







常用的缩写:
缩写 意义
L2 链路层(如ethernet)
L3 网络层(如ip)
L4 传输层(如tcp/udp/icmp)
BH 下半部(Bottom Half)
IRQ 中断(事件)
RX 接收
TX 发送
圾收集:
内存是有限的共享资源,不应该浪费,特别是在内存中,因为内核不使用虚拟内存。多数内核子系统会实现某种垃圾收集,以回收由未使用的或无效的数据结构实例所持有的内存。根据特定的功能所需而定,你会发现有两种主要的垃圾收集:
异步:
这种垃圾收集类型和特定事件无关。一个定时器会定期启用一个函数,以扫描一组数据结构,然后把那些适合删除的数据结构释放掉(常见的准则为是否存在null引用计数)。
同步:
在内存不足时,会立即触发垃圾收集,而不能等待定时器触发的异步垃圾收集。
函数指针:
执行一个函数指针之前,必须先检查其值。避免使用为null的函数指针。
if (dev->init && dev->init(dev) != 0 ) {
...
}缺点:使阅读代码稍显困难。
goto语句:
使用环境
用于处理函数内的不同返回代码。
用于跳出一层以上的循环嵌套。
捕捉bug :
BUG_ON(): 参数为真时,打印错误消息,然后内核panic.
BUG_TRAP(): 参数为真时, 内核会打印出警告消息。
向量定义(零长数组):
struct abc{
int age;
char *name[20];
...
char placeholder[0];
}可选区块从placeholder开始。注意placeholder定义的大小为0的向量。也就是说,当abc被分配为带有可选区块时,placeholder就指向此区块的起始处。不需要可选区块时,placeholder就只是一个指向此结构微端的指针而已,不耗用任何空间。
死代码:
内核像其他大型而动态演变的软件一样,也会包括一些不再被调用的代码片段。不幸得是,代码中的注释很少会告诉你这一点。有时候,只是因为你看的是死代码,害得你无法理解给定函数的用法或者给定变量的初始化是怎么回事。因此,看到似乎在做很奇怪的事的代码或者代码没有遵守通用而常识性的程序设计规则时,把这件事谨记在心是很有益的。
数据结构:
Linux网络子系统中存在一些很重要的数据结构,贯穿整个子系统,主要有以下两个:
struct sk_buff:数据封包结构。所有的网络分层都会使用这个结构来存储其报头、有关用户数据,以及协调其他工作的其他内部信息。struct net_device:在Linux内核中,每种网络设备都用这个数据结构表示,包括软硬件的配置信息。
套接字缓冲区:sk_buff结构
这可能是Linux网络代码中最重要的数据结构,表示数据报文。这个结构定义在头文件中,由巨大的变量堆组成,试图满足所有人的所有需求。
这个结构的字段大致分为以下几个类型:
- 网络层次
- 通用字段
- 功能专用
- 管理函数
在网络系统的不同网络层都会使用这个结构,而当这个结构从一个分层传到另一个分层时,其不同的字段会随之发生改变。如L4层在传递给L3之前会附加一个报头,通用L3到L2之前也会加上自己的报头。附加报头比把数据从一个分层拷贝到另一个分层更有效率。
由于要在一个缓冲区开端新增空间(也就是修改指向缓冲区头部的指针),内核提供了skb_reserve函数来执行这个操作。所以,当缓冲区往下传递给每个网络层时,每层的协议首先要做的就是调用skb_reserve函数为该协议的报头预留空间。
而在缓冲区向上传递给上层网络时,并没有本层报头从缓冲区中删除,二是将直线有效数据的指针向前移到上层的报头位置。
由于网络代码提供了大量的选项性功能,不一定总是需要,如防火墙、多播、连接跟踪等,这些功能都会在sk_buff结构猪附加上字段。因此,sk_buff结构中有许多由C预处理#ifdef指令附加的字段。一般而言,任何引起内核数据结构改变的选项,都不适合编译成一个模块进行动态加载。
sk_buff中的某些字段是为了组织数据结构本身:
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
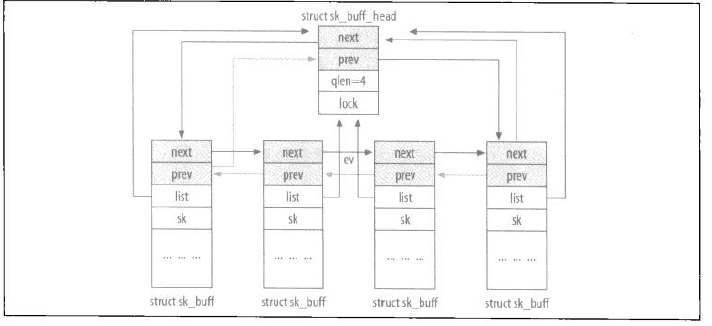
同时为了迅速找到整个表的头,在表的开端额外增加一个sk_buff_head结构作为一种哑元元素,sk_buff_head结构是:
