景切换检测
if( frames[j]->i_forced_type == X264_TYPE_AUTO && IS_X264_TYPE_AUTO_OR_I( frames[j+1]->i_forced_type ) &&
h->param.i_scenecut_threshold && scenecut( h, &a, frames, j, j+1, 0, orig_num_frames, i_max_search ) )
{ //如果满足场景切换的条件,则将当前帧的类型设置为P帧
frames[j]->i_type = X264_TYPE_P;
num_analysed_frames = j;
break;
}
}
//设置重置的起始帧(reset_start),根据是否为关键帧和帧类型的分析结果决定
reset_start = keyframe ? 1 : X264_MIN( num_bframes+2, num_analysed_frames+1 );
}
else
{ //如果没有启用B帧,将所有帧的类型设置为P帧
for( int j = 1; j <= num_frames; j++ )
if( IS_X264_TYPE_AUTO_OR_B( frames[j]->i_type ) )
frames[j]->i_type = X264_TYPE_P;
reset_start = !keyframe + 1;
}
//如果启用了宏块树分析(h->param.rc.b_mb_tree),则对宏块树进行分析,最多分析到最大关键帧间隔(h->param.i_keyint_max)或实际帧数(num_frames)的较小值
/* Perform the actual macroblock tree analysis.
* Don't go farther than the maximum keyframe interval; this helps in short GOPs. */
if( h->param.rc.b_mb_tree )
macroblock_tree( h, &a, frames, X264_MIN(num_frames, h->param.i_keyint_max), keyframe );
//如果没有启用帧内刷新(h->param.b_intra_refresh),执行关键帧限制操作
/* Enforce keyframe limit. */
if( !h->param.b_intra_refresh )
{ //获取上一个关键帧的帧号
int last_keyframe = h->lookahead->i_last_keyframe;
int last_possible = 0;
for( int j = 1; j <= num_frames; j++ )
{
x264_frame_t *frm = frames[j];
int keyframe_dist = frm->i_frame - last_keyframe;//遍历每一帧,计算当前帧与上一个关键帧的帧间距
if( IS_X264_TYPE_AUTO_OR_I( frm->i_forced_type ) )
{ //如果当前帧的强制类型为自动选择或I帧,并且前一帧不是B帧,则将last_possible设置为当前帧的索引
if( h->param.b_open_gop || !IS_X264_TYPE_B( frames[j-1]->i_forced_type ) )
last_possible = j;
}//如果keyframe_dist大于等于最大关键帧间隔
if( keyframe_dist >= h->param.i_keyint_max )
{ //如果last_possible不为0且不等于当前帧的索引,将j设置为last_possible,重新获取帧和帧间距
if( last_possible != 0 && last_possible != j )
{
j = last_possible;
frm = frames[j];
keyframe_dist = frm->i_frame - last_keyframe;
}
last_possible = 0;
if( frm->i_type != X264_TYPE_IDR )//如果当前帧的类型不是IDR帧(X264_TYPE_IDR),根据b_open_gop参数判断将当前帧的类型设置为I帧(X264_TYPE_I)或IDR帧
frm->i_type = h->param.b_open_gop ? X264_TYPE_I : X264_TYPE_IDR;
}//如果当前帧的类型是I帧且keyframe_dist大于等于最小关键帧间隔
if( frm->i_type == X264_TYPE_I && keyframe_dist >= h->param.i_keyint_min )
{
if( h->param.b_open_gop )
{ //如果b_open_gop为真,更新last_keyframe为当前帧的帧号
last_keyframe = frm->i_frame;
if( h->param.b_bluray_compat )
{
// Use bluray order
int bframes = 0;
while( bframes < j-1 && IS_X264_TYPE_B( frames[j-1-bframes]->i_type ) )
bframes++;
last_keyframe -= bframes;
}
}//如果b_open_gop为假且当前帧的强制类型不是I帧,将当前帧的类型设置为IDR帧
else if( frm->i_forced_type != X264_TYPE_I )
frm->i_type = X264_TYPE_IDR;
}
if( frm->i_type == X264_TYPE_IDR )
{ //如果当前帧的类型是IDR帧,更新last_keyframe为当前帧的帧号,并且如果上一帧是B帧,则将上一帧的类型设置为P帧
last_keyframe = frm->i_frame;
if( j > 1 && IS_X264_TYPE_B( frames[j-1]->i_type ) )
frames[j-1]->i_type = X264_TYPE_P;
}
}
}
//如果启用了vbv_lookahead,则执行vbv_lookahead函数对帧进行处理
if( b_vbv_lookahead )
vbv_lookahead( h, &a, frames, num_frames, keyframe );
//恢复所有尚未确定帧类型的帧的类型,将其类型设置为强制类型
/* Restore frametypes for all frames that haven't actually been decided yet. */
for( int j = reset_start; j <= num_frames; j++ )
frames[j]->i_type = frames[j]->i_forced_type;
#if HAVE_OPENCL
x264_opencl_slicetype_end( h );
#endif
}7.进行VBV预测vbv_lookahead
代码如下:
static void vbv_lookahead( x264_t *h, x264_mb_analysis_t *a, x264_frame_t **frames, int num_frames, int keyframe )
{ //初始化变量last_nonb和cur_nonb,用于记录最后一个非B帧和当前非B帧的索引。同时初始化变量idx为0,用于记录帧的索引
int last_nonb = 0, cur_nonb = 1, idx = 0;
x264_frame_t *prev_frame = NULL;
int prev_frame_idx = 0;
while( cur_nonb < num_frames && IS_X264_TYPE_B( frames[cur_nonb]->i_type ) )
cur_nonb++;//在while循环中,通过判断帧类型是否为B帧(IS_X264_TYPE_B)来找到下一个非B帧的索引。如果找到,则将next_nonb设置为该索引
int next_nonb = keyframe ? last_nonb : cur_nonb;
//如果frames[cur_nonb]的i_coded_fields_lookahead大于等于0
if( frames[cur_nonb]->i_coded_fields_lookahead >= 0 )
{
h->i_coded_fields_lookahead = frames[cur_nonb]->i_coded_fields_lookahead;
