







File构造函数的建立和分隔符的应用
File类用来将文件或者文件夹封装成对象,方便对文件和文件夹中的属性进行操作。
File file=new File("a.txt");可以将一个文件封装成File对象,文件名为a.txt,如果文件不存在则创建一个文件。
File file2=new File("c:\\","a.txt"),在指定目录下创建一个文件对象
File cPan=new File("c:\\");File file3=new File(cPan,"a.txt");可以将指定路径封装成文件对象操作与file2
对象不同的是可以使用文件的方法操作cPan,而file2中构造函数中的参数是固定的字符串。
字段:
public static final char separatorChar:与系统有关的默认名称分隔符。
此字段被初始化为包含系统属性 file.separator 值的第一个字符。在 UNIX 系统上,此字段的值为 '/';
在 Microsoft Windows 系统上,它为 '\\'。
例如:File file3=new File("c:\\abc\\a.txt");在windows中可以正常运行,但是在linux下不能编译,因为linux中的文件分隔符号是\
所以为了兼容不同平台的文件分隔符号应File file3=new File("c:"+File.separator+"abc"+File.separator+"a.txt");
常见功能:
1 。获取:
File file=new File("a.txt");
获取文件名称:file.getName();==>a.txt
获取文件的绝对路径:file.getAbsolutePath();==>E:\workspace\IODemo\a.txt
获取文件的相对路径:file.getPath();==>a.txt
获取文件的最后修改时间:long time=file.lastModified();
获取文件的长度:long length=file.getlength();
获取文件的父文件目录:File parentFile=file.getParent();如果该文件是相对路径创建的则返回null
获取文件的父文件对象:file.getParentFile();
获取当前目录下的文件文件夹以及隐藏文件:String []fileNames=file.list();
注意:调用list方法的File对象中封装的必须是文件目录,否则会发生空指针异常
2。文件的创建和删除:
文件的创建:boolean file.createNewFile();如果文件不存在则创建,存在则不创建
文件的删除:boolean file.delete();如果当前文件是文件夹而且文件夹下面只有子文件,则删除失败
如果是多级目录则只会删除最后一个文件
boolean file.deleteOnExit(); 在虚拟机终止时,请求删除此抽象路径名表示的文件或目录
文件夹的创建: boolean file.mkdir();会创建一个文件夹
boolean file.mkdirs();创建多级目录
3。文件的判断:
判断文件是否存在:boolean file.exists();
判断是否是文件:boolean file.isFile();
判断是否是目录:boolean file.isDirectory();
重命名文件:boolean renameTo(File file);
获取系统的根目录:File[] file=File.listRoots();
获取指定目下的指定文件
File file=new File("C:\\Windows");
String[] fileNames=file.list(new FilenameFilter(){
@Override
public boolean accept(File dir, String name) {
return name.endsWith(".exe");//如果文件以.exe文件结尾则返回
}
});
for (String fileName : fileNames) {
System.out.println(fileName);
}
FilenameFilter:文件过滤器
返回一个字符串数组,这些字符串指定此抽象路径名表示的目录中满足指定过滤器的文件和目录。除了返回数组中的字符串必须满足过滤器外,此方法的行为与 list() 方法相同。如果给定 filter 为 null,则接受所有名称。否则,当且仅当在此抽象路径名及其表示的目录中的文件名或目录名上调用过滤器的 FilenameFilter.accept(java.io.File, java.lang.String) 方法返回 true 时,该名称才满足过滤器。
深度遍历文件夹
将指定的目录中的文件全部遍历。包括子目录
删除一个带内容的目录:
原理:必须从最里面往外删除,需要遍历所有的文件
File[] files=dir.listFiles();
for (File file : files) {
if(file.isDirectory()){
removeDir(file);
}else{
System.out.println(file+":"+file.delete());
}
}
System.out.println(dir+":"+dir.delete());
代码分析:如果需要删除整个文件夹,文件夹中中没有文件的话可以使用dir.delete()方法删除,但是如果文件夹中存在文件则删除不了需要先将文件夹中的文件删除,这时需要遍历该文件夹。在遍历的过程中判断是否是目录,如果是目录的话则使用递归继续遍历该目录,如果遍历出来的是文件,则使用file.delete()方法删除该文件。当遍历结束后剩下的全是空的文件夹。再使用dir.delete()则可以删除掉空的文件夹。
Properties对象的使用:
Properties对象是Map框架中的Hashtable中的一个子类,该类可以和IO技术像关联使用,通常用在项目的配置文件中读取键值对的数据,表示一个持久的属性集,可以保存在流中,可以在流中加载,存储的键值对都是字符串。
方法:
p.setProperty(String key,String value):该方法可以向配置文件中存如一对数据,底层是调用了Hashtable的put方法
p.getProperty(String key);:该方法可以获取对应键的值
