








 本文探讨了大数据处理中的分而治之策略,通过案例解释了如何解决大规模数据排序和查找共同URL的问题。介绍了simhash算法、Bloom Filter及其应用,强调这些算法在内存限制下的高效性和可能的误判率。通过对Bit-map和布隆过滤器的原理分析,展示了它们在数据判重和空间效率上的优势。
本文探讨了大数据处理中的分而治之策略,通过案例解释了如何解决大规模数据排序和查找共同URL的问题。介绍了simhash算法、Bloom Filter及其应用,强调这些算法在内存限制下的高效性和可能的误判率。通过对Bit-map和布隆过滤器的原理分析,展示了它们在数据判重和空间效率上的优势。
https://wizardforcel.gitbooks.io/the-art-of-programming-by-july/content/06.03.html
分而治之
问题 1:
有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序,求TopK
解决:
hash映射
顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为a0,a1,..a9)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
Hash取模是一种等价映射,不会存在同一个元素分散到不同小文件中去的情况,即这里采用的是%1000算法,那么同一个IP在hash后,只可能落在同一个文件中,不可能被分散的。
那到底什么是hash映射呢?简单来说,就是为了便于计算机在有限的内存中处理big数据,从而通过一种映射散列的方式让数据均匀分布在对应的内存位置(如大数据通过取余的方式映射成小树存放在内存中,或大文件映射成多个小文件),而这个映射散列方式便是我们通常所说的hash函数,设计的好的hash函数能让数据均匀分布而减少冲突。尽管数据映射到了另外一些不同的位置,但数据还是原来的数据,只是代替和表示这些原始数据的形式发生了变化而已。
- hash_map统计
找一台内存在2G左右的机器,依次对每个小文件用hash_map(query, query_count)来统计每个query出现的次数。注:hash_map(query, query_count)是用来统计每个query的出现次数,不是存储他们的值,出现一次,则count+1。,利用快排或堆排,将排序好的query和对应的query_cout输出到文件中,这样得到了10个排好序的文件
- 堆排序(Top K问题)/快排/归并
求TopK:
可以维护k个元素的最小堆,即用容量为k的最小堆存储最先遍历到的k个数,并假设它们即是最大的k个数,建堆费时O(k),并调整堆(费时O(logk))后,有k1>k2>…kmin(kmin设为小顶堆中最小元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,若x>kmin,则更新堆(x入堆,用时logk),否则不更新堆。这样下来,总费时O(klogk+(n-k)logk)=O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk。
所有结果排序:
最后,对10个文件进行归并排序
问题 2
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
分析:
可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
解决:

