




一、卷积层(Convolution Layers)
卷积层是卷积神经网络(CNN)中的核心组件,用于提取输入数据的特征。它们通过应用卷积运算来捕捉局部的空间特征,非常适合处理图像和视频等具有空间结构的数据。
1. 卷积层的基本概念
卷积层通过在输入图像上滑动一个小的卷积核(也称为滤波器),计算每个位置的加权和来生成特征图。卷积核的权重是可以学习的参数,通过训练数据进行优化。
主要参数:
- 输入通道数(in_channels):输入数据的通道数。例如,RGB图像的通道数为3。
- 输出通道数(out_channels):卷积层输出的通道数,即卷积核的数量。
- 卷积核大小(kernel_size):卷积核的空间尺寸,通常是一个整数(例如3表示3x3的卷积核)或一个元组(例如(3, 3))。
- 步幅(stride):卷积核在输入上滑动的步长。默认值为1。
- 填充(padding):在输入的边缘补充零,使卷积核可以在边缘处理。默认值为0。
2. PyTorch中的二维卷积层(nn.Conv2d)
代码示例:
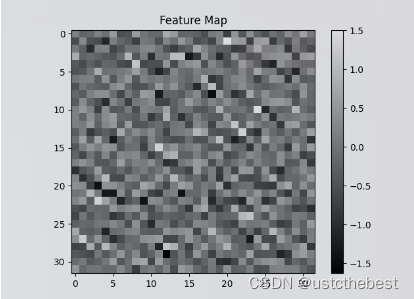
import torch import torch.nn as nn # 定义一个二维卷积层 conv_layer = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1) # 创建一个输入张量,形状为(批量大小, 通道数, 高度, 宽度) input_tensor = torch.randn(1, 3, 32, 32) # 通过卷积层处理输入张量 output_tensor = conv_layer(input_tensor) print(output_tensor.shape) # 提取第一个通道的特征图 feature_map = outputimg[0, 0, :, :].detach().numpy() # 可视化特征图 plt.imshow(feature_map, cmap='gray') plt.colorbar() plt.title('Feature Map') plt.show()
在这个示例中,我们定义了一个卷积层,输入通道数为3,输出通道数为16,卷积核大小为3x3,步幅为1,填充为1。输入张量为一个随机生成的32x32的RGB图像。卷积层处理输入张量后,输出张量的形状为(1, 16, 32, 32)。
详细解释:
- 输入通道数(in_channels):卷积层接收输入数据的深度。例如,对于RGB图像,深度为3。
- 输出通道数(out_channels):卷积层生成的特征图的深度。每个卷积核会产生一个特征图。
- 卷积核大小(kernel_size):定义卷积核的高度和宽度。例如,3x3卷积核会考虑3x3区域内的像素。
- 步幅(stride):决定卷积核在输入图像上滑动的步长。步幅越大,输出特征图的尺寸越小。
- 填充(padding):在输入图像的边缘添加额外的像素,以便卷积核能够处理图像边缘。填充越多,输出特征图的尺寸越大。
3. nn.Conv2d对数据进行读取和卷积
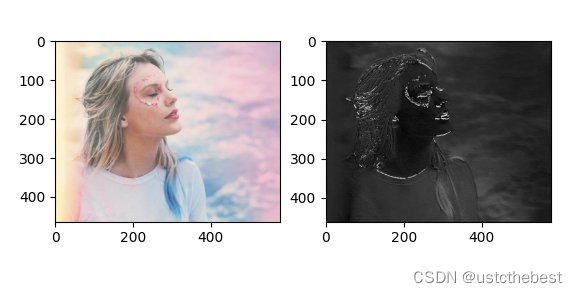
import torch import torch.nn as nn import matplotlib.pyplot as plt import os import torch import torch.nn as nn import matplotlib.pyplot as plt from PIL import Image from torchvision import transforms def transform_invert(img_tensor, transform): """ 反转图像的预处理操作 :param img_tensor: 经过预处理的图像张量 :param transform: 预处理操作 :return: 反转预处理操作后的图像 """ if 'Normalize' in str(transform): mean = torch.tensor(transform.transforms[1].mean) std = torch.tensor(transform.transforms[1].std) img_tensor = img_tensor * std[:, None, None] + mean[:, None, None] img_tensor = img_tensor.squeeze() # 移除批量维度 img = transforms.ToPILImage()(img_tensor) # 转换为PIL图像 return img # ================================= load img ================================== # 定义图像预处理变换 transform = transforms.Compose([ # transforms.Resize((128, 128)), # 调整图像大小 # transforms.RandomHorizontalFlip(), # 随机水平翻转 # transforms.RandomRotation(10), # 随机旋转10度 # transforms.ColorJitter(brightness=0.5), # 随机改变亮度 transforms.ToTensor(), # 转换为张量并归一化到[0, 1] transforms.Normalize((0.5,), (0.5,)) # 用均值0.5和标准差0.5归一化 ]) # 加载图像 image = Image.open("taylorpicture.jpg").convert("RGB") # 应用预处理变换 transformed_image = transform(image) # 检查变换后的图像 print(transformed_image.size()) # image.show() # 转换为张量 img_transform = transforms.Compose([transforms.ToTensor()]) img_tensor = img_transform(image) # 添加 batch 维度 img_tensor.unsqueeze_(dim=0) # =============== create convolution layer ================== # 定义一个二维卷积层 input_convd = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=3) nn.init.xavier_normal_(input_convd.weight.data) # 通过卷积层处理输入张量 img_conv = input_convd(img_tensor) print(img_conv.shape) # ================================= visualization ================================== print("卷积前尺寸:{}\n卷积后尺寸:{}".format(img_tensor.shape, img_conv.shape)) img_conv = transform_invert(img_conv[0, 0:1, ...], img_transform) img_raw = transform_invert(img_tensor.squeeze(), img_transform) plt.subplot(122).imshow(img_conv, cmap='gray') plt.subplot(121).imshow(img_raw) plt.show()卷积前,图像尺寸是464×580, 卷积后, 图像尺寸是462×578。我们这里的卷积核设置, 输入通道3, 卷积核个数1, 卷积核大小3, 无padding,步长是1, 那么我们根据上面的公式, 输出尺寸:(464−3)/1+1=462 (580−3)/1+1=578
torch.Size([3, 464, 580]) torch.Size([1, 1, 462, 578]) 卷积前尺寸:torch.Size([1, 3, 464, 580]) 卷积后尺寸:torch.Size([1, 1, 462, 578])
3.1 增加 batch 维度
img_tensor.unsqueeze_(dim=0)这行代码使用
unsqueeze_方法在张量的第0维添加一个新的维度。unsqueeze_方法是原地操作,会直接修改img_tensor而不是返回一个新的张量。在此之前,
img_tensor只有通道、高度和宽度。为了让这个张量能够作为输入传递给卷积神经网络模型,我们通常需要一个包含批量大小的维度(batch size)。卷积神经网络的输入通常是四维张量,形状为[batch_size, channels, height, width]。通过在第0维添加一个维度,这里的1表示批量大小,即一次处理一个图像。3.2 增加卷积权值初始化
在这段代码中,
nn.init.xavier_normal_使用了Xavier正态分布来初始化卷积层的权重。这种初始化方法使得每个卷积核中的权重值根据一个正态分布随机生成,分布的标准差根据输入和输出的通道数进行计算,确保每一层输出的方差稳定。总结:通过这些操作,可以确保图像正确加载为张量,并以适合卷积神经网络输入的格式传递。
4. nn.ConvTranspose 转置卷积
转置卷积(Transposed Convolution)也称为反卷积(Deconvolution),是一种用于上采样(Upsam
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









