






无限制信息关联技术的研究
--MageTower
信息平台架构
一、
概述。
我们现在使用的信息处理系统大多是使用关系型数据库来描述信息之间的关系,也就是“关联”。信息关联的情况会对信息系统的运行过程产生极为重要的影响。但这些“关联”或“关系”不管其多么复杂,一般在系统的设计阶段就固定下来(或限定在一定的范围内)。系统开发完成交付使用后,用户只能在这“有限”的关系中对信息进行处理。一旦用户要求修改或增加信息关系,就意味着对原有设计的改变,也就意味着修改原系统。
这种修改一般是增改原有的数据结构,或增改数据处理的程序。如果原有设计未充分考虑未来变化时,这种修改有时甚至会导致原先系统的混乱或整个系统要推倒重来。其耗时、耗力、耗经费的情况自毋庸多言。
本文研究一种“无限关联技术”,可以让系统中任意两个独立的信息,在任意概念上发生联系。基于此项技术来处理信息之间的相互关系,可以在不修改所用到的关联程序、不必修改数据库数据结构时,无限制地改变信息关联关系;通过配置数据,在较少修改甚至无需修改所用到的程序的情况下,对信息及关联的处理实施有效控制。
使用
“无限关联技术”,你在建造一个新的应用系统时,不必要求把整个系统方方面面的关系考虑完善后,再进行开发。你可以“想到哪,做到哪”,甚至在系统交付使用后,如果发现有新的关联要求,那你就径直把它加进去就行了。
二、
信息关系。
信息系统在本质上是对现实世界的抽象和模拟,包括现实世界中的对象、对象间的关系、影响、以及互动。因此,处理信息关系就成为信息系统的基础任务。
然而,信息系统理论所提供的用于描述信息之间关系的手段和工具却明显不足。比如,在关系型数据库中,我们用“一对一”、“一对多”、“多对多”来表达信息关系;在面向对象的设计方法中,我们用“继承”、“包含”、“组合”等来描述。这些形式上的描述仅仅是处于便于系统设计和开发的目的。
现实世界中对象之间的关系是远远不止于此的。比如人和人之间有“朋友”、“亲属”、“上下级”、“师生”、甚至“尊敬”、“崇拜”、“憎恶”、“敌对”等关系;人和组织机构之间有“雇佣”、“投资”、“客户”、“借贷”等关系。可以说,关系种类是数不胜数的。《时间简史》的作者、著名物理学家霍金指出:空间与时间,以及存在其中的事物总是在相互影响着。可见,现实系统中事物的联系是无限的,因此信息处理系统中的信息之间的关联也应该是无限的。
面对众多的关联关系,我们一般是采用前述“一对一”、“一对多”、或“继承”、“包含”等形式描述,并在相关的信息中插入所关联的信息标识,然后用程序将此信息关系解释成现实世界中的实际关系。比如,有“父子”关系,我们在人的信息中插入一个字段:“FID
”,这是“一对多”的关系,然后将每个人的父亲的
ID
写入(见图
1
)。这样,当需要查询“父子”关系时,就由程序来通过“FID
”找到相应的“父”或“子”的信息。
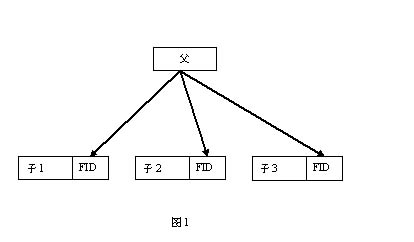
上述的这种做法有两个明显的副作用。其一,当需要增加新关系时,比如处理“师生”关系,需要在人的信息中增加一个新的字段:“
TID
”,这意味着改变原有的数据结构;其二,查询“师生”关系时,程序要通过
TID
,而不是
FID
,这意味着修改程序。当信息关系无限制增加时,以上方式所带来的副作用将会变得无法忍受。
造成这种情形的根本原因是我们的信息系统理论对信息关系的描述是间接的或隐含的,必须是通过程序解释的。本文的目的就是要构造一种能够对信息关系直接描述的形式方法。用此方法,可以在不修改所用到的关联程序、不必修改数据结构时,无限制地改变信息关联关系。
三、
无限关联。
两个事物之间有关联,其实质为这两个事物之间有直接或间接的相互影响,影响不同,则关联不同。为了区别起见,人们一般要对这种影响或关联进行分类,我们称之为“关联类别”或“关联类型”。比如,有父子俩在同一间公司供职,则他们有亲属关系,还有同事关系。这里“亲属”和“同事”就是不同的关联类别。
