









参考文章:
推荐文章:SoftMax多分类器原理及代码理解
神经网络中的softmax层为何可以解决分类问题——softmax前世今生系列(3)
softmax函数的正推原理——softmax前世今生系列(1)
1、softmax模型原理
softmax函数如下,其中z是输入的预测数组,C是分类总数:
Softmax
(
z
i
)
=
e
z
i
∑
c
=
1
C
e
z
c
\operatorname{Softmax}\left(z_{i}\right)=\frac{e^{z_{i}}}{\sum_{c=1}^{C} e^{z_{c}}}
Softmax(zi)=∑c=1Cezcezi
Logistic模型只适合处理二分类问题,且在给出分类结果的同时还会给出结果的概率值。那么对于多分类问题,如果想要用类似的方法,输出分类结果的同时还给出概率,则可以使用softmax模型。
在logistic模型中, 训练集由 n 个已标记的样本构成:
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
n
,
y
n
)
}
,
其
中
y
i
∈
{
0
,
1
}
.
\left \{ (x_1,y_1), (x_2, y_2),...,(x_n, y_n)\right\}, 其中y_i\in\left\{0,1\right\}.
{(x1,y1),(x2,y2),...,(xn,yn)},其中yi∈{0,1}.
logistic模型公式如下:
h
(
x
)
=
1
1
+
e
−
θ
T
x
h(x)=\frac1{1+e^{-\theta^Tx}}
h(x)=1+e−θTx1
损失函数为:
J
(
θ
)
=
−
1
n
[
∑
i
=
1
n
y
i
log
(
h
θ
(
x
i
)
)
+
(
1
−
y
i
)
log
(
1
−
h
θ
(
x
i
)
)
]
J(\theta)=-\frac{1}{n}[\sum _{i=1}^n y_i\log(h_{\theta}(x_i))+(1-y_i)\log(1-h_{\theta}(x_i))]
J(θ)=−n1[i=1∑nyilog(hθ(xi))+(1−yi)log(1−hθ(xi))]
推广到多分类情形,对于给定的测试输入
x
x
x ,用假设函数针对每一个类别 j 估算出概率值
p
(
y
=
j
∣
x
)
p(y=j|x)
p(y=j∣x) ,即,估计
x
x
x 的每一种分类结果出现的概率。假设函数将要输出 一个
k
k
k 维的向量来表示这
k
k
k 个估计的概率值。假设函数
h
θ
(
x
)
h_{\theta}(x)
hθ(x)形式如下:
h
(
x
i
;
θ
)
=
[
p
(
y
i
=
1
∣
x
i
;
θ
)
p
(
y
i
=
2
∣
x
i
;
θ
)
.
.
.
p
(
y
i
=
k
∣
x
i
;
θ
)
]
=
1
∑
j
=
1
k
e
θ
j
T
x
i
[
e
θ
1
T
x
i
e
θ
2
T
x
i
.
.
.
e
θ
k
T
x
i
]
h(x_i;\theta)= \begin{bmatrix} p(y_i=1|x_i;\theta)\\ p(y_i=2|x_i;\theta)\\ ...\\ p(y_i=k|x_i;\theta)\\ \end{bmatrix} =\frac{1}{\sum^k_{j=1} e^{\theta^T_j x_i}} \begin{bmatrix} e^{\theta^T_1 x_i}\\ e^{\theta^T_2 x_i}\\ ...\\ e^{\theta^T_k x_i}\\ \end{bmatrix}
h(xi;θ)=⎣⎢⎢⎡p(yi=1∣xi;θ)p(yi=2∣xi;θ)...p(yi=k∣xi;θ)⎦⎥⎥⎤=∑j=1keθjTxi1⎣⎢⎢⎡eθ1Txieθ2Txi...eθkTxi⎦⎥⎥⎤
在Softmax回归中将
x
x
x 分类为类别
j
j
j 的概率为:
p
(
y
i
=
j
∣
x
i
;
θ
)
=
e
θ
j
T
x
i
∑
l
=
1
k
e
θ
l
T
x
i
p(y_i=j|x_i;\theta)=\frac{e^{\theta_j^Tx_i}}{\sum^k_{l=1}e^{\theta_l^Tx_i}}
p(yi=j∣xi;θ)=∑l=1keθlTxieθjTxi
其中分母部分
∑
j
=
1
k
e
j
n
\sum^k_{j=1}e^n_j
∑j=1kejn对概率分布进行了归一化,使所有概率之和等于1。
2、代价函数及求导过程
J
(
θ
)
=
−
1
m
[
∑
i
=
1
m
∑
j
=
1
k
I
(