Set<String> p.stringPropertyNames();该方法获取配置文件中的键集
props.store(OutputStream, "注释");将键值对信息以字符流的形式存储到文件中
OutputStream outputStream=new FileOutputStream("info.ini");
props.store(outputStream, "key=Name,value=Age");
outputStream.close();
打印流:
PrintWriter和PrintStream
PrintStream 为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。它还提供其他两项功能。与其他输出流不同,PrintStream 永远不会抛出 IOException;而是,异常情况仅设置可通过 checkError 方法测试的内部标志。另外,为了自动刷新,可以创建一个 PrintStream;这意味着可在写入 byte 数组之后自动调用 flush 方法,可调用其中一个 println 方法,或写入一个换行符或字节 ('\n')。 PrintStream 打印的所有字符都使用平台的默认字符编码转换为字节。在需要写入字符而不是写入字节的情况下,应该使用 PrintWriter 类。
构造函数接收3种类型的值
1,字符串路径
2,File对象
3,字节输出流
PrintWriter可以向文本输出流打印对象的格式化表示形式
BufferedReader bufferedReader=new BufferedReader(new InputStreamReader(System.in));
PrintWriter out=new PrintWriter(new File("C:\\a.txt"));
String line=null;
while((line=bufferedReader.readLine())!=null){
out.println(line);
out.flush();
if("stop".equals(line))
break;
}
out.close();
bufferedReader.close();
File类用来将文件或者文件夹封装成对象,方便对文件和文件夹中的属性进行操作。
File file=new File("a.txt");可以将一个文件封装成File对象,文件名为a.txt,如果文件不存在则创建一个文件。
File file2=new File("c:\\","a.txt"),在指定目录下创建一个文件对象
File cPan=new File("c:\\");File file3=new File(cPan,"a.txt");可以将指定路径封装成文件对象操作与file2
对象不同的是可以使用文件的方法操作cPan,而file2中构造函数中的参数是固定的字符串。
字段:
public static final char separatorChar:与系统有关的默认名称分隔符。
此字段被初始化为包含系统属性 file.separator 值的第一个字符。在 UNIX 系统上,此字段的值为 '/';
在 Microsoft Windows 系统上,它为 '\\'。
例如:File file3=new File("c:\\abc\\a.txt");在windows中可以正常运行,但是在linux下不能编译,因为linux中的文件分隔符号是\
所以为了兼容不同平台的文件分隔符号应File file3=new File("c:"+File.separator+"abc"+File.separator+"a.txt");
常见功能:
1 。获取:
File file=new File("a.txt");
获取文件名称:file.getName();==>a.txt
获取文件的绝对路径:file.getAbsolutePath();==>E:\workspace\IODemo\a.txt
获取文件的相对路径:file.getPath();==>a.txt
获取文件的最后修改时间:long time=file.lastModified();
获取文件的长度:long length=file.getlength();
获取文件的父文件目录:File parentFile=file.getParent();如果该文件是相对路径创建的则返回null
获取文件的父文件对象:file.getParentFile();
获取当前目录下的文件文件夹以及隐藏文件:String []fileNames=file.list();
注意:调用list方法的File对象中封装的必须是文件目录,否则会发生空指针异常
2。文件的创建和删除:
文件的创建:boolean file.createNewFile();如果文件不存在则创建,存在则不创建
文件的删除:boolean file.delete();如果当前文件是文件夹而且文件夹下面只有子文件,则删除失败
如果是多级目录则只会删除最后一个文件
boolean file.deleteOnExit(); 在虚拟机终止时,请求删除此抽象路径名表示的文件或目录
文件夹的创建: boolean file.mkdir();会创建一个文件夹
boolean file.mkdirs();创建多级目录
3。文件的判断:
判断文件是否存在:boolean file.exists();
判断是否是文件:boolean file.isFile();
判断是否是目录:boolean file.isDirectory();
重命名文件:boolean renameTo(File file);
获取系统的根目录:File[] file=File.listRoots();
获取指定目下的指定文件
File file=new File("C:\\Windows");
String[] fileNames=file.list(new FilenameFilter(){
@Override
public boolean accept(File dir, String name) {
return name.endsWith(".exe");//如果文件以.exe文件结尾则返回
}
});
for (String fileName : fileNames) {
System.out.println(fileName);