关联类别具有方向性。比如对父子俩用“父子”这一关联类别来描述关联时,必须指明谁是“父”,谁是“子”。假如甲是乙的父亲,我们可以这样表示:
父子,甲
-
>
乙
也可以这样:
父子,乙
<
-
甲
如果“-
>
”称为“正向”,则“
<
-”称为“反向”,反之亦然。可见,当用“父子”这一关联类别来描述甲乙之间的关系时,这种关联方式对双方而言,是不对等的。但有些关联类别可以用于描述“对等的”关联关系,如“亲属”关系。我们可以说甲是乙的亲属,也可以说乙是甲的亲属。可以这样表示:
亲属,甲
<
-
>
乙
也可以这样:
亲属,乙
<
-
>
甲。
我们称“
<
-
>
”为“对等双向”,或简称“双向”。
综上所述,为了表达一对信息的关联关系,我们应该指明以下基本关联内容:
信息
A
信息
B
关联类别
关联方向
其中,关联方向在某些情况下是可以被省略的。特别是如果其中的关联类别是“对等的”,则关联方向必然是“双向的”,这时,关联方向可以作为一种隐含或缺省而被省略掉。
除了上述基本关联信息外,还可以在此基础上附加更为广泛的资料来进一步描述关联关系。比如:关联时间,来表达关系何时建立;关系程度,来表达关系的深浅或强弱。甚至是一段文本说明,比如可以在某个“朋友”关系中附加一句:“表面是朋友,其实是冤家。”
上述关联信息也称为“关联数据”。
实现信息无限制关联的基本方式就是:创建一个或一组记录关联数据的数据表,称为关联映射表。当要增加一对信息的关联关系时,就在此表中记录一条相应的关联数据。当要确认两条信息是否具有某种关联关系时,就查询关联映射表。只要不限制关联映射表的容量和存取能力,就可以实现本文所称的无限制信息关联。
然而,在我们建造的实际的信息系统中,限制往往是必要的和必须的。因为随意的、无限制的创建关联关系,必然会在系统中产生大量的无用关联垃圾,将影响系统的效率和准确性。特别是关联类别的划分,实质是我们人类主观判断和认识的产物,必然会出现不准确、不恰当、甚至是错误的情况。比如,人和人之间可能会有“父子”关联,但如果让两辆自行车之间也发生“父子”联系,那就大错特错了,除非你是在演绎某个童话故事。
可以在以下方面对关联做出限制:信息类别、关联类别、关联方向。也就是限制哪些信息、在哪些方面可以产生关联。还可以进一步限制信息的其他某些属性,比如,年龄大于
13
岁的男性的人,才可以成为“父亲”。
前面说到,因为人的主观认识会有错误或不恰当,所以要在信息系统中对关联进行适当限制。但这种限制有时也是主观的,也会有错误或不恰当。所以应该允许系统用户对关联限制进行调整,以适应新的情况或更正错误。比如若发现你
12
岁时就有了第一个儿子,则前面举例的限制就需要修改。
尽管有限制,但若可以对这些限制进行无限制地修改或调整,则我们认为这也是一种无限制的信息关联技术。
四、
关联映射表。
关联映射表用于反映任意两个信息之间的关联关系。一个关联映射表可包含多条数据,每一条数据反映一对信息之间的关联关系,称为关联数据,其数据结构的设计依照如下原则:
a)
能从数据中获得两条信息,这两条信息是此数据所反映的相关联的信息。
b)
能从数据中获得关联类别。
c)
能从数据中获得关联方向。
d)
如需要,数据中还可包含关联的附加信息。
以上所谓的“获得”,包括直接获取,和用隐含、缺省方式获取,或依某种规则推导而获取。
举例如下:
表1
|
元素
|
说明
|
|
Aid
|
信息A的信息标识
|
|
Atype
|
信息A的信息类别标识
|
|
Bid
|
信息B的信息标识
|
|
Btype
|
信息B的信息类别标识
|
|
Rtype
|
关联类别的标识
|
|
Direction
|
关联方向的标识
|
|
Append
|
附加信息
|
其中,
Aid
和
Atype
构成信息
A
的系统标识,
Bid
和
Btype
构成信息
B
的系统标识,因而可用以获得这两条关联的信息。
