






| 一、实验目的 |
|
| 二、实验环境 |
| Pycharm |
| 三、实验内容 |
| 决策树是一种监督学习算法,用于分类和回归任务。决策树的基本原理如下:
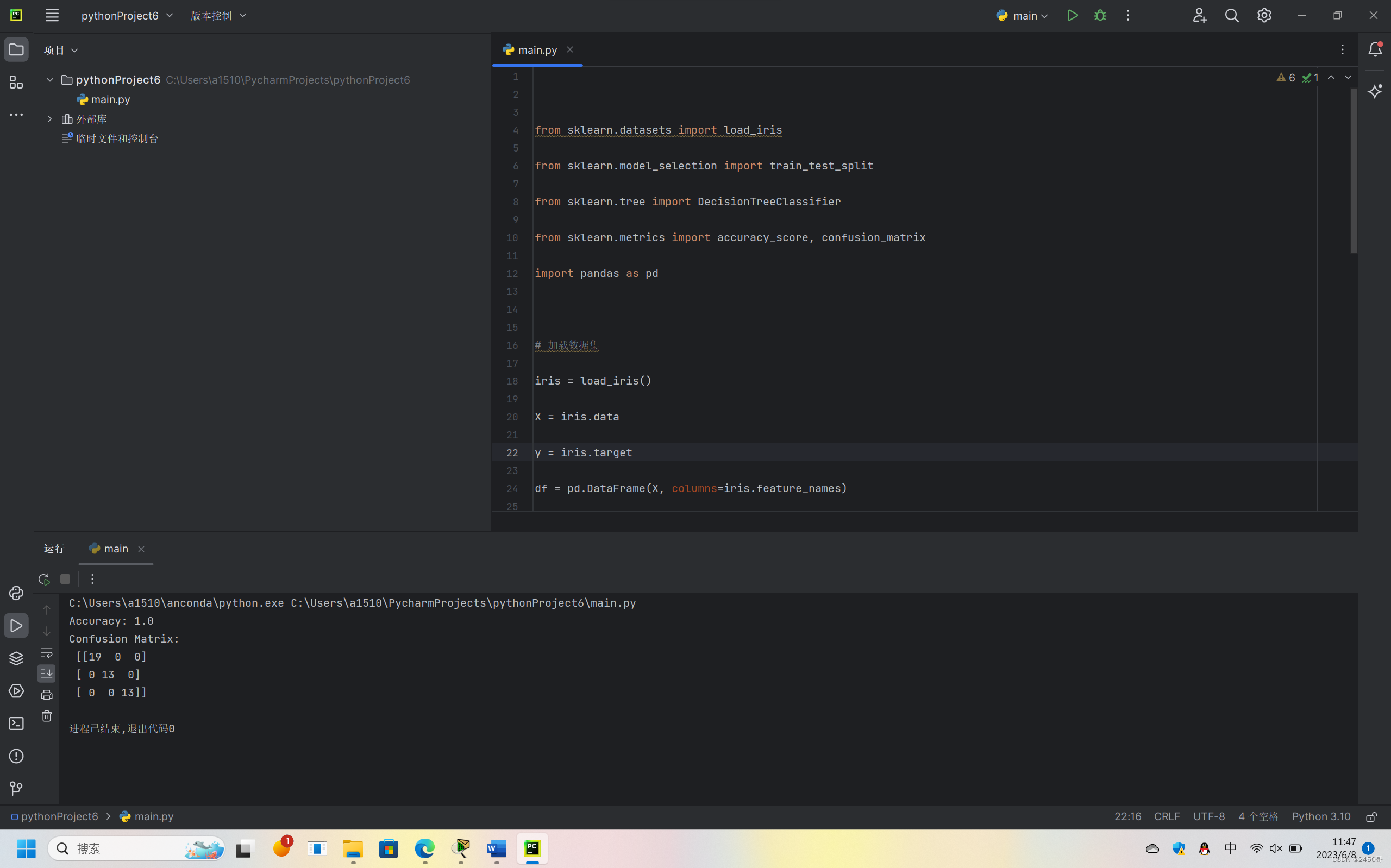
本实验使用鸢尾花数据集(Iris dataset),包含4个特征(sepal length (cm)、sepal width (cm)、petal length (cm)、petal width (cm))和3个类别(setosa、versicolor、virginica)。数据集已经进行了预处理,将缺失值填充为 在Python中,可以使用 from sklearn.datasets import load_iris
1.准确率(accuracy):准确率是指模型正确预测的样本数占总样本数的比例。计算公式为 accuracy = (TP + TN) / (TP + TN + FP + FN) 其中,TP表示真正例(True Positive),TN表示真负例(True Negative),FP表示假正例(False Positive),FN表示假负例(False Negative)。 2.精确率(precision):精确率是指模型正确预测为正例的样本数占所有被预测为正例的样本数的比例。计算公式为 precision = TP / (TP + FP) 3.召回率(recall):召回率是指模型正确预测为正例的样本数占所有实际为正例的样本数的比例。计算公式为 recall = TP / (TP + FN) 接下来,我们将使用混淆矩阵来可视化这些指标。混淆矩阵是一个二维表格,用于显示分类器在各个类别上的预测结果与实际结果之间的差异。以下是一个简单的混淆矩阵绘制函数:
|
| 五、实验总结 |
| 决策树是一种常用的机器学习算法,它在分类和回归任务中都表现出色。本实验通过使用Python的sklearn库,实现了对鸢尾花数据集的决策树建模。 首先,我们了解了决策树的基本原理,包括熵、交叉熵和信息增益。这些概念有助于我们更好地理解决策树的构建过程。接着,我们掌握了决策树函数语法,学会了如何使用DecisionTreeClassifier或DecisionTreeRegressor类来构建决策树模型。 在数据集分析阶段,我们使用了鸢尾花数据集,并将其划分为训练集和测试集。然后,我们使用训练集训练了一个决策树模型,并使用测试集对模型进行了评估。最后,我们计算了模型的准确率、召回率和混淆矩阵,以便对模型性能进行量化分析。 总之,本实验加深了我们对决策树算法的理解,提高了我们的编程能力和实践能力。通过本次实验,我们学会了如何使用Python进行数据预处理、特征选择和模型训练等操作,同时也了解了如何评估模型性能以及如何优化模型参数。 |















01-27
 2347
2347
2347
07-05
624
624
12-17
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