h->i_cpb_delay_lookahead = frames[cur_nonb]->i_cpb_delay_lookahead;
}
while( cur_nonb < num_frames )
{ //在while循环中,处理P帧和I帧的成本估计
/* P/I cost: This shouldn't include the cost of next_nonb */
if( next_nonb != cur_nonb )
{ //计算当前帧与下一个非B帧之间的成本,将成本值存储到frames[next_nonb]的i_planned_satd和i_planned_type数组中
int p0 = IS_X264_TYPE_I( frames[cur_nonb]->i_type ) ? cur_nonb : last_nonb;
frames[next_nonb]->i_planned_satd[idx] = vbv_frame_cost( h, a, frames, p0, cur_nonb, cur_nonb );
frames[next_nonb]->i_planned_type[idx] = frames[cur_nonb]->i_type;
frames[cur_nonb]->i_coded_fields_lookahead = h->i_coded_fields_lookahead;
frames[cur_nonb]->i_cpb_delay_lookahead = h->i_cpb_delay_lookahead;
calculate_durations( h, frames[cur_nonb], prev_frame, &h->i_cpb_delay_lookahead, &h->i_coded_fields_lookahead );
if( prev_frame )
{ //计算帧的持续时间,将持续时间存储到frames[next_nonb]的f_planned_cpb_duration数组中。
frames[next_nonb]->f_planned_cpb_duration[prev_frame_idx] = (double)prev_frame->i_cpb_duration *
h->sps->vui.i_num_units_in_tick / h->sps->vui.i_time_scale;
}
frames[next_nonb]->f_planned_cpb_duration[idx] = (double)frames[cur_nonb]->i_cpb_duration *
h->sps->vui.i_num_units_in_tick / h->sps->vui.i_time_scale;
prev_frame = frames[cur_nonb];//更新prev_frame和prev_frame_idx的值
prev_frame_idx = idx;
idx++;
}
/* Handle the B-frames: coded order */
for( int i = last_nonb+1; i < cur_nonb; i++, idx++ )
{ //在for循环中,处理B帧的成本估计。遍历last_nonb+1到cur_nonb之间的帧,计算这些帧与下一个非B帧之间的成本
frames[next_nonb]->i_planned_satd[idx] = vbv_frame_cost( h, a, frames, last_nonb, cur_nonb, i );
frames[next_nonb]->i_planned_type[idx] = X264_TYPE_B;
frames[i]->i_coded_fields_lookahead = h->i_coded_fields_lookahead;
frames[i]->i_cpb_delay_lookahead = h->i_cpb_delay_lookahead;
calculate_durations( h, frames[i], prev_frame, &h->i_cpb_delay_lookahead, &h->i_coded_fields_lookahead );
if( prev_frame )
{
frames[next_nonb]->f_planned_cpb_duration[prev_frame_idx] = (double)prev_frame->i_cpb_duration *
h->sps->vui.i_num_units_in_tick / h->sps->vui.i_time_scale;
}
frames[next_nonb]->f_planned_cpb_duration[idx] = (double)frames[i]->i_cpb_duration *
h->sps->vui.i_num_units_in_tick / h->sps->vui.i_time_scale;
prev_frame = frames[i];
prev_frame_idx = idx;
}//更新last_nonb和cur_nonb的值,继续查找下一个非B帧的索引,直到遍历完所有帧
last_nonb = cur_nonb;
cur_nonb++;
while( cur_nonb <= num_frames && IS_X264_TYPE_B( frames[cur_nonb]->i_type ) )
cur_nonb++;
}//在frames[next_nonb]的i_planned_type数组中将最后一个元素设置为X264_TYPE_AUTO,表示预测的帧类型为自动选择类型
frames[next_nonb]->i_planned_type[idx] = X264_TYPE_AUTO;
}8.场景检测scenecut
场景切件的流程判断如下:
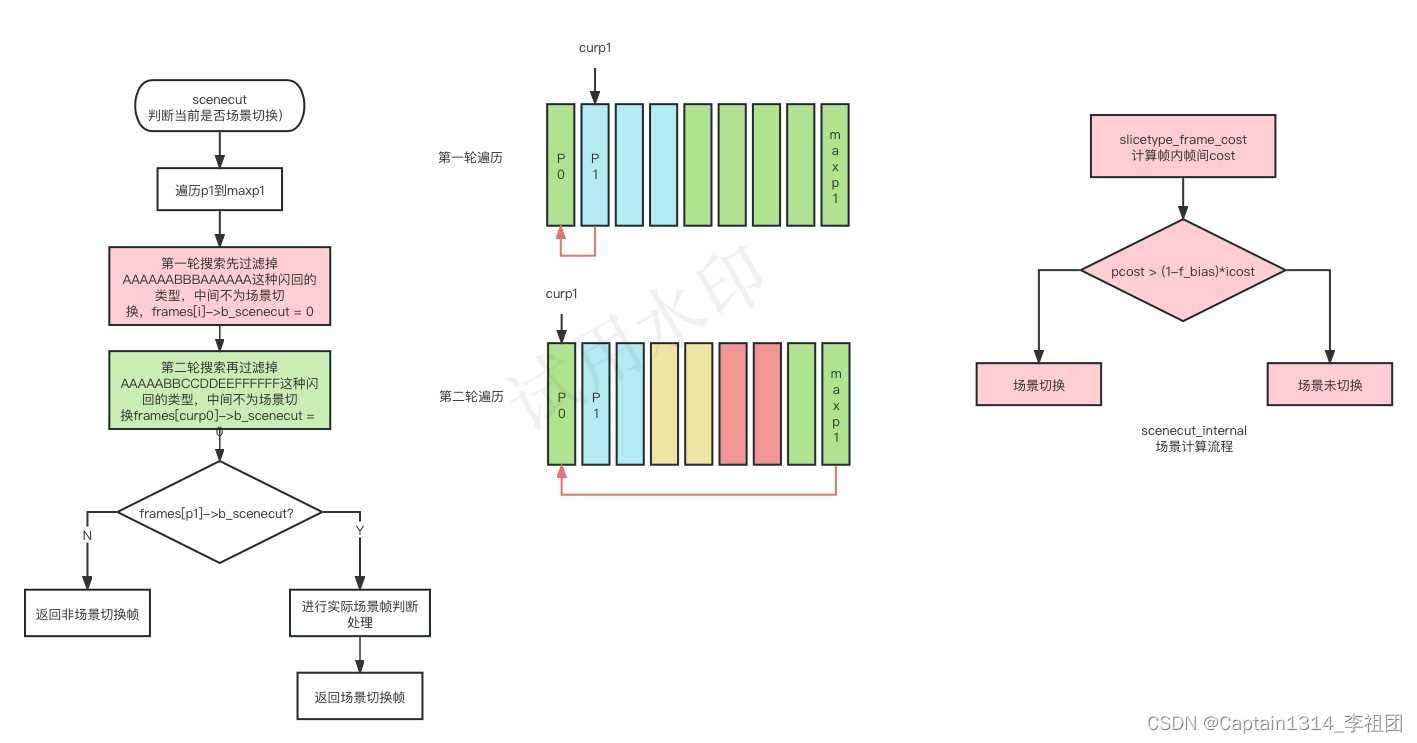
代码如下:
static int scenecut( x264_t *h, x264_mb_analysis_t *a, x264_frame_t **frames, int p0, int p1, int real_scenecut, int num_frames, int i_max_search )
{ //如果 real_scenecut 为真且 h->param.i_bframe 不为零,才进行场景切换分析。这表示只有在进行正常的场景切换检测时才执行下面的代码块
/* Only do analysis during a normal scenecut check. */
if( real_scenecut && h->param.i_bframe )
{
int origmaxp1 = p0 + 1;//根据不同的情况,确定场景切换检测的最大范围 maxp1
/* Look ahead to avoid coding short flashes as scenecuts. */
if( h->param.i_bframe_adaptive == X264_B_ADAPT_TRELLIS )
/* Don't analyse any more frames than the trellis would have covered. */
origmaxp1 += h->param.i_bframe;
else
origmaxp1++;
int maxp1 = X264_MIN( origmaxp1, num_frames );
/* Where A and B are scenes: AAAAAABBBAAAAAA
* If BBB is shorter than (maxp1-p0), it is detected as a flash
* and not considered a scenecut. *///需要避免出现这种闪回认为是场景的情况
for( int curp1 = p1; curp1 <= maxp1; curp1++ )
if( !scenecut_internal( h, a, frames, p0, curp1, 0 ) )
/* Any frame in between p0 and cur_p1 cannot be a real scenecut. */
for( int i = curp1; i > p0; i-- )//使用循环遍历从 p1 到 maxp1 之间的每个帧,并调用 scenecut_internal 函数进行场景切换检测
frames[i]->b_scenecut = 0;
/* Where A-F are scenes: AAAAABBCCDDEEFFFFFF
* If each of BB ... EE are shorter than (maxp1-p0), they are
* detected as flashes and not considered scenecuts.