y
i
=
j
)
log
e
θ
j
T
x
i
∑
l
=
1
k
e
θ
l
T
x
i
]
J(\theta)=-\frac{1}{m}[\sum^m_{i=1}\sum^k_{j=1}I(y_i=j)\log \frac{e^{\theta^T_j x_i}}{\sum^k_{l=1} e^{\theta^T_l x_i}}]
J(θ)=−m1[i=1∑mj=1∑kI(yi=j)log∑l=1keθlTxieθjTxi]
上述公式是logistic回归代价函数在多分类情形的推广 ,改为logistic形式为:
J
(
θ
)
=
−
1
m
[
∑
i
=
1
m
∑
j
=
0
1
I
(
y
i
=
j
)
log
p
(
y
i
=
j
∣
x
i
;
θ
)
]
J(\theta)=-\frac{1}{m}[\sum^m_{i=1}\sum^1_{j=0}I(y_i=j)\log p(y_i=j|x_i;\theta)]
J(θ)=−m1[i=1∑mj=0∑1I(yi=j)logp(yi=j∣xi;θ)]
优化上和logistic模型类似,使用梯度下降优化算法来最小化代价函数。
设参数为
w
w
w,损失函数对w的偏导数:
∂
J
(
w
)
∂
w
j
=
−
1
m
∑
i
=
1
m
[
x
i
(
I
(
y
i
=
j
)
−
p
(
y
i
=
j
∣
x
i
;
w
)
)
]
\frac{\partial J(w)}{\partial w_j}=-\frac{1}{m}\sum^m_{i=1} [x_i(I(y_i=j)-p(y_i=j|x_i;w))]
∂wj∂J(w)=−m1i=1∑m[xi(I(yi=j)−p(yi=j∣xi;w))]
公式求出的偏导数是一个向量,表示对第
j
j
j个类别而求得的,所以上面的公式求得的只是一个类别的偏导公式,最后还需要求出所有类别的偏导公式。使用上面的损失函数求出的参数并不是唯一的,解决方法是对上式加入正则项,加入正则项后的损失函数如下:
J
(
w
)
=
−
1
m
[
∑
i
=
1
m
∑
j
=
1
k
I
(
y
i
=
j
)
log
e
w
j
T
x
i
∑
l
=
1
k
e
w
l
T
x
i
]
+
λ
2
∑
i
=
1
k
∑
j
=
1
n
w
i
j
2
J(w)=-\frac{1}{m}[\sum^m_{i=1}\sum^k_{j=1}I(y_i=j)\log \frac{e^{w^T_j x_i}}{\sum^k_{l=1} e^{w^T_l x_i}}]+\frac{\lambda} 2\sum^k_{i=1}\sum ^n_{j=1}w_{ij}^2
J(w)=−m1[i=1∑mj=1∑kI(yi=j)log∑l=1kewlTxiewjTxi]+2λi=1∑kj=1∑nwij2
此时偏导公式如下:
∂
J
(
w
)
∂
w
j
=
−
1
m
∑
i
=
1
m
[
x
i
(
I
(
y
i
=
j
)
−
p
(
y
i
=
j
∣
x
i
;
w
)
)
]
+
λ
w
j
\frac{\partial J(w)}{\partial w_j}=-\frac{1}{m}\sum^m_{i=1} [x_i(I(y_i=j)-p(y_i=j|x_i;w))]+\lambda w_{j}
∂wj∂J(w)=−m1i=1∑m[xi(I(yi=j)−p(yi=j∣xi;w))]+λwj
通过上面的偏导数,采用梯度下降法对参数进行更新,就可以迭代求解最优参数了。
w
j
,
t
+
1
=
w
j
,
t
−
γ
∂
J
(
w
)
∂
w
j
w_{j,{t+1}}=w_{j,t}-\gamma \frac{\partial J(w)}{\partial w_j}
wj,t+1=wj,t−γ∂wj∂J(w)
经过多次迭代即可求得最优参数w。
3、例子
举个网上的例子,假设三个输入的值分别为3、1、-3,对应的指数函数值为20、2.7、0.05,再分别除以累加和得到最终的概率值,0.88、0.12、0。
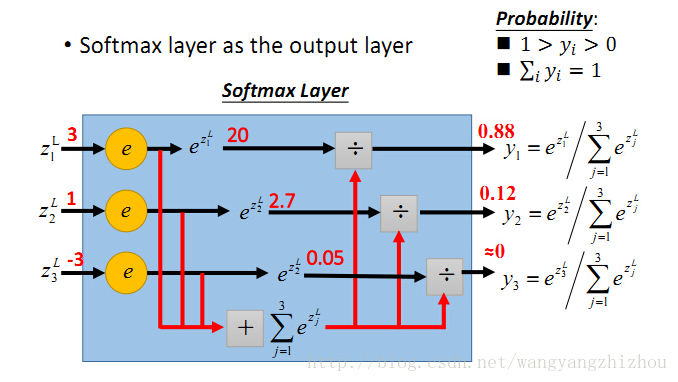
可以看到它有多个值,所有值加起来刚好等于1,每个输出都映射到了0到1区间,可以看成是概率问题。
在多分类场景中可以用softmax也可以用多个二分类器组合成多分类,比如多个逻辑分类器或SVM分类器等等。该使用softmax还是组合分类器,主要看分类的类别是否互斥,如果互斥则用softmax,如果不是互斥的则使用组合分类器。















 4317
4317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









