







NSGANetV2:进化的多目标代理辅助神经体系结构搜索
(最近看了一些论文,写在Word上面,有的时候在其他设备上查找的时候很麻烦,干脆写个博客)
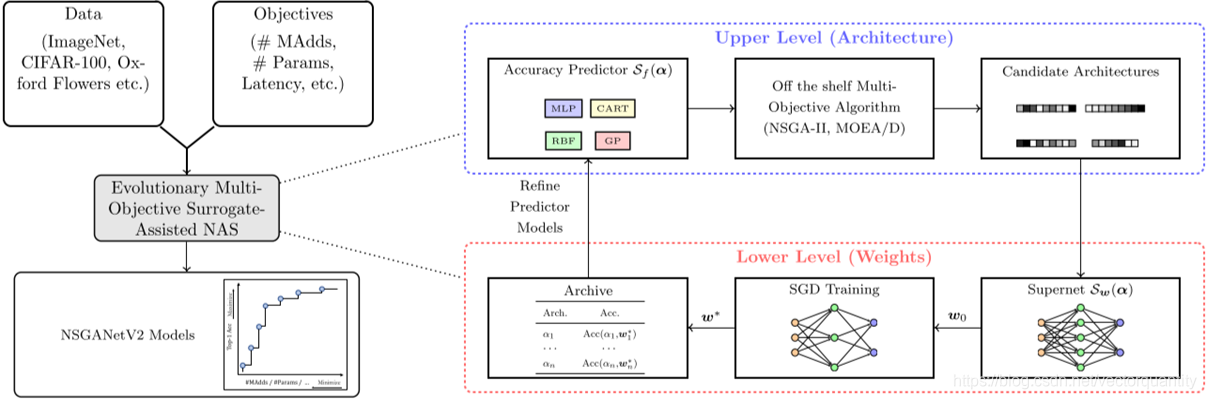
这篇论文提出了一个高效的NAS算法,用于生成在多个竞争目标下具有竞争力的特定任务。 包含两个代理模型:
(1)一个在体系结构级别,来提高的效率。
(2)一个在权重级别,通过超网,来提高梯度下降的训练效率。
1. 简介
神经体系结构搜索(NAS)尝试自动执行神经网络架构搜索过程,以找到给定数据集的良好体系结构。
人们希望使用NAS在自定义非标准数据集上获得高性能模型,优化可能的多个竞争目标,并在没有现有NAS方法繁重的计算负担的情况下这样做。
NAS的目标是获得最佳架构及其相关的最佳权重。NAS通常被视为双层优化问题,其中内部优化针对给定体系结构遍历网络的权重,而外部优化则遍历网络体系结构本身。解决此问题的计算挑战来自上层和下层优化。在较低级别中学习网络的最佳权重需要进行随机梯度下降的昂贵迭代。
在本文中,我们通过在上层和下层同时采用显式代理模型,提出了一种实用有效的NAS算法。我们的下层代理采用微调方法,其中微调的初始权重是通过超网模型获得的。我们的上层代理采用在线学习算法,该算法专注于搜索空间中接近当前权衡前沿的架构,而不是离线代理方法中使用的随机/统一架构集。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1268
1268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









