







《设计模式简单整理》
#第一篇: 设计原则
#第一篇: 设计原则
++++1、单一职责原则
++++2、里氏替换原则
++++3、依赖倒置原则
++++4、接口隔离原则
++++5、迪米特法则
++++6、开放封闭原则
++SOLID设计原则:
++++软件设计最大的难题就是应对需求的变化,但是纷繁复杂的需求变化又是不可预料的。我们要为不可预料的事情做好准备,这本身就是一件非常痛苦的情况,但是大师们还是给我们提出了非常好的6大设计原则以及23个设计模式来“封装”未来的变化:
--Single Responsibility Principle:单一职责原则
--Open Closed Principle :开闭原则
--Liskov Substitution Principle :里氏替换原则
--Law of Demeter : 迪米特法则
--Interface Segregation Principle:接口隔离原则
--Dependence Inversion Principle: 依赖倒置原则
++++把这6个原则的首字母(里氏替换原则和迪米特法则的首字母重复,只取一个)联合起来就是SOLID(solid,稳定的),其代表的含义也就是把这6个原则结合使用的好处: 建立稳定、灵活、健壮的设计,而开闭原则又是重中之重,是最基础的原则,是其他5大原则的精神领袖。
##1.1、单一职责原则
++1.1、单一职责原则(Single Responsibility Principle)
++++【单一职责原则(SRP)】: 就一个类而言,应该仅有一个引起它变化的原因。
++++如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化可能会削弱或者抑制这个类完成其他职责的能力。这种耦合会导致脆弱的设计,当变化发生时,设计会遭受到意想不到的破坏。
++++软件设计真正要做的许多内容,就是发现职责并把那些职责相互分离。
++++如果你能够想到多于一个的动机去改变一个类,那么这个类就具有多于一个的职责。
++++单一职责原则提出了一个编写程序的标准,用“职责”或“变化原因”来衡量接口或类设计得是否优良,但是“职责”和“变化原因”都是不可度量的,因项目而异,因环境而异。
++++类的单一职责确实受非常多因素的制约,纯理论地来讲,这个原则是非常优秀的,但是现实有现实的难处,你必须去考虑项目工期、成本、人员技术水平、硬件情况、网络情况甚至有时候还要考虑政府政策、垄断协议等因素。
++++对于单一职责原则,建议是接口一定要做到单一职责,类的设计尽量做到只有一个原因引起变化。
++1.1.1、单一职责原则的好处:
++++1、类的复杂性降低,实现什么职责都有清晰明确的定义;
++++2、可读性提高,复杂性降低,那当然可读性提高了;
++++3、可维护性提高,可读性提高,那当然更容易维护了;
++++4、变更引起的风险降低,变更是必不可少的,如果接口的单一职责做得好,一个接口修改只对相应的实现类有影响,对其他的接口无影响,这对系统的扩展性、维护性都有非常大的帮助。
++1.1.2、我单纯,所以我快乐
++++对于接口,我们在设计得时候一定要做到单一,但是对于实现类需要多方面考虑了。生搬硬套单一职责原则会引起类的剧增,给维护带来非常多的麻烦,而且过分细分类的职责也会人为地增加系统的复杂性。本来一个类可以实现的行为硬要拆成两个类,然后再使用聚合或组合的方式耦合在一起,人为制造了系统的复杂性。所以原则是死的,人是活的,这句话很有道理。
##1.2、里氏替换原则
++1.2、里氏替换原则(Liskov Substitution Principle)
++++【里氏代换原则(LSP)】: 子类型必须能够替换掉它们的父类型。
++++一个软件实体如果使用的是一个父类的话,那么一定适用于其子类,而且它察觉不出父类对象和子类对象的区别。也就是说,在软件里面,把父类都替换成它的子类,程序的行为没有变化。
++++只有当子类可以替换掉父类,软件单位的功能不受到影响时,父类才能真正被复用,而子类也能够在父类的基础上增加新的行为。
++++由于子类型的可替换性才使得使用父类类型的模块在无需修改的情况下就可以扩展。
++++所有引用基类的地方必须能透明地使用其子类的对象。(只要父类能出现的地方,子类就可以出现,而且替换为子类也不会产生任何错误或异常,使用者可能根本就不需要知道是父类还是子类。但是,反过来就不行了,有子类出现的地方,父类未必就能适应。)
++++采用里氏替换原则的目的就是增强程序的健壮性,版本升级时也可以保持非常好的兼容性。即使增加子类,原有的子类还可以继续运行。在实际项目中,每个子类对应不同的业务含义,使用父类作为参数,传递不同的子类完成不同的业务逻辑,非常完美。
++1.2.1、纠纷不断,规则压制
++++里氏替换原则为良好的继承定义了一个规范,一句简单的定义包含了4层含义:
--1、子类必须完全实现父类的方法。
----在做系统设计时,经常会定义一个接口或抽象类,然后编码实现,调用类则直接传入接口或抽象类,其实这里已经使用了里氏替换原则。
----在类中调用其他类时务必要使用父类或接口,如果不能使用父类或接口,则说明类的设计已经违背了LSP原则。
----如果子类不能完整地实现父类的方法,或者父类的某些方法在子类中已经发生“畸变”,则建议断开父子继承关系,采用依赖、聚集、组合等关系代替继承。
--2、子类可以有自己的个性。
----子类当然可以有自己的行为和外观了,也就是方法和属性。
--3、覆盖或实现父类的方法时输入参数可以被放大。
----方法中的输入参数称为前置条件。
--4、覆写或实现父类的方法时输出结果可以被缩小。
##1.3、依赖倒置原则
++1.3、依赖倒置原则(Dependence Inversion Principle)
++++【依赖倒转原则】:
--A、高层模块不应该依赖低层模块。两个都应该依赖抽象。
--B、抽象不应该依赖细节。细节应该依赖抽象。
++++里氏代换原则(LSP): 子类型必须能够替换掉它们的父类型。
--一个软件实体如果使用的是一个父类的话,那么一定适用于其子类,而且它察觉不出父类对象和子类对象的区别。也就是说,在软件里面,把父类都替换成它的子类,程序的行为没有变化。
--只有当子类可以替换掉父类,软件单元的功能不受到影响时,父类才能真正被复用,而子类也能够在父类的基础上增加新的行为。
--由于子类型的可替换性才使得父类类型的模块在无需修改的情况下就可以扩展。
++++依赖倒转其实可以说是面向对象设计的标志,用哪种语言来编写程序不重要,如果编写时考虑的都是如何针对抽象编程而不是针对细节编程,即程序中所有的依赖关系都是终止于抽象类或者接口,那就是面向对象的设计,反之那就是过程化的设计了。
++++依赖倒置原则的优点在小型项目中很难体现出来。在一个大中型项目中,采用依赖倒置原则有非常多的优点,特别是规避一些非技术因素引起的问题。项目越大,需要变化的概率也越大,通过采用依赖倒置原则设计的接口或抽象类对实现类进行约束,可以减少需要变化引起的工作量剧增的情况。人员的变动在大中型项目中也是时常存在的,如果设计优良、代码结构清晰,人员变化对项目的影响基本为零。大中型项目的维护周期一般都很长,采用依赖倒置原则可以让维护人员轻松地扩展和维护。
++++依赖倒置原则是6个设计原则中最难实现的原则,它是实现开闭原则的重要途径,依赖倒置原则没有实现,就别想实现对扩展开放,对修改关闭。在项目中,大家只要记住是“面向接口编程”就基本上抓住了依赖倒置原则的核心。
++++我们在实际的项目中使用依赖倒置原则时需要审时度势,所以别为了遵循一个原则而放弃了一个项目的终极目标: 投产上线和盈利。 作为一个项目经理或架构师,应该懂得技术只是实现目的的工具,惹恼了顶头上司,设计做得再漂亮,代码写得再完美,项目做得再符合标准,一旦项目亏本,产品投入大于产出,那整体就是扯淡!
++1.3.1、依赖倒置原则包含三层含义:
++++A、高层模块不应该依赖低层模块,两者都应该依赖其抽象;
++++B、抽象不应该依赖细节;
++++C、细节应该依赖抽象;
++++补充1:高层模块和低层模块容易理解,每一个逻辑的实现都是由原则逻辑组成的,不可分割的原子逻辑就是低层模块,原则逻辑的再组装就是高层模块。
++++补充2:抽象就是指接口或抽象类,两者都是不能直接被实例化的;细节就是实现类,实现接口或继承抽象类而产生的类就是细节,其特点就是可以直接被实例化,也就是可以加上一个关键字new产生一个对象。
++1.3.2、依赖倒置原则的表现:
++++A、模块间的依赖通过抽象发生,实现类之间不发生直接的依赖关系,其依赖关系是通过接口或抽象类产生的;
++++B、接口或抽象类不依赖于实现类;
++++C、实现类依赖接口或抽象类;
++++补充1: 面向接口编程:OOD(Object-Oriented Design,面向对象设计)的精髓之一。
++1.3.3、言而无信,你太需要契约
++++采用依赖倒置原则可以减少类间的耦合性,提高系统的稳定性,降低并行开发引起的风险,提高代码的可读性和可维护性。
++++设计是否具备稳定性,只要适当地“松松土”,观察“设计的蓝图”是否还可以茁壮地成长就可以得出结论,稳定性较高的设计,在周围环境频繁变化的时候,依赖可以做到“我自岿然不动”。
++1.3.4、依赖的三种写法:
++++依赖是可以传递的,A对象依赖B对象,B又依赖C,C又依赖D ...... 生生不息,依赖不止,记住一点: 只要做到抽象依赖,即使是多层的依赖传递也无所畏惧!
++++A、构造函数传递依赖对象:
--在类中通过构造函数声明依赖对象,按照依赖注入的说法,这种方式叫做构造函数注入。
--public Driver(ICar _car){ this.car = _car; }
++++B、Setter方法传递依赖对象:
--在抽象中设置Setter方法声明依赖关系,依照依赖注入的说法,这是Setter依赖注入。
--public void setCar(ICar car){ this.car = car; }
++++C、接口声明依赖对象:
--在接口的方法中声明依赖对象,采用接口声明依赖的方式,该方法也叫做接口注入。
--public void drive(ICar car);
++1.3.5、依赖倒置原则遵循的几个规则:
++++依赖倒置原则的本质就是通过抽象(接口或抽象类)使各个类或模块的实现彼此独立,不相互影响,实现模块间的松耦合。
++++A、每个类尽量都有接口或抽象类,或者抽象类和接口两者都具备。
--这是依赖倒置的基本要求,接口和抽象类都是属于抽象的,有了抽象才可能依赖倒置。
++++B、变量的表面类型尽量是接口或者是抽象类。
++++C、任何类都不应该从具体类派生。
++++D、尽量不要覆写基类的方法。
--如果基类是一个抽象类,而且这个方法已经实现了,子类尽量不要覆写。类间依赖的是抽象,覆写了抽象方法,对依赖的稳定性会产生一定的影响。
++++E、结合里氏替换原则使用。
--接口负责定义public属性和方法,并且声明与其他对象的依赖关系,抽象类负责公共构造部分的实现,实现类准确的实现业务逻辑,同时在适当的时候对父类进行细化。
##1.4、接口隔离原则
++1.4、接口隔离原则
++++接口分为两种:
--A、实例接口(Object Interface),声明一个类,然后用new关键字产生一个实例,它是对一个类型的事物的描述,这是一种接口。
--B、类接口(Class Interface),使用interface关键字定义的接口。
++++客户端不应该依赖它不需要的接口。(客户端需要什么接口就提供什么接口,把不需要的接口剔除掉,那就需要对接口进行细化,保证其纯洁性。)
++++类间的依赖关系应该建立在最小的接口上。(它要求是最小的接口,也是要求接口细化,接口纯洁。)
++++建立单一接口,不要建立臃肿庞大的接口。(接口尽量细化,同时接口中的方法尽量少。)
++++接口隔离原则与单一职责的审视角度是不同的,单一职责要求的是类和接口职责单一,注重的是职责,这是业务逻辑上的划分,而接口隔离原则要求接口的方法尽量少。
++++接口隔离原则和其他设计原则一样,都需要花费较多的时间和精力来进行设计和筹划,但是它带来了设计的灵活性,让你可以在业务人员提出“无理”要求时轻松应对。贯彻使用接口隔离原则最好的方法就是一个接口一个方法,保证绝对符合接口隔离原则(有可能不符合单一职责原则)。(根据经验和常识决定接口的粒度大小,接口粒度太小,导致接口数据剧增,开发人员呛死在接口的海洋里;接口粒度太大,灵活性降低,无法提供定制服务,给整体项目带来无法预料的风险。)
++1.4.1、保证接口的纯洁性
++++接口隔离原则是对接口进行规范约束,其包含以下4层含义:
--A、接口要尽量小。
----这是接口隔离原则的核心定义,不出现臃肿的接口(Fat Interface),但是“小”是有限度的,首先就是不能违反单一职责原则。(根据接口隔离原则拆分接口时,首先必须满足单一职责原则)。
--B、接口要高内聚。
----高内聚就是提高接口、类、模块的处理能力,减少对外的交互。(具体到接口隔离原则就是,要求在接口中尽量少公布public方法,接口是对外的承诺,承诺越少对系统的开发越有利,变更的风险也就越少,同时也有利于降低成本)
--C、定制服务。
----一个系统或系统内的模块之间必然会有耦合,有耦合就要有相互访问的接口(并不一定是定义Interface,也可能是一个类或单纯的数据交换),我们设计时就需要为各个访问者(即客户端)定制服务。(定制服务就是单独为一个个体提供优良的服务)
----我们在做系统设计时也需要考虑对系统之间或模块之间的接口采用定制服务。采用定制服务就必然有一个要求: 只提供访问者需要的方法。
--D、接口设计是有限度的。
----接口的设计粒度越小,系统越灵活,这是不争的事实。但是,灵活的同时也带来了结构的复杂化,开发难度增加,可维护性降低,这不是一个项目或产品所期望看到的,所以接口设计一定要注意适度。
++1.4.2、接口隔离原则可以根据以下几个规则来衡量:
++++接口隔离原则是对接口的定义,同时也是对类的定义,接口和类尽量使用原子接口或原子类来组装。
++++A、一个接口只服务于一个子模块或业务逻辑;
++++B、通过业务逻辑压缩接口中的public方法,接口时常去回顾,尽量让接口达到“满身筋骨肉”,而不是“肥嘟嘟”的一大堆方法。
++++C、已经被污染了的接口,尽量去修改,若变更的风险较大,则采用适配器模式进行转化处理。
++++D、了解环境,拒绝盲从。每个项目或产品都有特定的环境因素,别看到大师是这样做的你就照抄。环境不同,接口拆分的标准就不同。深入了解业务逻辑,最好的接口设计就出自你的手中。
##1.5、迪米特法则
++1.5、迪米特法则(Law of Demeter)
++++【迪米特法则(LoD)】: 如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。如果其中一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。
++++在类的结构设计上,每一个类都应当尽量降低成员的访问权限。
++++迪米特法则其根本思想,是强调了类之间的松耦合。
++++类之间的耦合越弱,越有利于复用,一个处在弱耦合的类被修改,不会对有关系的类造成波及。
++++迪米特法则(Law of Demeter, LoD)也称为最少知识原则(Least Knowledge Principle)。
--一个对象应该对其他对象有最少的了解。(一个类应该对自己需要耦合或调用的类知道得最少,被耦合或调用的类的内部是如何复杂都和我没关系。)
++++迪米特法则的核心观念就是类间解耦,弱耦合,只有弱耦合了以后,类的复用率才可以提高。其要求的结果就是产生了大量的中转或跳转类,导致系统的复杂性提高,同时也为维护带来了难度。(在采用迪米特法则时需要反复权衡,既做到让结构清晰,又做到高内聚低耦合。)
++++“任何两个素不相识的人中间最多只隔着6个人,即只通过6个人就可以将他们联系在一起”,这就是著名的“六度分隔理论”。如果将这个理论应用到项目中,也就是说,调用的类之间最多有6次传递。(其实,在实际应用中,如果一个类跳转两次以上才能访问到另一个类,就需要想办法进行重构了。因为一个系统的成功不仅仅是一个标准或者原则就能够决定的,有非常多的外在因素决定,跳转次数越多,系统越复杂,维护就越困难,所以只要跳转不超过两次都是可以忍受的,这需要具体问题具体分析。)
++++迪米特法则要求类间解耦,但解耦是有限度的。在实际的项目中,需要适度地考虑这个原则,别为了套用原则而做项目。原则只是供参考,如果违背了这个原则,项目也未必会失败,这就需要在采用原则时反复度量,不遵循是不对的,严格执行就是“过犹不及”。
++1.5.1、迪米特法则对类的低耦合包含以下4层含义:
++++1、只和朋友交流。
--迪米特法则还有一个英文解释是:Only talk to your immediate friends(只与直接的朋友通信。)
--每个对象都必然会与其他对象有耦合关系,两个对象之间的耦合就成为朋友关系,这种关系的类型有很多,例如组合、聚合、依赖等。
--类与类之间的关系是建立在类间的,而不是方法间,因此一个方法尽量不引入一个类中不存在的对象。
++++2、朋友间也是由距离的。
--人和人之间是有距离的,太远关系逐渐疏远,最终形同陌路;太近就相互刺伤。
--一个类公开的public属性或方法越多,修改时涉及的面也就越大,变更引起的风险扩散也就越大。因此,为了保持朋友类间的距离,在设计时需要反复衡量;是否还可以再减少public方法和属性,是否可以修改为private、protected等访问权限。
--迪米特法则要求类“羞涩”一点,尽量不要对外公布太多的public方法和非静态的public变量,尽量内敛,多使用private、protected等访问权限。
++++3、是自己的就是自己的。
--如果一个方法放在本类中,即不增加类间关系,也对本类不产生负面影响,就放置在本类中。
++++4、谨慎使用Serializable。
--从private变更为public,访问权限扩大了,如果服务器上没有做出相应的变更,就会报序列化失败。
##1.6、开放封闭原则
++1.6、开放封闭原则(Open Closed Principle)
++++【开放-封闭原则】: 是说软件实体(类、模块、函数等等)应该可以扩展,但是不可修改。
++++对于扩展是开放的(Open for extension),对于更改是封闭的(Closed for modification)。
++++怎样的设计才能面对需求的改变却可以保持相对稳定,从而使得系统可以在第一个版本以后不断推出新的版本呢?
