






学习利用python爬虫获取数据
一、获取requests模块

二、新建项目进行测试
- 导入模块
import requests
- 发送请求, 获取响应
response = requests.get('http://www.baidu.com')
目的是为了获取到百度网站首页的内容
print(response)
- 获取响应数据
print(response.encoding)
二进制编码形式的输出
print(response.text)
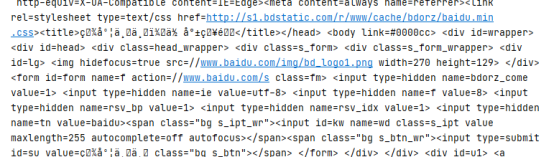
打开之后全是乱码,因为代码是ISO-8859-1
response.encoding = 'utf8'
Utf-8规定了输出的语言为汉语
但是每次都用text+utf8,把输出二进制码转为中文的命令比较麻烦,所以利用一个新的指令可以一步到位
print(response.content.decode())
直接得到中文
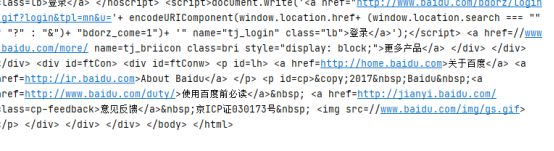
小结:
response.text : 响应体 str类型
response.ecoding : 二进制转换字符使用的编码
respones.content: 响应体 bytes类型
做一个案例:获取丁香园疫情首页的内容
丁香园的地址是https://ncov.dxy.cn/ncovh5/view/pneumonia
编码如下:
import requests
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia')
#print(response.text)
print(response.content.decode())
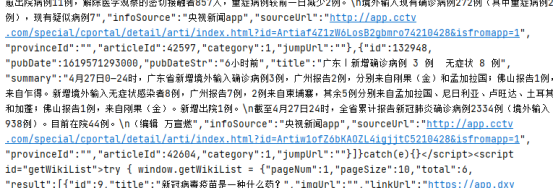
三、在获取到的数据中提取我们需要的内容
1.Beautiful Soup
这是一个可以从HTML或XML文件中提取数据的Python库
安装
安装 Beautiful Soup 4
pip install bs4
安装 lxml解析库
pip install lxml
BeautifulSoup对象: 代表要解析整个文档树,
它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法.
#1.导入模块
from bs4 import BeautifulSoup
#2.创建BeautifulSoup对象
soup = BeautifulSoup('<html>data</html>','lxml')←这里第二个参数是指定解析器lxml
print(soup)
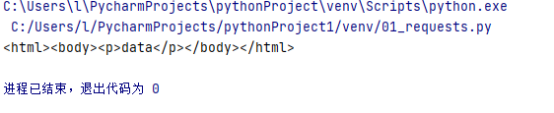
得到的结果会自动填充为正确格式
2.Find方法
作用是搜索文档树
Find方法中有四个标签,分别是name=None, attrs={}, recursive=True, text=None
以此为例

参数意义:
name: 标签名,指定之后查找特定标签
attrs: 属性字典,指定属性后可以找到对应标签
recursive: 是否递归循环查找,比如如果在上面的name指定title标签,然后recursive=false的话会找不到内容,因为上面的例子在html的子标签里只有head和body,没有title
一般默认值为true
text: 根据文本内容查找
返回值:查找到的第一个元素对象
如果想要所有对象,则需要find all
一个案例:
根据标签名查找
需求: 获取刚才文档中的 title 标签 和 a 标签
思路:
- 导入模块
from bs4 import BeautifulSoup
- 准备文档字符串
html = '''<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title">
<b>The Dormouse's story</b>
</p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
'''
- 创建BeautifulSoup对象
soup = BeautifulSoup(html, 'lxml')
- 查找title标签
title = soup.find('title')
print(title)
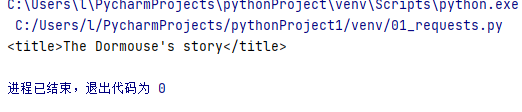
找到啦
- 查找a 标签
a = soup.find('a')
print(a)

查找所有的a标签
a_s = soup.find_all('a')
print(a_s)
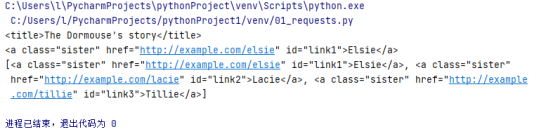
至此学会了使用标签名查找对象的方法















 4582
4582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









