






每周一期,纵览音视频技术领域的干货。
新闻投稿:contribute@livevideostack.com。
✦
一周简讯
✦
MPAI-MMC将被IEEE采纳为技术标准

在 MPAI Multimodal Conversation (MPAI-MMC) 获得批准满 6 个月的当天,IEEE 主持了 P3300 工作组的启动会议,任务是采用 MPAI 技术规范作为 IEEE 标准。早些时候,MPAI 和 IEEE 签署了一项协议,MPAI 授予 IEEE 将 MPAI-MMC 作为 IEEE 标准发布的权利。
Meta向“元宇宙”开发者抽成47.5% 比苹果30%还高

新浪科技讯 北京时间4月12日晚间消息,据报道,对于在其“元宇宙”中销售虚拟产品的开发者,Facebook母公司Meta将向他们收取高达47.5%的费用,远远高于苹果公司App Store应用商店向开发者收取的30%费用。
Google 将把 AI 写作内容视为垃圾信息从搜索结果中移除

OpenAI 的文本生成神经网络 GPT-3 被认为能产生以假乱真的文章,那么搜索引擎应该如何对待它生成的内容?据Search Engine Land报道,Google 的 Search Advocate John Mueller上周在一场搜索引擎优化(SEO)的线上对谈中,在被问到Google对提供AI自动生成的内容会如何反应时,他表示这类网站将被归类在自动生成内容的网站,意指这违反了Google的网站站长质量指南。根据Google的网站站长质量指南,系统在大多数情况下都会自动发现垃圾内容并将其从搜索结果中移除。为了确保索引质量,Google还会采取手动操作将垃圾内容从搜索结果中移除。
百度开源PP-Human项目
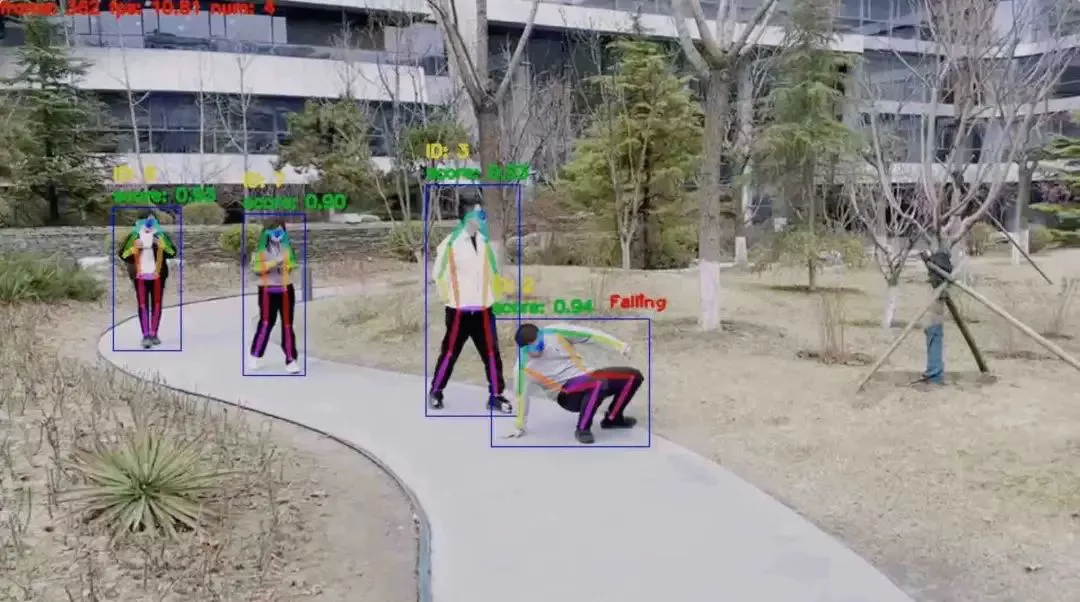
飞桨目标检测开发套件 PaddleDetection 中提供的 PP-Human 是一套综合了目标检测、跟踪、关键点检测等核心能力的产业级开源实时行人分析工具。它基于企业真实场景数据打磨优化,拥有人体属性识别、行为识别与流量计数三大能力,兼容单张图片、单路或多路视频 3 种输入类型,还可适应不同光线、复杂背景及跨镜头场景!不仅如此,PP-Human 还直接提供目标检测、属性分析、关键点检测、行为识别、ReID 预训练模型,方便开发者灵活取用及更改。PP-Human 项目传送门:https://github.com/PaddlePaddle/PaddleDetection。记得收藏,防止走丢又实时关注更新。
TikTok向所有用户开放AR特效工具
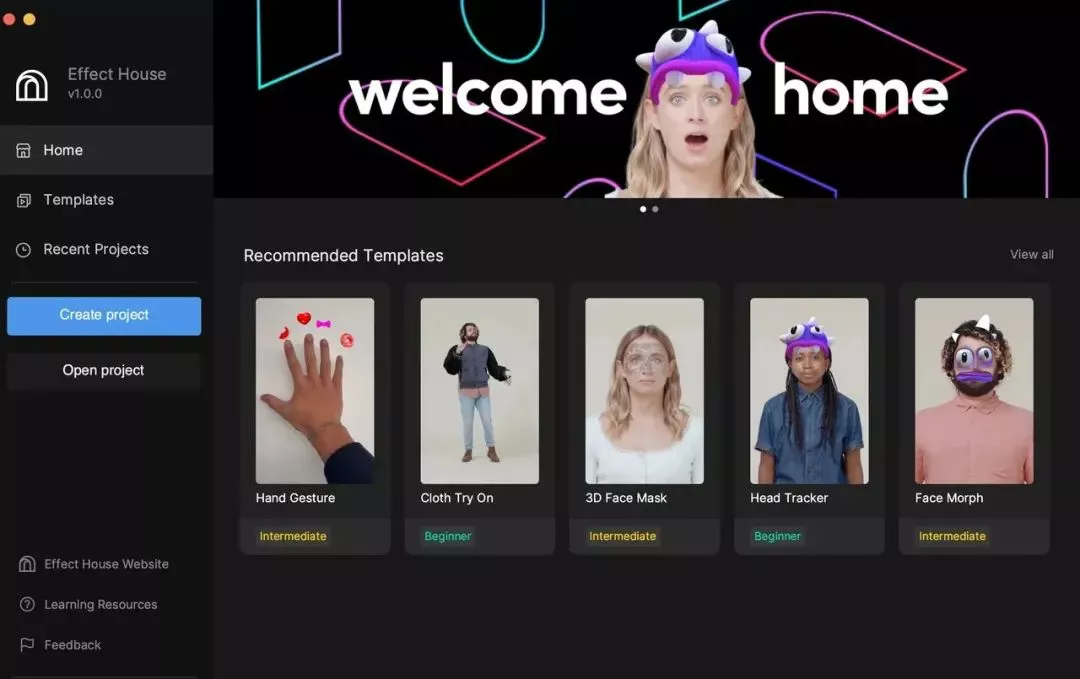
TikTok正式向所有创作者和开发者推出AR效果工具。Effect House允许创作者制作自己的AR相机特效,让其他TikTok用户在视频中使用。该公司在一份声明中表示,该特效平台包括工具和学习资源,将向“世界各地的所有创造者、设计师和开发人员开放”。该公司讲道:“无论是用绿屏抠像把自己传送到一个新的世界,还是用时空扭曲扫描滤镜定格画面,这些抖音创意效果都能让创作者通过各种引人入胜的、沉浸式形式来表达、娱乐和分享故事。”TikTok公司表示,特效提交后需要经过审核才能使用。该公司明确表示将禁止“发布肤色歧视或其他负面刻板印象内容”的特效,以及“描绘如唇部填充等整容手术,或鼓励审视外貌”的特效。