* Instead, the first F frame becomes a scenecut.
* If the video ends before F, no frame becomes a scenecut. */
for( int curp0 = p0; curp0 <= maxp1; curp0++ )//用循环遍历从 p0 到 maxp1 之间的每个帧
if( origmaxp1 > i_max_search || (curp0 < maxp1 && scenecut_internal( h, a, frames, curp0, maxp1, 0 )) )
/* If cur_p0 is the p0 of a scenecut, it cannot be the p1 of a scenecut. */
frames[curp0]->b_scenecut = 0;
}
//最后,检查 p1 对应的帧是否被标记为场景切换帧。如果是,则调用 scenecut_internal 函数进行真正的场景切换检测
/* Ignore frames that are part of a flash, i.e. cannot be real scenecuts. */
if( !frames[p1]->b_scenecut )
return 0;
return scenecut_internal( h, a, frames, p0, p1, real_scenecut );
}9.每帧成本计算slicetype_frame_cost
代码如下:
static int slicetype_frame_cost( x264_t *h, x264_mb_analysis_t *a,
x264_frame_t **frames, int p0, int p1, int b )
{
int i_score = 0;
int do_search[2];//用于指示是否需要进行低分辨率运动搜索
const x264_weight_t *w = x264_weight_none;//权重信息
x264_frame_t *fenc = frames[b];//当前帧
//检查是否已经对该帧进行了评估,即检查fenc->i_cost_est[b - p0][p1 - b]的值是否大于等于0,并且检查是否已经计算了当前帧的行SATD值。
/* Check whether we already evaluated this frame
* If we have tried this frame as P, then we have also tried
* the preceding frames as B. (is this still true?) */
/* Also check that we already calculated the row SATDs for the current frame. */
if( fenc->i_cost_est[b-p0][p1-b] >= 0 && (!h->param.rc.i_vbv_buffer_size || fenc->i_row_satds[b-p0][p1-b][0] != -1) )
i_score = fenc->i_cost_est[b-p0][p1-b];//如果已经评估过,则直接将i_score设置为fenc->i_cost_est[b - p0][p1 - b]的值
else
{
int dist_scale_factor = 128;//初始化dist_scale_factor为128
//对于每个列表,检查是否需要对参考帧进行低分辨率运动搜索。do_search[0]表示是否需要对p0帧进行搜索,do_search[1]表示是否需要对p1帧进行搜索
/* For each list, check to see whether we have lowres motion-searched this reference frame before. */
do_search[0] = b != p0 && fenc->lowres_mvs[0][b-p0-1][0][0] == 0x7FFF;
do_search[1] = b != p1 && fenc->lowres_mvs[1][p1-b-1][0][0] == 0x7FFF;
if( do_search[0] )
{ //如果do_search[0]为真,并且h->param.analyse.i_weighted_pred为真且b等于p1,则执行加权分析(x264_weights_analyse)并将权重信息赋值给w
if( h->param.analyse.i_weighted_pred && b == p1 )
{
x264_emms();
x264_weights_analyse( h, fenc, frames[p0], 1 );
w = fenc->weight[0];
}
fenc->lowres_mvs[0][b-p0-1][0][0] = 0;
}//更新fenc->lowres_mvs数组,赋初值
if( do_search[1] ) fenc->lowres_mvs[1][p1-b-1][0][0] = 0;
if( p1 != p0 )//计算dist_scale_factor的值,用于调整运动搜索的距离因子
dist_scale_factor = ( ((b-p0) << 8) + ((p1-p0) >> 1) ) / (p1-p0);
int output_buf_size = h->mb.i_mb_height + (NUM_INTS + PAD_SIZE) * h->param.i_lookahead_threads;
int *output_inter[X264_LOOKAHEAD_THREAD_MAX+1];
int *output_intra[X264_LOOKAHEAD_THREAD_MAX+1];
output_inter[0] = h->scratch_buffer2;
output_intra[0] = output_inter[0] + output_buf_size;
#if HAVE_OPENCL
if( h->param.b_opencl )
{
x264_opencl_lowres_init(h, fenc, a->i_lambda );
if( do_search[0] )
{
x264_opencl_lowres_init( h, frames[p0], a->i_lambda );
x264_opencl_motionsearch( h, frames, b, p0, 0, a->i_lambda, w );
}
if( do_search[1] )
{
x264_opencl_lowres_init( h, frames[p1], a->i_lambda );
x264_opencl_motionsearch( h, frames, b, p1, 1, a->i_lambda, NULL );
}
if( b != p0 )
x264_opencl_finalize_cost( h, a->i_lambda, frames, p0, p1, b, dist_scale_factor );
x264_opencl_flush( h );
i_score = fenc->i_cost_est[b-p0][p1-b];
}
else
#endif
{
if( h->param.i_lookahead_threads > 1 )//表示启用了多线程的前向预测处理
{
x264_slicetype_slice_t s[X264_LOOKAHEAD_THREAD_MAX];
for( int i = 0; i < h->param.i_lookahead_threads; i++ )
{ //代码通过循环创建 h->param.i_lookahead_threads 个线程,并为每个线程分配不同的任务
x264_t *t = h->lookahead_thread[i];
/* FIXME move this somewhere else */
t->mb.i_me_method = h->mb.i_me_method;
t->mb.i_subpel_refine = h->mb.i_subpel_refine;
t->mb.b_chroma_me = h->mb.b_chroma_me;
//每个线程的任务由 x264_slicetype_slice_t 结构体表示,结构体中包含了一些参数和数据,用于传递给线程函数 slicetype_slice_cost
s[i] = (x264_slicetype_slice_t){ t, a, frames, p0, p1, b, dist_scale_factor, do_search, w,
output_inter[i], output_intra[i] };
//计算了当前线程的切片(slice)范围 t->i_threadslice_start 和 t->i_threadslice_end,并根据切片高度分配了输出缓冲区的空间
t->i_threadslice_start = ((h->mb.i_mb_height * i + h->param.i_lookahead_threads/2) / h->param.i_lookahead_threads);
t->i_threadslice_end = ((h->mb.i_mb_height * (i+1) + h->param.i_lookahead_threads/2) / h->param.i_lookahead_threads);
int thread_height = t->i_threadslice_end - t->i_threadslice_start;
int thread_output_size = thread_height + NUM_INTS;
memset( output_inter[i], 0, thread_output_size * sizeof(int) );
memset( output_intra[i], 0, thread_output_size * sizeof(int) );
output_inter[i][NUM_ROWS] = output_intra[i][NUM_ROWS] = thread_height;
output_inter[i+1] = output_inter[i] + thread_output_size + PAD_SIZE;