struct sk_buff_head {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
__u32 qlen;
spinlock_t lock;
};- qlen是表中元素的数目,lock是用于防止对表的并发访问。
- sk_buff和sk_buff_head结构的前两个元素是相同的,所以同样的函数也可用于操作sk_buff和sk_buff_head二者。
每个sk_buff结构都包含一个指针,指向专一的sk_buff_head结构,增加了其复杂性。这个指针的字段名称为list。
看图:
sk_buff中的其他字段:
- struct sock *sk:指向拥有此缓冲区的套接字的sock数据结构。当数据在本地产生或者正在由本地进程接收时,就需要这个指针,因为该数据以及套接字相关的信息会由L4层(TCP或UDP)以及用户应用程序使用。当缓冲区只是被转发时,该指针就是NULL。
- unsigned int len:这是指缓冲区猪数据区块的大小。这个长度包括主要缓冲区(由head所指)的数据以及一些片段(fragment)的数据。当缓冲区从一个网络层传递给下一个网络层时,其值会发生变化。因为在协议栈中往上移动时,报头会被丢弃。但是往下移动时,报头会被添加进来,len会将协议报头长度算在里面
- unsigned int data_len:与len不同,data_len只计算片段中的数据大小
- unsigned int mac_len:MAC报头的大小
- atomic_t users:引用计数,或者使用这个sk_buff缓冲区的实例的数目。这个参数的的主要用途是避免这个结构仍在使用时,被另一个实例释放掉。users有时直接使用atimic_inc和atomic_dec函数递增和递减,但在大多数时候,采用skb_get和kfree_skb进行处理。
- unsigned int truesize:表示此缓冲区的总大小,包括sk_buff结构本身。当此缓冲区得到所分配的len个字节的数据请求空间时,此字段的初始化由alloc_skb函数设置为len+sizeof(sk_buff)。每当skb->len的值增加时,此字段就会得到更新。
sk_buff_data_t tail
sk_buff_data_t end
unsigned char *head
unsigned char *data这些字段代表缓冲区的边界以及其中的数据。当每一层为其工作而准备缓冲区时,可能会为了一个报头或更多的数据分配更多的空间。head和end指向已分配空间的开端和尾端,而data和tail指向实际数据的开端和尾端。因此,可以再head和data直接填充报文头,在tail和end之间增加新的数据。
其中tail和end根据系统是否使用NET_SKBUFF_DATA_USES_OFFSET来决定使用偏移地址还是指针
#ifdef NET_SKBUFF_DATA_USES_OFFSET
typedef unsigned int sk_buff_data_t;
#else
typedef unsigned char *sk_buff_data_t;
#endif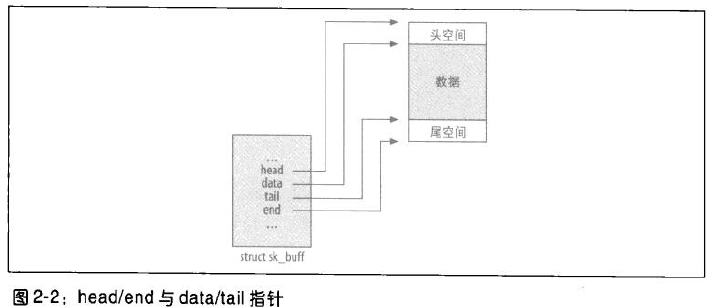
void (*destructor)(struct sk_buff *skb):此函数指针所指的函数在缓冲区被删除时,完成某些工作。当此缓冲区不属于一个套接字时,destructor通常不会被初始化。但若属于一个套接字时,通常被设置为sock_rfree或sock_wfree。这两个函数可用于更新套接字队列中所持有的内存。
sk_buff结构中有一些通用字段,和特定内核功能无关:
ktime_t tstamp:对一个已接收的封包才有意义。这是一个时间戳,表示接收包的时间,或者有时用于表示封包预定的传输时间。这个丢按由netif_rx函数调用net_timestamp_check设置,而这个函数在接收每个包后由设备驱动程序调用。
struct net_device *dev:这个字段描述一个网络设备,由dev代表的设备角色依赖于这个封包是即将发出的数据包还是刚被接收的数据包。即若是即将发出的数据包,这个网络设备代表发送设备,否则就是接收设备。
有些网络功能允许一些设备按组集合起来代表一个虚拟的接口,有一个虚拟设备驱动程序提供接口服务。当该设备驱动程序被调用时,dev参数会指向此虚拟设备的net_device结构。但该驱动程序会从其组中选择一个特定的物理设备,然后将dev参数指向真实物理设备的net_device结构。因此,这种情况下,在包的处理期间传输设备的指针可能会变化。