}
FilenameFilter:文件过滤器
返回一个字符串数组,这些字符串指定此抽象路径名表示的目录中满足指定过滤器的文件和目录。除了返回数组中的字符串必须满足过滤器外,此方法的行为与 list() 方法相同。如果给定 filter 为 null,则接受所有名称。否则,当且仅当在此抽象路径名及其表示的目录中的文件名或目录名上调用过滤器的 FilenameFilter.accept(java.io.File, java.lang.String) 方法返回 true 时,该名称才满足过滤器。
深度遍历文件夹
将指定的目录中的文件全部遍历。包括子目录
private static void walkFile(String prefix, File dir) {
System.out.println(prefix+"/"+dir);
//获取指定目录下所有的文件夹或者文件对象
File[]files=dir.listFiles();
for (File file : files) {
if(file.isDirectory()){//判断该文件对象是否是文件夹,如果是则递归继续判断
walkFile(prefix+"....",file);
}else{//如果是文件则直接打印
System.out.println(prefix+"/"+file);
}
}
}删除一个带内容的目录:
原理:必须从最里面往外删除,需要遍历所有的文件
File[] files=dir.listFiles();
for (File file : files) {
if(file.isDirectory()){
removeDir(file);
}else{
System.out.println(file+":"+file.delete());
}
}
System.out.println(dir+":"+dir.delete());
代码分析:如果需要删除整个文件夹,文件夹中中没有文件的话可以使用dir.delete()方法删除,但是如果文件夹中存在文件则删除不了需要先将文件夹中的文件删除,这时需要遍历该文件夹。在遍历的过程中判断是否是目录,如果是目录的话则使用递归继续遍历该目录,如果遍历出来的是文件,则使用file.delete()方法删除该文件。当遍历结束后剩下的全是空的文件夹。再使用dir.delete()则可以删除掉空的文件夹。
Properties对象的使用:
Properties对象是Map框架中的Hashtable中的一个子类,该类可以和IO技术像关联使用,通常用在项目的配置文件中读取键值对的数据,表示一个持久的属性集,可以保存在流中,可以在流中加载,存储的键值对都是字符串。
方法:
p.setProperty(String key,String value):该方法可以向配置文件中存如一对数据,底层是调用了Hashtable的put方法
p.getProperty(String key);:该方法可以获取对应键的值
Set<String> p.stringPropertyNames();该方法获取配置文件中的键集
props.store(OutputStream, "注释");将键值对信息以字符流的形式存储到文件中
OutputStream outputStream=new FileOutputStream("info.ini");
props.store(outputStream, "key=Name,value=Age");
outputStream.close();
FileInputStream inStream = null;
try {
// 获取配置文件的路径
String filePath = BeanFactory.class.getClassLoader().getResource("info.properties").getPath();
inStream = new FileInputStream(filePath);
// 加载到配置文件
properties.load(inStream);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
if (inStream != null) {
try {
inStream.close();// 关闭流
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
从指定目录中将所有的.java文件所在的目录信息写入到一个文本文件中
public class FileDemo4 {
/**
* @param args
*/
public static void main(String[] args) {
String url = "E:\\workspace";
File dir = new File(url);
List<File> list = new ArrayList<File>();
listFile(dir, new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
return name.endsWith("xml");// 过滤出所有的xml文件
}
}, list);
File destFile = new File("file.txt");
write2File(list, destFile);
}
private static void write2File(List<File> list, File destFile) {
BufferedWriter bufferedWriter = null;
try {
// 创建一个带缓冲区的字符写入流对象和将要写入的文件相关联
bufferedWriter = new BufferedWriter(new FileWriter(destFile));
int index = 1;
for (File file : list) {
// 将文件的文件名称和绝对路径写入到指定文件中
bufferedWriter.write(index++ + ":" + file.getName() + "---------" + file.getAbsolutePath());
bufferedWriter.newLine();// 每写一次空一行
bufferedWriter.flush();
}
} catch (Exception e) {