++++无论模块是多么的“封闭”,都会存在一些无法对之封闭的变化。既然不可能完全封闭,设计人员必须对于他设计的模块应该对哪种变化封闭做出选择。他必须先猜测出最有可能发生的变化种类,然后构造抽象来隔离那些变化。
++++等到变化发生时立即采取行动。
++++在最初编写代码时,假设变化不会发生。当变化发生时,我们就创建抽象来隔离以后发生的同类变化。
++++面对需求,对程序的改动是通过增加新代码进行的,而不是更改现有的代码。(这是“开放-封闭原则”的精神所在。)
++++我们希望的是在开发工作展开不久就知道可能发生的变化。查明可能发生的变化所等待的时间越长,要创建正确的抽象就越困难。
++++开放-封闭原则是面向对象设计的核心所在。遵循这个原则可以带来面向对象技术所声称的巨大好处,也就是可维护、可扩展、可复用、灵活性好。开发人员应该仅对程序中呈现出频繁变化的那些部分做出抽象,然而,对于应用程序中的每个部分都刻意地进行抽象同样不是一个好主意。拒绝不成熟的抽象和抽象本身一样重要。
++++开闭原则的定义: Software entities like classes, modules and functions should be open for extension but closed for modifications。(一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。)
++++开闭原则只是精神口号,实现拥抱变化的方法非常多,并不局限于这6大设计原则,但是遵循这6大设计原则基本上可以应对大多数变化。因此,我们在项目中应尽量采用这6大原则,适当时候可以进行扩充。
++++如果你是一位项目经理或架构师,应尽量让自己的项目成员稳定,稳定后才能建立高效的团队文化,章程是一个团队所有成员共同的知识结晶,也是所有成员必须遵守的约定。优秀的章程能带给项目带来非常多的好处,如提高开发效率、降低缺陷率、提高团队士气、提高技术成员水平,等等。
++++开闭原则是一个终极目标,任何人包括大师级人物都无法百分之百做到,但朝这个方向努力,可以非常显著地改善一个系统的架构,真正做到“拥抱变化”。
++1.6.1、开闭原则的庐山真面目
++++软件实体应该对扩展开放,对修改关闭,其含义是说一个软件实体应该通过扩展来实现变化,而不是通过修改已有的代码来实现变化。
++++软件实体包括以下几个部分:
--项目或软件产品中按照一定的逻辑规则划分的模块。
--抽象和类。
--方法。
++++一个软件产品只要在生命期内,都会发生变化,既然变化是一个既定的事实,我们就应该在设计时尽量适应这些变化,以提高项目的稳定性和灵活性,真正实践“拥抱变化”。开闭原则告诉我们应尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来完成变化,它是软件实体的未来事件而制定的对现行开发设计进行约束的一个原则。
++++开闭原则对扩展开放,对修改关闭,并不意味着不做任何修改,低层模块的变更,必然要有高层模块进行耦合,否则就是一个独立无意义的代码片段。
++++变化有一下三种类型:
--A、逻辑变化。
----只变化一个逻辑,而不涉及其他模块,可以通过修改原有类中的方法的方式来完成,前提条件是所有依赖或关联类都按照相同的逻辑处理。
--B、子模块变化。
----一个模块变化,会对其他的模块产生影响,特别是一个低层次的模块变化必然引起高层模块的变化,因此在通过扩展完成变化时,高层次的模块修改是必然的。
--C、可见视图变化。
----可见视图是提供给客户使用的界面,该部分的变化一般会引起连锁反应。如果仅仅是界面上按钮、文字的重新排布倒是简单,最司空见惯的是业务耦合变化。
++1.6.2、为什么要采用开闭原则
++++每个事物的诞生都有它存在的必要性,存在即合理,那开闭原则的存在也是合理的。
++++首先,开闭原则是那么地著名,只要是做面向对象编程的,甭管是什么语言,在开发时都会提及开闭原则。
++++其次,开闭原则是最基础的一个原则,前5个原则都是开闭原则的具体形态,也就是说前5个原则就是指导设计的工具和方法,而开闭原则才是其精神领袖。换一个角度来理解,开闭原则是抽象类,其他五大原则是具体的实现类,开闭原则在面向对象设计领域中的地位就类似于牛顿第一定律在力学、勾股定理在几何学、质能方程在狭义相对论中的地位,其地位无人能及。
++++最后,开闭原则是非常重要的,可通过以下几方面理解其重要性:
--A、开闭原则对测试的影响。
----所有已经投产的代码都是有意义的,并且都受系统规则的约束,这样的代码都要经过“千锤百炼”的测试过程,不仅保证逻辑是正确的,还要保证苛刻条件(高压力、异常、错误)下不产生“有毒代码(Poisonous Code)”,因此有变化提出时,我们就需要考虑一下,原有的健壮代码是否可以不修改,仅仅通过扩展实现变化呢?否则,就需要把原有的测试过程回笼一遍,需要进行单元测试、功能测试、集成测试甚至验收测试,现在虽然在大力提供自动化测试工具,但是仍然代替不了人工的测试工作。
--B、开闭原则可以提高复用性。
----在面向对象的设计中,所有的逻辑都是从原子逻辑组合而来的,而不是在一个类中独立实现一个业务逻辑。只有这样的代码才可以复用,粒度越小,被复用的可能性就越大。
--C、开闭原则可以提高可维护性。
----一款软件投产后,维护人员的工作不仅仅是对数据进行维护,还可能要对程序进行扩展,维护人员最乐意做的事情就是扩展一个类,而不是修改一个类,甭管原有的代码写得多么优秀还是多么糟糕,让维护人员读懂原有的代码,然后再修改,是一件很痛苦的事情,不要让他在原有的代码海洋里游弋完毕后再修改,那是对维护人员的一种折磨和摧残。
--D、面向对象开发的要求。
----万物皆对象,需要把所有的事物都抽象成对象,然后针对对象进行操作,但是万物皆运动,有运动就有变化,有变化就要有策略去应对。这就需要在设计之初考虑到所有可能变化的因素,然后留下接口,等待“可能”转变为“现实”。
++1.6.3、如何使用开闭原则
++++开闭原则是一个非常虚的原则,前5个原则是对开闭原则的具体解释,但是开闭原则并不局限于这么多,它“虚”得没有边界,就像“好好学习,天天向上”的口号一样,告诉我们要好好学习,但是学什么,怎么学并没有告诉我们,需要去体会和掌握,开闭原则也是一个口号,那怎么把这个口号应用到实际工作中呢?
--A、抽象约束。
----抽象是对一组事物的通用描述,没有具体的实现,也就表示它可以有非常多的可能性,可以跟随需求的变化而变化。因此,通过接口或抽象类可以约束一组可能变化的行为,并且能够实现对扩展开放,其包含三层含义:
----第一,通过接口或抽象类约束扩展,对扩展进行边界限定,不允许出现在接口或抽象类中不存在的public方法;
----第二,参数类型、引用对象尽量使用接口或者抽象类,而不是实现类;
----第三,抽象层尽量保持稳定,一旦确定即不允许修改。
--B、元数据(metadata)控制模块行为。
----尽量使用元数据来控制程序的行为,减少重复开发。(元数据: 用来描述环境和数据的数据,就是配置参数,参数可以从文件中获得,也可以从数据库中获得。)
--C、制定项目章程。
----在一个团队中,建立项目章程是非常重要的,因为章程中制定了所有人员都必须遵守的约定,对项目来说,约定优于配置。
--D、封装变化。
----对变化的封装包含两层含义:
----第一,将相同的变化封装到一个接口或抽象类中;
----第二,将不同的变化封装到不同的接口或抽象类中,不应该有两个不同的变化出现在同一个接口或抽象类中。
----封装变化,也就是受保护的变化(protected variations),找出预计有变化或不稳定的点,为这些变化点创建稳定的接口,准确地将是封装可能发生的变化,一旦预测到或“第六感”发觉有变化,就可以进行封装,23个设计模式都是从各个不同的角度对变化进行封装的。
#第二篇: 设计模式
#第二篇: 设计模式
++++设计模式,是对面向对象思想的深刻理解,对软件设计方法和编程经验的完美总结。
++++如果说,数学是思维的体操,那设计模式,就是面向对象编程思维的体操。
++++设计模式有四境界:
--境界1:没学前是一点不懂,根本想不到用设计模式,设计的代码很糟糕。
--境界2:学了几个模式后,很开心,于是到处想着要用自己学过的模式,于是时常造成误用模式而不自知。
--境界3:学完全部模式时,感觉诸多模式极其相似,无法分清模式之间的差异,有困惑,但深知误用之害,应用之时有所犹豫。
--境界4:灵活应用模式,甚至不应用具体的某种模式也能设计出非常优秀的代码,以达到无剑胜有剑的境界。
++++不会用设计模式的人远远超过过度使用设计模式的人,从这个角度讲,因为怕过度设计而不用设计模式显然是因噎废食。当你认识到自己有过度使用模式的时候,那就证明你已意识到问题的存在,只有通过不断的钻研和努力,你才能突破“不识庐山真面目,只缘身在此山中”的瓶颈,达到“会当凌绝顶,一览众山小”的境界。
++++一般而言,一个设计模式有四个基本要素:
--A、模式名称(pattern name): 一个助记名,它用一两个词来描述模式的问题、解决方案和效果。
--B、问题(problem): 描述了应该在何时使用模式。
--C、解决方案(solution): 描述了设计的组成成分,它们之间的相互关系及各自的职责和协作方式。
--D、效果(consequences): 描述了模式应用的效果及使用模式应权衡的问题。
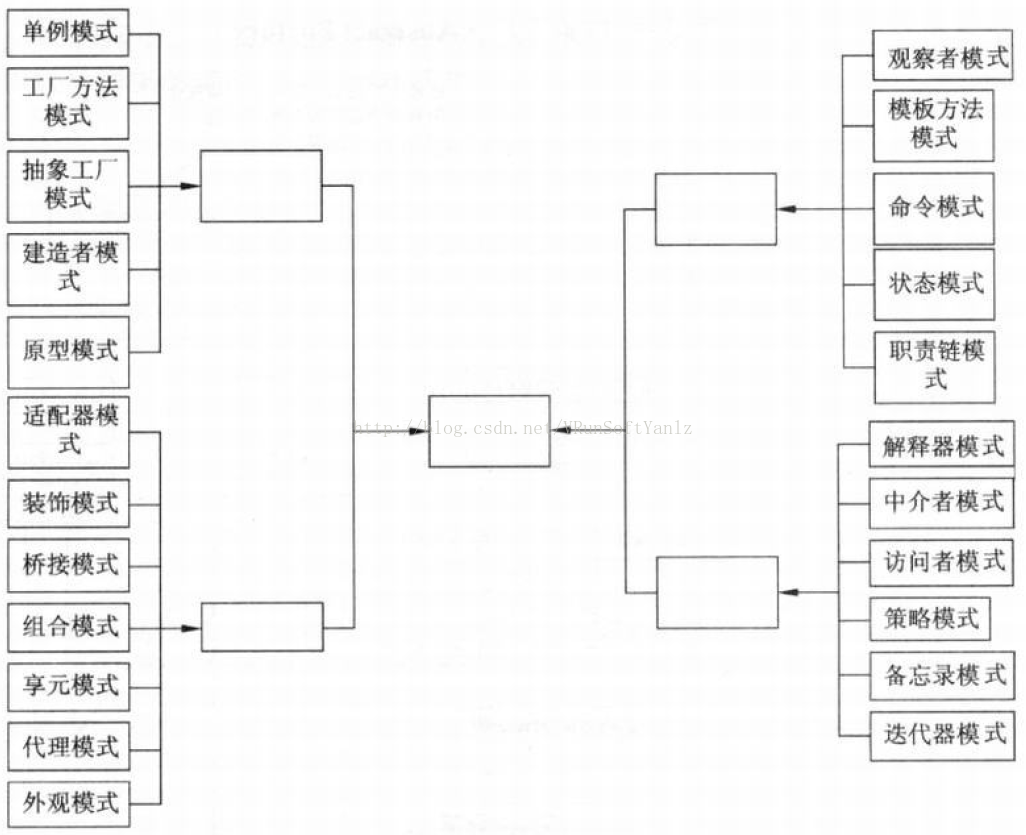
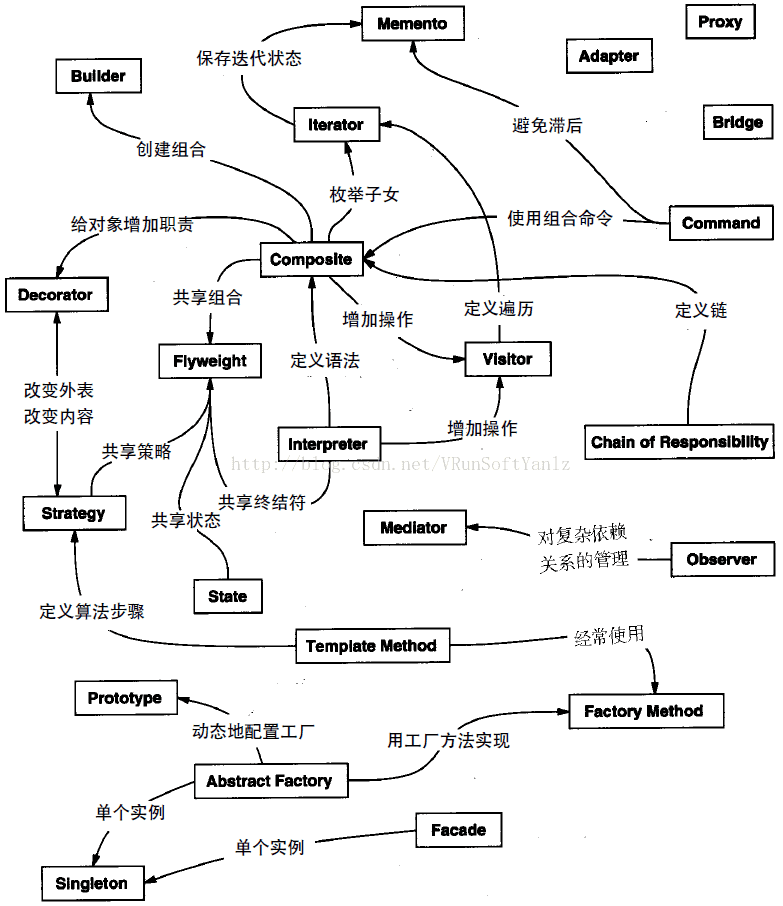
++23种设计模式:
++++A、创建型模式:
--A.1、单例模式
--A.2、工厂方法模式
--A.3、抽象工厂模式
--A.4、建造者模式
--A.5、原型模式
++++B、结构型模式:
--B.6、适配器模式
--B.7、装饰模式
--B.8、桥接模式
--B.9、组合模式
--B.10、享元模式
--B.11、代理模式
--B.12、外观模式
++++C、行为型模式:
--C.13、观察者模式
--C.14、模板方法模式
--C.15、命令模式
--C.16、状态模式
--C.17、责任链模式
--C.18、解释器模式
--C.19、中介者模式
--C.20、访问者模式
--C.21、策略模式
--C.22、备忘录模式
--C.23、迭代器模式
##2.1、单例模式
++2.1、单例模式
++++【单例模式(Singleton)】: 保证一个类仅有一个实例,并提供一个访问它的全局访问点。
++++通常我们可以让一个全局变量使得一个对象被访问,但它不能防止你实例化多个对象。一个最好的方法就是,让类自身负责保存它的唯一实例。这个类可以保证没有其他实例可以被创建,并且它可以提供一个访问该实例的方法。
++++单例模式因为Singleton类封装它的唯一实例,这样它可以严格地控制客户怎样访问它以及何时访问它。简单地说就是对唯一实例的受控访问。
++++单例模式(Singleton Pattern)是一个比较简单的模式,其定义:Ensure a class has only one instance, and provide a global point of access to it.(确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例。)
++2.1.1、单例模式实现

++++Singleton类,定义一个GetInstance操作,允许客户访问它的唯一实例。GetInstance是一个静态方法,主要负责创建自己的唯一实例。
