







待处理文件
准备待处理文件student.data,内容如下:
1|vincent|13827460000|gvark@eyou.com
2|jenny|13827460002|ovwgofpa@56.com
3|sofia|13827460003|jfbmgpm@netease.com
4|natasha|13827460004|vjtw@35.com
5|catalina|13827460005|bpnoc@qq.com
6|jax|13827460006|rfieancklpvq@yahoo.com.cn
7|missfortune|13827460007|crwglpmmwsv@qq.com
8|anny|13827460008|nmbigtektdbow@qq.com
9|jinx|13827460009|jqu@xinhuanet
10|ezrio|13827460010|wvvoio@netease.com
11|lucas|13827460011|fgn@email.com.cn
12||13827460012|klukgp@yahoo.com.cn
13|NULL|13827460013|pgovoloacfuoed@etang.com
特别注意最后第二个字段有特点。
代码实现
首先测试分隔符:
package cn.ac.iie.spark
import org.apache.spark.sql.SparkSession
/**
* DataFrame中的操作
*/
object DataFrameCase {
def main(args: Array[String]): Unit = {
val DataFrameCase = SparkSession.builder().appName("DataFrameCase").master("local[2]").getOrCreate()
val rdd = DataFrameCase.sparkContext.textFile("file:///E:/test/student.data")
// 注意需要导入隐式转换
import DataFrameCase.implicits._
val studenntDF = rdd.map(_.split("\\")).map(line => Student(line(0).toInt, line(1), line(2), line(3))).toDF()
studenntDF.show()
DataFrameCase.close()
}
case class Student(id: Int, name: String, phone: String, email: String)
}
输出如下:

注意分隔符应该使用转义字符进行转移,否则出现下面的情况,就不是我们所期望的了:
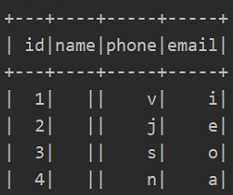
同时可以看到,当邮箱长度过长时,会出现...的情况。
可以使用show(20, false)重载方法(第一个参数表示显示多少行,第二个方式表示是否截取),来解决这个问题。
studenntDF.select("email").show:只显示email数据studenntDF.filter("name='' OR name='NULL'").show(false):只显示name为空或者NULL的数据studenntDF.filter("SUBSTR(name,0,1)='v'").show(false):显示name第一个字符为v的数据。SUBSTR与SUBSTRING等价。studenntDF.sort(studenntDF.col("name")).show():按照name进行字母顺序排序studenntDF.sort(studenntDF.col("name").desc).show():按照name进行降序排序studenntDF.sort(studenntDF.col("name").desc, studenntDF.col("email")).show():按照name进行降序,email进行升序studenntDF.join(studenntDF2, studenntDF.col("id") === studenntDF2.col("id"), "inner").show():进行join操作,默认是内连接。















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









