






GRU门控循环单元简述
By:Yang Liu
1.什么是门控循环单元GRU
在循环神经⽹络中的梯度计算⽅法中,我们发现,当时间步数较⼤或者时间步较小时,循环神经⽹络的梯度较容易出现衰减或爆炸。虽然裁剪梯度可以应对梯度爆炸,但⽆法解决梯度衰减的问题。通常由于这个原因,循环神经⽹络在实际中较难捕捉时间序列中时间步距离较⼤的依赖关系。
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,更易于计算。
名词解释:
剃度消失:Sigmoid函数有一个缺点:当x较大或较小时,导数接近0;并且Sigmoid函数导数的最大值是0.25;我们使用标准方法来初始化网络中的权重,那么会使用一个均值为0标准差为1的高斯分布。因此所有的权重通常会满足|w|<1,而激励函数导数是小于0.25的值,那么当神经网络特别深的时候,梯度呈指数级衰减,导数在每一层至少会被压缩为原来的1/4,当z值绝对值特别大时,导数趋于0,从输出层不断向输入层反向传播训练时,导数很容易逐渐变为0,使得权重和偏差参数无法被更新,导致神经网络无法被优化,训练永远不会收敛到良好的解决方案,这被称为梯度消失问题。
梯度爆炸:当我们将w初始化为一个较大的值时,例如>10的值,那么从输出层到输入层每一层都会有一个增倍,同梯度消失类似,当神经网络很深时,梯度呈指数级增长,最后到输入时,梯度将会非常大,我们会得到一个非常大的权重更新,这就是梯度爆炸的问题。
2.GRU的结构

LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在GRU模型中只有两个门:分别是更新门和重置门。zt和rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集上,重置门越小,前一状态的信息被写入的越少。
3.GRU与LSTM的对比
(1)GRU 有两个门(重置门与更新门),而 LSTM 有三个门(输入门、遗忘门和输出门)。
(2)GRU 并不会控制并保留内部记忆C,且没有 LSTM 中的输出门。
(3)LSTM 中的输入与遗忘门对应于 GRU 的更新门,重置门直接作用于前面的隐藏状态。
(4)在计算输出时并不应用二阶非线性。
4.GRU的前向传播公式
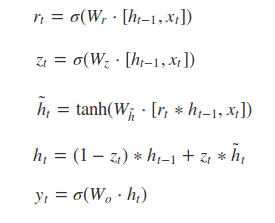
[]表示两个向量相连,*表示矩阵的乘积。
5.GRU的训练过程

概括来说,LSTM和GRU都是通过各种门函数来将重要特征保留下来。
参考文献:
(1) https://blog.csdn.net/junjun150013652/article/details/81274958
(2) https://blog.csdn.net/wangyangzhizhou/article/details/77332582
(3) https://www.jianshu.com/p/0cf7436c33ae
(4) https://blog.csdn.net/Uwr44UOuQcNsUQb60zk2/article/details/78888834
(5) https://www.cnblogs.com/jiangxinyang/p/9376021.html
(6) https://zhuanlan.zhihu.com/p/3248174















 1842
1842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