class Singleton{
private static Singleton instance;
private Singleton(){} //构造方法让其private,这就堵死了外界利用new创建此类实例的可能
//此方法是获得本类实例的唯一全局访问点
public static Singleton GetInstance(){
if(instance == null){
//若实例不存在,则new一个新实例,否则返回已有的实例
instance = new Singleton();
}
return instance;
}
}
++2.1.2、静态初始化
++++C#与公共语言运行库提供了一种“静态初始化”方法,这种方法不需要开发人员显式地编写线程安全代码,即可解决多线程环境下它是不安全的问题。
//sealed: 阻止发生派生,而派生可能会增加实例
public sealed class Singleton{
//readonly:在第一次引用类的任何成员时创建实例。公共语言运行库负责处理变量初始化
private static readonly Singleton instance = new Singleton();
private Singleton(){ }
public static Singleton GetInstance(){
return instance;
}
}
++++这种静态初始化的方式是在自己被加载时就将自己实例化,所以被形象地称之为饿汉式单例类。(原先的是要在第一次被引用时,才会将自己实例化,所以就被称为懒汉式单例类。)
++2.1.3、单例模式的优点:
++++优点A.1: 对唯一实例的受控访问。(因为Singleton类封装它的唯一实例,所以它可以严格的控制客户怎样以及何时访问它。)
++++优点A.2:缩小名空间。(Singleton模式是对全局变量的一种改进。它避免了哪些存储唯一实例的全局变量污染名空间。)
++++优点A.3:允许对操作和表示的精化。(Singleton类可以有子类,而且用这个扩展类的实例来配置一个应用是很容易的。你可以用你所需要的类的实例在运行时刻配置应用。)
++++优点A.4:允许可变数目的实例。(单例模式使得你易于改变你的想法,并允许Singleton类的多个实例。此外,你可以用相同的方法来控制应用所使用的实例的数目。只有允许访问Singleton实例的操作需要改变。)
++++优点A.5: 比类操作更灵活。(另一种封装单例功能的方式是使用类操作(即C++中的静态成员函数等)。但这种语言技术都难以改变设计以允许一个类有多个实例。此外,C++中的静态成员函数不是虚函数,因此子类不能多态的重定义它们。)
++++优点B.1:由于单例模式在内存中只有一个实例,减少了内存开支,特别是一个对象需要频繁地创建、销毁时,而且创建和销毁时性能又无法优化,单例模式的优势就非常明显。
++++优点B.2:由于单例模式只生成一个实例,所以减少了系统的性能开销,当一个对象的产生需要比较多的资源时,如读取配置、产生其他依赖对象时,则可以通过在应用启动时直接产生一个单例对象,然后用永久驻留内存的方式来解决。
++++优点B.3:单例模式可以避免对资源的多重占用,例如一个写文件动作,由于只有一个实例存在内存中,避免对同一个资源文件的同时写操作。
++++优点B.4:单例模式可以在系统设置全局的访问点,优化和共享资源访问,例如可以设计一个单例类,负责所有数据表的映射处理。
++2.1.4、单例模式的缺点:
++++缺点1: 单例模式一般没有接口,扩展很困难,若要扩展,除了修改代码基本上没有第二种途径可以实现。(单例不能增加接口,是因为接口对单例模式是没有任何意义的,它要求“自行实例化”,并且提供单一实例、接口或者抽象类,是不可能被实例化的。)(当然,在特殊情况下,单例模式可以实现接口、被继承等,需要在系统开发中根据环境判断。)
++++缺点2: 单例模式对测试是不利的。(在并行开发环境中,如果单例模式没有完成,是不能进行测试的,没有接口也不能虚拟一个对象。)
++++缺点3: 单例模式与单一职责原则有冲突。(一个类应该只实现一个逻辑,而不关心它是否是单例的,是不是要单例取决于环境,单例模式把“要单例”和业务逻辑融合在一个类中。)
++2.1.5、单例模式的使用场景:
++++使用Singleton模式:
--当类只能有一个实例而且客户可以从一个众所周知的访问点访问它时。
--当这个唯一实例应该是通过子类化可扩展的,并且客户应该无需更改代码就能使用一个扩展的实例时。
++++在一个系统中,要求一个类有且仅有一个对象,如果出现多个对象就会出现“不良反应”,可以采用单例模式,具体的场景如下:
--场景A:要求生成唯一序列号的环境;
--场景B:在整个项目中需要一个共享访问点或共享数据。(例如一个Web页面上的计时器,可以不用把每次刷新都记录到数据库中,使用单例模式保持计数器的值,并确保是线程安全的。)
--场景C:创建一个对象需要消耗的资源过多,如要访问IO和数据库等资源;
--场景D:需要定义大量的静态常量和静态方法(如工具类)的环境,可以采用单例模式(当然,也可以直接声明为static的方式)。
++2.1.6、相关模式
++++很多模式可以使用Singleton模式实现。
##2.2、工厂方法模式
++2.2、工厂方法模式
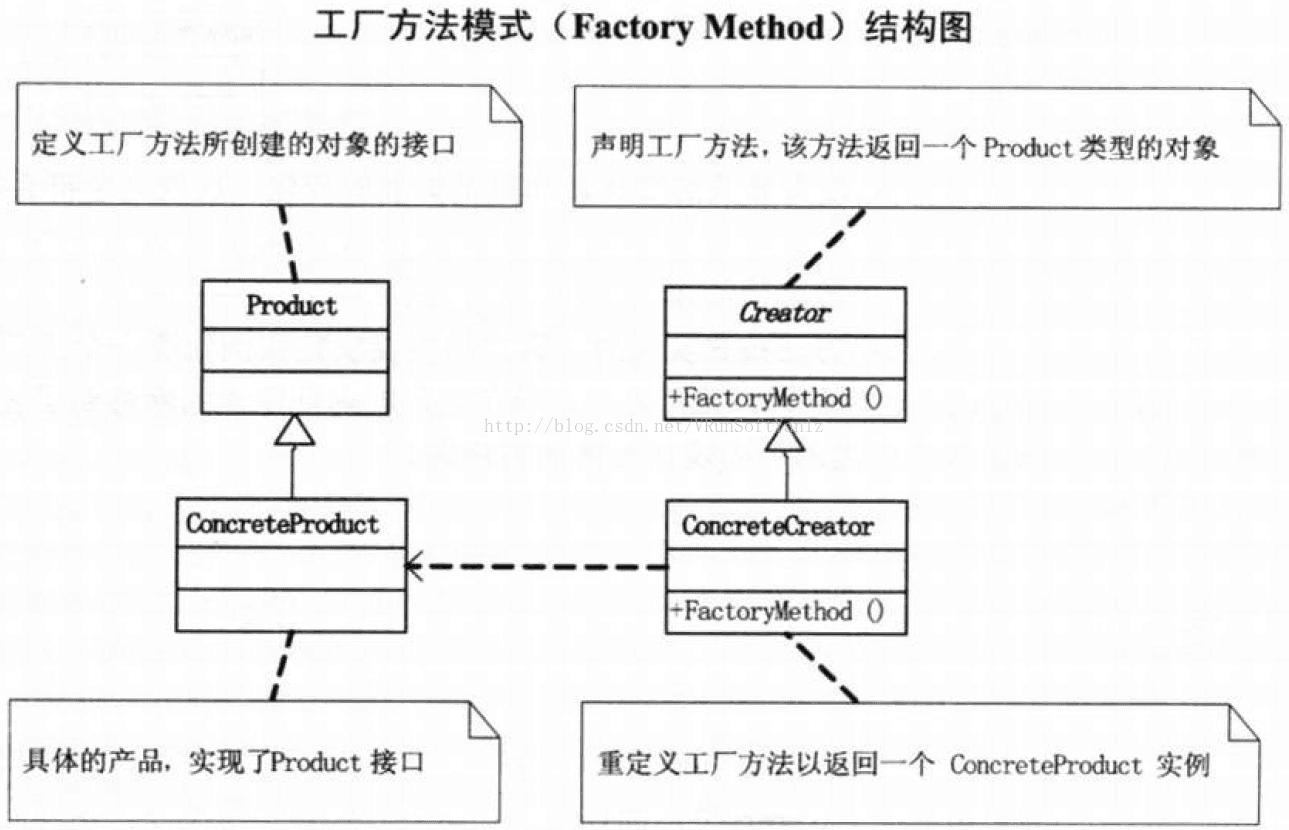
++++【工厂方法模式(Factory Method)】: 定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。
++++工厂方法模式使用的频率非常高,其定义为:Define an interface for creating an object, but let subclasses decide which class to instantiate. Factory Method lets a class defer instantiation to subclasses.(定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延时到其子类。)
++++工厂方法模式在项目中使用得非常频繁,以至于很多代码中都包含工厂方法模式。(该模式几乎尽人皆知,但不是每个人都能用得好。熟能生巧,熟练掌握该模式,多思考工厂方法如何应用,而且工厂方法模式还可以与其他模式混合使用(例如模板方法模式、单例模式、原型模式等),变化出无穷的优秀设计,这也正是软件设计和开发的乐趣所在。)
++2.2.1、工厂方法模式实现
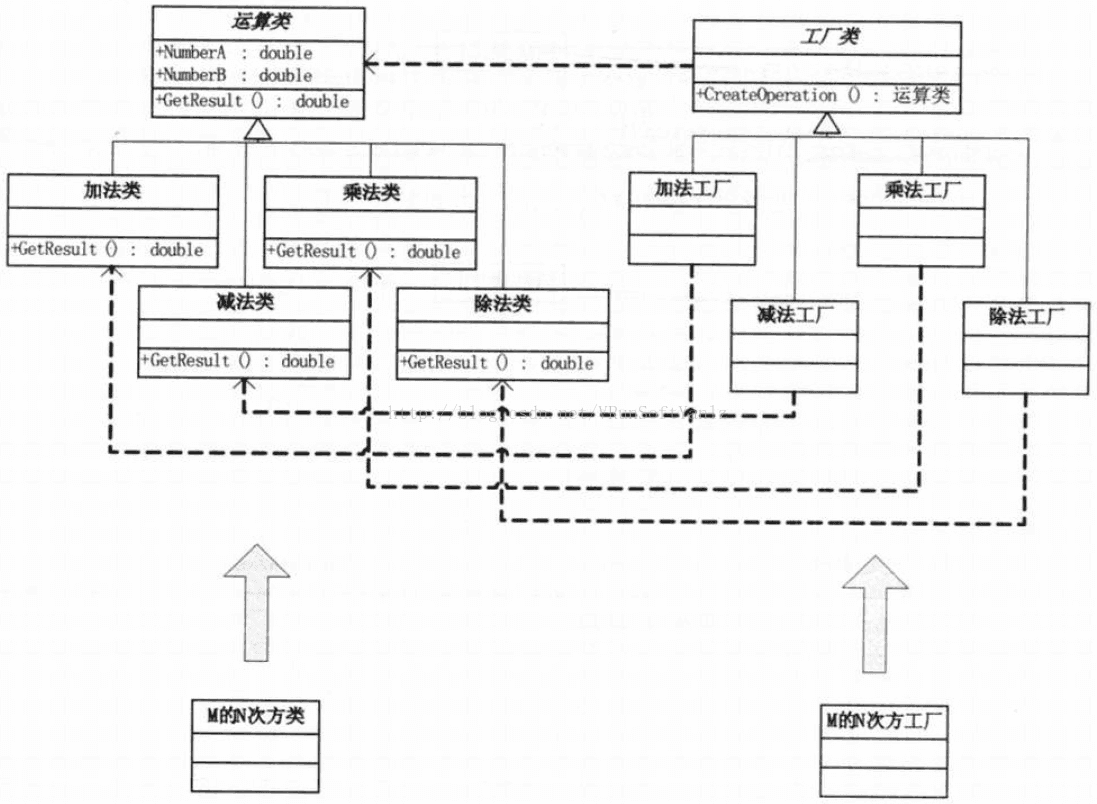
++++案例: 计算器的工厂方法模式实现:
--A、先构建一个工厂接口:
interface IFactory{
Operation CreateOperation();
}
--B、然后加减乘除各建一个具体工厂去实现这个接口:
//加法类工厂
class AddFactory:IFactory{
public Operation CreateOperation(){
return new OperationAdd();
}
}
//减法类工厂
class SubFactory:IFactory{
public Operation CreateOperation(){
return new OperationSub();
}
}
//乘法类工厂
class MulFactory:IFactory{
public Operation CreateOperation(){
return new OperationMul();
}
}
//除法类工厂
class DivFactory:IFactory{
public Operation CreateOperation(){
return new OperationDiv();
}
}
//Operation运算类
public class Operation{
private double _numberA =0;
private double _numberB=0;
public double NumberA{
get{ return _numberA; }
set{ _numberA = value; }
}
public double NumberB{
get{ return _numberB; }
set{ _numberB = value; }
}
public virtual double GetResult(){
double result = 0;
return result;
}
}
//加减乘除类
//加法类,继承运算类
class OperationAdd:Operation{
public override double GetResult(){
double result = 0;
result = NumberA + NumberB;
return result;
}
}
//减法类,继承运算类
class OperationSub:Operation{
public override double GetResult(){
double result = 0;
result = NumberA - NumberB;
return result;
}
}
//乘法类,继承运算类
class OperationMul:Operation{
public override double GetResult(){
double result = 0;
result = NumberA * NumberB;
return result;
}
}
//除法类,继承运算类
class OperationDiv:Operation{
public override double GetResult(){
double result = 0;
if(NumberB == 0){
Throw new Exception(“yanlz_Error:除数不能为0。”);
}
result = NumberA / NumberB;
return result;
}
}
//客户端的代码:
IFactory operFactory = new AddFactory();
Operation oper = operFactory.CreateOperation();
oper.NumberA =1;
oper.NumberB =2;
double result = oper.GetResult();
++2.2.2、工厂方法模式的优点
++++首先,良好的封装性,代码结构清晰。(一个对象创建是有条件约束的,如一个调用者需要一个具体的产品对象,只要知道这个产品的类名(或约束字符串)就可以了,不用知道创建对象的艰辛过程,降低模块间的耦合。)
++++其次,工厂方法模式的扩展性非常优秀。(在增加产品类的情况下,只要适当地修改具体的工厂类或扩展一个工厂类,就可以完成“拥抱变化”。)
++++再次,屏蔽产品类。(这一特点非常重要,产品类的实现如何变化,调用者都不需要关心,它只需要关心产品的接口,只要接口保持不变,系统中的上层模块就不要发生变化。因为产品类的实例化工作是由工厂类负责的,一个产品对象具体由哪一个产品生成是由工厂类决定的。)
++++最后,工厂方法模式是典型的解耦框架。(高层模块值需要知道产品的抽象类,其他的实现类都不用关心,符合迪米特法则,我不需要的就不要去交流,也符合依赖倒置原则,只依赖产品类的抽象;当然也符合里氏替换原则,使用产品子类替换产品父类,没问题!)