throw new RuntimeException("文件写入失败");
} finally {
if (bufferedWriter != null) {
try {
bufferedWriter.close();
} catch (IOException e) {
throw new RuntimeException("关闭流失败");
}
}
}
}
/**
* 遍历指定的文件
*
* @param dir
* 要遍历的目录
* @param filter
* 文件名称过滤器
* @param list
* 将符合条件的文件名存储到list
*/
private static void listFile(File dir, FilenameFilter filter, List<File> list) {
File[] files = dir.listFiles();// 遍历指定目录中的所有文件
for (File file : files) {
if (file.isDirectory()) {// 如果是目录则递归继续遍历
listFile(file, filter, list);
} else {
if (filter.accept(dir, file.getName())) {
list.add(file);// 将所有的符合条件的文件添加到集合中
}
}
}
}
}打印流:
PrintWriter和PrintStream
PrintStream 为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。它还提供其他两项功能。与其他输出流不同,PrintStream 永远不会抛出 IOException;而是,异常情况仅设置可通过 checkError 方法测试的内部标志。另外,为了自动刷新,可以创建一个 PrintStream;这意味着可在写入 byte 数组之后自动调用 flush 方法,可调用其中一个 println 方法,或写入一个换行符或字节 ('\n')。 PrintStream 打印的所有字符都使用平台的默认字符编码转换为字节。在需要写入字符而不是写入字节的情况下,应该使用 PrintWriter 类。
构造函数接收3种类型的值
1,字符串路径
2,File对象
3,字节输出流
PrintWriter可以向文本输出流打印对象的格式化表示形式
BufferedReader bufferedReader=new BufferedReader(new InputStreamReader(System.in));
PrintWriter out=new PrintWriter(new File("C:\\a.txt"));
String line=null;
while((line=bufferedReader.readLine())!=null){
out.println(line);
out.flush();
if("stop".equals(line))
break;
}
out.close();
bufferedReader.close();
序列流
SequenceInputStream 对多个流进行合并SequenceInputStream 表示其他输入流的逻辑串联。它从输入流的有序集合开始,并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止。
将3个文件中的数据整合到一个文件中
SequenceInputStream 对多个流进行合并SequenceInputStream 表示其他输入流的逻辑串联。它从输入流的有序集合开始,并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止。
将3个文件中的数据整合到一个文件中
package com.tan.filedemo;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.SequenceInputStream;
import java.util.Vector;
public class SequenceInputStreamDemo {
/**
* @param args
* @throws FileNotFoundException
*/
public static void main(String[] args) throws FileNotFoundException {
Vector<InputStream> vector=new Vector<InputStream>();
vector.add(new FileInputStream(new File("c:\\1.txt")));
vector.add(new FileInputStream(new File("c:\\2.txt")));
vector.add(new FileInputStream(new File("c:\\3.txt")));
File file=new File("c:\\all.txt");
megreFile(vector,file);
}
/**
* 合并文件中的数据
* @param vector 存储文件流的集合
* @param file 输出到文件对象
*/
private static void megreFile(Vector<InputStream> vector, File file) {
SequenceInputStream sequenceInputStream=null;
FileOutputStream fileOutputStream=null;
try {
//创建序列流对象,将集合中的元素按照枚举给定参数
sequenceInputStream=new SequenceInputStream(vector.elements());
//创建文件输出流对象
fileOutputStream=new FileOutputStream(file);
int length=0;
byte[]buffer=new byte[1024];
while((length=sequenceInputStream.read(buffer))!=-1){
fileOutputStream.write(buffer, 0, length);
}
} catch (Exception e) {
throw new RuntimeException("文件合并失败");
