







内核文件解读
为了解决 initcall_t到底是什么变量类型则必须提及 C 语言中一个比较少见的内容——可执行文件格 式,只有了解了这种文件格式才能具体知道 initcall_t 的意义。
ELF 文件格式
ELF 是*nix 系统上可执行文件的标准格式,它取代了 out 格式的可执行文件,原因在于它的可扩展 性。 ELF 格式的可执行文件可有多个 section。DWARF(Debugging With Attribute Record Format)是经常 碰到的名词,它在 ELF 格式的可执行文件中。
ELF文件有三种不同的形式:
1. Relocatable:由编译器和汇编器生成,由 linker 处理它。
2. Executable:所有的重定位和符号解析都完成了,也许共享库的符号要在运行时刻解析。
3. hared Object:包含 linker 需要的符号信息和运行时刻所需的代码。
ELF 文件有双重性质:一方面,编译器、汇编器、连接器都把它看作是逻辑段(sections)的集合, 另一方面 loader 把它看作段(segments)的集合。Section 是给 linker 做进一步处理的,而 segments 是被 映射到内存中去的。 (中文里面 section 可以叫做节也可以叫段,而 segment 亦然,为避免歧义,这里坚持 用英文表示)一个 segment 可以由几个 sections 组成。为了定位不同 segment/section,可执行文件用一个 table 来记录各个 segment/section 的位置和描述。Relocatable 有 section table,Executable 有 program header table。而 Shared Object 两者都有。
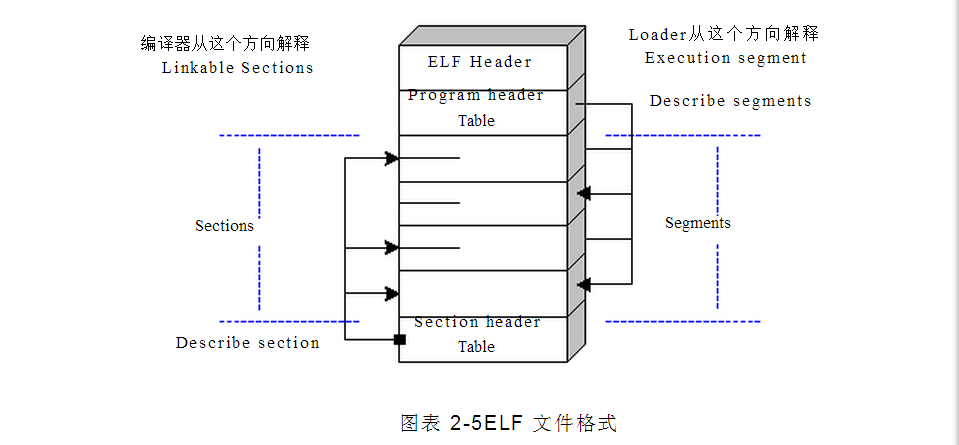
上图演示了从不同的角度来解释 segment 和 section 的不同。
当 as 生成一个目标文件时,它假设程序段是从地址 0 开始,ld 则把最后的地址赋给这个程序段.以至于 不同的程序段不会相互复盖。ld 把程序移动到各自的运行时地址,指定 section 的运行时地址叫重定位 (relocation)。
as 输出的目标文件至上有三个 section,任何一个都有可能为空,它们是 text,data,bss 段。你可以不写诸 如.text 或.data 段,但目标文件中还是存在这些段,只不过是空的,在目标文件中段是如下排列
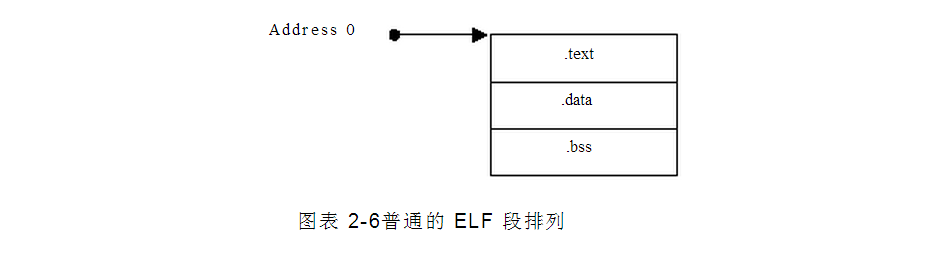
为了让 ld 能正确重定位各段,as 生成一些重定位所需的信息。
实际上 as 用的每一个地址都是以这样的形式:(section)+(offset into section)表示,ld 把所有相同的 section 放到连续的地址里。你还可以用 subsections 把一个大的 section 分成多个小的 section。可以用标号 来区分,这里就不细说了。
普通情况下 ld 处理四种段:
named section:
text section
data section //这两个段放着你的程序,它们是分开的但是却是相等的段。只是在运行的时刻,text 段不 能被改变。
bss section
absolute section //这个段的 0 地址总是被重定位到运行地址0
undefined section //用来放置不在前面几个段里的数据。
对于一个在 text、data、bss 中的符号而言,它的值就是从段首到它的偏移,于是,当 ld 在连接各段 时就改变了 label 的值。
对于没有定义(undefined)的值,ld 尽量从外部其他文件引入并确定其值。
不同的 sections 的含义(大家都知道的我就不说了):
.dynamic:该 section 保存着动态连接的信息。
.dtnstr:保存动态连接时需要的字符串。
.dynsym:保存动态符号表如“symbol table”的描述。
.interp:保存程序的解释程序(interperter)的路径
.line:包含编辑字符的行数信息,它描述源代码与机器代码之间的对应关系。
.rel<name>和.rela<name>:保存重定位的信息。
.rodata和.rodata1:保存只读数据,在进程映像中构造不可写的段。
前缀是点(.)的 section 名是系统保留的
Link Scripts 知识
我们通常有一个疑问,为什么我们编出来的代码肯定是在用户地址空间运行,而内核编出来的代码 却一定是运行在内核空间?如果我们把目光仅仅盯在 C 文件或 h 文件甚至 Makefile,估计想破脑袋也不 知道为什么会这样。其实我们经常忽视了链接器的作用。不能简单地认为链接器仅仅完成将各 obj 文件 拼在一起的任务,而且它还指定每个段被装入内存的真正地址,没错,是装入!