++2.2.3、工厂方法模式的使用场景
++++A.1、当一个类不知道它所必须创建的对象的类的时候。
++++A.2、当一个类希望由它的子类来指定它所创建的对象的时候。
++++A.3、当类将创建对象的职责委托给多个帮助子类中的某一个,并且你希望将哪一个帮助子类是代理者这一信息局部化的时候。
++++B.1、工厂方法模式是new一个对象的替代品,所以在所有需要生成对象的地方都可以使用,但是需要慎重地考虑是否要增加一个工厂类进行管理,增加代码的复杂度。
++++B.2、需要灵活的、可扩展的框架时,可以考虑采用工厂方法模式。万物皆对象,那万物也就皆产品类。
++++B.3、工厂方法模式可以用在异构项目中。
++++B.4、可以使用在测试驱动开发的框架下。
++2.2.4、相关模式
++++AbstractFactory经常用工厂方法来实现。
++++工厂方法通常在TemplateMethods中被调用。
++++Prototypes不要创建Creator的子类。但是,它们通常要求一个针对Product类的Initialize操作。Creator使用Initialize来初始化对象。而FactoryMethod不需要这样的操作。
##2.3、抽象工厂模式
++2.3、抽象工厂模式
++++【抽象工厂模式(Abstract Factory)】: 提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
++++抽象工厂模式(Abstract Factory Pattern)是一种比较常用的模式,定义:Provide an interface for creating families of related or dependent objects without specifying their concrete classes.(为创建一组相关或相互依赖的对象提供一个接口,而且无需指定它们的具体类。)
++++抽象工厂模式是工厂方法模式的升级版本,在有多个业务品种、业务分类时,通过抽象工厂模式产生需要的对象是一种非常好的解决方式。
++++抽象工厂模式的使用场景定义非常简单: 一个对象族(或是一组没有任何关系的对象)都有相同的约束,则可以使用抽象工厂模式。
++++抽象工厂模式是一个简单的模式,使用的场景非常多,在软件产品开发过程中,涉及不同操作系统的时候,都可以考虑使用抽象工厂模式。
++2.3.1、抽象工厂模式实现
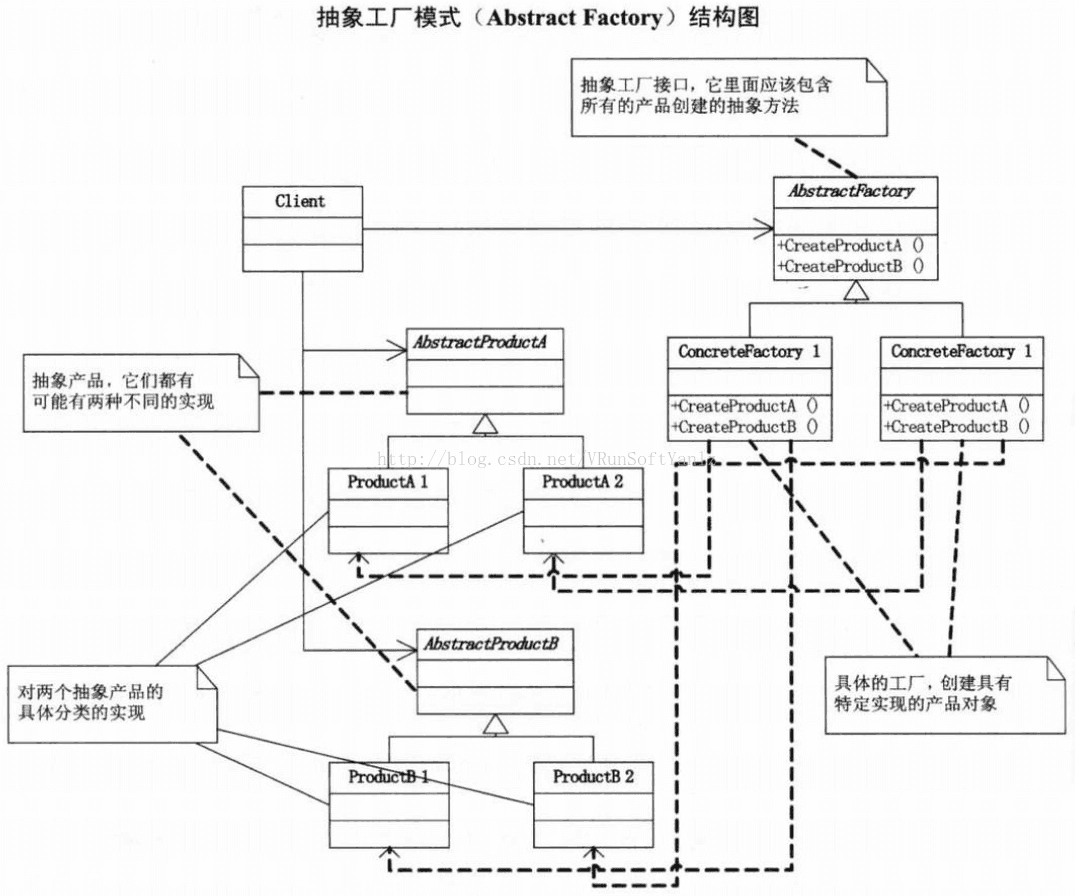
++++AbstractProductA和AbstractProductB是两个抽象产品。
++++ProductA1、ProductA2和ProductB1、ProductB2就是对两个抽象产品的具体分类的实现。
++++IFactory是一个抽象工厂接口,它里面应该包含所有的产品创建的抽象方法。
++++ConcreteFactory1和ConcreteFactory2就是具体的工厂。
++++通常是在运行时刻再创建一个ConcreteFactory类的实例,这个具体的工厂再创建具有特定实现的产品对象,也就是说,为创建不同的产品对象,客户端应使用不同的具体工厂。
++2.3.2、抽象工厂模式的优点与缺点
++++最大的好处便是易于交换产品系列,由于具体工厂类在一个应用中只需要在初始化的时候出现一次,这就使得改变一个应用的具体工厂变得非常容易,它只需要改变具体工厂即可使用不同的产品配置。
++++第二大好处是,抽象工厂让具体的创建实例过程与客户端分离,客户端是通过它们的抽象接口操纵实例,产品的具体类名也被具体工厂的实现分离,不会出现在客户代码中。
++++优点1:封装性,每个产品的实现类不是高层模块要关心的,它关心的是接口,是抽象,它不关心对象是如何创建出来,这是由工厂类负责,只要知道工厂类是谁,就能创建出一个需要的对象省时省力优秀设计就应该如此。
++++优点2:产品族内的约束为非公开状态。
++++缺点1:抽象工厂模式的最大缺点就是产品族扩展非常困难。(是产品族扩展比较困难,不是产品等级。在该模式下,产品等级是非常容易扩展的,增加一个产品等级,只要增加一个工厂类负责新增加出来的产品生产任务即可。也就是说横向扩展容易,纵向扩展困难。)
++2.3.3、抽象工厂模式的适用性:
++++A、一个系统要独立于它的产品的创建、组合和表示时。
++++B、一个系统由多个产品系列中的一个来配置时。
++++C、当你要强调一系列相关的产品对象的设计以便进行联合使用时。
++++D、当你提供一个产品类库,而只想显示它们的接口而不是实现时。
++++优点1: 它分离了具体的类。(Abstract Factory模式帮助我们控制一个应用创建的对象的类。因为一个工厂封装创建产品对象的责任和过程,它将客户与类的实现分离。客户通过它们的抽象接口操纵实例。产品的类名也在具体工厂的实现中被分离;它们不出现在客户代码中。)
++++优点2: 它使得易于交换产品系列。(一个具体工厂类在一个应用中仅出现一次,即在它初始化的时候。这使得改变一个应用的具体工厂变得很容易。它只需改变具体的工厂即可使用不同的产品配置,这是因为一个抽象工厂创建了一个完整的产品系列,所以整个产品系列会立刻改变。)
++++优点3: 它有利于产品的一致性。(当一个系列中的产品对象被设计成一起工作时,一个应用一次只能使用同一个系列中的对象,这一点很重要。而AbstractFactory很容易实现这一点。)
++++缺点1: 难以支持新种类的产品。(难以扩展抽象工厂以生产新种类的产品。这是因为AbstractFactory接口确定了可以被创建的产品集合。支持新种类的产品就需要扩展该工厂接口,这将涉及AbstractFactory类及其所有子类的改变。)
++++技术点1: 将工厂作为单例。(一个应用中一般每个产品系列只需一个ConcreteFactory的实例。因此工厂通常最好实现为一个Singleton。)
++++技术点2: 创建产品。(AbstractFactory仅声明一个创建产品的接口,真正创建产品是由ConcreteProduct子类实现的。最通常的一个办法是为每一个产品定义一个工厂方法。一个具体的工厂将为每个产品重定义该工厂方法以指定产品。虽然这样的实现很简单,但它却要求每个产品系列都要有一个新的具体工厂子类,即使这些产品系列的差别很小。)(如果有多个可能的产品系列,具体工厂也可以使用Prototype(原型)模式来实现。具体工厂使用产品系列中每一个产品的原型实例来初始化,且它通过复制它的原型来创建新的产品。在基于原型的方法中,使得不是每个新的产品系列都需要一个新的具体工厂类。)
++++技术点3: 定义可扩展的工厂。(AbstractFactory通常为每一种它可以生产的产品定义一个操作。产品的种类被编码在操作型构中。增加一种新的产品要求改变AbstractFactory的接口以及所有与它相关的类。一个更灵活但不太安全的设计是给创建对象的操作增加一个参数。该参数指定了将被创建的对象的种类。它可以是一个类标识符、一个整数、一个字符串,或其他任何可以标识这种产品的东西。实际上使用这种方法,AbstractFactory只需要一个“Make”操作和一个指示要创建对象的种类的参数。)
++2.3.4、相关模式
++++AbstractFactory类通常用工厂方法(FactoryMethod)实现,但它们也可以用Prototype实现。
++++一个具体的工厂通常是一个单件(Singleton)。
##2.4、建造者模式
++2.4、建造者模式
++++【建造者模式(Builder)】,将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
++++建造者模式是在当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时适用的模式。
++++建造者模式(Builder Pattern)也叫做生成器模式,其定义:Separate the construction of a complex object from its representation so that the same construction process can create different representations.(将一个复杂的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。)
++++建造者模式关注的是零件类型和装配工艺(顺序),这是它与工厂方法模式最大不同的地方,虽然同为创建类模式,但是注重点不同。(建造者模式最主要的功能是基本方法的调用顺序安排。)
++++在使用建造者模式的时候考虑一下模板方法模式,别孤立地思考一个模式,僵化地套用一个模式会让你受害无穷!
