






 本文介绍了GRU(GateRecurrentUnit)的发展背景,它是LSTM的一种变体,具有更简单的结构和类似的效果。文章详细解析了GRU的基本原理,单元体结构,以及如何利用TensorFlow和Keras构建和训练GRU模型。还展示了数据预处理和模型训练的代码示例。
本文介绍了GRU(GateRecurrentUnit)的发展背景,它是LSTM的一种变体,具有更简单的结构和类似的效果。文章详细解析了GRU的基本原理,单元体结构,以及如何利用TensorFlow和Keras构建和训练GRU模型。还展示了数据预处理和模型训练的代码示例。
一、GRU发展背景
GRU(Gate Recurrent Unit)是LSTM网络的一种变体,属于新一代的循环神经网络,由Cho等人在2014年引入(引用源论文:https://arxiv.org/pdf/1406.1078v3.pdf);它较LSTM网络的结构更加简单,效果也相差无几,也能很好的解决RNN中的长期依赖问题,因此也是当前非常流行的一种网络。
二、GRU基本结构与原理
2.1 基本原理概述
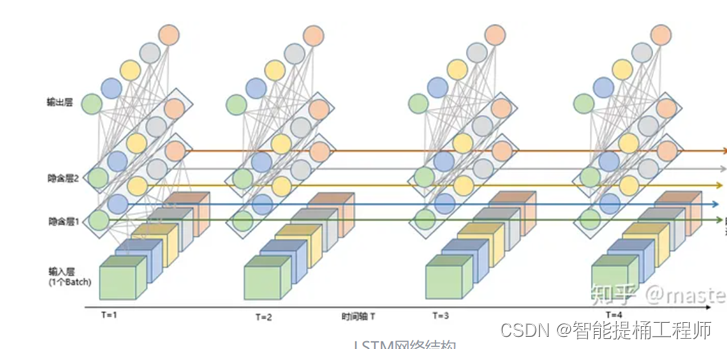
2.1.1 GRU的整体结构(宏观上看)
GRU的基本结构也是跟lstm一样的;
1.在垂直于时间步方向上,每一个时间步都有一个BP网络,包括输入层、隐藏层和输出层。输入层接收输入序列,隐藏层包含GRU单元,输出层输出预测结果。GRU单元的主要组成部分包括更新门(update gate)和输出门(output gate)。
2。在平行于时间步方向上,包含在中间绿色的隐藏层中的GRU单元体,沿着时间步方向传递隐藏状态ht(就是平行于时间轴的那一堆五颜六色的线),从而传统历史信息。
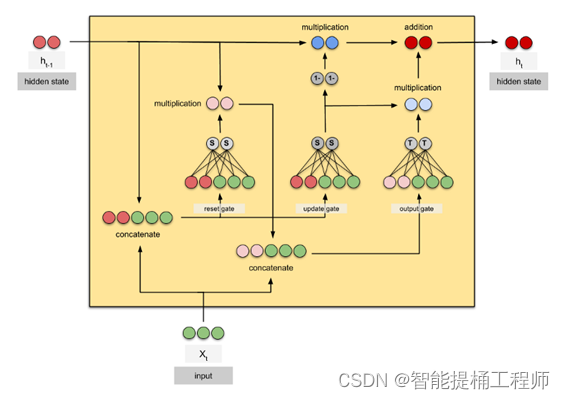
2.1.2 GRU的单元体结构(微观上看)
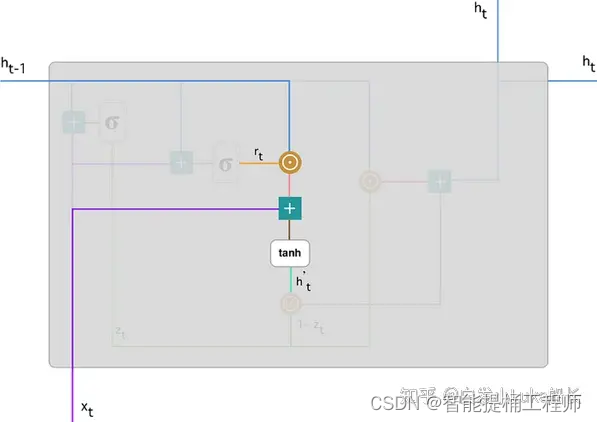
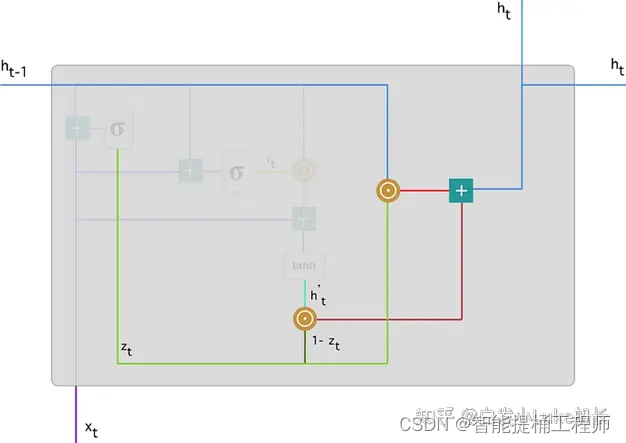
与LSTM的单元体结构相比,GRU去除掉了细胞状态,使用隐藏层状态来进行历史信息的传递;如图GRU的单元体结构示意图可知,它只包含两个门:重置门(reset gate)、更新门(update gate),因此GRU的计算量较LSTM明显更小。
在GRU单元体中,重置门的作用就是决定历史信息有多少能被留下,并与当前的输入信息相结合;更新门的作用类似于LSTM中的遗忘门+输入门,它决定了历史信息和当前输入信息有多少是需要继续传递到当前输出信息中。依靠这个单元体的双门控机制,GRU既能保存长期序列中的信息,避免随时间而清除历史信息,又能保留结合当前信息并传递到下一个单元;从而展示出在低计算成本下处理长期依赖序列数据的优异表现。
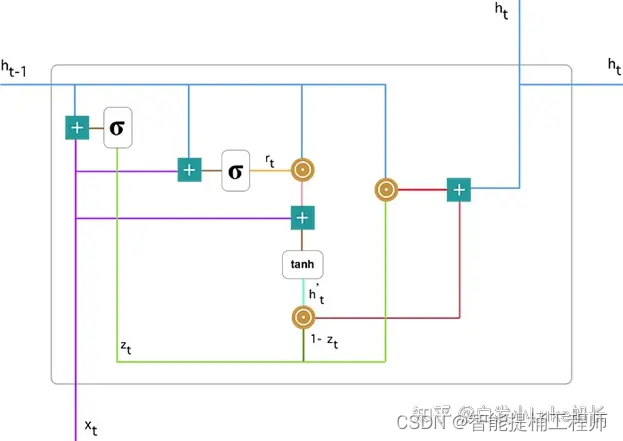
2.3 单元体内部结构--公式推导理解
聚焦在这个单元中
这里的公式和图片均参考此博主的文章快速理解 GRU (Gated Recurrent Unit)网络模型 - 知乎 (zhihu.com)
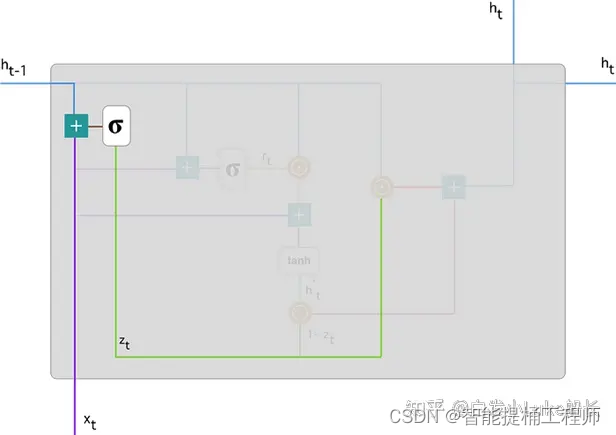
首先,让我们介绍以下的符号注释:










