







概念引入
关联容器有四种:set、multiset、map、multimap
之所以称之为关联容器,是因为可以通过键值key来查找容器的元素
键值和元素唯一对应的是单重关联容器:set和map
一个键值可以对应多个元素的是多重关联容器:multiset和multimap
set可以被视为只有关键字而没有相关的映射值的map。
可以正确输出15的代码表达:
map<int, int> maps;
maps.insert(pair<int, int> (10, 15));
cout << maps.find(10)->second << endl;只用键值来构建的是简单关联容器:set<键值>,multiset<键值>
构建时需要附加数据类型的是二元关联容器:map<键值,数据>,multimap<键值,数据>
所以,set和map在查找上不同,set可知“是否存在”,map可返回附加数据。
set::insert(const value_type&val); 函数的返回值类型是什么?
pair<iterator,bool> set::insert(const value_type&val);
通过判断r.second这个bool值,就可知该元素是否存在了。
以上均为有序的关联容器,是使用比较运算符来实现
而无序的关联容器,例如unordered_set使用哈希和==来组织
在题目中学习
1.输入一串实数,将重复的去掉,取最大和最小者的中值,分别输出小于等于此中值和大于等于此中值的实数。
#include <set>
#include <iterator>
#include <utility>
#include <iostream>
using namespace std;
int main(){
set<double> s;//接收
while(true){
double v;
cin>>v;
if(v==0)break;//输入0结束,注意一开始直接输入0,程序不安全,集合为空,后续访问*iter1时会导致未定义行为
pair<set<double>::iterator,bool> r=s.insert(v);
//注意insert函数的返回值是pair<iterator,bool>
if(!r.second)//bool值为false,说明v此前已经存在
cout<<v<<"is duplicated"<<endl;
}
set<double>::iterator iter1 = s.begin();
set<double>::iterator iter2 = s.end();
double medium=(*iter1+*(--iter2))/2;
//iter2本身指的是最后一个元素之后的位置
cout<<"<=medium:";
copy(s.begin(),s.upper_bound(medium),ostream_iterator<double>(cout," "));
cout<<endl;
//将要符合范围从begin()开始到上限upper_bound(medium)的要输出的元素copy入输出流ostream_iterator<double>(cout," ")
cout<<">=medium:";
copy(s.lower_bound(medium),s.end(),ostream_iterator<double>(cout," "));
cout<<endl;
return 0;
}2.有五门课,每一门课有相应学分,从中选择3门,并输出学分总和。
#include <map>
#include <string>
#include <utility>
#include <iostream>
using namespace std;
int main(){
map<string,int> courses;
courses.insert(make_pair("DSA",3));
courses.insert(make_pair("C++",4));
courses.insert(make_pair("English",1));
courses.insert(make_pair("math",6));
courses.insert(make_pair("STL",3));
int n =3;//可选课的次数
int sum =0;//学分总和
while(n>0){
string name;
cin>>name;
map<string,int>::iterator iter=courses.find(name);
//查找find()的返回值类型为iterator
if(iter==courses.end()){
cout<<name<<"is not available"<<endl;
}else{
sum+=iter->second;
courses.erase(iter);//删除map某一对儿键值
n--;
}
}
cout<<"Total credit:"<<sum<<endl;
return 0;
}3.一句话中每个字母出现的次数
#include <map>
#include <string>
#include <utility>
#include <iostream>
using namespace std;
int main(){
map<char,int> s;
char c;
do{
cin>>c;
if(isalpha(c)){
c=tolower(c);
s[c]++;//对应c的存储次数的int++
}
}while(c!='.');
for(map<char,int>::iterator iter = s.begin();iter!=s.end();++iter){
cout<<iter->first<<" "<<iter->second<<" ";//调用字母和相应次数的方法
cout<<endl;}
return 0;
}4.上课时间查询
#include <map>
#include <string>
#include <utility>
#include <iostream>
using namespace std;
int main(){
multimap<string,string>courses;//课程名称和上课时间
typedef multimap<string,string>::iterator CourseIter;//定义这种类型名为CourseIter
courses.insert(make_pair("C++","2-6"));
courses.insert(make_pair("C++","2-7"));
courses.insert(make_pair("C++","2-8"));
courses.insert(make_pair("C","3-1"));
courses.insert(make_pair("C#","5-4"));
string name;
int count;//上课次数
do{
cin>>name;
count=courses.count(name);//这里的count返回一个课程名称name对应有几个上课时间,即上课次数
if(count==0)
cout<<"Cannot find this course!" <<endl;
}while(count==0);
cout<<count<<" lesson(s) per week:";
pair<CourseIter,CourseIter> range= courses.equal_range(name);//输出的范围区间应该是name对应的全部上课时间
for(CourseIter iter= range.first;iter!=range.second;++iter)
cout<<iter->second<<" ";//iter->first全是name
cout<<endl;
return 0;
}实践应用
1.编写一个程序,从键盘输入一个个单词,每接收到一个单词后,输出该单词曾经出现过的次数,接收到“QUIT”单词后程序直接退出。建议使用multiset或者map来解决该问题。
输入描述:一行一个单词,”QUIT”结束
输出描述:每行输出为相应单词统计结果