output_intra[i+1] = output_intra[i] + thread_output_size + PAD_SIZE;
//调用了线程池的函数 x264_threadpool_run,将当前线程的任务信息和线程函数 slicetype_slice_cost 提交给线程池执行
x264_threadpool_run( h->lookaheadpool, (void*)slicetype_slice_cost, &s[i] );
}
for( int i = 0; i < h->param.i_lookahead_threads; i++ )
x264_threadpool_wait( h->lookaheadpool, &s[i] );
}
else//表示没有启用多线程的前向预测处理,代码将在当前线程中执行片类型成本的计算
{ //首先,设置了当前线程的切片范围 h->i_threadslice_start 和 h->i_threadslice_end,然后分配了输出缓冲区的空间
h->i_threadslice_start = 0;
h->i_threadslice_end = h->mb.i_mb_height;
memset( output_inter[0], 0, (output_buf_size - PAD_SIZE) * sizeof(int) );
memset( output_intra[0], 0, (output_buf_size - PAD_SIZE) * sizeof(int) );
output_inter[0][NUM_ROWS] = output_intra[0][NUM_ROWS] = h->mb.i_mb_height;
x264_slicetype_slice_t s = (x264_slicetype_slice_t){ h, a, frames, p0, p1, b, dist_scale_factor, do_search, w,
output_inter[0], output_intra[0] };
slicetype_slice_cost( &s );//执行片类型成本的计算
}
/* Sum up accumulators */
if( b == p1 )//果 b 等于 p1,则将 fenc->i_intra_mbs[b-p0] 设为0
fenc->i_intra_mbs[b-p0] = 0;
if( !fenc->b_intra_calculated )
{ //如果为假,则将 fenc->i_cost_est[0][0] 和 fenc->i_cost_est_aq[0][0] 设为0
fenc->i_cost_est[0][0] = 0;
fenc->i_cost_est_aq[0][0] = 0;
}
fenc->i_cost_est[b-p0][p1-b] = 0;
fenc->i_cost_est_aq[b-p0][p1-b] = 0;
int *row_satd_inter = fenc->i_row_satds[b-p0][p1-b];
int *row_satd_intra = fenc->i_row_satds[0][0];
for( int i = 0; i < h->param.i_lookahead_threads; i++ )
{
if( b == p1 )//如果只有前向
fenc->i_intra_mbs[b-p0] += output_inter[i][INTRA_MBS];
if( !fenc->b_intra_calculated )
{ //帧内cost累加
fenc->i_cost_est[0][0] += output_intra[i][COST_EST];
fenc->i_cost_est_aq[0][0] += output_intra[i][COST_EST_AQ];
}
//帧间cost累加
fenc->i_cost_est[b-p0][p1-b] += output_inter[i][COST_EST];
fenc->i_cost_est_aq[b-p0][p1-b] += output_inter[i][COST_EST_AQ];
if( h->param.rc.i_vbv_buffer_size )
{
int row_count = output_inter[i][NUM_ROWS];
memcpy( row_satd_inter, output_inter[i] + NUM_INTS, row_count * sizeof(int) );
if( !fenc->b_intra_calculated )
memcpy( row_satd_intra, output_intra[i] + NUM_INTS, row_count * sizeof(int) );
row_satd_inter += row_count;
row_satd_intra += row_count;
}
}
i_score = fenc->i_cost_est[b-p0][p1-b];
if( b != p1 )//是否对B帧后向参考的做偏移调整
i_score = (uint64_t)i_score * 100 / (120 + h->param.i_bframe_bias);
else
fenc->b_intra_calculated = 1;//标识帧内已经计算过
fenc->i_cost_est[b-p0][p1-b] = i_score;
x264_emms();
}
}
return i_score;
}10.每片成本计算slicetype_slice_cost
宏块的遍历顺序逆序进行,从下至上,从右到左,代码如下:
static void slicetype_slice_cost( x264_slicetype_slice_t *s )
{
x264_t *h = s->h;
/* Lowres lookahead goes backwards because the MVs are used as predictors in the main encode.
* This considerably improves MV prediction overall. */
/* The edge mbs seem to reduce the predictive quality of the
* whole frame's score, but are needed for a spatial distribution. *///do_edges的值根据一系列条件判断而确定,用于控制是否在边缘MB上进行处理
int do_edges = h->param.rc.b_mb_tree || h->param.rc.i_vbv_buffer_size || h->mb.i_mb_width <= 2 || h->mb.i_mb_height <= 2;
//反向进行,start_y和end_y用于确定循环的y方向起始和结束位置
int start_y = X264_MIN( h->i_threadslice_end - 1, h->mb.i_mb_height - 2 + do_edges );
int end_y = X264_MAX( h->i_threadslice_start, 1 - do_edges );
int start_x = h->mb.i_mb_width - 2 + do_edges;
int end_x = 1 - do_edges;//start_x和end_x用于确定循环的x方向起始和结束位置
//通过两层循环,从起始位置逐渐递减地遍历MB的坐标。循环中调用了slicetype_mb_cost函数,该函数用于计算每个MB的成本
for( h->mb.i_mb_y = start_y; h->mb.i_mb_y >= end_y; h->mb.i_mb_y-- )
for( h->mb.i_mb_x = start_x; h->mb.i_mb_x >= end_x; h->mb.i_mb_x-- )
slicetype_mb_cost( h, s->a, s->frames, s->p0, s->p1, s->b, s->dist_scale_factor,
s->do_search, s->w, s->output_inter, s->output_intra );
}11.每个MB的成本计算slicetype_mb_cost
宏块的遍历顺序是从帧右下角往左上角逆序执行,对应的宏块为低像素8x8块,总的流程:
1.根据前后参考帧是否一致,判断是否只需要进行帧内预测模式,若是则跳到第;否则继续执行;
2.通过 b_bidir 判读是否执行第一次双向预测,如果后向参考帧已经经过前向预测,则直接获取同位的宏块的前向运动矢量结果,根据前向参考帧、当前帧和后向参考帧的距离信息,计算得到当前帧当前宏块的前向和后向预测运动矢量;否则,直接使用0值运动矢量;
3.使用 TRY_BIDIR 进行双向预测,如果是非零值运动矢量,则额外再进行一次零值运动矢量的双向预测;
4.遍历前向预测和后向预测,将当前宏块右边、下面、左下和右下块的mv将入到mvc候选列表中,并进行运动搜索;
5.在最优mv为非零值的情况下进行双向预测;
6.进行帧内预测,遍历9种帧内预测方式;
7.更新并记录最低cost和最优MV;
代码如下:
static void slicetype_mb_cost( x264_t *h, x264_mb_analysis_t *a,
x264_frame_t **frames, int p0, int p1, int b,
int dist_scale_factor, int do_search[2], const x264_weight_t *w,
int *output_inter, int *output_intra )
{ //fref0、fref1和fenc分别指向frames数组中的帧数据:前向参考帧、后向参考帧、当前帧
x264_frame_t *fref0 = frames[p0];
x264_frame_t *fref1 = frames[p1];
x264_frame_t *fenc = frames[b];
const int b_bidir = (b < p1);//判断是否进行双向
const int i_mb_x = h->mb.i_mb_x;//i_mb_x和i_mb_y分别表示当前MB的x和y坐标
const int i_mb_y = h->mb.i_mb_y;
const int i_mb_stride = h->mb.i_mb_width;
