






K-means算法原理
By:Yang Liu
1.K-means算法简述
目的:把一组数据中相似的部分划分为一组,最终得到K组数据。
属于无监督学习领域的问题。无监督学习:对没有概念标记(分类)的训练样本进行学习,以发现训练样本集中的结构性知识。
2.优点
简单、快速、适合常规数据集。
3.缺点
(1)K值难确定,没有准确的确定方法,主要取决于个人经验和感觉。
(2)复杂度和样本呈线性关系,每次迭代都要计算每个样本到质心的距离,因此,在样本数目较大的情况下,算法计算量大。
4.K-means算法工作流程
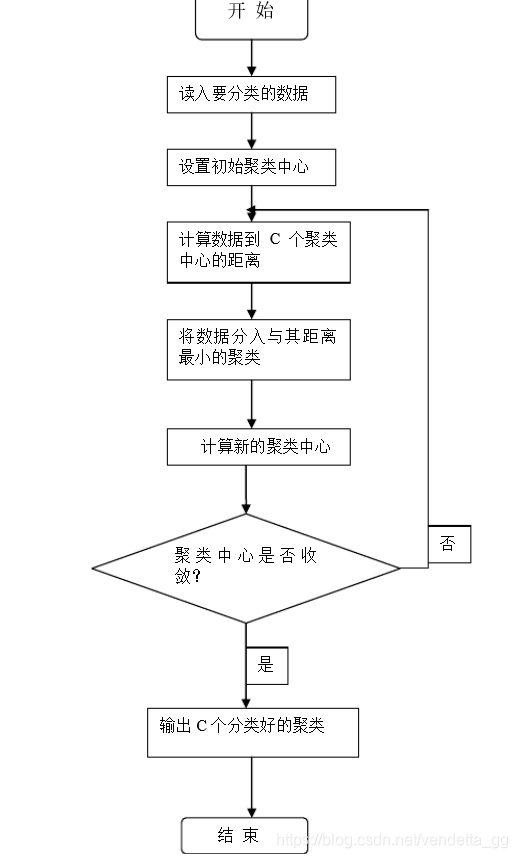
(1)确定K值,即我们要得到的簇的个数。
(2)确定K个质心,随机确定。(因为此算法中,初始值对结果的影响很大,所以要多执行几次算法,哪个结果更合理就用哪个结果,或者计算多个结果取平均)。
(3)计算各点到各个质心的距离,划分成簇,点到哪个质心距离最短,就把此点划分到哪个簇。
注:首次计算前要处理数据,使数据标准化,常用的两种方法如下。
a:min-max标准化(离差标准化):对原始数据进行线性变换,是结果落到[0,1]区间,转换方法为 X’=(X-min)/(max-min),其中max为样本数据最大值,min为样本数据最小值。
b:z-score标准化(标准差标准化):处理后的数据符合标准正态分布(均值为0,方差为1),转换公式:X减去均值,再除以标准差。
(4)优化质心,新的质心满足
min
∑
x
∈
C
i
d
i
s
t
(
C
i
,
x
)
2
\min \sum\limits_{x \in {C_i}} {dist{{({C_i},x)}^2}}
minx∈Ci∑dist(Ci,x)2。
(5)迭代(3)和(4),直到得到
min
∑
i
=
1
k
∑
x
∈
C
i
d
i
s
t
(
C
i
,
x
)
2
\min \sum\limits_{i = 1}^k {\sum\limits_{x \in {C_i}} {dist{{({C_i},x)}^2}} }
mini=1∑kx∈Ci∑dist(Ci,x)2 ,此时,所划分的簇为最终结果,算法结束。
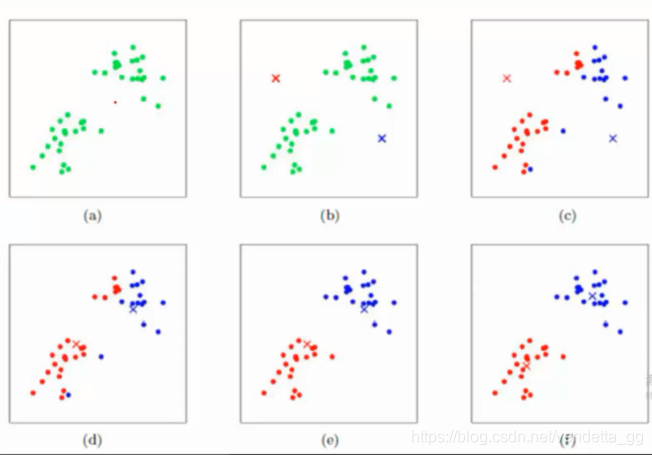
下图为把一组数据分为两组的演示图。
参考文献:
1.https://blog.csdn.net/sinat_36710456/article/details/88019323
2.https://www.bilibili.com/video/BV1j4411H771/?p=4&t=423














 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