#include <map>
#include <string>
#include <utility>
#include <iostream>
using namespace std;
int out[100];
int main(){
map<string,int> m;
string c;
int i=0;
while(true){
cin>>c;
if(c=="QUIT"){
break;
}
out[i]=m[c];//这里的m[c]就是map m中c对应的个数int
m[c]++;
i++;
}
for(int j=0;j<i;j++)
cout<<out[j]<<endl;
return 0;
}2.输入n个数,对这n个数去重之后排序,并输出从小到大排序结果
(友情提示:去重函数unique、排序函数sort。STL容器的排序,支持随机访问的容器vector和deque。string没有sort成员,可调用std::sort排序;list排序调用自带的list::sort。)
输入描述:首先输入n,然后接着输入n个数。其中1<=n<=100,每个数的范围1<=x<=n
输出描述:输出去重之后从小到大排序结果
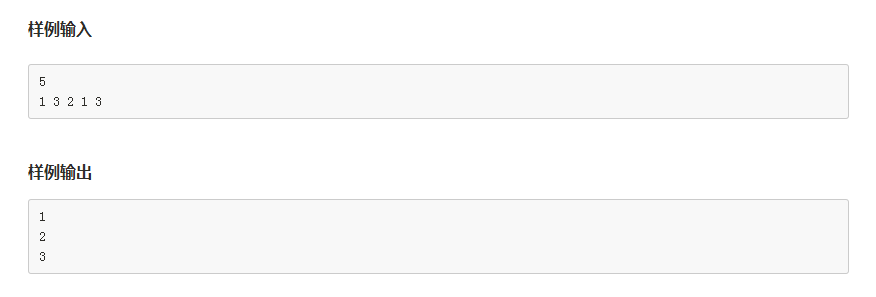
#include <vector>
#include <iterator>
#include <utility>
#include <iostream>
#include<algorithm>
using namespace std;
int main(){
int n;
cin>>n;
int data;
vector<int> v;
vector<int> iv;
while(n>0){
cin>>data;
v.push_back(data);//插入到vector的最末
--n;
}
sort(v.begin(), v.end());
unique_copy(v.begin() , v.end() , back_inserter(iv));
//copy(iv.begin(),iv.end(),ostream_iterator<int>(cout," "));
for(vector<int>::iterator iter = iv.begin() ; iter != iv.end() ; ++iter)
cout<<*iter<<endl;
return 0;
}unique()、unqiue_copy()这两个函数的剔除字符原理是,看当前字符与他前一个字符是否相同,如果相同就剔除当前字符,如果不同就跳转到下一个字符。所以在求一个字符串的字符集的时候要先把字符串排个序再调用上面两个函数剔除重复字符,获取字符集。
调用unique()“删除”了相邻的重复值。给“删除”加上引号是因为unique实际上并没有删除任何元素,而是将无重复的元素复制到序列的前段,从而覆盖相邻的重复元素。unique返回的迭代器指向超出无重复的元素范围末端的下一个位置。
注意:算法不直接修改容器的大小。如果需要添加或删除元素,则必须使用容器操作。
唯一的区别在于:unqiue_copy()第三个迭代器实参,用于指定复制不重复元素的目标序列。
3.给定一个串a和串b,求b在a中出现次数
(友情提示可以使用stl::count函数)
输入描述:字符串a,b的长度1<= len(a)<=100, 1<=len(b)<=len(a)
输出描述:一个数字















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