}finally{
if(fileOutputStream!=null){
try {
fileOutputStream.close();
}catch(Exception e){
throw new RuntimeException("关闭文件输出流失败");
}finally{
try {
sequenceInputStream.close();
} catch (IOException e) {
throw new RuntimeException("关闭合并流失败");
}
}
}
}
}
}
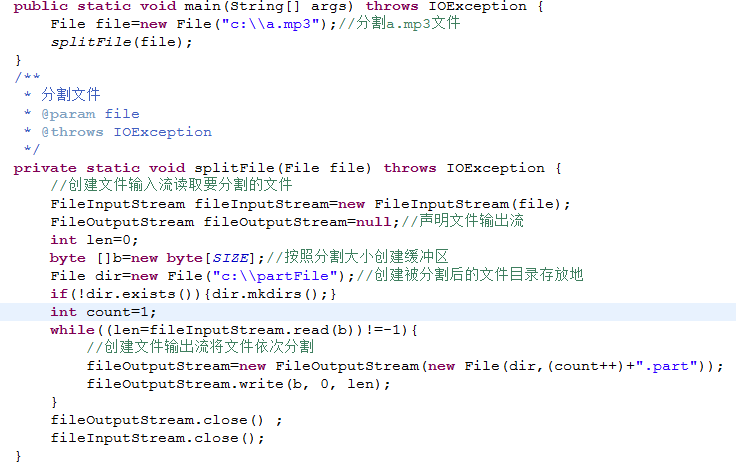 分割后的文件
分割后的文件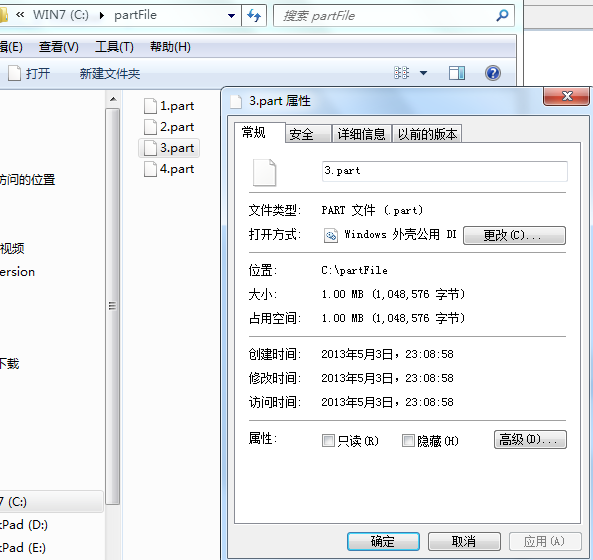
对象的序列化
将多个数据封装成对象,将对象用流的方式写入到可存储设备中叫做对象的持久化
ObjectOutputStream objectOutputStream=new ObjectOutputStream(new FileOutputStream("obj.object"));
objectOutputStream.writeObject(new Person());
objectOutputStream.close();
使用ObjectOutputStream的writeObject(obj)方法可以将堆内存中的对象obj的生命周期延长,通过使用文件输入输出流写入到文件中永久保存,下次使用该对象直接使用 其中obj对象必须实现了Serializable接口。持久化到文件中的对象按照字节的方式写入。对象的默认序列化机制写入的内容是:对象的类,类签名,以及非瞬态和非静态字段的值。
其他对象的引用(瞬态和静态字段除外)也会导致写入那些对象。可使用引用共享机制对单个对象的多个引用进行编码, 这样即可将对象的图形恢复为最初写入它们时的形状。当 OutputStream 中出现问题或者遇到不应序列化的类时将抛出异常NotSerializableException 。
对象的反序列化
ObjectInputStream inputStream=new ObjectInputStream(new FileInputStream("obj.object"));
Person p=(Person)inputStream.readObject();
System.out.println(p.getName()+":"+p.getAge());
ObjectInputStream 对以前使用 ObjectOutputStream 写入的基本数据和对象进行反序列化。 ObjectOutputStream 和 ObjectInputStream 分别与 FileOutputStream 和 FileInputStream 一起使用时, 可以为应用程序提供对对象图形的持久存储。ObjectInputStream 用于恢复那些以前序列化的对象。 其他用途包括使用套接字流在主机之间传递对象,或者用于编组和解组远程通信系统中的实参和形参。
ObjectOutputStream objectOutputStream=new ObjectOutputStream(new FileOutputStream("obj.object"));
objectOutputStream.writeObject(new Person());
objectOutputStream.close();
使用ObjectOutputStream的writeObject(obj)方法可以将堆内存中的对象obj的生命周期延长,通过使用文件输入输出流写入到文件中永久保存,下次使用该对象直接使用 其中obj对象必须实现了Serializable接口。持久化到文件中的对象按照字节的方式写入。对象的默认序列化机制写入的内容是:对象的类,类签名,以及非瞬态和非静态字段的值。
其他对象的引用(瞬态和静态字段除外)也会导致写入那些对象。可使用引用共享机制对单个对象的多个引用进行编码, 这样即可将对象的图形恢复为最初写入它们时的形状。当 OutputStream 中出现问题或者遇到不应序列化的类时将抛出异常NotSerializableException 。
对象的反序列化
ObjectInputStream inputStream=new ObjectInputStream(new FileInputStream("obj.object"));
Person p=(Person)inputStream.readObject();
System.out.println(p.getName()+":"+p.getAge());
ObjectInputStream 对以前使用 ObjectOutputStream 写入的基本数据和对象进行反序列化。 ObjectOutputStream 和 ObjectInputStream 分别与 FileOutputStream 和 FileInputStream 一起使用时, 可以为应用程序提供对对象图形的持久存储。ObjectInputStream 用于恢复那些以前序列化的对象。 其他用途包括使用套接字流在主机之间传递对象,或者用于编组和解组远程通信系统中的实参和形参。
Serializable接口:
Serializable作为一个标记接口主要是为类添加一个serialVersionUID用于判断类和对象是否是同一版本序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。如果接收者加载的该对象的类的 serialVersionUID与对应的发送者的类的版本号不同,则反序列化将会导致 InvalidClassException。
Serializable作为一个标记接口主要是为类添加一个serialVersionUID用于判断类和对象是否是同一版本序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。如果接收者加载的该对象的类的 serialVersionUID与对应的发送者的类的版本号不同,则反序列化将会导致 InvalidClassException。















 3213
3213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