++2.4.1、建造者模式的实现
++++通常有一个抽象的Builder类为导向者可能要求创建的每一个构件定义一个操作。这些操作缺省情况下什么都不做。一个ConcreteBuilder类对它有兴趣创建的构建重定义这些操作。还要考虑的实现问题:
--A、装配和构造接口。(生成器逐步的构造它们的产品。因此Builder类接口必须足够普遍,以便为各种类型的具体生成器构造产品。)(一个关键的设计问题在于构造和装配过程的模型。构造请求的结果只是被添加到产品中,通常这样的模型就已足够了。(有时我们可能需要访问前面已经构造了的产品部件,在这种情况下,生成器将子结点返回给导向者,然后导向者将它们回传给生成者去创建父结点。)
--B、为什么产品没有抽象类。(通常情况下,由具体生成器生成的产品,它们的表示相差是如此之大以至于给不同的产品以公共父类没有太大意思。因为客户通常用合适的具体生成器来配置导向者,客户处于的位置使它知道Builder的哪一个具体子类被使用和能相应的处理它的产品。)
--C、在Builder中缺省的方法为空。(C++中,生成方法故意不声明为纯虚成员函数,而是把它们定义为空方法,这使客户只重定义他们所感兴趣的操作。)
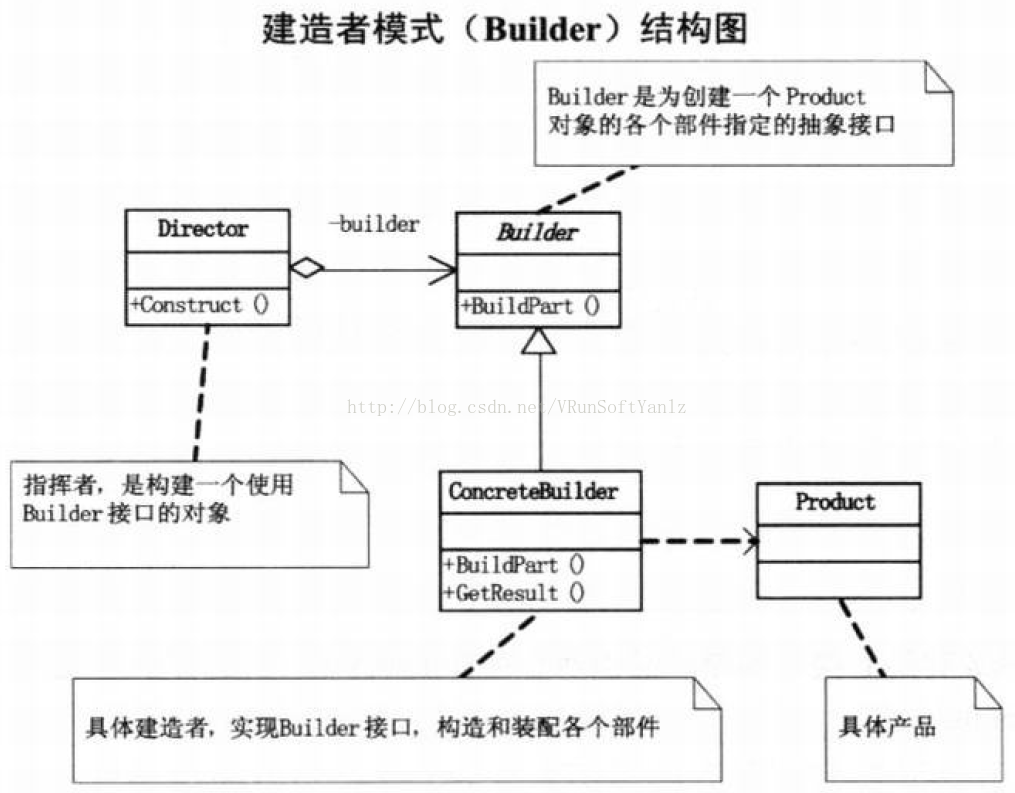
++++Builder是为创建一个Product对象的各个部件指定的抽象接口。
++++ConcreteBuilder是具体建造者,实现Builder接口,构造和装配各个部件。Product就是产品角色。
++++Director是指挥者,它是构建一个使用Builder接口的对象。主要是用于创建一些复杂的对象,这些对象内部构建间的建造顺序通常是稳定的,但对象内部的构建通常面临着复杂的变化。
++++建造者模式的好处就是使得建造代码与表示代码分离,由于建造者隐藏了该产品是如何组装的,所以若需要改变一个产品的内部表示,只需要再定义一个具体的建造者就可以了。
++2.4.2、建造者模式基本代码:
++++Product类: 产品类,由多个部件组成。
class Product{
List<string> parts = new List<string>();
//添加产品部件
public void Add(string part){
parts.Add(part)
}
public void Show(){
Console.WriteLine(“\nyanlz_tip:产品 创建----”);
foreach(string part in parts){
Console.WriteLine(part);
}
}
}
++++Builder类:抽象建造者类,确定产品由两个部件PartA和PartB组成,并声明一个得到产品建造后结果的方法GetResult:
abstract class Builder{
public abstract void BuildPartA();
public abstract void BuildPartB();
public abstract Product GetResult();
}
++++ConcreteBuilder 1类:具体建造者类
class ConcreteBuilder1 :Builder{
private Product product = new Product();
public override void BuildPartA(){
product.Add(“部件A”);
}
public override void BuildPartB(){
product.Add(“部件B”);
}
public override Product GetResult(){
return product;
}
}
++++ConcreteBuilder 2类:具体建造者类
class ConcreteBuilder2 :Builder{
private Product product = new Product();
public override void BuildPartA(){
product.Add(“部件X”);
}
public override void BuildPartB(){
product.Add(“部件Y”);
}
public override Product GetResult(){
return product;
}
}
++++Director类: 指挥者类
class Director{
public void Construct(Builder builder){
builder.BuildPartA();
builder.BuildPartB();
}
}
++++客户端代码,客户不需知道具体的建造过程:
static void Main(string[] args){
Director director = new Director();
Builder b1 = new ConcreteBuilder1();
Builder b2 = new ConcreteBuilder2();
//指挥者用ConcreteBuilder1的方法来建造产品
director.Construct(b1);
Product p1 = b1.GetResult();
p1.Show();
//指挥用ConcreteBuilder2的方法来建造产品
director.Construct(b2);
Product p2 = b2.GetResult();
p2.Show();
Console.Read();
}
++++建造者模式分析:
--A、Product产品类。(通常是实现了模板方法模式,也就是有模板方法和基本方法。)(表示被构造的复杂对象。ConcreteBuilder创建该产品的内部表示并定义它的装配过程。包含地很诡异组成部件的类,包括将这些部件装配成最终产品的接口。)
--B、Builder抽象建造者。(规范产品的组建,一般是由子类实现。)(为创建一个Product对象的各个部件指定抽象接口。)
--C、ConcreteBuilder具体建造者。(实现抽象类定义的所有方法,并且返回一个组建好的对象。)(实现Builder的接口以构造和装配该产品的各个部件。定义并明确它所创建的表示。提供一个检索产品的接口。)
--D、Director导演类。(负责安排已有模块的顺序,然后告诉Builder开始建造。)(构造一个使用Builder接口的对象。)
++2.4.3、建造者模式的优点:
++++优点1: 封装性。(使用建造者模式客户使客户端不必知道产品内部组成的细节。)
++++优点2: 建造者独立,容易扩展。
++++优点3: 便于控制细节风险。(由于具体的建造者是独立的,因此可以对建造过程逐步细化,而不对其他的模块产生任何影响。)
++2.4.4、建造者模式的使用场景:
++++适用性1: 当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时。
++++适用性2:当构造过程必须允许被构造的对象有不同的表示时。
++++场景A: 相同的方法,不同的执行顺序,产生不同的事件结果时,可以采用建造者模式。
++++场景B: 多个部件或零件,都可以装配到一个对象中,但是产生的运行结果又不相同时,则可以使用该模式。
++++场景C: 产品类非常复杂,或者产品类中的调用顺序不同产生了不同的效能,这个时候使用建造者模式非常合适。
++++场景D: 在对象创建过程中会使用到系统中的一些其他对象,这些对象在产品对象的创建过程中不易得到时,也可以采用建造者模式封装该对象的创建过程。(这种场景只能是一个补偿方法,因为一个对象不容易获得,而在设计阶段竟然没有发觉,而要通过创建者模式柔化创建过程,本身已经违反设计的最初目标。)
++2.4.5、建造者模式的协作分析:
++++下面说明了 Builder和Director是如何与一个客户协作的:
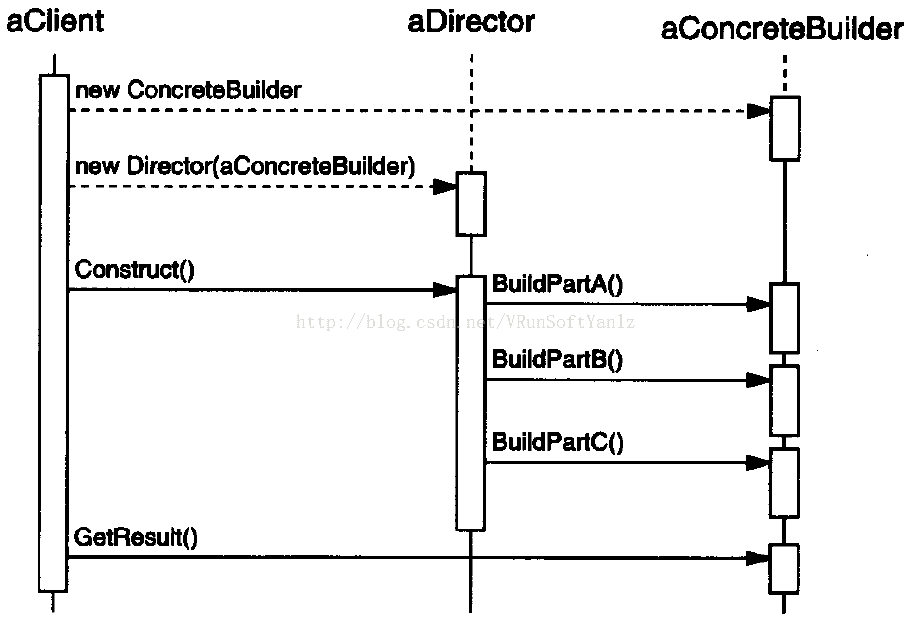
++++客户创建Director对象,并用它所想要的Builder对象进行配置。
++++一旦产品部件被生成,导向器就会通知生成器。
++++生成器处理导向器的请求,并将部件添加到该产品中。
++++客户从生成器中检索产品。
++2.4.6、建造者模式的主要效果:
++++效果1: 它使你可以改变一个产品的内部表示。(Builder对象提供给导向器一个构造产品的抽象接口。该接口使得生成器可以隐藏这个产品的表示和内部结构。它同时也隐藏了该产品是如何装配的。因为产品是通过抽象接口构造的,你在改变该产品的内部表示时所要做的只是定义一个新的生成器。)
++++效果2:它将构造代码和表示代码分开。(Builder模式通过封装一个复杂对象的创建和表示方式提高了对象的模块性。客户不需要知道定义产品内部结构的类的所有信息;这些类是不出现在Builder接口中的。每个ConcreteBuilder包含了创建和装配一个特定产品的所有代码。这些代码只需要写一次;然后不同的Director可以复用它以在相同部件集合的基础上构作不同的Product。)
++++效果3: 它使你可对构造过程进行更精细的控制。(Builder模式与一下子就生成产品的创建型模式不同,它是在导向者的控制下一步一步构造产品的。仅当该产品完成时导向者才从生成器中取回它。因此Builder接口相比其他创建型模式能更好的反映产品的构造过程。这使你可以更精细的控制构建过程,从而能更精细的控制所得产品的内部结构。)
++2.4.7、相关模式
++++AbstractFactory与Builder相似,因为它也可以创建复杂对象。主要的区别是Builder模式着重于一步步构造一个复杂对象。而AbstractFactory着重于多个系列的产品对象(简单的或是复杂的)。Builder在最后的一步返回产品,而对于AbstractFactory来说,产品是立即返回的。
++++Composite通常是用Builder生成的。
##2.5、原型模式
++2.5、原型模式
++++【原型模式(Prototype)】: 用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
++++原型模式(Prototype Pattern)的简单程度仅次于单例模式和迭代器模式。正是由于简单,使用的场景才非常地多,其定义:Specify the kinds of objects to create using a prototypical instance, and create new objects by copying this prototype.(用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。)
++++原型模式的核心是一个clone方法,通过该方法进行对象的拷贝。
++++在实际项目中,原型模式很少单独出现,一般是和工厂方法模式一起出现,通过clone的方法创建一个对象,然后由工厂方法提供给调用者。
++++原型模式先产生出一个包含大量共有信息的类,然后可以拷贝出副本,修正细节信息,建立了一个完整的个性对象。(原型模式就是由一个正本可以创建多个副本的概念: 一个对象的产生可以不由零起步,直接从一个已经具备一定雏形的对象克隆,然后再修改为生产需要的对象。)
++++用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
++++当一个系统应该独立于它的产品创建、构成和表示时,要使用Prototype模式;以及当要实例化的类是运行时刻指定时,例如,通过动态装载;或者为了避免创建一个与产品类层次平行的工厂类层次时;或者当一个类的实例只能有几个不同状态组合中的一种时。建立相应数目的原型并克隆它们可能比每次用合适的状态手工实例化该类更方便一些。
++2.5.1、原型模式的实现
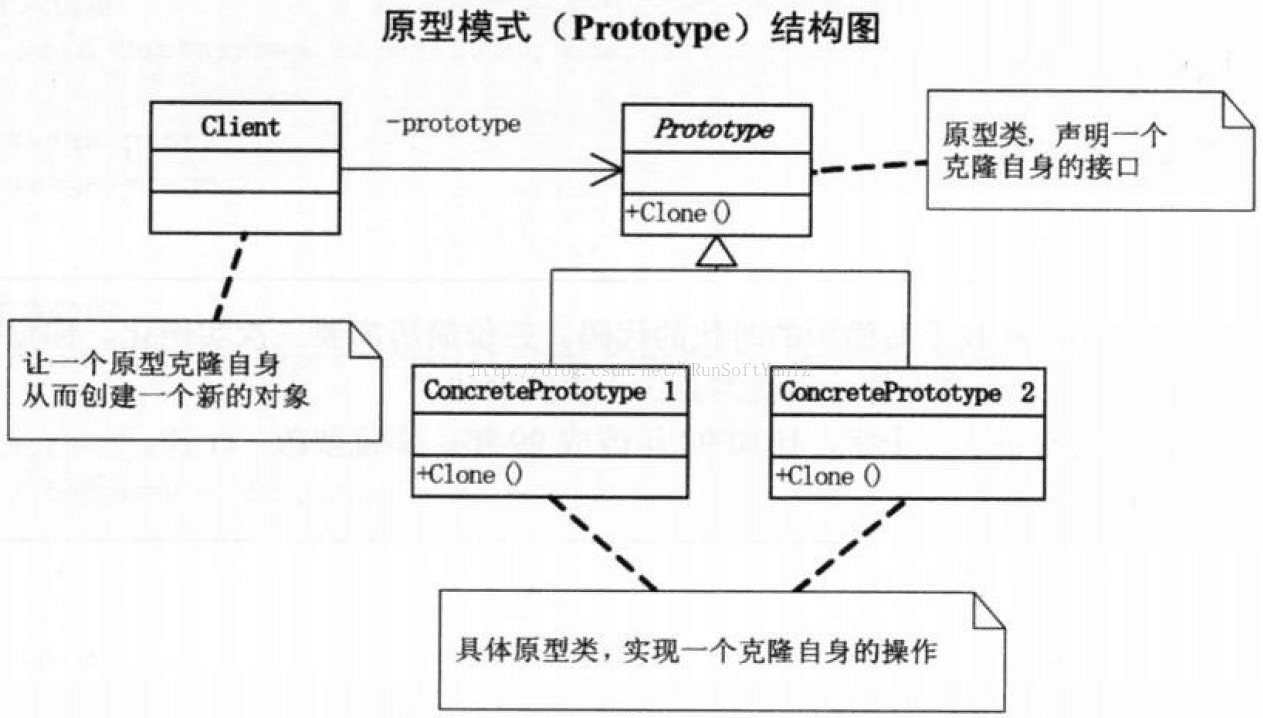
++++原型模式其实就是从一个对象再创建另外一个可定制的对象,而且不需知道任何创建的细节。
++++一般在初始化的信息不发生变化的情况下,克隆是最好的办法。(这既隐藏了对象创建的细节,又对性能是大大的提高。)(不用重新初始化对象,而是动态地获得对象运行时的状态。)
++++Prototype:声明一个克隆自身的接口。
++++ConcretePrototype: 实现一个克隆自身的操作。
++++Client: 让一个原型克隆自身从而创建一个新的对象。
++++客户请求一个原型克隆自身。
++2.5.2、原型模式代码
++++原型类:
abstract class Prototype{
private string id;
public Prototype(string id){
this.id = id;
}
public string Id{
get{ return id; }
}
//抽象类关键就是有这样一个Clone方法
public abstract Prototype Clone();
}
++++具体原型类:
class ConcretePrototype1 :Prototype{
public ConcretePrototype1(string id) :base(id){
}
public override Prototype Clone(){
return (Prototype)this.MemeberwiseClone();
//创建当前对象的浅表副本。方法是创建一个新对象,然后将当前对象的非静态字段复制到该新对象。如果字段是值类型的,则对该字段执行逐位复制。如果字段是引用类型,则复制引用但不复制引用的对象;因此,原始对象及其副本引用同一对象。
}
}
++++客户端代码:
static void Main(string[] args){
ConcretePrototype1 p1= new ConcretePrototype1(“I”);
//克隆类ConcretePrototype1的对象p1就能得到新的实例c1
ConcretePrototype1 c1= (ConcretePrototype1)p1.Clone();
Console.WriteLine(“yanlzPrint: Cloned: {0}”, c1.Id);
Console.Read();
}
++++说明:对于.NET而言,那个原型抽象类Prototype是用不着的,因为克隆实在是太常用了,所以.NET在System命名空间中提供了ICloneable接口,其中就是唯一的一个方法Clone(),这样我们只需要实现这个接口就可以完成原型模式了。