✦
✦
✦
超级干货
✦
今天给大家分享一下关于音视频中的黑屏、花屏、绿屏问题,这也是各大微信群里经常问的问题,这次争取将他们一网打尽,彻底解决了。
音视频开发之旅(五)MediaExtractor MediaMuxer 实现视频的解封装与合成
本文首先介绍了MediaExtractor MediaMuxer 能做什么,然后对视频解封装和合成的API以及流程进行了介绍,最后分享了三个实践实例,以及遇到的问题等。
在知识星球里面有位 PM 同学,咨询关于音视频里面的解码帧率和渲染帧率,关于这两个概念其实挺绕的,不同的人可能还有不同的看法,所以也让大家一起来评估一下解读是否正确!
iOS AVDemo(8):视频编码,H.264 和 H.265 都支持丨音视频工程示例
FFmpeg命令分析-1
本系列主要分析各种 FFmpeg 命令 在代码里是如何实现的。本文分析 FFmpeg 简单裁剪翻转滤镜命令 在代码里是如何实现的。
https://juejin.cn/post/7052348505280479239
本文主要讲解了基本的语音学研究范围,对基本的语音特征进行了简单的介绍,最后对语音信号处理技术的应用进行了相关介绍。
本文记录了第一个基于CNN卷积神经网络在图像识别领域的应用:猫狗图像识别。主要内容包含:数据创建和预处理、神经网络模型搭建、数据增强实现减小正则化。
一文彻底搞懂自动机器学习AutoML:Auto-Sklearn
本文将系统全面的介绍自动机器学习的其中一个常用框架: Auto-Sklearn,介绍安装及使用,分类和回归小案例,以及一些用户手册的介绍。
本章首先介绍了熵编码和熵解码算法的基本原理,并给出其在HEVC标准中的基本流程。然后对熵编码和熵解码的相关子模块进行VLSI设计,得出设计结果与对比。
英国赫特福德大学与 GBG Plc 的研究者近日发布了一篇综述论文,对人脸识别方法进行了全面的梳理和总结,其中涵盖各种传统方法和如今风头正盛的深度学习方法。
OpenCV是功能强大的计算机视觉库,具有强大的图像处理工具包。在本文中,我们将利用它来创建绘图和绘画,其中大多数将使用内置功能!让我们简短介绍一下,直接进入令人兴奋的实操环节。
现代相机拍摄的图像会因噪声而退化,图像中的噪声是图像中颜色信息的失真,当在夜间拍摄时,图像变得更嘈杂。该案例研究试图建立一个预测模型,该模型将带噪图像作为输入并输出去噪后的图像。
今天给大家介绍一下直方图,无论是相机的直方图还是后期软件中的直方图都是大同小异的,所以不用去分什么相机中的直方图还是后期软件中的直方图。
数据增强也叫数据扩增,意思是在不实质性的增加数据的情况下,让有限的数据产生等价于更多数据的价值。
✦
✦
✦
科技前沿
✦
北京2022冬奥会不仅向观众展示了运动员的体育才能,而且向世界展示了它的技术创新。我们将在下文了解支持了本届奥运会的下一代网络连接、技术能力以及数字化生态系统。
专治各种噩梦级抠图!魏茨曼联合英伟达发布Text2LIVE,用自然语言就能PS
还在为PS的各种命令、工具头疼吗?魏茨曼联合英伟达发布了一个新模型Text2LIVE,只需用自然语言就能轻松完成各种抠图、贴图,图像和视频都能用!