const int i_mb_xy = i_mb_x + i_mb_y * i_mb_stride;//i_mb_xy表示MB在一维数组中的索引
const int i_stride = fenc->i_stride_lowres;
const int i_pel_offset = 8 * (i_mb_x + i_mb_y * i_stride);
const int i_bipred_weight = h->param.analyse.b_weighted_bipred ? 64 - (dist_scale_factor>>2) : 32;//i_bipred_weight根据配置参数确定加权双向预测的权重
int16_t (*fenc_mvs[2])[2] = { b != p0 ? &fenc->lowres_mvs[0][b-p0-1][i_mb_xy] : NULL, b != p1 ? &fenc->lowres_mvs[1][p1-b-1][i_mb_xy] : NULL };
int (*fenc_costs[2]) = { b != p0 ? &fenc->lowres_mv_costs[0][b-p0-1][i_mb_xy] : NULL, b != p1 ? &fenc->lowres_mv_costs[1][p1-b-1][i_mb_xy] : NULL };
int b_frame_score_mb = (i_mb_x > 0 && i_mb_x < h->mb.i_mb_width - 1 &&
i_mb_y > 0 && i_mb_y < h->mb.i_mb_height - 1) ||
h->mb.i_mb_width <= 2 || h->mb.i_mb_height <= 2;//b_frame_score_mb用于判断是否需要对当前MB进行处理
ALIGNED_ARRAY_16( pixel, pix1,[9*FDEC_STRIDE] );
pixel *pix2 = pix1+8;
x264_me_t m[2];
int i_bcost = COST_MAX;
int list_used = 0;
/* A small, arbitrary bias to avoid VBV problems caused by zero-residual lookahead blocks. */
int lowres_penalty = 4;//一种小的、任意的偏置,以避免由零残差先行块引起的VBV问题
//拷贝对应MB数据,由于进行过下采样,所以是8x8大小
h->mb.pic.p_fenc[0] = h->mb.pic.fenc_buf;
h->mc.copy[PIXEL_8x8]( h->mb.pic.p_fenc[0], FENC_STRIDE, &fenc->lowres[0][i_pel_offset], i_stride, 8 );
if( p0 == p1 )//如果只需要进行帧内模式
goto lowres_intra_mb;
//运动矢量的限制范围
int mv_range = 2 * h->param.analyse.i_mv_range;
// no need for h->mb.mv_min[]
h->mb.mv_min_spel[0] = X264_MAX( 4*(-8*h->mb.i_mb_x - 12), -mv_range );
h->mb.mv_max_spel[0] = X264_MIN( 4*(8*(h->mb.i_mb_width - h->mb.i_mb_x - 1) + 12), mv_range-1 );
h->mb.mv_limit_fpel[0][0] = h->mb.mv_min_spel[0] >> 2;
h->mb.mv_limit_fpel[1][0] = h->mb.mv_max_spel[0] >> 2;
if( h->mb.i_mb_x >= h->mb.i_mb_width - 2 )
{
h->mb.mv_min_spel[1] = X264_MAX( 4*(-8*h->mb.i_mb_y - 12), -mv_range );
h->mb.mv_max_spel[1] = X264_MIN( 4*(8*( h->mb.i_mb_height - h->mb.i_mb_y - 1) + 12), mv_range-1 );
h->mb.mv_limit_fpel[0][1] = h->mb.mv_min_spel[1] >> 2;
h->mb.mv_limit_fpel[1][1] = h->mb.mv_max_spel[1] >> 2;
}
#define LOAD_HPELS_LUMA(dst, src) \
{ \
(dst)[0] = &(src)[0][i_pel_offset]; \
(dst)[1] = &(src)[1][i_pel_offset]; \
(dst)[2] = &(src)[2][i_pel_offset]; \
(dst)[3] = &(src)[3][i_pel_offset]; \
}
#define LOAD_WPELS_LUMA(dst,src) \
(dst) = &(src)[i_pel_offset];
//用于将运动矢量进行限制范围的裁剪
#define CLIP_MV( mv ) \
{ \
mv[0] = x264_clip3( mv[0], h->mb.mv_min_spel[0], h->mb.mv_max_spel[0] ); \
mv[1] = x264_clip3( mv[1], h->mb.mv_min_spel[1], h->mb.mv_max_spel[1] ); \
}
#define TRY_BIDIR( mv0, mv1, penalty ) \
{ \
int i_cost; \
if( h->param.analyse.i_subpel_refine <= 1 ) \
{ \
int hpel_idx1 = (((mv0)[0]&2)>>1) + ((mv0)[1]&2); \
int hpel_idx2 = (((mv1)[0]&2)>>1) + ((mv1)[1]&2); \
pixel *src1 = m[0].p_fref[hpel_idx1] + ((mv0)[0]>>2) + ((mv0)[1]>>2) * m[0].i_stride[0]; \
pixel *src2 = m[1].p_fref[hpel_idx2] + ((mv1)[0]>>2) + ((mv1)[1]>>2) * m[1].i_stride[0]; \
h->mc.avg[PIXEL_8x8]( pix1, 16, src1, m[0].i_stride[0], src2, m[1].i_stride[0], i_bipred_weight ); \
} \
else \
{ \
intptr_t stride1 = 16, stride2 = 16; \
pixel *src1, *src2; \
src1 = h->mc.get_ref( pix1, &stride1, m[0].p_fref, m[0].i_stride[0], \
(mv0)[0], (mv0)[1], 8, 8, w ); \
src2 = h->mc.get_ref( pix2, &stride2, m[1].p_fref, m[1].i_stride[0], \
(mv1)[0], (mv1)[1], 8, 8, w ); \
h->mc.avg[PIXEL_8x8]( pix1, 16, src1, stride1, src2, stride2, i_bipred_weight ); \
} \
i_cost = penalty * a->i_lambda + h->pixf.mbcmp[PIXEL_8x8]( \
m[0].p_fenc[0], FENC_STRIDE, pix1, 16 ); \
COPY2_IF_LT( i_bcost, i_cost, list_used, 3 ); \
}
m[0].i_pixel = PIXEL_8x8;//设置为PIXEL_8x8,表示处理的像素块大小为8x8
m[0].p_cost_mv = a->p_cost_mv;//指向一个代价模型的函数指针,用于计算运动矢量的代价
m[0].i_stride[0] = i_stride;//设置为i_stride,表示输入图像的跨度
m[0].p_fenc[0] = h->mb.pic.p_fenc[0];//指向编码帧的亮度分量
m[0].weight = w;//设置为w,表示权重
m[0].i_ref = 0;//设置为0,表示参考帧索引为0
LOAD_HPELS_LUMA( m[0].p_fref, fref0->lowres );//通过宏LOAD_HPELS_LUMA加载参考帧的低分辨率亮度分量
m[0].p_fref_w = m[0].p_fref[0];//表示加权后的低分辨率亮度分量
if( w[0].weightfn )
LOAD_WPELS_LUMA( m[0].p_fref_w, fenc->weighted[0] );//使用宏LOAD_WPELS_LUMA加载加权后的参考帧像素
if( b_bidir )
{
ALIGNED_ARRAY_8( int16_t, dmv,[2],[2] );//用于存储运动矢量
m[1].i_pixel = PIXEL_8x8;//设置为PIXEL_8x8,表示处理的像素块大小为8x8
m[1].p_cost_mv = a->p_cost_mv;//指向一个代价模型的函数指针,用于计算运动矢量的代价
m[1].i_stride[0] = i_stride;//设置为i_stride,表示输入图像的跨度
m[1].p_fenc[0] = h->mb.pic.p_fenc[0];//指向编码帧的亮度分量
m[1].i_ref = 0;//设置为0,表示参考帧索引为0
m[1].weight = x264_weight_none;//设置为x264_weight_none,表示无权重
LOAD_HPELS_LUMA( m[1].p_fref, fref1->lowres );//通过宏LOAD_HPELS_LUMA加载后向参考帧的低分辨率亮度分量
m[1].p_fref_w = m[1].p_fref[0];//表示加权后的低分辨率亮度分量
if( fref1->lowres_mvs[0][p1-p0-1][0][0] != 0x7FFF )//判断后向参考帧,是否已经经过前向预测
{ //如果第二个参考帧的运动矢量不等于0x7FFF,则计算运动矢量,并进行限制范围的裁剪