++2.5.3、浅复制与深复制
++++MemberwiseClone()方法是这样的,如果字段是值类型的,则对该字段执行逐位复制,如果字段是引用类型,则复制引用但不复制引用的对象;因此,原始对象及其复本引用同一对象。
++++浅复制,被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用都仍然指向原来的对象。(把要复制的对象所引用的对象都复制一遍。)
++++深复制把引用对象的变量指向复制过的新对象,而不是原有的被引用的对象。
++2.5.4、原型模式的优点:
++++优点1: 性能优良。(原型模式是在内存二进制流的拷贝,要比直接new一个对象性能好很多,特别是要在一个循环体内产生大量的对象时,原型模式可以更好地体现其优点。)
++++优点2:逃避构造函数的约束。(这既是它的优点也是缺点,直接在内存中拷贝,构造函数是不会执行的。优点就是减少了约束,缺点也是减少了约束,在实际应用时注意。)
++2.5.5、原型模式的使用场景:
++++场景1:资源优化场景。(类初始化需要消化非常多的资源,这个资源包括数据、硬件资源等。)
++++场景2:性能和安全要求的场景。(通过new产生一个对象需要非常繁琐的数据准备货访问权限,则可以使用原型模式。)
++++场景3:一个对象多个修改者的场景。(一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可以考虑使用原型模式拷贝多个对象供调用者使用。)
++++原型模式的注意事项:
--注意1:构造函数不会被执行。(对象拷贝不会执行构造函数,Object类的clone方法的原理是从内存中(具体地说就是堆内存),以二进制流的方式进行拷贝,重新分配一个内存块,那构造函数没有被执行也是非常正常的了。)
--注意2: 浅拷贝和深拷贝。(Object类提供的方法clone只是拷贝本对象,其对象内部的数组、引用对象等都不拷贝,还是指向原生对象的内部元素地址。)(浅拷贝是有风险的。)(深拷贝和浅拷贝不要混合使用,特别是在涉及类的继承时,父类有多个引用的情况就非常复杂,建议的方案是深拷贝和浅拷贝分开实现。)
--注意3:使用原型模式时,引用的成员变量必须满足两个条件才不会被拷贝:一是类的成员变量,而不是方法内变量;二是必须是一个可变的引用对象,而不是一个原始类型或不可变对象。
--注意4:clone与final两个冤家。(对象的clone与对象内的final关键字是有冲突的。)(删除掉final关键字,这是最便捷、安全、快捷的方式。要使用clone方法,在类的成员变量上就不要增加final关键字。)
++2.5.6、Prototype原型模式的优点:
++++优点1:Prototype有许多AbstractFactory和Builder一样的效果: 它对客户隐藏了具体的产品类,因此减少了客户知道的名字的数目。(这些模式使客户无需改变即可使用与特定应用相关的类。)
++++优点2: 运行时刻增加和删除产品。(Prototype允许只通过客户注册原型实例就可以将一个新的具体产品类并入系统。它比其他创建型模式更为灵活,因为客户可以在运行时刻建立和删除原型。)
++++优点3:改变值以指定新对象。(高度动态的系统允许你通过对象复合定义新的行为,例如,通过为一个对象变量指定值,并且不定义新的类。)(通过实例化已有类并且将这些实例注册为客户对象的原型,就可以有效定义新类别的对象。客户可以将职责代理给原型,从而表现出新的行为。)(这种设计使得用户无需编程即可定义新“类”。实际上,克隆一个原型类似于实例化一个类。Prototype模式可以极大的减少系统所需要的类的数目。)
++++优点4:改变结构以指定新对象。(许多应用由部件和子部件来创建对象。为方便起见,这样的应用通常允许实例化复杂的、用户定义的结构。)
++++优点5:减少子类的构造。(FactoryMethod经常产生一个与产品类层次平行的Creator类层次。Prototype模式使得你克隆一个原型而不是请求一个工厂方法去产生一个新的对象。)
++++优点6:用类动态配置应用。(一些运行时刻环境允许你动态将类装载到应用中。Prototype模式是利用这种功能的关键。)(一个希望创建动态载入类的实例的应用不能静态引用类的构造器。而应该由运行环境在载入时自动创建每个类的实例,并用原型管理器来注册这个实例。这样应用就可以向原型管理器请求新装载的类的实例,这些类原本并没有和程序相连接。)
++++缺点1:Prototype的主要缺陷是每一个Prototype的子类都必须实现Clone操作,这可能很困难。(例如,当所考虑的类已经存在时就难以新增Clone操作。当内部包括一些不支持拷贝或有循环引用的对象时,实现克隆可能也会很困难的。)
++2.5.7、实现原型模式时,要考虑的问题:
++++问题1:使用一个原型管理器。(当一个系统中原型数目不固定时(也就是说,它们可以动态创建和销毁),要保持一个可用原型的注册表。客户不会自己来管理原型,但会在注册表中存储和检索原型。客户在克隆一个原型前会向注册表请求该原型。我们称这个注册表为原型管理器(prototype manager)。)(原型管理器是一个关联存储器(associatie store),它返回一个与给定关键字相匹配的原型。它有一些操作可以用来通过关键字注册原型和解除注册。客户可以在运行时更改甚至或浏览这个注册表。这使得客户无需编写代码就可以扩展并得到系统清单。)
++++问题2:实现克隆操作。(Prototype模式最困难的部分在于正确实现Clone操作。当对象结构包含循环引用时,这尤为棘手。)(大多数语言都对克隆对象提供了一些支持。例如,C++提供了一个拷贝构造器。但这些设施并不能解决“浅拷贝和深拷贝”问题: 克隆一个对象时依次克隆它的实例变量呢,或者还是由克隆对象和原对象共享这些变量?)(浅拷贝简单并且通常也足够了。C++中的缺省拷贝构造器实现按成员拷贝,这意味着在拷贝的和原来的对象之间是共享指针的。但克隆一个结构复杂的原型通常需要深拷贝,因为复制对象和原对象必须相互独立。因此你必须保证克隆对象的构件也是对原型的构件的克隆。)
++++问题3:初始化克隆对象。(当一些客户对克隆对象已经相当满意时,另一些客户将会希望使用他们所选择的一些值来初始化该对象的一些或是所有的内部状态。一般来说不可能在Clone操作中传递这些值,因为这些值的数目由于原型的类的不同而会有所不同。一些原型可能需要多个初始化参数,另一些可能什么也不要。在Clone操作中传递参数会破坏克隆接口的统一性。)(注意深拷贝Clone操作,一些复制在你重新初始化它们之前可能必须要被删除掉(删除可以显式地做也可以在Initialize内部做。))
++2.5.8、相关模式
++++Prototype和AbstractFactory模式在某种方面是相互竞争的。但是它们也可以一起使用。AbstractFactory可以存储一个被克隆的原型的集合,并且返回产品对象。
++++大量使用Composite和Decorator模式的设计通常也可从Prototype模式处获益。
##2.6、适配器模式
++2.6、适配器模式
++++适配器模式(Adapter):将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的哪些类可以一起工作。
++++系统的数据和行为都正确,但接口不符时,我们应该考虑用适配器,目的是使控制范围之外的一个原有对象与某个接口匹配。(适配器模式主要应用于希望复用一些显存的类,但是接口又与复用环境要求不一致的情况。)
++++适配器模式主要两种类型: 类适配器模式和对象适配器模式。(类适配器是类间继承,对象适配器是对象的合成关系,也可以说是类的关联关系,这是两者的根本区别。)(二者在实际项目中都会经常用到,由于对象适配器是通过类间的关联关系进行耦合的,因此在设计时就可以做到比较灵活,比如修补源角色的隐形缺陷,关联其他对象等,而类适配器就只能通过覆写源角色的方法进行扩展,在实际项目中,对象适配器使用的场景相对较多。)
++++使用一个已经存在的类,但如果它的接口,也就是它的方法和你的要求不相同时,就应该考虑用适配器模式。(两个类所做的事情相同或相似,但是具有不同的接口时要使用它。)(客户代码可以统一调用同一接口,可以更简单、更直接、更紧凑。)(在双方都不太容易修改的时候再使用适配器模式适配。)
++++适配器模式(Adapter Pattern)的定义:Convert the interface of a class into another interface clients export. Adapter lets classes work together that couldn’t otherwise becasue of incompatible interfaces.(将一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。)
++++适配器模式又叫做变压器模式,也叫做包装模式(Wrapper),但是包装模式可不止一个,还包括装饰模式。(适配器模式就是把一个接口或类转换成其他的接口或类,从另一方面来说,适配器模式也就是一个包装模式。)
++++适配器应用的场景:有动机修改一个已经投产中的接口时,适配器模式可能是最适合的模式。(比如系统扩展了,需要使用一个已有或新建立的类,但这个类又不符合系统的接口,可以使用适配器模式。)
++++适配器模式最好在详细设计阶段不要考虑它,它不是为了解决还处在开发阶段的问题,而是解决正在服役的项目问题,没有一个系统分析师会在做详细设计的时候考虑使用适配器模式,这个模式使用的主要场景是扩展应用中。(系统扩展了,不符合原有设计的时候才考虑通过适配器模式减少代码修改带来的风险。)
++++提示: 项目一定要遵守依赖倒置原则和里氏替换原则,否在即使在适合使用适配器的场合下,也会带来非常大的改造。
++++适配器模式是一个补偿模式,或者说是一个“补救”模式,通常用来解决接口不相容的问题,在百分之百的完美设计中是不可能使用到的。(不管系统设计得多么完美,都无法逃避新业务的发生,技术只是一个工具而已,是因为它推动了其他行业的进步和发展而具有了价值。)
++++Adapter适配器的意图: 将一个类的接口转换成客户希望的另外一个接口。(Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。)
++++Adapter模式的适用性: 想使用一个已经存在的类,而它的接口不符合你的要求。想创建一个可以复用的类,该类可以与其他不相关的类或不可预见的类(即那些接口可能不一定兼容的类)协同工作。想使用一些已经存在的子类,但是不可能对每一个都进行子类化以匹配它们的接口(仅适用于对象Adapter,对象适配器可以适配它的父类接口)。
++2.6.1、适配器模式实现
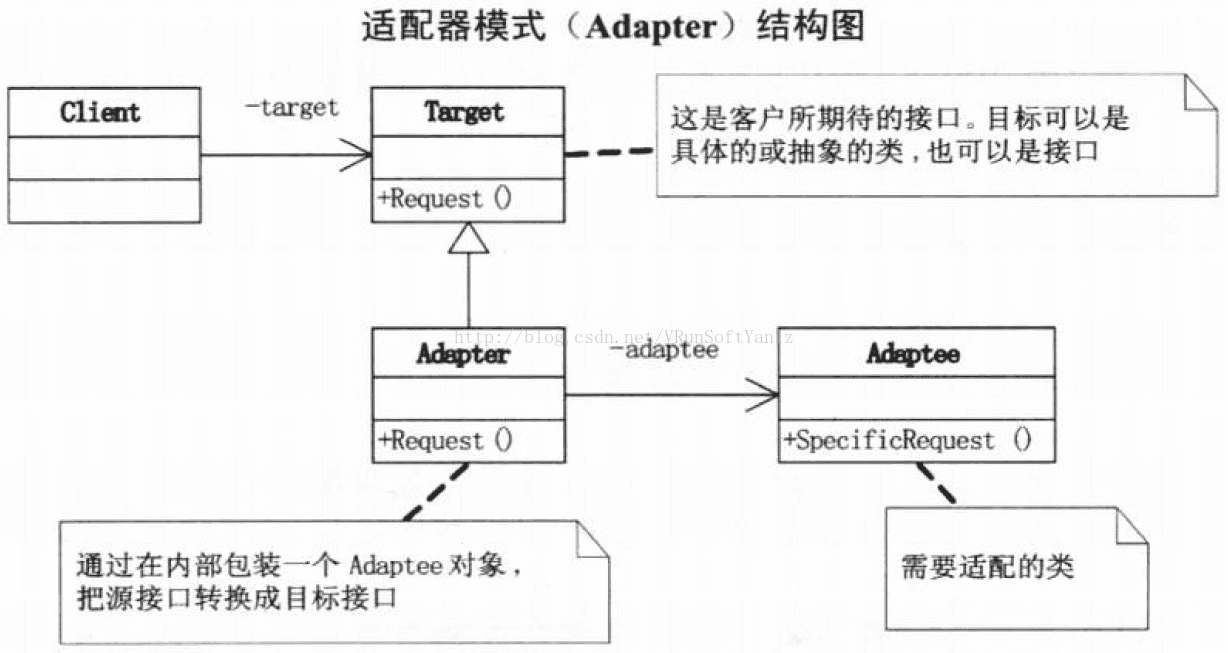
++++Target目标角色。(定义Client使用的特定领域相关的接口。)(该角色定义把其他类转换为何种接口,也就是我们的期望接口。)
++++Client。(与符合Target接口的对象协同。)
++++Adaptee源角色。(定义一个已经存在的接口,这个接口需要适配。)(想把谁转换成目标角色,谁就是源角色,它是已经存在的、运动良好的类或对象,经过适配器角色的包装,它会成为一个崭新、靓丽的角色。)
++++Adapter适配器角色。(对Adaptee的接口与Target接口进行适配。)(适配器模式的核心角色,其他两个角色都是已经存在的角色,而适配器角色是需要新建立的,它的职责非常简单:把源角色转换为目标角色,通过继承或是类关联的方式。)
++++协作: Client在Adapter实例上调用一些操作。(接着适配器调用Adaptee的操作实现这个请求。)
++2.6.2、适配器模式代码:
++++Target(这是客户所期待的接口。目标可以是具体的或抽象的类,也可以是接口):
class Target{
public virtual void Request(){
Console.WriteLine(“yanlzPrint:----普通请求!”);
}
}
++++Adaptee(需要适配的类):
class Adaptee{
public void SpecificRequest(){
Console.WriteLine(“yanlzPrint:----特殊请求!”);
}
}
++++Adapter(通过在内部包装一个Adaptee对象,把源接口转换成目标接口):
class Adapter :Target{
//建立一个私有的Adaptee对象
private Adaptee adaptee = new Adaptee();
public override void Request(){
//这样就可把表面上调用Request()方法变成实际调用SpecificRequest()
adaptee.SpecificRequest();
}
}
++++客户端代码:
static void Main(string[] args){
Target target = new Adapter();
target.Request();
//对客户端来说,调用的就是Target的Request()
Console.Read();
}
++2.6.3、适配器模式的.NET应用
++++在.NET中有一个类库已经实现的、非常重要的适配器,那就是DataAdapter。
++++DataAdapter用作DataSet和数据源之间的适配器以便检索和保存数据。
++++DataAdapter通过映射Fill(这更改了DataSet中的数据以便于数据源中的数据相匹配)和Update(这更改了数据源中的数据以便与DataSet中的数据相匹配)来提供这一适配器。(由于数据源可能是来自SQL Server,可能来自Oracle,也可能来自Access、DB2,这些数据在组织上可能有不同之处,但我们希望得到统一的DataSet(实质是XNL数据),此时用DataAdapter就是非常好的手段,我们不必关注不同数据库的数据细节,就可以灵活的使用数据。)
++2.6.4、适配器模式的优点
++++优点1:适配器模式可以让两个没有任何关系的类在一起运行,只要适配器这个角色能够搞定他们就成。
++++优点2:增加了类的透明性。(我们访问的Target目标角色,但是具体的实现都委托给了源角色,而这些对高层次模块是透明的,也是它不需要关心的。)