港大火星实验室最新工作:用于精确实时3D SLAM的高效概率自适应体素地图
成果速览 | 首个基于FPGA的4K超高清端到端智能视频压缩系统
视频也可以用扩散模型来生成了,效果很能打:新SOTA已达成 | 谷歌
斯坦福学生攻破两个约会软件!用GAN模型「女扮男装」骗过人脸识别系统
人脸识别技术最近又有新的破解方式!一位斯坦福的学生使用GAN模型生成了几张自己的图片,轻松攻破两个约会软件,最离谱的是「女扮男装」都识别不出来。
德国研究人员认为:人看的是形状,计算机看的是纹理。这一发现相当有趣,但它证明计算机算法离人类视觉还有很远距离。
CVPR 2022 | 利用递归 “瞥视” 解码器优化基于Transformer的目标检测算法
✦
✦
✦
推荐阅读
✦
最近几年,随着各类音视频应用的爆火,处理音视频所需的算力也急剧增长。同时音视频对延迟也有很高的要求。那么如何才能满足“高算力,低延迟”这一迫切需求,又能帮助企业降低成本?边缘计算提供了绝佳的选择!
盘点来自工业界的GPU共享方案
近年来工业界一直孜孜不倦地寻求提升GPU利用率的方案,能被更多用户理解和使用的GPU共享走进工程师的视野中。本文将总结目前有公开PR的、来自工业界的部分GPU容器计算共享方案,看看工业界对GPU共享的定位和需求。
https://zhuanlan.zhihu.com/p/398369404
上个世纪50年代中期,爱折腾的美国摄影师 Morton Heilig 发明了第一台VR设备:Sensorama (1962年提交专利)。这台设备被一些人认为是 VR 设备的鼻祖。
到了90年代,随着市场的热捧,VR眼镜迎来了第一次热潮,2012 VR热潮重启,2016年,VR新元年正式开始。
近日,国外社交媒体 Instagram 上流传着一个视频,在视频中,有交警发现了一辆汽车在傍晚时前灯并未亮起,随后便下车查看,发现汽车驾驶位并没有人,就在交警转身走向警车时,这辆汽车试图“逃”走。
CVPR 2022|快手&中科院开源StyTr^2:基于Transformer的图像风格化方法
本文提出了一种基于 Transformer 的图像风格迁移方法,我们希望该方法能推进图像风格化的前沿研究以及 Transformer 在视觉尤其是图像生成领域的应用。
AR是一把开启未来的钥匙,率先打开的也许会是创意节目的大门。目前许多节目都在通过融入AR技术,来营造一种耳目一新的视觉体验。今天我们就一起来看看那些令人惊艳的AR节目。
内嵌6块摄像头,Meta XR头显Project Cambria高清细节图曝光
✦
✦
活动推荐

【城市沙龙】LiveVideoStack Meet深圳:元宇宙与音视频
去年底,元宇宙一词入选了《柯林斯词典》2021年度热词,虽然外界对于元宇宙概念和属性的看法仍在变化,但对其未来的良好前景已基本达成共识。元宇宙又会给音视频互动带来哪些新玩法与新场景?4月23日LiveVideoStack Meet将在深圳与大家见面,共聊元宇宙与音视频发展!
活动时间:2022年4月23日 14:00-17:00
活动地点:深圳市南山区卓越前海壹号T3写字楼38层培训室
报名方式:点击「阅读原文」立即报名。

















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









