







点击上方“LiveVideoStack”关注我们
在此次LiveVideoStackCon 2021 音视频技术大会 北京站,来自镕铭半导体的刘迅思详细列举了目前常用的AI辅助编解码的方法,论述如何在硬件和软件层面将AI结合编解码的实践,探索新的标准和新一代编码器结合AI应该如何设计。
文 | 刘迅思
整理 | LiveVideoStack
大家好,我是来自NETINT镕铭半导体的刘迅思,本次要跟大家分享的主题是视频编码器的智能化。
为什么要分享这个话题?直白的说主要的是为了带货,因为目前公司最新推出了基于带有AI功能的硬件ASIC编码器、编码卡,当然更重要的是我们觉得它也是未来视频编解码一个很重要的方向。
我知道来LiveVideoStackCon 音视频技术大会的老师,可能很多都是做AI算法、编码算法,或是应用开发的。作为一家芯片公司,打个比方,我们就有点像是“种菜”的,诸位老师就像是“大厨”,我一个“种菜”的和大家说种出来的菜能做成什么样的美食,很容易得到一些不信任的目光。说到这个也很有意思,前两天看到LVS的一位讲师的朋友圈,提到之前写PPT的时候非常谨慎,咨询很多专家,总是担心PPT内有什么错误,但现在却不像之前那样,为什么呢?他说,现在更欢迎听众来提出一些不同的意见。对我来说其实也是一样的,非常期待大家听完能有一些反馈给到我们。这其实也是公司三年以来在国内跟数据中心的客户合作的一种模式,因为客户很多都是业务方、应用方,我们会反馈给客户更多底层的信息,客户也同样反馈给我们很多应用端的信息,互相协作可以把事情做得很好。

本次分享的内容主要有以下几点:首先是我们理解的AI辅助编码在学术界研究的主要方向;其次是正在落地的商业化实践;还会基于以上内容,分享ASIC编码器在软硬件实现上有什么样的区别;接着会介绍ASIC编码器的优势场景;最后会跟大家探讨一下未来基于ASIC以及基于硬件的视频编解码器应该是什么样子。
1. 研究方向
首先,介绍学术界的一些研究方向。

总的来说,可分为两大类:一类是基于传统的,也就是264、265,基于残差,基于DCT变换来开发一些编码的工具,并且我们还会在每一个编码工具上基于神经网络来做一些优化;而另外一类,则是完全抛开这些工具,直接使用神经网络来做编解码的压缩。
1.1像素概率建模

第一种是像素概率建模。其原理是,它认为每一个像素点其实是可以根据上下文的一些像素的概率估算出来的,比如 ,当前像素值可以根据它之前
,当前像素值可以根据它之前 一直到
一直到 的这些值的概率,做一个联合概率,计算得出
的这些值的概率,做一个联合概率,计算得出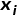 的值。比较著名的一些神经网络,如最早发布的PixelCNN和PixelRNN,这是两个不同的算子,用CNN和RNN来做像素概率建模,后续又有了Gated PixelCNN,或者叫conditional PixelCNN。
的值。比较著名的一些神经网络,如最早发布的PixelCNN和PixelRNN,这是两个不同的算子,用CNN和RNN来做像素概率建模,后续又有了Gated PixelCNN,或者叫conditional PixelCNN。
其实在做像素概率建模的时候需要一个掩模,它的原理是从之前的像素来推断出当前像素,这就意味着在计算时,需要将后续的像素点做掩模遮蔽掉,但在遮蔽的时候有可能会挡住之前一些像素点,造成一些盲点,Gated PixelCNN就是为了解决盲点的问题。说起来感觉可能比较复杂,这个算法其实是有比较常见的应用的,像大家可能用过一些APP是拍摄一张自己现在的照片,然后可以推算出当你七十岁时会长成什么样子,这就是用上述算法来实现的。它其实最早是用来做图像生成的,用于编解码时,之前看到有的p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