Rtype
是关联类别的标识,用以将不同的关联类别区别开来。利用一个
Rtype
可以唯一获得一个关联类别。
Direction
用以表达关联方向,如
A
表示正向、
B
表示反向等。
可以设置唯一的一个关联映射表,也可以设置多个关联映射表。如果设置了多个关联映射表,则在存取时要明确不同的信息类别所对应的关联映射表。一般是另设置一个映射表,来反映信息类别与关联映射表之间的对应关系(如下表
2
所示)。这样,只要给定一个信息类别,就可以确定用哪个关联映射表来存取或检索关联关系。
表
2
|
信息类别标识
|
关联映射表ID
|
|
***
|
***
|
|
***
|
***
|
如果信息类别与关联映射表之间的对应关系是一一对应的关系,则在构建关联映射表时,可以省去一个信息类别标识,即元素
Atype
。这里此元素就是一种隐含的存在形式。
元素
Append
,用于对关联关系做进一步的说明或补充,如反映关联关系的建立日期、关系程度、附加说明等。根据需要,可以构建多个“附加信息”元素,也可以省略此元素。
五、
关联的控制。
为了提高关联或关联处理的有效性和实用性,一般应该对关联条件、关联方式、或其他处理方式(如统计方式、运算方式、信息组合方式、动作行为方式等)进行限定和控制。本文采用配置数据来进行控制,利用配置数据与关联程序的配合,可以做到既实施有效控制,又较少修改甚至无须修改关联程序就能对控制进行必要的调整。
配置数据的类型和内容包括以下部分:
a
)信息的过滤条件。关联程序将据此检索特定的信息。可以包括对信息中某些元素的限定条件(如大于某个值),或排序方式等。
例如,获取金额大于
10000
的订单,并按订单日期的倒序进行排序:
<
Filter
>
< Restrict >
< Field Name =”金额”>
 <Value Comparator
=”大于”>10000</Value>
<Value Comparator
=”大于”>10000</Value>
</Field
>
</
Restrict
>
<
Sort
>
< Field Name =”日期”>DESC</Field>
</Sort >
</ Filter >
< Restrict >
< Field Name =”金额”>
<Value Comparator
=”大于”>10000</Value>
</Field
>
</
Restrict
>
<
Sort
>
< Field Name =”日期”>DESC</Field>
</Sort >
</ Filter >
b
)描述信息的关联方式或关联条件。关联程序将根据关联条件来寻找某个或某类信息的关联信息,或用关联方式来限制关联信息的处理方式。可以包括:关联信息的信息类别、关联类别、关联方向或过滤条件(参见
a
))等。
例如,限定某种信息可以与“收款单”相关联,其关联类别为“收款”,关联方向为“
A
”(正向):
通过调整这些数据,用户就可以在不改变程序和数据结构的情况下,任意调整和改变信息关联的处理方式。
还可以限制关联的数量。如在上述例子中增加一条:
<RelNum>1</RelNum>
表示一条信息只允许与一个“收款单”建立关联。
c
)描述信息处理的特定方式。在处理关联信息时,经常需要对信息数据进行相关的统计、运算、或组合等处理。这时,可以在配置数据中描述这些处理的指令或表达式,关联程序将据此进行处理。
例如,对于符合特定过滤条件的“收款单”信息,统计其数量,并将统计值保存于名称为“
Count
”的变量中;统计金额(
Amount
)总和,并保存于名称为“
Sum
”的变量中。描述如下:
<
Statistics
>
<
Count
>
COUNT(ID)
</
Count
>
<
Sum
>
SUM(Amount)
</
Sum
>
</
Statistics
>
又例如,对于某一指定的订单信息,我们要将对其所关联的收款单所统计的金额总和,以
