






1. 什么是快速排序
快速排序(QuickSort)是一种常用的排序算法,是从冒泡算法演变而来的,该算法通过将待排序的序列分割成较小和较大的两个子序列,并递归地对子序列进行排序,最终实现整个序列的排序。
2. 快速排序的原理
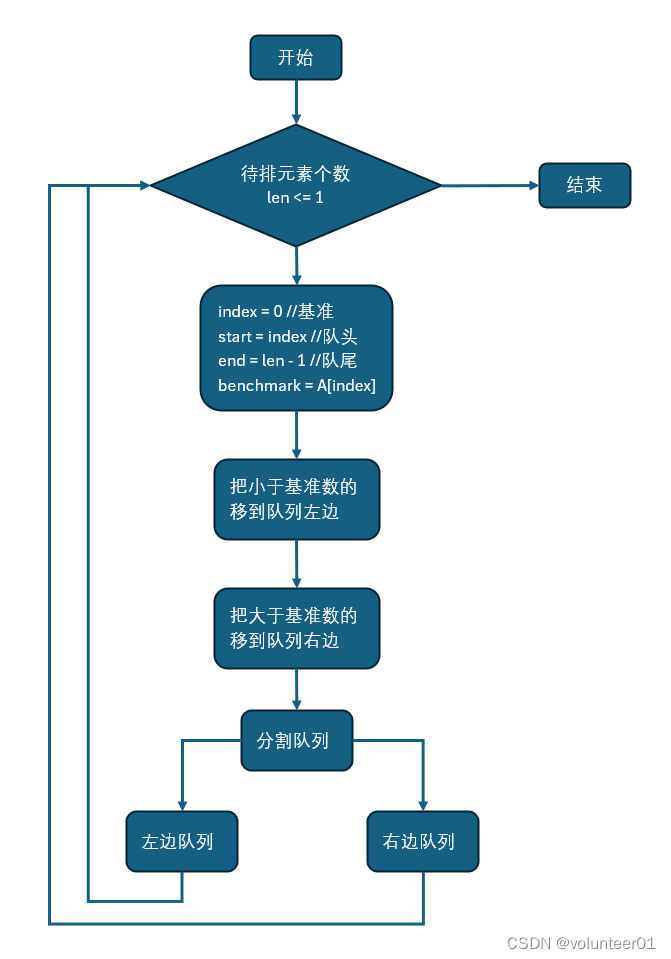
下面是快速排序的基本思想和步骤:
- 选择一个基准元素:从待排序序列中选择一个元素作为基准(通常选择第一个或最后一个元素)。
- 分割操作:通过重新排列序列,将比基准元素小的元素放在基准元素的左边,比基准元素大的元素放在基准元素的右边。同时,基准元素所在的位置也确定了它的最终排序位置。这个过程称为分割操作(Partition)。
- 递归排序:对基准元素左边的子序列和右边的子序列分别进行快速排序。递归地重复这个过程,直到子序列的长度为1或0,此时序列已经有序。
快速排序的关键在于分割操作,它可以通过不断交换元素的位置,将比基准元素小的元素移到基准元素的左边,比基准元素大的元素移到基准元素的右边。
3. 快速排序流程图
4. 时间空间复杂度
快速排序的时间复杂度取决于分割操作的效果。在最好情况下,每次分割操作都将序列均匀地分成两个子序列,时间复杂度为O(nlogn)。在最坏情况下,每次分割操作只能将序列分成一个子序列和一个空序列,时间复杂度为O(n^2)。平均情况下,快速排序的时间复杂度为O(nlogn)。
快速排序是一种原地排序算法,它不需要额外的存储空间来存储临时数据,只需要用到递归调用的栈空间。因此,快速排序的空间复杂度为O(logn)。
5. C语言实现
static void quick_sort(unsigned int *array, int len)
{
int start, end, index;
unsigned int benchmark;
if (len <= 1 || array == NULL)
return;
index = 0;
start = index;
benchmark = array[index];
do
{
for (end = len - 1; end > start; end--)
{
if (array[end] < benchmark)
{
array[start] = array[end];
break;
}
}
for (start = index; start < end; start++)
{
if (array[start] > benchmark)
{
array[end] = array[start];
break;
}
}
} while (start < end);
array[start] = benchmark;
if (start > 0)
quick_sort(array, start);
if (len > start + 1)
quick_sort(array + start + 1, len - start - 1);
}
6. 应用场景
快速排序在实际应用中有广泛的应用场景。由于其高效的平均时间复杂度和较低的空间复杂度,它被认为是一种很好的排序算法选择。以下是一些应用场景:
-
通用排序算法:快速排序是一种通用的排序算法,适用于各种数据类型和数据规模。它可以对数字、字符串、对象等进行排序,因此在需要对各种类型的数据进行排序的场景中都可以使用。
-
大数据排序:快速排序的时间复杂度为O(nlogn),在处理大规模数据集时表现良好。它可以高效地对大量数据进行排序,因此在大数据处理和分析中广泛应用。
-
在线排序:快速排序可以在不完全接收所有数据的情况下进行部分排序。它可以在逐步接收数据的过程中,对已接收的数据进行排序,适用于在线排序和实时数据处理的场景。
-
排名和统计分析:快速排序可以用于对数据进行排名和统计分析。通过对数据进行排序,可以快速找到最大值、最小值、中位数等统计指标,以及对数据进行排名和分组。
-
数据库查询优化:快速排序可以用于数据库中的排序操作,例如对查询结果按照某个字段进行排序。通过快速排序,可以提高数据库查询的性能和响应时间。















 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









