










文章目录
9.1. 门控循环单元(GRU)
门控循环单元(gated recurrent unit,GRU) 是一个稍微简化的变体,通常能够提供同等的效果, 并且计算的速度明显更快。
9.1.1. 门控隐状态
门控循环单元与普通的循环神经网络之间的关键区别在于:
前者支持隐状态的门控。
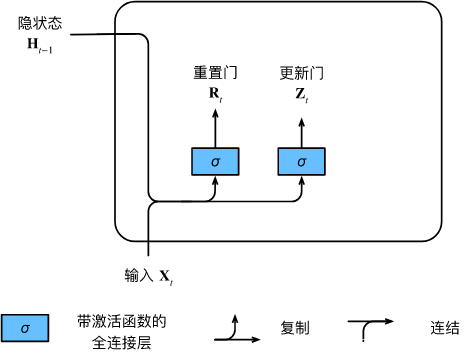
9.1.1.1. 重置门和更新门
重置门允许我们控制“可能还想记住”的过去状态的数量;
更新门将允许我们控制新状态中有多少个是旧状态的副本。
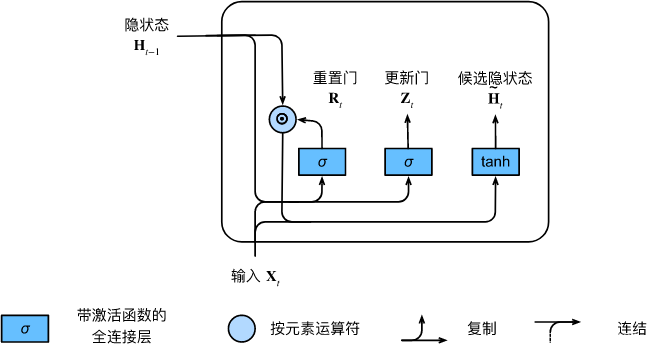
9.1.1.2. 候选隐状态
9.1.1.3. 隐状态
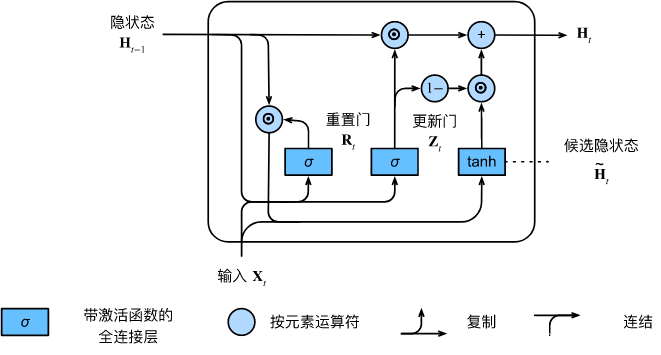
总之,门控循环单元具有以下两个显著特征:
-
重置门有助于捕获序列中的短期依赖关系。
-
更新门有助于捕获序列中的长期依赖关系。
9.1.2. 从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
9.1.2.1. 初始化模型参数
从标准差为0.01的高斯分布中提取权重, 并将偏置项设为0,超参数num_hiddens定义隐藏单元的数量, 实例化与更新门、重置门、候选隐状态和输出层相关的所有权重和偏置。
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
9.1.2.2. 定义模型
定义隐状态的初始化函数init_gru_state
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
#
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
9.1.2.3. 训练与预测
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
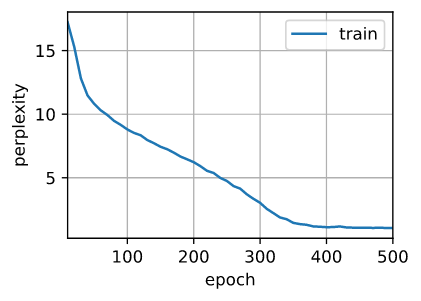
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# result
perplexity 1.1, 25883.3 tokens/sec on cuda:0
time traveller with a slight accession ofcheerfulness really thi
traveller for so it will be convenient to speak of himwas e
9.1.3. 简洁实现
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)
model = d2l.RNNModel(gru_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# result
perplexity 1.0, 327477.3 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby
9.1.4. 小结
-
门控循环神经网络可以更好地捕获时间步距离很长的序列上的依赖关系。
-
重置门有助于捕获序列中的短期依赖关系。
-
更新门有助于捕获序列中的长期依赖关系。
-
重置门打开时,门控循环单元包含基本循环神经网络;更新门打开时,门控循环单元可以跳过子序列。















 1841
1841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