方案2:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
simhash算法
流程

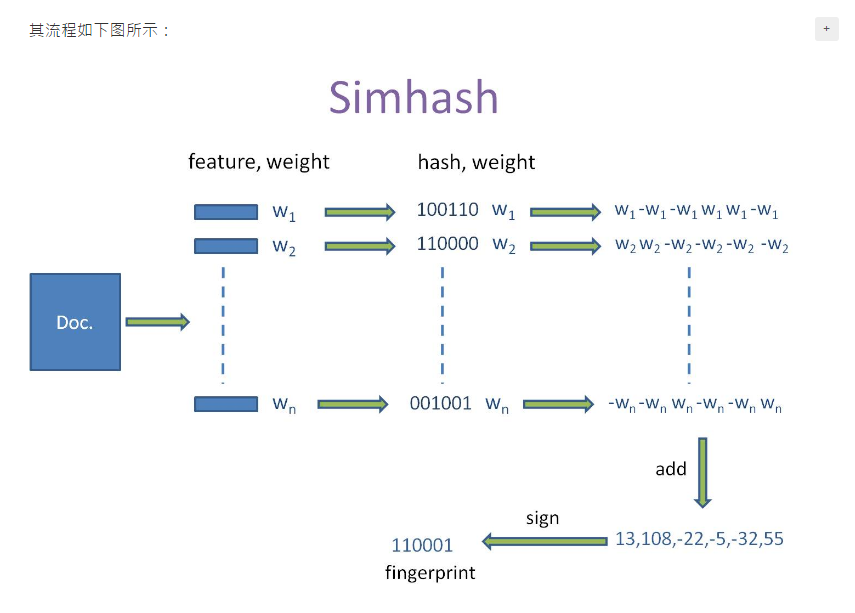
应用
每篇文档得到SimHash签名值后,接着计算两个签名的海明距离即可。根据经验值,对64位的 SimHash值,海明距离在3以内的可认为相似度比较高。
海明距离的求法:异或时,只有在两个比较的位不同时其结果是1 ,否则结果为0,两个二进制“异或”后得到1的个数即为海明距离的大小。
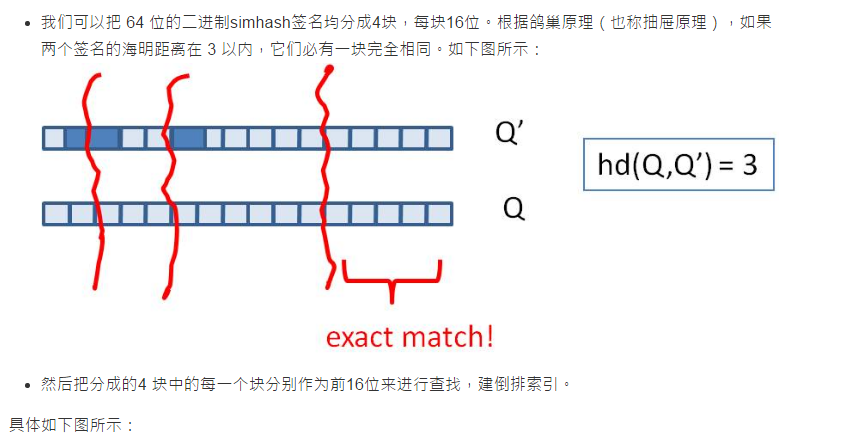
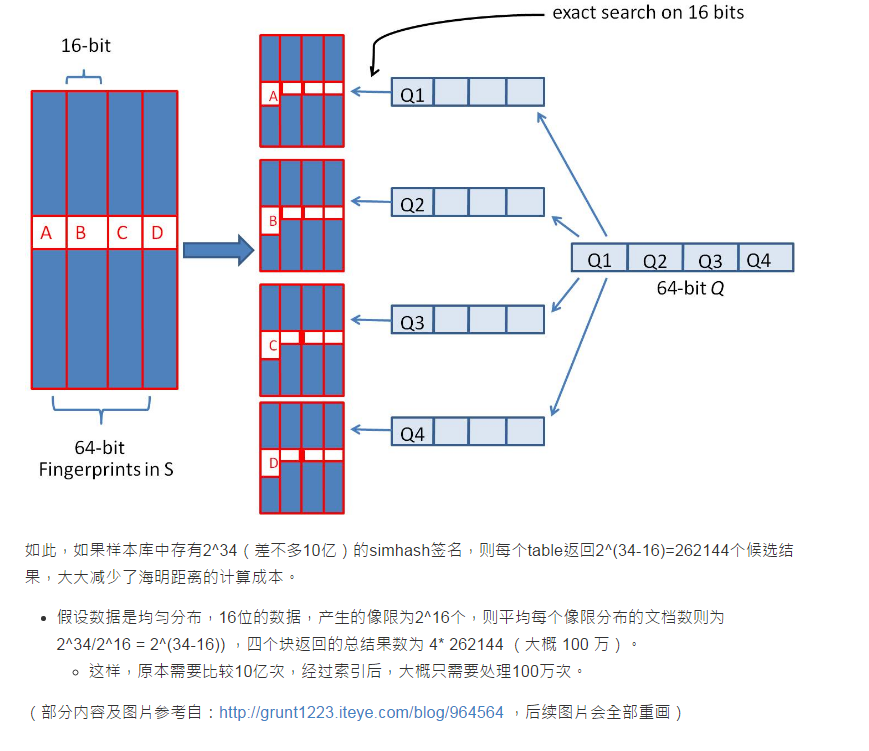
Bit-map
概念

可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
问题实例
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。 (可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)
2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
Bloom Filter
布隆过滤器
Bloom filter可以看做是对bit-map的扩展
概念
Bloom Filter是一种空间效率很高的随机数据结构,它的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位阵列(Bit array)中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检索元素一定不在;如果都是1,则被检索元素很可能在。这就是布隆过滤器的基本思想。
但Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
原理
对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这 个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位,即第二个“1“处)。

在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素(因为y1有一处指向了“0”位)。y2或者属于这个集合,或者刚好是一个false positive。

概括
在使用Bloom Filter判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的存储空间。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
适用范围
可以用来实现数据字典,进行数据的判重,或者集合求交集 ,URL去重。
问题实例
给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿,n=50亿,如果按出错率0.01算需要的大概是650亿个bit。 现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些urlip是一一对应的,就可以转换成ip,则大大简单了。















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









