







embedding理解
- 本质就是量化相似性,将相似性通过在多个维度上的量化,从而通过判断两个向量的距离来判断相似性。
- 意义:将类别数据(无限维度/多维度)用低维表示且可自学习。
协同过滤
推荐系统有两种主要类型,区分这两种类型很重要。
**基于内容的过滤:**这种类型的过滤是基于有关项目或者产品的数据。例如,让用户填写一份关于他们喜欢什么电影的调查。如果他们说他们喜欢科幻电影,系统便推荐他们去看科幻电影。在这种情况下,所有项目都必须有大量元信息可用。
**协同过滤:**让系统找到像你一样的人,看看他们喜欢什么,假设你也喜欢同样的东西。和你一样的人=以相似的方式评价你看的电影的人。在大型的数据集中,这比元数据方法工作得好得多。本质上,询问人们的行为不如观察他们的实际行为好。
目标
- 输入:50 万个用户已经选择观看的 100 万部书(具体到某个用户看过哪几部书)
- 任务:向用户推荐书(本质:预测用户喜欢的书)
要解决这一问题,需要使用某种方法来确定哪些书相似。
流程
- 1、原始输入:使用one-hot矩阵,缺点:表示维度过多;优点:但是可以对每一个维度进行打分,从而挑出最好的一个。
类似于:时域到频域
- 2、embeding层输入:只保留one的id/index,通过embeding层转为固定数量的维度,可以理解为下面的相似度排序中的特征。优点:数据维度在推荐系统中大幅减少,且不用人工方式得到特征,可以获取特定维度的特征。
- 3、embeding层输出:一个确定维度大小的矩阵,里面均为小数,可以理解为每个兴趣为度的感兴趣程度,实际上是没有实际意义为隐藏兴趣。
—> 生成embeding矩阵的方法:1、基于内容的word2vec/item2vec、协同过滤矩阵分解方法3、DNN深度学习 …
- 书籍案例
100万维->二维
按照人类视角的特征分类重新上色
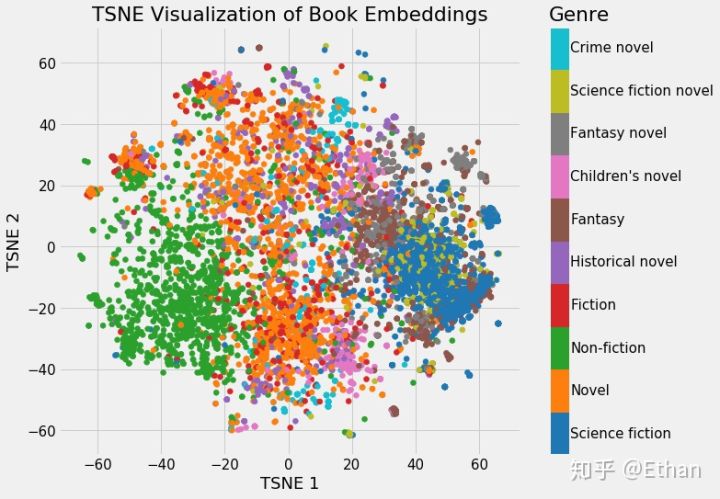
我们可以清楚地看到属于同一类型的书籍的分组。虽然它并不完美,但惊奇的是,我们只用 2 个数字就代表维基百科上的所有书籍,而在这些数字中仍能捕捉到不同类型之间的差异。这代表着 embedding 的价值。
理解
按照相似度排序
- 一维
只能按照单一的维度sort,例如:(成人还是儿童等)
- 二维
按照两个维度sort,例如:(成人还是儿童+节奏快/慢)。即,变为一个坐标系,求欧氏距离就是两部电影的相似程度。
- 多维
可以将二维的方法拓展到n维
数据
-
一个用户观看过的书,例如:用户a-[0, 1, 0, 1, 0, 0, …],1代表对应位置的书被看过。(在推荐系统中的初始候选过于多,必须解决)->只记录看过的N部书[1, 3, …]更加高效、可用。
-
用户-用户标签:从用户看过的所有书中随机挑选n部(也就是用户喜欢的)
-
训练数据:剩下N-n部
-
需要确定embeding维度,也就是隐含兴趣维度
实际应用
推荐系统建立两个embedding向量,一个为用户embedding,也就是存储着用户在每个隐藏兴趣维度上面的坐标;一个为物品embeding,也就是存着物品在每个隐藏兴趣维度上面的坐标。两个向量每个维度意义一致(生成embeding参数一致),从而达到可以用户推荐用户(相似的人)、用户推荐物品(视频推荐)、物品推荐物品(相似的人)。
-
数据流:[1, 0, 1, 0, …]->[0, 2, …]->[0.8, -0.32, …]->计算余弦相似度->…
one-hot->index->embedding















 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