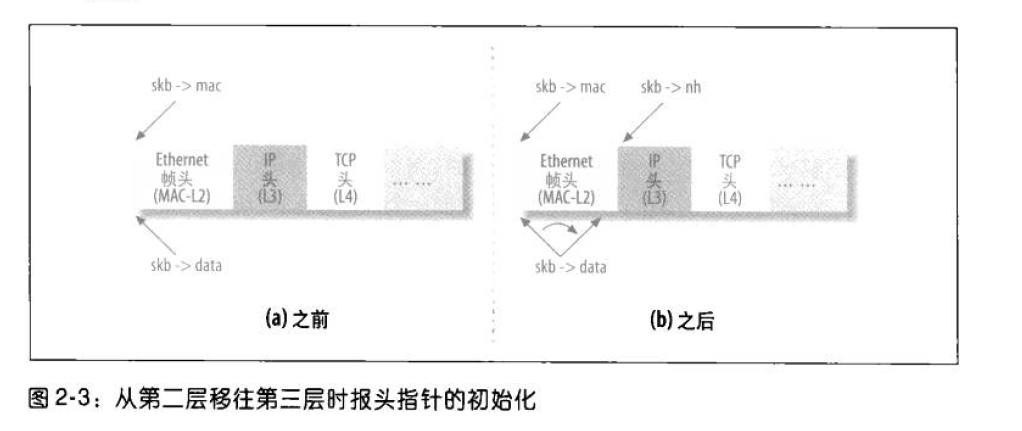
sk_buff_data_t transport_header:
sk_buff_data_t network_header:
sk_buff_data_t mac_header: 这些是指向TCP/IP协议栈的协议报头,其值是偏移地址还是指针取决于系统NET_SKBUFF_DATA_USES_OFFSET是否生效。这些字段分别代表传输层、网络层和链路层的报头位置。当接受一个数据包时,负责处理第n层报头的函数,会从第n-1层接收缓冲区,而该缓冲区的skb->data指向第n层报头的位置,同时将其对应层的指针进行初始化(如,网络层会将network_header字段指向网络层报头位置),因为当下一层进行处理时,skb->data会被设置指向其对应层报头的位置。
unsigned long _skb_refdst:这个字段由路由子系统使用。
char cb[48]:这是一个控制缓冲区(control buffer),也就是每层的私有存储空间。48个字节足以容纳每层所需的私有数据。在每一层都是通过宏进行访问的。如在tcp.h中,TCP使用这个空间来存储一个tcp_skb_cb数据结构:
struct tcp_skb_cb {
union {
struct inet_skb_parm h4;
#if defined(CONFIG_IPV6) || defined (CONFIG_IPV6_MODULE)
struct inet6_skb_parm h6;
#endif
} header; /* For incoming frames */
__u32 seq; /* Starting sequence number */
__u32 end_seq; /* SEQ + FIN + SYN + datalen */
__u32 when; /* used to compute rtt's */
__u8 flags; /* TCP header flags. */
__u8 sacked; /* State flags for SACK/FACK. */
#define TCPCB_SACKED_ACKED 0x01 /* SKB ACK'd by a SACK block */
#define TCPCB_SACKED_RETRANS 0x02 /* SKB retransmitted */
#define TCPCB_LOST 0x04 /* SKB is lost */
#define TCPCB_TAGBITS 0x07 /* All tag bits */
#define TCPCB_EVER_RETRANS 0x80 /* Ever retransmitted frame */
#define TCPCB_RETRANS (TCPCB_SACKED_RETRANS|TCPCB_EVER_RETRANS)
__u32 ack_seq; /* Sequence number ACK'd */
};
#define TCP_SKB_CB(__skb) ((struct tcp_skb_cb *)&((__skb)->cb[0]))在TCP子系统的net/ipv4/tcp_ipv4.c文件中,tcp_v4_rcv函数对这个结构进行了填充:
th = tcp_hdr(skb);
iph = ip_hdr(skb);
TCP_SKB_CB(skb)->seq = ntohl(th->seq);
TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin +
skb->len - th->doff * 4);
TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);
TCP_SKB_CB(skb)->when = 0;
TCP_SKB_CB(skb)->flags = iph->tos;
TCP_SKB_CB(skb)->sacked = 0; 














 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