int16_t *mvr = fref1->lowres_mvs[0][p1-p0-1][i_mb_xy];//获取后向参考帧,相同位置块的前向预测运动矢量结果
dmv[0][0] = ( mvr[0] * dist_scale_factor + 128 ) >> 8;//根据前向参考帧、当前帧和后向参考帧的距离信息,直接得到前向参考的运动矢量
dmv[0][1] = ( mvr[1] * dist_scale_factor + 128 ) >> 8;
dmv[1][0] = dmv[0][0] - mvr[0];//通过运动矢量相减,直接得到后向参考帧的运动矢量
dmv[1][1] = dmv[0][1] - mvr[1];
CLIP_MV( dmv[0] );
CLIP_MV( dmv[1] );
if( h->param.analyse.i_subpel_refine <= 1 )//如果子像素方案小于等于1,将运动矢量差值的最低位设为0
M64( dmv ) &= ~0x0001000100010001ULL; /* mv & ~1 */
}
else
M64( dmv ) = 0;//0运动向量
//使用宏TRY_BIDIR尝试双向预测。
TRY_BIDIR( dmv[0], dmv[1], 0 );
if( M64( dmv ) )//在运动矢量不为0的情况下,额外再进行一次0运动矢量的成本计算
{
int i_cost;
h->mc.avg[PIXEL_8x8]( pix1, 16, m[0].p_fref[0], m[0].i_stride[0], m[1].p_fref[0], m[1].i_stride[0], i_bipred_weight );
i_cost = h->pixf.mbcmp[PIXEL_8x8]( m[0].p_fenc[0], FENC_STRIDE, pix1, 16 );
COPY2_IF_LT( i_bcost, i_cost, list_used, 3 );
}
}
for( int l = 0; l < 1 + b_bidir; l++ )
{ //循环的目的是对两个方向(l=0和l=1)进行运动估计,其中l=0表示前向运动估计,l=1表示后向运动估计
if( do_search[l] )//首先检查是否需要进行当前方向的运动估计(由do_search[l]决定)
{
int i_mvc = 0;
int16_t (*fenc_mv)[2] = fenc_mvs[l];
ALIGNED_ARRAY_8( int16_t, mvc,[4],[2] );
/* Reverse-order MV prediction. */
M32( mvc[0] ) = 0;
M32( mvc[2] ) = 0;
#define MVC(mv) { CP32( mvc[i_mvc], mv ); i_mvc++; }//通过使用宏MVC(mv)将相关的运动矢量存储在mvc数组中。这里根据当前宏块的位置,将周围宏块的运动矢量存储在mvc数组中
if( i_mb_x < h->mb.i_mb_width - 1 )
MVC( fenc_mv[1] );//将当前块右边的宏块的mv加入到mvc中,作为候选mv
if( i_mb_y < h->i_threadslice_end - 1 )
{
MVC( fenc_mv[i_mb_stride] );//将当前块下面的宏块的mv加入到mvc中,作为候选mv
if( i_mb_x > 0 )
MVC( fenc_mv[i_mb_stride-1] );//将当前块左下面的宏块的mv加入到mvc中,作为候选mv
if( i_mb_x < h->mb.i_mb_width - 1 )
MVC( fenc_mv[i_mb_stride+1] );//将当前右块下面的宏块的mv加入到mvc中,作为候选mv
}
#undef MVC
if( i_mvc <= 1 )//如果只有一个运动矢量,则直接将其赋值给m[l].mvp
CP32( m[l].mvp, mvc[0] );
else//通过调用x264_median_mv函数计算出中值运动矢量,并将其赋值给m[l].mvp
x264_median_mv( m[l].mvp, mvc[0], mvc[1], mvc[2] );
//进行快速跳过(fast skip)步骤,用于检测是否可以跳过当前方向的运动估计
/* Fast skip for cases of near-zero residual. Shortcut: don't bother except in the mv0 case,
* since anything else is likely to have enough residual to not trigger the skip. */
if( !M32( m[l].mvp ) )//首先检查正向预测运动矢量是否为零,如果为零,则计算0运动矢量当前宏块的残差代价(m[l].cost)并进行比较
{
m[l].cost = h->pixf.mbcmp[PIXEL_8x8]( m[l].p_fenc[0], FENC_STRIDE, m[l].p_fref[0], m[l].i_stride[0] );
if( m[l].cost < 64 )
{ //如果残差代价(m[l].cost)小于64,说明当前宏块的残差较小,可以跳过运动估计步骤
M32( m[l].mv ) = 0;
goto skip_motionest;//在这种情况下,将运动矢量设置为零(M32( m[l].mv ) = 0),并跳转到skip_motionest标签处
}
}
//如果无法跳过运动估计步骤,调用x264_me_search函数进行全局运动估计搜索,得到最优的运动矢量(m[l].mv)和对应的残差代价(m[l].cost)
x264_me_search( h, &m[l], mvc, i_mvc );
m[l].cost -= a->p_cost_mv[0]; // remove mvcost from skip mbs
if( M32( m[l].mv ) )
m[l].cost += 5 * a->i_lambda;
skip_motionest://从跳过运动估计步骤处跳转到此处,将最终的运动矢量(m[l].mv)存储到fenc_mvs[l]中,并将对应的残差代价(m[l].cost)存储到fenc_costs[l]中
CP32( fenc_mvs[l], m[l].mv );
*fenc_costs[l] = m[l].cost;
}
else
{ //即do_search[l]为false,则将之前估计得到的运动矢量(fenc_mvs[l])和残差代价(fenc_costs[l])分别赋值给m[l].mv和m[l].cost
CP32( m[l].mv, fenc_mvs[l] );
m[l].cost = *fenc_costs[l];
}//将当前方向的残差代价与之前的最小代价进行比较,如果更小,则更新最小代价
COPY2_IF_LT( i_bcost, m[l].cost, list_used, l+1 );
}
//使用宏TRY_BIDIR尝试双向预测。该宏将使用运动矢量差值进行双向预测
if( b_bidir && ( M32( m[0].mv ) || M32( m[1].mv ) ) )
TRY_BIDIR( m[0].mv, m[1].mv, 5 );
lowres_intra_mb:
if( !fenc->b_intra_calculated )
{ //创建一个名为edge的16字节对齐的数组,用于存储边缘像素值
ALIGNED_ARRAY_16( pixel, edge,[36] );
pixel *pix = &pix1[8+FDEC_STRIDE];
pixel *src = &fenc->lowres[0][i_pel_offset];//当前宏块的像素数据
const int intra_penalty = 5 * a->i_lambda;//定义一个称为intra_penalty的变量,用于表示帧内预测的惩罚值
int satds[3];
int pixoff = 4 / SIZEOF_PIXEL;
//将低分辨率帧的像素数据复制到当前宏块的输入图像中,并进行一些存储优化
/* Avoid store forwarding stalls by writing larger chunks */
memcpy( pix-FDEC_STRIDE, src-i_stride, 16 * SIZEOF_PIXEL );
for( int i = -1; i < 8; i++ )
M32( &pix[i*FDEC_STRIDE-pixoff] ) = M32( &src[i*i_stride-pixoff] );
//调用h->pixf.intra_mbcmp_x3_8x8c函数,计算dc v h三种帧内预测的残差,并存储在satds数组中
h->pixf.intra_mbcmp_x3_8x8c( h->mb.pic.p_fenc[0], pix, satds );
int i_icost = X264_MIN3( satds[0], satds[1], satds[2] );
if( h->param.analyse.i_subpel_refine > 1 )
{
h->predict_8x8c[I_PRED_CHROMA_P]( pix );//对像素进行色度帧内预测
int satd = h->pixf.mbcmp[PIXEL_8x8]( h->mb.pic.p_fenc[0], FENC_STRIDE, pix, FDEC_STRIDE );
i_icost = X264_MIN( i_icost, satd );
h->predict_8x8_filter( pix, edge, ALL_NEIGHBORS, ALL_NEIGHBORS );//对像素进行滤波预测
for( int i = 3; i < 9; i++ )
{ //进行剩下的6种帧内预测模式,计算satd
h->predict_8x8[i]( pix, edge );
satd = h->pixf.mbcmp[PIXEL_8x8]( h->mb.pic.p_fenc[0], FENC_STRIDE, pix, FDEC_STRIDE );
i_icost = X264_MIN( i_icost, satd );
}
}
i_icost = ((i_icost + intra_penalty) >> (BIT_DEPTH - 8)) + lowres_penalty;