三、GRU模型构建以及训练代码
这里的话呢,补充一点自己写的小小代码
import numpy as np
from numpy import savetxt
import pandas as pd
from pandas.plotting import register_matplotlib_converters
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.metrics import r2_score
import tensorflow as tf
from tensorflow import keras
from keras.optimizers import Adam,RMSprop
import os
import tensorflow as tf
tf.config.set_visible_devices(tf.config.list_physical_devices('GPU'), 'GPU')
register_matplotlib_converters()
#plt.rcParams["font.sans-serif"] = [""]# 指定默认字体
pd.set_option('display.max_columns', None) # 结果显示所有列
pd.set_option('display.max_rows', None) # 结果显示所行行
#>>>>>>>>>>>>数据预处理
#1.训练集(New-train)数据处理
source = 'New-train.csv'
df_train = pd.read_csv(source, index_col=None)
df_train = df_train[['设置你的数据表头']]
source = 'New-test.csv'
df_test = pd.read_csv(source, index_col=None)
df_test = df_test[['设置你的数据表头']]
train_size = int(len(df_train))
test_size = int(len(df_test))
train = df_train.iloc[0:train_size]
test = df_test.iloc[0:test_size]
print(len(train), len(test))
def training_data(X, y, time_steps=1):
Xs, ys = [], []
for i in range(len(X) - time_steps):
v = X.iloc[i:(i + time_steps)].values
Xs.append(v)
ys.append(y.iloc[i + time_steps])
return np.array(Xs), np.array(ys)
time_steps = 10
X_train, y_train = training_data(train.loc[:, '设置你的数据表头'], train.*, time_steps)
x_test, y_test = training_data(test.loc[:,'设置你的数据表头'], test.*, time_steps)
#构建模型
def model_GRU(units):
model = keras.Sequential()
#input
model.add(keras.layers.GRU(
units=units,
activation="relu",
input_shape=(X_train.shape[1], X_train.shape[2])
))
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(1))
model.compile(loss='mse', optimizer=Adam(learning_rate=0.001))
return model
#训练模型
def fit_model(model):
#早停机制,防止过拟合
early_stop = keras.callbacks.EarlyStopping(
monitor='val_loss',
min_delta=0.0,#min_delta=0.0 表示如果训练过程中的指标没有发生任何改善,即使改善非常微小,也会被视为没有显著改善
patience=2000)#表示如果在连续的 2000 个 epoch 中,指标没有超过 min_delta 的改善,训练将被提前停止
history = model.fit( # 在调用model.fit()方法时,模型会根据训练数据进行参数更新,并在训练过程中逐渐优化模型的性能
X_train, y_train, # 当训练完成后,模型的参数就被更新为训练过程中得到的最优值
epochs=400, # 此时model已经是fit之后的model,直接model.predict即可(千万不要model=model.fit(),然后再model.predict)
validation_split=0.1,
batch_size=12600,
shuffle=False,
callbacks=[early_stop])
return history
GRU = model_GRU(64)
#这里只是写了训练模型的代码,预测的话要根据自己的数据结构以及想要的效果来写喔
















 2230
2230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