“
收款总额
”
的名称附加到此订单信息的
Append
区域中,然后,将此值与订单金额之差,以
“
欠款额
”
的名称,也附加进去。描述如下:
<
Append
>
<
收款总额
>
Relation(关联收款单).Statistics(Sum)
<
收款总额
>
<
欠款额
>
Field(Amount) – Append(收款总额)
</
欠款额
>
</
Append
>
六、
关联处理程序。
关联信息处理程序,用于依据相关的指令和参数,完成对输入的信息的关联关系的处理,包括:管理关联关系、以及对关联关系及关联的信息进行统计、检索和处理。由以下功能实现:
1、
配置数据的分析和执行。用于对关联条件、关联方式、或其他处理方式(如统计方式、运算方式、信息组合方式、动作行为方式等)进行限定和控制。它从配置数据中提取相应的指令、数据或表达式,将数据提供给其他单元使用,或执行所述的指令或表达式,将执行结果提供给其他单元使用。例如,创建信息关联的程序通过分析相关的配置数据,来确定两条待关联的信息是否被允许建立关联。
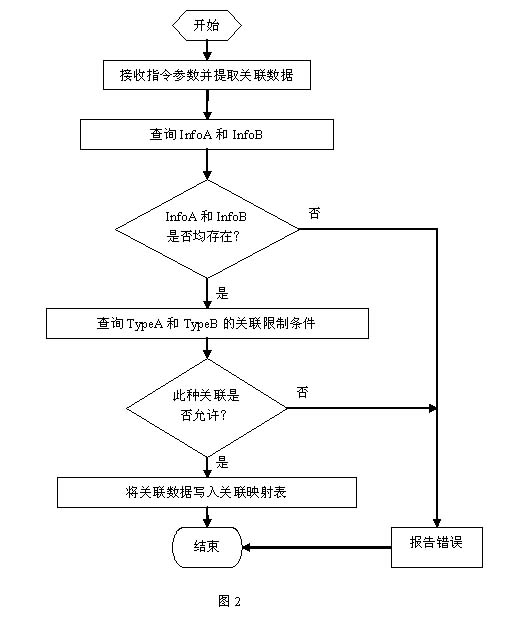
2、
管理关联关系的单元。用指定的关联方式或关联条件来管理关联映射表中的关联数据。包括创建、修改、检索、或删除。图
2
是创建关联关系的流程示意。
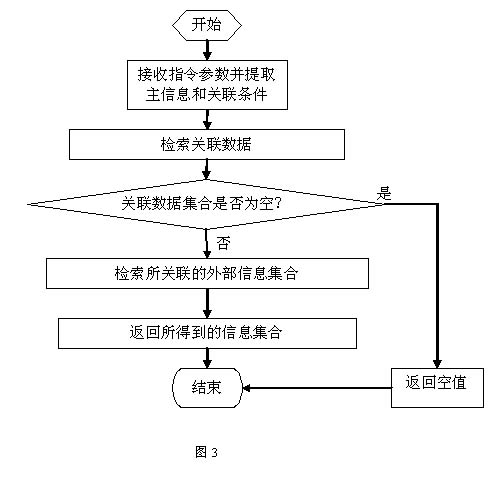
3、
检索相关联
的信息。用于依据关联条件,通过访问相应的关联映射表,获取与所述关联条件相对应的关联数据,并根据关联数据检索与所述关联数据对应的信息。图
3
是检索的流程示意。
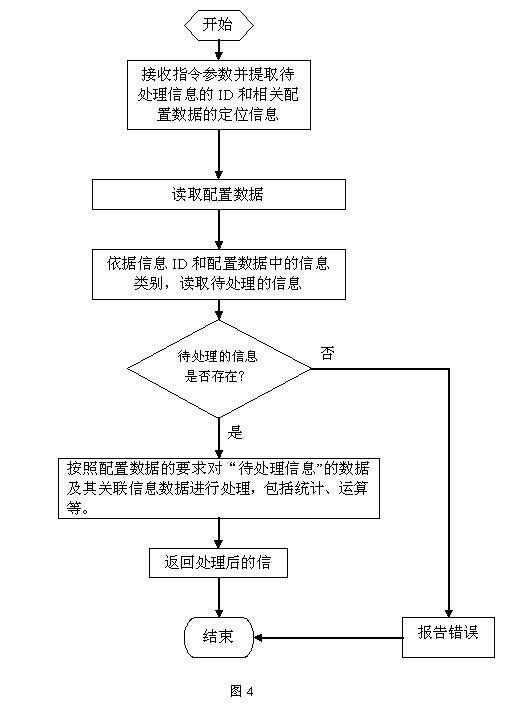
4、
统计关联信息。用于依据关联条件,访问相应的关联映射表,检索出与所述关联条件相对应的关联数据,并利用指定的统计方式进行统计,获得统计数据,指定的统计方式包括对关联数据集合中的指定数据进行统计,或利用检索出的关联数据,对关联数据所对应的信息中的指定数据进行统计。统计内容可以包括:信息数量的计数,或对某个信息元素的求和、求最大值、求最小值、求均值、或求方差等。
5、
信息重构。用于对检索或统计所获得的信息,用指定的处理方式进行处理,获得在原信息集合之外的新的数据,处理方式包括判断、运算、组合、分解、信息附加或直接引用。流程示意如图
4
。
举例如下:
假设外部信息集合中有订单信息和收款信息,这两类信息之间已经使用前述关联管理功能建立了必要的关联。这里,我们将通过对某订单所关联的收款信息进行相关的统计和运算,以便确定此订单是否已收款、收款几次、共收多少、是否还有欠款、以及欠款多少。这些信息与原订单信息一起,将构成一个新的订单综合信息反馈给用户。
在此功能使用之前,先设置一段配置数据,如下:
1
<Info>
2
<InfoType>订单</InfoType>
3
<Relation Name=”关联收款单”>
4
<InfoType>收款单</InfoType>
5
<RelationType>收款</RelationType>
6
<Direction>A</Direction>
7
<Statistics>
8
<Count>COUNT(ID)</Count>
9 <Sum>SUM(Amount)</Sum>
10
</Statistics>
11
</Relation>
12
<Append>
13
<收款次数>Relation(关联收款单).Statistics(Count)</收款次数>
14
<是否收款>Boolean(Append(收款次数)>0)</是否收款>
15
<收款总额>Relation(关联收款单).Statistics(Sum)<收款总额>
16
<欠款额>Field(Amount) – Append(收款总额)</欠款额>
17
