







1、关联容器
1.1基本概念
关联容器也是存储数据的容器,但是和顺序容器很大的区别。
1、关联容器底层数据结构
底层存放红黑树
BST:二叉搜索树、二叉排序树:保证中序遍历排序升序有序。所以在插入结点时,需要调整结点红黑树:是一种特殊的BST树,把结点划分为红节点和黑节点,进行调整
2、关联容器分类
set:单集合容器multiset:多集合容器map:单映射容器multimap:多重映射容器
1.2关联容器都有的函数
1、构造函数
默认的构造函数:直接开辟空间,如set s传入迭代器(指针)区间的构造函数:传入起始位置,末尾位置,会把起始~末尾的迭代器区间元素传入容器。注意也可以传入数组,字符串的指针。如set s(arr,arr+len),将arr~arr+len区间的数据传入容器。注意map的数组不是一维数组,所以尽量不使用区间构造map。
2、其他函数
| 函数名称 | 含义 | 使用 |
|---|---|---|
| find查找函数 | 因为关联容器底层是红黑树,中序遍历有序,可以使用二分查找,所以关联容器实现了自己的find,利用二分查找实现元素,时间复杂度是O(logn),比泛型算法find时间复杂度O(n)速度快 | setiterator fit=s.find(x);//在s容器中查找元素x |
| count计数函数 | 返回关联容器中值为x的元素个数 | int co=s.count(x);//返回x的个数 |
| 清空函数 | 清空容器元素 | c.clear() |
3、类型别名
| 类型别名 | 含义 |
|---|---|
| key_value | 容器的关键字类型 |
| mapped_type | 每个关键字关联的类型,只适用于map |
| value_type | 对于set,与key_type相同;对于map,等同于pair,mapped_type> |
迭代器需要进行自加操作,用到it++,++it
- it++:先使用旧值运算,再++;原理:先对a进行备份,产生临时量,内置类型的临时量是常量,整个运算过程中用的都是临时量,直到表达式结束时,把a自加
- ++it:先自加++后,再运算。原理:用it本身进行自加,返回it本身
所以it=begin(),it++后,还是指向begin()位置;++it后向前走了一个,指向第二个位置。
2、set 详解
set单集合,存放元素value,不允许重复,不允许修改,按照一定次序存储,头文件为:
# include<set>
2.1基本操作
1、增
首先我们定义一个单重集合。他存储key值不会重复的元素
set<int> set1;
然后循环插入元素
for (int i = 0; i < 50; i++)
{
set1.insert(rand() % 20 + 1);
}
对于关联容器的insert只需要给入插入元素的值即可,不需要像vector/deque/list还要给出迭代器。因为其底层是哈希表对于该插入的位置有相应的函数计算
没有必要提供端点位置的数据插入(前插、尾插),因为尾插后,会将其调整,调整后不一定在最后,所以只需要提供任意位置插入函数即可。
插入时不需要传入位置,只需要传入数值即可,因为树形结构会进行调整。
插入方式:
| 插入方式 | 形式 | 含义 |
|---|---|---|
| 插入元素 | insert(val) | 将元素val插入set,插入后会自动调整排序 |
| 给指定位置插入元素 | insert(index,val) | 位置无效,只是为了和前面顺序容器兼容,你传入了位置,不一样插入指定的位置,因为存在自动调整 |
| 插入区间元素 | insert(first,last) | 在set中插入(first,last)区间的元素 |
2、查
方式一:采用迭代器遍历
auto it1 = set1.begin();
for (; it1 != set1.end(); ++it1)
{
cout << *it1 << " ";
}
方式二:采用for each遍历
for (int v : set1)
{
cout << v << " ";
}
3、删除
方式一:用迭代器遍历去找元素,找到了删除
for (it1 = set1.begin(); it1 != set1.end(); )
{
if (*it1 == 30)
{
it1 = set1.erase(it1);//调用erase,it1迭代器就失效了,所以要对迭代器更新
}
else
{
++it1;
}
}
方式二:使用函数find
find如果找不到元素会返回end迭代器
int main()
{
int arr[] = { 1,12,54,6,5,5 };
int len = sizeof(arr) / sizeof(arr[0]);
std::set<int> myset(arr, arr + len);
std::set<int> ::iterator it1 = std::find(myset.begin(),
myset.end(),30);
if (it1 != myset.end())
{
myset.erase(it1);
}
else
{
std::cout << "not find!" << std::endl;
}
}
| 删除方式 | 形式 | 含义 |
|---|---|---|
| 删除区间元素 | erase(first,last) | 删除first~last之间的元素 |
| 删除指定位置的元素 | erase(index) | 删除set上index上的元素 |
| 删除元素 | erase(val) | 删除元素val |
4、其他操作
我们来查看此容器的大小和key为15的元素个数,具体操作如下:
for (int i = 0; i < 50; i++)
{
set1.insert(rand() % 20 + 1);
}
cout << set1.size() << endl;
cout << set1.count(15) << endl;
结果如下:

虽然我们输入了50个数,因为是单重集合,所以其自动去除了重复的元素,且key为15的元素个数肯定也是1.
但是同样是上述代码的插入,如果我们将其改成了多重集合,定义如下:
multiset<int> set1;
输出结果如下:
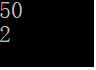
因为其存储key值是会重复的元素。所以50个元素全部都存储进去了,且key为15的元素个数就是相应重复的个数了。
2.2特点
不允许重复,即key关键字不允许重复,可以去重set元素不能在容器中修改,因为:元素用const修饰,修改过后不能自己调整红黑树。导致序列乱序。所以修改一个元素可以先删除再插入。set在插入元素时,会进行排序,默认按照红黑树中序遍历升序的方式排序, 所以 如果用set存储对象信息,需要在对象对应的类中提供比较方式,因为set在存储数据时,不知道怎么比较对象。基于关键字的快速查询。
应用一
题目要求:在10万整数中,在海量数据中查找重复的元素
分析:因为在此要求我们在海量数据中只是找到重复的元素值即可,所以采用set是一个非常好的方法,具体代码实现如下:
int main()
{
const int ARR_LEN = 100000;
int arr[ARR_LEN] = {
0 };
for (int i = 0; i < ARR_LEN; ++i)
{
arr[i] = rand() % 10000 + 1;
}
unordered_set<int> set;
for (int v : arr)//O(n)
{
set.insert(v);//O(1)
}
for (int v : set)
{
cout << v << " ";
}
cout << endl;
return 0;
}
应用二
set的简单使用
# include<iostream>
# include<deque>
# include<vector>
# include<list>
# include<algorithm>
# include<iterator>
# include<set>
template<typename Container>
void show(Container& con)
{
typename Container::iterator it = con.begin();
for (; it != con.end(); it++)
{
std::cout << *it << " ";
}
std::cout << std::endl;
}
int main()
{
std::set<int> myset1;//无参构造
int a[] = {
0,1,2,3,4,5,6,7 };
int len = sizeof(a) / sizeof(a[0]);
std::set<int> myset(a, a + len);//通过迭代器区间构造
//2.迭代器打印整型容器
show(myset);
//3.迭代器指向起始位置,将数组的元素插入2号下标,会去重,所以不会插入
myset.insert(a + 2, a + 5);
show(myset) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