fenc->i_intra_cost[i_mb_xy] = i_icost;
int i_icost_aq = i_icost;
if( h->param.rc.i_aq_mode )
i_icost_aq = (i_icost_aq * fenc->i_inv_qscale_factor[i_mb_xy] + 128) >> 8;
output_intra[ROW_SATD] += i_icost_aq;//更新输出统计信息output_intra
if( b_frame_score_mb )
{
output_intra[COST_EST] += i_icost;
output_intra[COST_EST_AQ] += i_icost_aq;
}
}
i_bcost = (i_bcost >> (BIT_DEPTH - 8)) + lowres_penalty;
/* forbid intra-mbs in B-frames, because it's rare and not worth checking */
/* FIXME: Should we still forbid them now that we cache intra scores? */
if( !b_bidir )
{
int i_icost = fenc->i_intra_cost[i_mb_xy];
int b_intra = i_icost < i_bcost;
if( b_intra )
{
i_bcost = i_icost;//如果当前宏块的内部预测成本比已计算的外部预测成本更低,则将内部预测成本赋值给i_bcost变量
list_used = 0;//并将list_used设置为0
}
if( b_frame_score_mb )//如果启用了帧分数统计(b_frame_score_mb为真),则更新输出统计信息output_inter
output_inter[INTRA_MBS] += b_intra;
}
//处理了非I帧(B帧和P帧)的情况
/* In an I-frame, we've already added the results above in the intra section. */
if( p0 != p1 )
{
int i_bcost_aq = i_bcost;
if( h->param.rc.i_aq_mode )//根据AQ模式计算自适应量化后的成本,并更新输出统计信息output_inter
i_bcost_aq = (i_bcost_aq * fenc->i_inv_qscale_factor[i_mb_xy] + 128) >> 8;
output_inter[ROW_SATD] += i_bcost_aq;
if( b_frame_score_mb )
{
/* Don't use AQ-weighted costs for slicetype decision, only for ratecontrol. */
output_inter[COST_EST] += i_bcost;
output_inter[COST_EST_AQ] += i_bcost_aq;
}
}
//将计算得到的低分辨率成本存储在fenc->lowres_costs数组中,用于后续处理
fenc->lowres_costs[b-p0][p1-b][i_mb_xy] = X264_MIN( i_bcost, LOWRES_COST_MASK ) + (list_used << LOWRES_COST_SHIFT);
}12.帧结构路径成本计算slicetype_path_cost
实现了X264_B_ADAPT_TRELLIS帧结构的方案,代码如下:
static uint64_t slicetype_path_cost( x264_t *h, x264_mb_analysis_t *a, x264_frame_t **frames, char *path, uint64_t threshold )
{
uint64_t cost = 0;
int loc = 1;//初始化变量 loc 为 1,表示路径的索引位置,从第一个路径元素开始
int cur_nonb = 0;//初始化变量 cur_nonb 为 0,表示当前非B帧(non-B-frame)的索引位置
path--; /* Since the 1st path element is really the second frame *///将路径指针 path 减1,这是因为第一个路径元素实际上是第二帧
while( path[loc] )//在循环中,遍历路径元素,直到遇到空字符结束循环
{
int next_nonb = loc;
/* Find the location of the next non-B-frame. */
while( path[next_nonb] == 'B' )//在每次循环中,找到下一个非B帧的位置,即路径中下一个不为'B'的字符的位置
next_nonb++;
//根据找到的下一个非B帧位置,计算该帧的代价,并将其添加到总代价 cost 中
/* Add the cost of the non-B-frame found above */
if( path[next_nonb] == 'P' )
cost += slicetype_frame_cost( h, a, frames, cur_nonb, next_nonb, next_nonb );
else /* I-frame */
cost += slicetype_frame_cost( h, a, frames, next_nonb, next_nonb, next_nonb );
/* Early terminate if the cost we have found is larger than the best path cost so far */
if( cost > threshold )//如果当前的总代价 cost 大于阈值 threshold,提前终止循环
break;
//如果启用了B帧金字塔(B-frame pyramid)且下一个非B帧与当前非B帧的间隔大于2,则进行特殊处理
if( h->param.i_bframe_pyramid && next_nonb - cur_nonb > 2 )
{
int middle = cur_nonb + (next_nonb - cur_nonb)/2;
cost += slicetype_frame_cost( h, a, frames, cur_nonb, next_nonb, middle );
for( int next_b = loc; next_b < middle && cost < threshold; next_b++ )
cost += slicetype_frame_cost( h, a, frames, cur_nonb, middle, next_b );
for( int next_b = middle+1; next_b < next_nonb && cost < threshold; next_b++ )
cost += slicetype_frame_cost( h, a, frames, middle, next_nonb, next_b );
}
else//如果未启用B帧金字塔或间隔小于等于2,则遍历当前非B帧和下一个非B帧之间的每一帧,计算其代价并添加到总代价 cost 中
for( int next_b = loc; next_b < next_nonb && cost < threshold; next_b++ )
cost += slicetype_frame_cost( h, a, frames, cur_nonb, next_nonb, next_b );
loc = next_nonb + 1;
cur_nonb = next_nonb;
}
return cost;
}13.生成宏块树macroblock_tree
这段代码的作用是根据帧类型成本和编码器参数,生成宏块树结构。宏块树是在视频编码中用于描述帧类型和宏块关系的数据结构;代码如下:
static void macroblock_tree( x264_t *h, x264_mb_analysis_t *a, x264_frame_t **frames, int num_frames, int b_intra )
{
int idx = !b_intra;
int last_nonb, cur_nonb = 1;
int bframes = 0;
x264_emms();
float total_duration = 0.0;
for( int j = 0; j <= num_frames; j++ )//计算帧序列的总时长和平均时长
total_duration += frames[j]->f_duration;
float average_duration = total_duration / (num_frames + 1);
int i = num_frames;
//根据输入参数b_intra的值,如果是帧内编码,则调用slicetype_frame_cost函数计算帧类型成本
if( b_intra )
slicetype_frame_cost( h, a, frames, 0, 0, 0 );
while( i > 0 && IS_X264_TYPE_B( frames[i]->i_type ) )
i--;
last_nonb = i;
/* Lookaheadless MB-tree is not a theoretically distinct case; the same extrapolation could
* be applied to the end of a lookahead buffer of any size. However, it's most needed when
* lookahead=0, so that's what's currently implemented. */
if( !h->param.rc.i_lookahead )
{
if( b_intra )
{
memset( frames[0]->i_propagate_cost, 0, h->mb.i_mb_count * sizeof(uint16_t) );
memcpy( frames[0]->f_qp_offset, frames[0]->f_qp_offset_aq, h->mb.i_mb_count * sizeof(float) );