++++优点3:提高了类的复用度。(源角色在原有的系统中还是可以正常使用,而在目标角色中也可以充当新的演员。)
++++优点4:灵活性非常好。(如果不想要适配器了,删除掉就可以了,其他的代码都不用修改,基本上就类似一个灵活的构件,想用就用,不想就卸载。)
++2.6.5、适配器使用(类适配器和对象适配器)
++++A、类适配器:
--用一个具体的Adapter类对Adaptee和Target进行匹配。(结果是当我们想要匹配一个类以及所有它的子类时,类Adapter将不能胜任工作。)
--使得Adatper可以重定义Adaptee的部分行为,因为Adapter是Adaptee的一个子类。
--仅仅引入了一个对象,并不需要额外的指针以间接得到adaptee。
++++B、对象适配器:
--允许一个Adapter与多个Adaptee,即Adaptee本身以及它的所有子类(如果有子类的话),同时工作。(Adapter也可以一次给所有的Adaptee添加功能。)
--使得重定义Adaptee的行为比较困难。(这就需要生成Adaptee的子类并且使得Adapter引用这个子类而不是引用Adaptee本身。)
++++使用Adapter模式时需要考虑的其他因素:
--1)Adapter的匹配程度。(对Adaptee的接口与Target的接口进行匹配的工作量各个Adapter可能不一样。工作范围可能是,从简单的接口转换(例如改变操作名)到支持完全不同的操作集合。)(Adapter的工作量取决于Target接口与Adaptee接口的相似程度。)
--2)可插入的Adapter。(当其他的类使用一个类时,如果所需的假定条件越少,这个类就更具可复用性。如果将接口匹配构建为一个类,就不需要假定对其他的类可见的是一个相同的接口。)(接口匹配使得我们可以将自己的类加入到一些现有的系统中去,而这些系统对这个类的接口可能会有所不同。)
--3)使用双向适配器提供透明操作。(使用适配器的一个潜在问题是,它们不对所有的客户都透明。)(被适配的对象不再兼容Adaptee的接口,因此并不是所有Adaptee对象可以被使用的地方它都可以被使用。)(双向适配器提供了这样的透明性。)(在两个不同的客户需要用不同的方式查看同一个对象时,双向适配器尤其有用。)
++2.6.6、Adapter模式的实现及注意事项
++++实现1:使用C++实现适配器类。(在使用C++实现适配器类时,Adapter类应该采用公共方式继承Target类,并且用私有方式继承Adaptee类。因此,Adapter类应该是Target的子类型,但不是Adaptee的子类型。)
++++实现2:可插入的适配器。(有许多方法可以实现可插入的适配器。)
--方法1:使用抽象操作。(由子类来实现这些抽象操作并匹配具体的树结构的对象。)
--方法2:使用代理对象。(在C++这样的静态类型语言中,需要一个代理的显式接口定义。然后运用继承机制将这个接口融合到所选择的代理中。)
--方法3:参数化的适配器。(用一个或多个模块对适配器进行参数化。模块构造支持无子类化的适配。一个模块可以匹配一个请求,并且适配器可以为每个请求存储一个模块。)
++++补充1:类适配器采用多重继承适配接口。(类适配器的关键是用一个分支继承接口,而用另外一个分支继承接口的实现部分。通常C++中作出这一区分的方法是:用公共方式继承接口;用私有方式继承接口的实现。)
++++补充2:对象适配器采用对象组合的方法将具有不同接口的类组合在一起。
++2.6.7、相关模式
++++模式Bridge的结构与对象适配器类似,但是Bridge模式的出发点不同:Bridge目的是将接口部分和实现部分分离,从而对它们可以较为容易也相对独立的加以改变。而Adapter则意味着改变一个已有对象的接口。
++++Decorator模式增强了其他对象的功能而同时又不改变它的接口。因此decorator对应用程序的透明性比适配器要好。结果是decorator支持递归组合,而纯粹使用适配器是不可能实现这一点的。
++++模式Proxy在不改变它的接口的条件下,为另一个对象定义了一个代理。
##2.7、装饰模式
++2.7、装饰模式
++++【装饰模式(Decorator)】:动态地给一个对象添加一些额外的职责,就增加功能来说,装饰模式比生成子类更为灵活。
++++装饰模式是为已有功能动态地添加更多功能的一种方式。(当系统需要新功能的时候,是向旧的类中添加新的代码。这些新加的代码通常装饰了原有类的核心职责或主要行为。)(在主类中加入了新的字段,新的方法和新的逻辑,从而增加了主类的复杂度,而这些新加入的东西仅仅是为了满足一些只在某种特定情况下才会执行的特殊行为的需要。装饰模式提供了一个非常好的解决方案,它把每个要装饰的功能放在单独的类中,并让这个类包装它所要装饰的对象,因此,当需要执行特殊行为时,客户代码就可以在运行时根据需要有选择地、按顺序地使用装饰功能包装对象了。)
++++装饰模式的优点:把类中的装饰功能从类中搬移去除,这样可以简化原有的类。(有效地把类的核心职责和装饰功能区分开了。而且可以去除相关类中重复的装饰逻辑。)
++++装饰模式(Decorator Pattern)是一种比较常见的模式,定义:Attach additional responsibilities to an object dynamically keeping the same interface. Decorators provide a flexible alternative to subclassing for extending functionality.(动态地给一个对象添加一些额外的职责。就增加功能来说,装饰模式相比生成子类更为灵活。)
++++装饰模式是对继承的有力补充。(继承不是万能的,继承可以解决实际的问题,但是在项目中要考虑诸如易维护、易扩展、易复用等,在一些情况下要是用继承就会增加很多子类,而且灵活性非常差,维护也不容易,也就是说,装饰模式可以替代继承,解决我们类膨胀的问题。)(继承是静态地给类增加功能,而装饰模式则是动态地增加功能。)
++++装饰模式有一个非常好的优点:扩展性非常好。
++++Decorator装饰模式的意图:动态地给一个对象添加一些额外的职责。(新增加功能来说,Decorator模式相比生成子类更为灵活。)
++2.7.1、装饰模式的实现
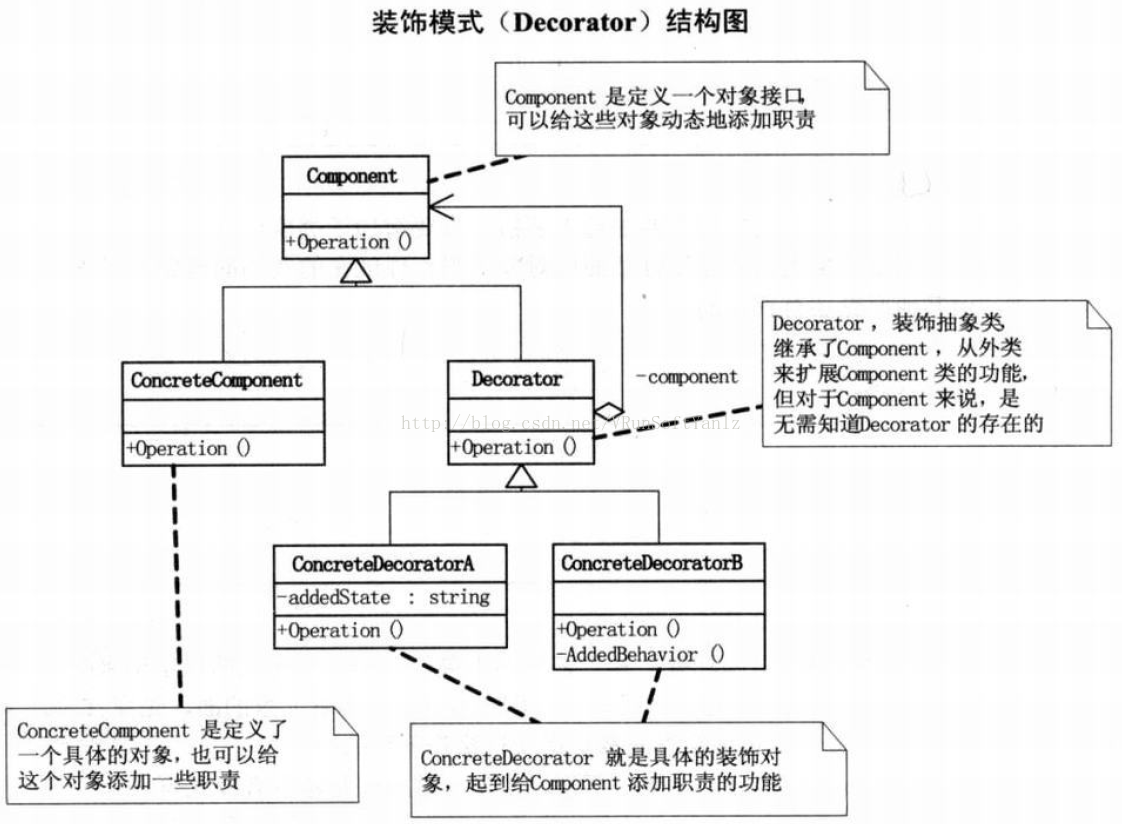
++++Component是定义一个对象接口,可以给这些对象动态地添加职责。(抽象构件,是一个接口或者是抽象类,就是定义我们最核心的对象,也就是最原始的对象。)(在装饰模式中,必然有一个最基本、最核心、最原始的接口或抽象类充当Component抽象构件。)(定义一个对象接口,可以给这些对象动态地添加职责。)
++++ConcreteComponent是定义了一个具体的对象,也可以给这个对象添加一些职责。(具体构件,是最核心、最原始、最基本的接口或抽象类的实现,我们要装饰的就是它。)(定义一个对象,可以给这个对象添加一些职责。)
++++Decorator,装饰抽象类,继承了Component,从外类来扩展Component类的功能,但对于Component来说,是无需知道Decorator的存在的。(装饰角色,一般是一个抽象类,实现接口或者抽象方法,它里面可不一定有抽象的方法,在它的属性里必然有一个private变量指向Component抽象构件。)(维持一个指向Component对象的指针,并定义一个与Component接口一致的接口。)
++++ConcreteDecorator就是具体的装饰对象,起到给Component添加职责的功能。(具体装饰角色,ConcreteDecoratorA和ConcreteDecoratorB是两个具体的装饰类,我们要把最核心的、最原始的、最基本的东西装饰成其他东西。)(向组件添加职责。)
++++原始方法和装饰方法的执行顺序在具体的装饰类是固定的,可以通过方法重载实现多种执行顺序。
++2.7.2、装饰模式的代码
++++Component类:
abstract class Component{
public abstract void Operation();
}
++++ConcreteComponent类:
class ConcreteComponent :Component{
public override void Operation(){
Console.WriteLine(“yanlzPrint:----具体对象的操作”);
}
}
++++Decorator类
abstract class Decorator:Component{
protected Component component;
//设置Component
public void SetComponent(Component component){
this.component = component;
}
//重写Operation(),实际执行的是Component的Operation()
public override void Operation(){
if(component != null){
component.Operation();
}
}
}
++++ConcreteDecoratorA类
class ConcreteDecoratorA :Decorator{
//本类的独有功能,以区别于ConcreteDecoratorB
private string addedState;
public override void Operation(){
//首先运行原Component的Operation(),再执行本类的功能,如addedState,相当于对原Component进行了装饰。
base.Operation();
addedState = “New State”;
Console.WriteLine(“具体装饰对象A的操作”);
}
}
++++ConcreteDecoratorB类
class ConcreteDecoratorB :Deorator{
public override void Operation(){
//首先运行原Component的Operation(),再执行本类的功能,如AddedBehaviour(),相当于对原Component进行了装饰
base.Operation();
AddedBehaviour();
Console.WriteLine(“yanlzPrint:----具体装饰对象B的操作”);
}
//本类独有的方法,以区别于ConcreteDecoratorB
private void AddedBehaviour(){}
}
++++客户端代码:
static void Main(string[] args){
ConcreteComponent c = new ConcreteComponent();
ConcreteDecoratorA d1 = new ConcreteDecoratorA();
ConcreteDecoratorB d2 = new ConcreteDecoratorB();
//装饰的方法是: 首先用ConcreteComponent实例化对象c,然后用ConcreteDecoratorA的实例化对象d1来包装c,再用ConcreteDecoratorB的对象d2包装d1,最终执行d2的Operation()
d1.SetComponent(c);
d2.SetComponent(d1);
d2.Operation();
Console.Read();
}
++++分析1:装饰模式是利用SetComponent来对对象进行包装的。(每个装饰对象的实现就是和如何使用这个对象分离开了,每个装饰对象只关心自己的功能,不需要关心如何被添加到对象链当中。)
++++分析2:如果只有一个ConcreteComponent类而没有抽象的Component类,那么Decorator类可以是ConcreteComponent的一个子类。(同理,如果只有一个ConcreteDecorator类,那么就没有必要建立一个单独的Decorator类,而可以把Decorator和ConceteDecorator的责任合并成一个类。)
++2.7.3、装饰模式的应用
++++A、装饰模式的优点:
--优点1:装饰类和被装饰类可以独立发展,而不会相互耦合。(Component类无须知道Decorator类,Decorator类是从外部来扩展Component类的功能,而Decorator也不用知道具体的构件)
--优点2:装饰模式是继承关系的一个替代方案。(装饰类Decorator,不管装饰多少层,返回的对象还是Component,实现的还是is-a的关系。)
--优点3:装饰模式可以动态地扩展一个实现类的功能。
++++B、装饰模式的缺点:
--缺点1:多层的装饰是比较复杂的。(尽量减少装饰类的数量,以便降低系统的复杂度。)
++++C、装饰模式的使用场景:
--场景1:需要扩展一个类的功能,或给一个类增加附加功能。
--场景2:需要动态地给一个对象增加功能,这些功能可以再动态地撤销。
--场景3:需要为一批的兄弟类进行改装或加装功能,当然是首先装饰模式。
++++D、适用性,以下情况可使用Decorator模式:
--情况1:在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责。
--情况2:处理那些可以撤销的职责。
--情况3:当不能采用生成子类的方法进行扩充时。(一种情况是,可能有大量独立的扩展,为支持每一种组合将产生大量的子类,使得子类数目呈爆发性增长。另一种情况可能是因为类定义被隐藏,或类定义不能用于生成子类。)
++2.7.4、Decorator装饰模式的优缺点
++++优点1:比静态继承更灵活。(与对象的静态继承(多重继承)相比,Decorator模式提供了更加灵活的向对象添加职责的方式。可以用添加和分离的方式,用装饰在运行时刻增加和删除职责。)(相比之下,继承机制要求为每个添加的职责创建一个新的子类。这会产生许多新的类,并且会增加系统的复杂度)(此外,为一个特定的Component类提供多个不同的Decorator类,这就使得我们可以对一些职责进行混合和匹配。)(使用Decorator模式可以很容易地重复添加一个特性。)