链接器(Linker)其实有自己的一套语言规范,其目的是描述输入文件中的 sections 是如何映射到输 出文件中,并控制输出文件的内存排列。如果你从来没有看到过 ld script,那么请用 ld -verbose 查看输出 结果,那就是 ld script。只是它是内置在链接器中,而且 ld 就是使用这个缺省的 script 去生成输出我们平 时应用程序 obj,所以如果是用缺省的 ld script 生成内核,那么它肯定也只能跑在用户空间。
我们已经知道每一个目标文件有一个 sections 的列表,在输入文件中,是 input section,在输出文件 中叫 output section。每个 section 有名字和大小。大多数 section 有相关的数据块,就是 section contents。 一个 section 可以是标记为 loadable,意味着输出文件在运行时可以把这一 section 装入内存。没有内容的 section 可以叫 allocatable,表示这块区域放在内存的某个地方,但没有什么特殊的东西放在里面(一般都 是被初始化为 0),一个既不是 loadable 也不是 allocatable 的 section 一般是包含一堆调试信息。
每一个 loadable 和 allocatable 的 section 有两个地址。第一个是 VMA,即虚存地址。这是输出文件运 行时的地址。第二个是 LMA,即装入内存地址。这是 section 被装入的地址。在多数情况下,这两个地 址是相同的。他们不同的例子是:当数据 section 被装入 ROM,当程序开始执行时被复制到 RAM(这个 技术通常用来初始化基于 ROM 系统的全局量)。
你可以用 dumpobj -h 去查看目标文件的 section 信息。每个目标文件有符号表。每个符号有一个名字, 且每个有定义的符号有一个地址及其他信息。你可以用 nm查看符号表信息,也可以用 objdump -t命令查 看。
最简单的 script 只有一个 SECTIONS 命令。它描述输出文件的内存排列。
例子:
SECTIONS {
.=0x10000; /*代码被装入到此地址*/
.text SIZEOF_HEADERS:{
*(.init)
*(.text)
*(.fini)
}
.=0x8000000; /*数据被装入到此地址*/
.data:{*(.data)}
.bss:{*(.bss)} }
在上例中,第 3 行的’.’是一个特殊符号,用来做定位计数器。它根据输出段的大小增长。在 SECTIONS 开始时它等于 0。
‘*‘是一个通配符,匹配所有的文件,表达式”*(.text)“表示所有输入文件的”.text“段。输出文件的.text段包含所有输入文件的.init 和.text 及.fini。
在 linker 放置”.data“后,定位计数器的值等于0x8000000加上”.data“的大小。然后 linker 会把.bss 段放在.data 之后。注意:linker 可能会在.data和.bss 段之间划出一个 gap。
程序中执行的第一条指令叫 entry point,可以用 ENTRY 指定入口点。如ENTRY(symbol)。linker 有 几种方法设置入口点:
1。在命令行中输入`-e entry`
2。在 linker script 文件中指定 `ENTRY(symbol) `
3。如果定义了 start,则 start 的值就是入口点
4。.text 的第一个字节
5。地址 0
在一些目标文件里,公共符号不属于某个特别的段,linker 认为它们属于一个叫 COMMON 的段,大 多数情况,输入文件里的公共符号被放在输出文件的.bss 段中,如
.bss {*(.bss) *(COMMON)}
输出段属性
linker 一般在 input section 的基础上设置 output section 的属性。 可以使用 AT 命令改变地址值。 覆盖命令提供了一个简单的方法把不同的 section 装入单一内存镜像中,但在执行的时候是从同一的 地址开始执行。
PROVIDE 输出符号以便让 linker 能在解析过程中用到。用法是 PROVIDE(symbol = express)。
例如
SECTIONS {
.text : {
*(.text)
_etext = .;
PROVIDE(etext = .);
}
} 如果程序里定义了_etext,则 linker 会报错:多个_etext 的定义。但如果程序定义了 etext,则编译器 默认使用程序里的etext 定义;如果程序没有定义etext 但却用到了etext,则 linker 使用 link script 中的定 义。
Linux 内核镜像研究
下面我们就拿 Linux 内核源代码作为复习以上的例子。先回顾 include/linux 目录下这么一个 init.h 文 件,它不仅定义了 initcall_t 类型变量,还定义了一些常规 C 语言编程中未见过得类型:
#ifndef _LINUX_INIT_H
#define _LINUX_INIT_H
#include <linux/compiler.h>
#include <linux/types.h>
/* These macros are used to mark some functions or
* initialized data (doesn't apply to uninitialized data)
* as `initialization' functions. The kernel can take this
* as hint that the function is used only during the initialization
* phase and free up used memory resources after
*
* Usage:
* For functions:
*
* You should add __init immediately before the function name, like:
* 对于函数,应该在函数名之前加一个__init,如下:
* static void __init initme(int x, int y)
* {
* extern int z; z = x * y;
* }
*
* If the function has a prototype somewhere, you can also add
* __init between closing brace of the prototype and semicolon:
* 如果函数在其他地方有原型,那么你可以在括号和分号之间加__init,如下
*
* extern int initiali 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 61
61











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