return;
}
XCHG( uint16_t*, frames[last_nonb]->i_propagate_cost, frames[0]->i_propagate_cost );
memset( frames[0]->i_propagate_cost, 0, h->mb.i_mb_count * sizeof(uint16_t) );
}
else
{
if( last_nonb < idx )
return;
memset( frames[last_nonb]->i_propagate_cost, 0, h->mb.i_mb_count * sizeof(uint16_t) );
}
while( i-- > idx )
{ //从最后一个非B帧开始,向前遍历帧序列
cur_nonb = i;
while( IS_X264_TYPE_B( frames[cur_nonb]->i_type ) && cur_nonb > 0 )
cur_nonb--;
if( cur_nonb < idx )
break;
slicetype_frame_cost( h, a, frames, cur_nonb, last_nonb, last_nonb );//计算当前帧与上一个非B帧之间的帧类型成本
memset( frames[cur_nonb]->i_propagate_cost, 0, h->mb.i_mb_count * sizeof(uint16_t) );
bframes = last_nonb - cur_nonb - 1;printf("cur_nonb=%d\n",cur_nonb);
if( h->param.i_bframe_pyramid && bframes > 1 )
{ //如果编码器的参数i_bframe_pyramid为真且B帧数大于1,则进行金字塔结构的处理
int middle = (bframes + 1)/2 + cur_nonb;
slicetype_frame_cost( h, a, frames, cur_nonb, last_nonb, middle );//首先确定一个中间层次的索引middle,然后计算中间层次的帧类型成本,并进行一些初始化操作
memset( frames[middle]->i_propagate_cost, 0, h->mb.i_mb_count * sizeof(uint16_t) );
while( i > cur_nonb )
{
int p0 = i > middle ? middle : cur_nonb;
int p1 = i < middle ? middle : last_nonb;
if( i != middle )
{ //从当前帧向前遍历,计算每一帧与参考帧之间的帧类型成本,并进行宏块树的传递操作
slicetype_frame_cost( h, a, frames, p0, p1, i );
macroblock_tree_propagate( h, frames, average_duration, p0, p1, i, 0 );
}
i--;
}
macroblock_tree_propagate( h, frames, average_duration, cur_nonb, last_nonb, middle, 1 );
}
else
{
while( i > cur_nonb )
{ //向前遍历,计算所有帧的cost
slicetype_frame_cost( h, a, frames, cur_nonb, last_nonb, i );
macroblock_tree_propagate( h, frames, average_duration, cur_nonb, last_nonb, i, 0 );
i--;
}
}
macroblock_tree_propagate( h, frames, average_duration, cur_nonb, last_nonb, last_nonb, 1 );
last_nonb = cur_nonb;
}
if( !h->param.rc.i_lookahead )
{
slicetype_frame_cost( h, a, frames, 0, last_nonb, last_nonb );
macroblock_tree_propagate( h, frames, average_duration, 0, last_nonb, last_nonb, 1 );
XCHG( uint16_t*, frames[last_nonb]->i_propagate_cost, frames[0]->i_propagate_cost );
}
//在所有的帧类型成本计算和宏块树的传递操作完成后,进行宏块树的最终处理,并输出结果
macroblock_tree_finish( h, frames[last_nonb], average_duration, last_nonb );
if( h->param.i_bframe_pyramid && bframes > 1 && !h->param.rc.i_vbv_buffer_size )
macroblock_tree_finish( h, frames[last_nonb+(bframes+1)/2], average_duration, 0 );
}14.传递宏块树信息mbtree_propagate_list
这段代码的作用是根据运动矢量和传播量,在宏块树中传递参考成本的信息;代码如下:
static void mbtree_propagate_list( x264_t *h, uint16_t *ref_costs, int16_t (*mvs)[2],
int16_t *propagate_amount, uint16_t *lowres_costs,
int bipred_weight, int mb_y, int len, int list )
{
unsigned stride = h->mb.i_mb_stride;
unsigned width = h->mb.i_mb_width;
unsigned height = h->mb.i_mb_height;
for( int i = 0; i < len; i++ )
{ //根据低分辨率成本数组的值判断是否使用了当前列表
int lists_used = lowres_costs[i]>>LOWRES_COST_SHIFT;
//如果没有使用当前列表,则继续到下一个位置
if( !(lists_used & (1 << list)) )
continue;
//获取遗传量listamount
int listamount = propagate_amount[i];
/* Apply bipred weighting. */
if( lists_used == 3 )//如果使用了两个列表(双向预测),根据双向预测权重对传播量进行加权
listamount = (listamount * bipred_weight + 32) >> 6;
/* Early termination for simple case of mv0. */
if( !M32( mvs[i] ) )//如果运动矢量为零(表示没有运动),则将遗传量添加到参考成本中并继续到下一个位置
{
MC_CLIP_ADD( ref_costs[mb_y*stride + i], listamount );
continue;
}
//计算当前运动矢量的坐标和索引
int x = mvs[i][0];
int y = mvs[i][1];
unsigned mbx = (unsigned)((x>>5)+i);//根据坐标和权重计算四个索引的权重
unsigned mby = (unsigned)((y>>5)+mb_y);
unsigned idx0 = mbx + mby * stride;
unsigned idx2 = idx0 + stride;
x &= 31;
y &= 31;
int idx0weight = (32-y)*(32-x);
int idx1weight = (32-y)*x;
int idx2weight = y*(32-x);
int idx3weight = y*x;//根据索引的位置,将权重添加到参考成本中
idx0weight = (idx0weight * listamount + 512) >> 10;
idx1weight = (idx1weight * listamount + 512) >> 10;
idx2weight = (idx2weight * listamount + 512) >> 10;
idx3weight = (idx3weight * listamount + 512) >> 10;
if( mbx < width-1 && mby < height-1 )
{
MC_CLIP_ADD( ref_costs[idx0+0], idx0weight );
MC_CLIP_ADD( ref_costs[idx0+1], idx1weight );
MC_CLIP_ADD( ref_costs[idx2+0], idx2weight );
MC_CLIP_ADD( ref_costs[idx2+1], idx3weight );
}
else
{
/* Note: this takes advantage of unsigned representation to
* catch negative mbx/mby. */
if( mby < height )
{
if( mbx < width )
MC_CLIP_ADD( ref_costs[idx0+0], idx0weight );
if( mbx+1 < width )
MC_CLIP_ADD( ref_costs[idx0+1], idx1weight );
}
if( mby+1 < height )
{
if( mbx < width )
MC_CLIP_ADD( ref_costs[idx2+0], idx2weight );
if( mbx+1 < width )
MC_CLIP_ADD( ref_costs[idx2+1], idx3weight );
}
}
}
}点赞、收藏,会是我继续写作的动力!赠人玫瑰,手有余香
参考文献:
















 9442
9442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









