









一、 利用spark从hadoop的hdfs中读取数据并计算
1.1准备阶段
部署好hadoop分布式搭建(+zookeeper,6台机器)可以参考这篇博客:http://blog.csdn.net/vinsuan1993/article/details/70155112
| 主机名 | IP | 安装的程序 | 运行的进程 |
| Heres01 | 192.168.2.108 | jdk、hadoop、zookeeper、spark | DataNode JournalNode Master QuorumPeerMain NodeManager |
| Heres02 | 192.168.2.99 | jdk、hadoop、zookeeper、spark | DataNode JournalNode Worker QuorumPeerMain NodeManager |
| Heres03 | 192.168.2.109 | jdk、hadoop、zookeeper、spark | DataNode JournalNode Worker QuorumPeerMain NodeManager |
| Heres04 | 192.168.2.113 | jdk、hadoop | ResourceManager |
| Heres05 | 192.168.2.112 | jdk、hadoop | DFSZKFailoverController NameNode |
| Heres06 | 192.168.2.110 | jdk、hadoop | DFSZKFailoverController NameNode |
部署好spark集群,可以参考这篇博客:http://blog.csdn.net/vinsuan1993/article/details/75578441
1.2启动hdfs
1.2.1启动zookeeper集群(分别在heres01、heres02、heres03上启动zk)
cd/heres/zookeeper-3.4.5/bin/
./zkServer.shstart
#查看状态:一个leader,两个follower
./zkServer.shstatus
1.2.2启动journalnode(在heres01上启动所有journalnode,注意:是调用的hadoop-daemons.sh这个脚本,注意是复数s的那个脚本)
cd/heres/hadoop-2.2.0
sbin/hadoop-daemons.shstart journalnode
#运行jps命令检验,heres01、heres02、heres03上多了JournalNode进程
1.2.3启动HDFS(在heres01上执行)
sbin/start-dfs.sh
到此,hadoop2.2.0配置完毕,可以通过浏览器访问:
http://192.168.2.110:50070
NameNode'heres06:9000' (active)
http://192.168.2.112:50070
NameNode 'heres05:9000' (standby)
1.3.启动spark集群
/bigdata/spark-1.6.1-bin-hadoop2.6/sbin/start-all.sh
1.4.启动spark-shell
bin/spark-shell --masterspark://heres01:7077 --executor-memory 512m --total-executor-cores 2
注:“-”前面是没有空格的,否则会报错
1.5.上传文件到hdfs上
hdfs dfs-mkdir /wc
dfs dfs -ls /
hdfs dfs-put words.txt /wc/1.log
hdfs dfs-put words.txt /wc/2.log
hdfs dfs -put words.txt /wc/3.log
1.6.在spark-shell中编写spark程序
sc.textFile("hdfs://heres06:9000/wc").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
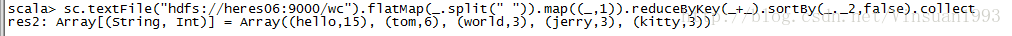
sc.textFile("hdfs://heres06:9000/wc").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).saveAsTextFile("hdfs://heres06:9000/vinout")
结果会生成三个文件
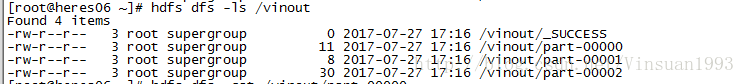
sc.textFile("hdfs://heres06:9000/wc").flatMap(_.split("")).map((_,1)).reduceByKey(_+_,1).sortBy(_._2,false).saveAsTextFile("hdfs://heres06:9000/vinout1")
结果会生成一个文件















 2483
2483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