<是否欠款>Boolean(Append(欠款额)>0)</是否欠款>
18
</Append>
19
</Info>
随后,用如图
4
所示的流程进行处理。本功能在执行过程中,将使用配置数据的分析和执行单元来对上述配置数据进行分析,得到相应的指令、参数、表达式。然后完成相关的指令运算、表达式运算等任务。以下具体解释本功能程序分析上述配置数据后,所执行的处理方法:
第
1
行,
<Info>
表示一条特定的信息。其下级内容表示了如何构造此信息。
第
2
行,表示此信息的类型为
“
订单
”
。因此可以根据一个精确的信息标识(
ID
)来确定一个唯一的订单。
第
3
行到第
11
行,表示当得到一个订单后,将建立一个与此订单对应的关联信息存储区域,用于获取此订单的关联信息。并且此区域有一个名字:关联收款单。其下级内容表示了如何确定这些关联信息。
第
4
行,表示所关联的信息限定为
“
收款单
”
的信息类型。
第
5
行,表示关联类别为:收款,即这些收款单是因
“
收款
”
而与对应的订单相关联的。
第
6
行,表示关联方向为:
A
,即订单收款后产生的收款单。
第
7
行到第
10
行,表示要对上述所关联的收款单进行统计,可通过调用统计关联信息的单元来实现,同时在此关联信息区域中建立一个统计信息存储区,用以保存所统计的信息。其下级内容表示了要做哪些统计,以及如何统计。
第
8
行,
<Count>COUNT(ID)</Count>
表示要在统计信息区创建一个名称为
“Count”
的统计变量,其值为对所关联的收款单的
ID
进行计数统计,这代表了此订单的收款次数。
COUNT
是一个统计指令
:
计数。
(ID)
表示对收款单的
ID
进行计数。
第
9
行,表示要在统计信息区创建一个名称为
“Sum”
的统计变量,其值为对所关联的收款单的金额值进行求和,这代表了此订单的收款总额。
SUM
是一个统计指令
:
求和。
(Amount)
表示求和的对象为收款单的
Amount
元素,即收款金额。
第
12
行到第
18
行,表示要向对应的订单附加一些信息数据,这些数据将保存在此订单的附加数据区域。其下级内容表示了要附加哪些数据,以及如何得到这些数据的值。
第
13
行,表示在附加数据区创建一个名称为
“
收款次数
”
的对象
(
变量
)
,其值为:在名称为
“
关联收款单
”
的关联信息区中的统计信息:
Count
变量中的值。
第
14
行,表示在附加数据区创建一个名称为
“
是否收款
”
的对象
(
变量
)
,其值为:收款次数的值是否大于
0
(是或否)。其中
Append(
收款次数
)
表示附加数据区中名称为
“
收款次数
”
的对象
(
变量
)
。
Boolean
是一个运算指令:对括号中的表达式求布尔值(是或否)。
第
15
行,表示在附加数据区创建一个名称为
“
收款总额
”
的对象
(
变量
)
,其值为:在名称为
“
关联收款单
”
的关联信息区中的统计信息:
Sum
变量中的值。
第
16
行,表示在附加数据区创建一个名称为
“
欠款额
”
的对象
(
变量
)
,其值为:订单金额与收款总额的差。
Field(Amount)
表示订单的
Amount
元素,即订单金额。
Append(
收款总额
)
表示订单的附加数据区中名称为
“
收款总额
”
的对象
(
变量
)
。
“-”
将这两个对象连接起来构成一个减法表达式,其值为这两个对象值之差。
第
17
行,表示在附加数据区创建一个名称为
“
是否欠款
”
的对象
(
变量
)
,其值为:欠款额的值是否大于
0
(是或否)。其中
Append(
欠款额
)
表示附加数据区中名称为“欠款额”的对象
(
变量
)
。
Boolean
是一个运算指令:对括号中的表达式求布尔值(是或否)。















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