++++优点2:避免在层次结构高层的类有太多的特征。(Decorator模式提供了一种“即用即付”的方法来添加职责。它并不试图在一个复杂的可定制的类中支持所有可预见的特征,相反,我们可以定义一个简单的类,并且用Decorator类给它逐渐地添加功能。可以从简单的部件组合出复杂的功能。这样,应用程序不必为不需要的特征付出代价。同时也更易于不依赖于Decorator所扩展(甚至是不可预知的扩展)的类而独立地定义新类型的Decorator。扩展一个复杂类的时候,很可能会暴露与添加的职责无关的细节。)
++++缺点1:Decorator与它的Component不一样。(Decorator是一个透明的包装。如果我们从对象标识的观点出发,一个被装饰了的组件与这个组件是由差别的,因此,使用装饰时不应该依赖对象标识。)
++++缺点2:有许多小对象。(采用Decorator模式进行系统设计往往会产生许多看上去类似的小对象,这些对象仅仅在他们相互连接的方式上有所不同,而不是它们的类或是它们的属性值有所不同。尽管对于那些了解这些系统的人来说,很容易对它们进行定制,但是很难学习这些系统,排错也很困难。)
++2.7.5、使用Decorator装饰模式时注意点
++++注意点1:接口的一致性。(装饰对象的接口必须与它所装饰的Component的接口是一致的,因此,所有的ConcreteDecorator类必须有一个公共的父类(至少在C++中如此))。
++++注意点2:省略抽象的Decorator类。(当我们仅需要添加一个职责时,没有必要定义抽象Decorator类。常常需要处理现存的类层次结构而不是设计一个新系统,这是可以把Decorator向Component转发请求的职责合并到ConcreteDecorator中。)
++++注意点3:保持Component类的简单性。(为了保证接口的一致性,组件和装饰必须有一个公共的Component父类。因此保持这个类的简单性是很重要的,即,它应集中于定义接口而不是存储数据。对数据表示的定义应延迟到子类中,否则Component类会变得过于复杂和庞大,因而难以大量使用。赋予Component太多的功能也使得,具体的子类有一些它们并不需要的功能的可能性大大增加。)
++++注意点4:改变对象外壳与改变对象内核。(我们可以将Decorator看做一个对象的外壳,它可以改变这个对象的行为。另外一种方法是改变对象的内核。)
++2.7.6、相关模式
++++Adapter模式:Decorator模式不同于Adapter模式,因为装饰仅改变对象的职责而不改变它的接口;而适配器将给对象一个全新的接口。
++++ Composite模式:可以将装饰视为一个退化的、仅有一个组件的组合。然而,装饰仅给对象添加一些额外的职责,它的目的不在于对象聚集。
++++Strategy模式:用一个装饰可以改变对象的外表;而Strategy模式使得可以改变对象的内核。这是改变对象的两种途径。
##2.8、桥接模式
++2.8、桥接模式
++++【桥接模式(Bridge)】:将抽象部分与它的实现部分分离,使它们都可以独立地变化。(什么叫抽象与它的实现分离,这并不是说,让抽象类与其派生类分离,因为这没有任何意义。实现指的是抽象类和它的派生类用来实现自己的对象。)
++++桥接模式(Bridge Pattern),是一个比较简单的模式,定义:Decouple an abstraction from its implementation so that the two can very independently.(将抽象和实现解耦,使得两者可以独立地变化。)
++++桥梁模式的重点是在“解耦”上,如何让它们两者解耦是我们要了解的重点。
++++桥梁模式是非常简单的,使用该模式时主要考虑如何拆分抽象和实现,并不是一涉及继承就要考虑使用该模式。(桥梁模式的意图还是对变化的封装,尽量把可能变化的因素封装到最细、最小的逻辑单元中,避免风险扩散。在进行系统设计时,发现类的继承有N层时,可以考虑使用桥梁模式。)
++++Bridge桥接的意图:将抽象部分与它的实现部分分离,使它们都可以独立地变化。
++++Bridge桥接模式的动机:当一个抽象可能有多个实现时,通常用继承来协调它们。抽象类定义对该抽象的接口,而具体的子类则用不同方式加以实现。但是此方法有时不够灵活。(继承机制将抽象部分与它的实现部分固定在一起,使得难以对抽象部分和实现部分独立地进行修改、扩充和重用。)
++2.8.1、桥接模式的实现

++++Abstraction:抽象化角色。(它的主要职责是定义出该角色的行为,同时保存一个对实现化角色的引用,该角色一般是抽象类。)(定义抽象类的接口。)(维护一个指向Implementor类型对象的指针。)
++++Implementor:实现化角色。(它是接口或者抽象类,定义角色必须的行为和属性。)(定义实现类的接口,该接口不一定要与Abstraction的接口完全一致;事实上这两个接口可以完全不同。一般来讲,Implementor接口仅提供基本操作,而Abstraction则定义了基于这些基本操作的较高层次的操作。)
++++RefinedAbstraction:修正抽象化角色。(它引用实现化角色对抽象化角色进行修正。)(扩充由Abstraction定义的接口。)
++++ConcreteImplementor:具体实现化角色。(它实现接口或抽象类定义的方法和属性。)
++++抽象角色引用实现角色,或者说抽象角色的部分实现是由实现角色完成的。(实现Implementor接口并定义它的具体实现。)
++++协作:Abstraction将client的请求转发给它的Implementor对象。
++2.8.2、桥接模式的代码
++++Implementor类:
abstract class Implementor{
public abstract void Operation();
}
++++ConcreteImplementorA和ConcreteImplementorB等派生类:
class ConcreteImplementorA :Implementor{
public override void Operation(){
Console.WriteLine(“yanlzPrint:----具体实现A的方法执行”);
}
}
class ConcreteImplementorB :Implementor{
public override void Operation(){
Console.WriteLine(“yanlzPrint:----具体实现B的方法执行”);
}
}
++++Abstraction类
class Abstraction{
protected Implementor implementor;
public void SetImplementor(Implementor implementor){
this.implementor = implementor;
}
public virtual void Operation(){
implementor.Operation();
}
}
++++RefinedAbstraction类
class RefinedAbstraction :Abstraction{
public override void Operation(){
implementor.Operation();
}
}
++++客户端实现:
static void Main(string[] args){
Abstraction ab = new RefinedAbstraction();
ab.SetImplementor(new ConcreteImplementorA());
ab.Operation();
ab.SetImplementor(new ConcreteImplementorB());
ab.Operation();
Console.Read();
}
++++实现系统可能有多角度分类,每一种分类都有可能变化,那么就把这种角度分离出来让它们独立变化,减少它们之间的耦合。
++++只要真正深入地理解了设计原则,很多设计模式其实就是原则的应用而已,或许在不知不觉中就使用设计模式了。
++2.8.3、桥梁模式的优点
++++优点A.1:分离接口及其实现部分。(一个实现未必不变地绑定在一个接口上。抽象类的实现可以在运行时刻进行配置,一个对象甚至可以在运行时刻改变它的实现。)(将Abstraction与Implementor分离有助于降低对实现部分编译时刻的依赖性,当改变一个实现类时,并不需要重新编译Abstraction类和它的客户程序。为了保证一个类库的不同版本之间的二进制兼容性,一定要有这个性质。)(另外,接口与实现分离有助于分层,从而产生更好的结构化系统,系统的高层部分仅需知道Abstraction和Implementor即可。)
++++优点A.2:提高可扩充性。(可以独立地对Abstraction和Implementor层次结构进行扩充。)
++++优点A.3:实现细节对客户透明。(可以对客户隐藏实现细节,例如共享Implementor对象以及相应的引用计数机制(如果有的话)。)
++++优点B.1:抽象和实现分离。(这是桥梁模式的主要特点,它完全是为了解决继承的缺点而提出的设计模式。在该模式下,实现可以不受抽象的约束,不用再绑定在一个固定的抽象层次上。)
++++优点B.2:优秀的扩充能力。(想增加实现?没问题!想增加抽象,也没有问题!只要对外暴露的接口层允许这样的变化,我们已经把变化可能性减到最小。)
++++优点B.3:实现细节对客户透明。(客户不用关心细节的实现,它已经由抽象层通过聚合关系完成了封装。)
++2.8.4、桥梁模式的使用场景
++++场景1:不希望或不适用使用继承的场景。(例如继承层次过渡、无法更细化设计颗粒等场景,需要考虑使用桥梁模式。)
++++场景2:接口或抽象类不稳定的场景。(明知道接口不稳定还想通过实现或继承来实现业务需求,那是得不偿失的,也是比较失败的做法。)
++++场景3:重用性要求较高的场景。(设计的颗粒度越细,则被重用的可能性就越大,而采用继承则受父类的限制,不可能出现太细的颗粒度。)
++++实现分析:继承的优点有很多,可以把公共的方法或属性抽取,父类封装共性,子类实现特性,这是继承的基本功能。缺点是:强侵入,父类有一个方法,子类也必须有这个方法,这是不可选择的,会带来扩展性的问题。(桥接模式就解决这个问题,桥接模式描述了类间弱关联关系。)(不能说继承不好,它非常好,但是有缺点,对于比较明确不发生变化的,则通过继承来完成;若不能确定是否会发生变化的,那就认为是会发生变化,则通过桥接模式来解决。)
++2.8.5、Bridge模式的适用性:
++++适用性1:不希望在抽象和它的实现部分之间有一个固定的绑定关系。(例如这种情况可能是因为,在程序运行时刻实现部分应可以被选择或者切换。)
++++适用性2:类的抽象以及它的实现都应该可以通过生成子类的方法加以扩充。(这时Bridge模式使你可对不同的抽象接口和实现部分进行组合,并分别对它们进行扩充。)
++++适用性3:对一个抽象的实现部分的修改应对客户不产生影响,即客户的代码不必重新编译。
++++适用性4:(C++)想对客户完全隐藏抽象的实现部分。(在C++中,类的表示在类接口中是可见的。)
++++适用性5:想在多个对象间共享实现(可能使用引用计数),但同时要求客户并不知道这一点。
++2.8.6、Bridge模式实现及注意点
++++注意点1:仅有一个Implementor。(在仅有一个实现的时候,没有必要创建一个抽象的Implementor类。这是Bridge模式的退化情况。)(在Abstraction与Implementor之间有一种一对一的关系。尽管如此,当希望改变一个类的实现不会影响已有的客户程序时,模式的分离机制还是非常有用的,也就是说:不必重新编译它们,仅需要重新连接即可。)(分离机制:在C++中,Implementor类的类接口可以在一个私有的头文件中定义,这个文件不提供给客户。这样就对客户彻底隐藏了一个类的实现部分。)
++++注意点2:创建正确的Implementor对象。(当存在多个Implementor类的时候,应该用何种方法,在何时何处确定创建哪一个Implementor类?)(如果Abstraction知道所有的ConcreteImplementor类,它就可以在它的构造器中对其中的一个类进行实例化,它可以通过传递给构造器的参数确定实例化哪一个类。例如,如果一个collection类支持多重实现,就可以根据collection的大小决定实例化哪一个类。链表的实现可以用于较小的collection类,而hash表则可用于较大的collection类。)(另外一种方法是首先选择一个缺省的实现,然后根据需要改变这个实现。例如,如果一个collection的大小超出了一定的阀值时,它将会切换它的实现,使之更适用于表目较多的collection。)(也可以代理给另一个对象,由它一次决定。)
++++注意点3:共享Implementor对象。(Coplien阐明了如何用C++中常用的Handle/Body方法在多个对象间共享一些实现。其中Body有一个对象引用计数器,Handle对它进行增减操作。)
++++注意点4:采用多重继承机制。(在C++中可以使用多重继承机制将抽象接口和它的实现部分结合起来。例如,一个类可以用public方式继承Abstraction而以private方式继承ConcreteImplementor。但是由于这种方式依赖于静态继承,它将实现部分与接口固定不变的绑定在一起。因此不可能使用多重继承的方法实现真正的Bridge模式,至少用C++不行。)
++2.8.7、相关模式
++++AbstractFactory模式可以用来创建和配置一个特定的Bridge模式。
++++Adapter模式用来帮助无关的类协同工作,它通常在系统设计完成后才会被使用。然而,Bridge模式则是在系统开始时就被使用,它使得抽象接口和实现部分可以独立进行改变。
##2.9、组合模式
++2.9、组合模式
++++【组合模式(Composite)】:将对象组合成树形结构以表示“部分-整体”的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
++++需求中是体现部分与整体层次的结构时,希望用户可以忽略组合对象与单个对象的不同,统一地使用组合结构中的所有对象时,就应该考虑用组合模式了。
++++组合模式定义了包含基本对象和组合对象的类层次结构。(基本对象可以被组合成更复杂的组合对象,而这个组合对象又可以被组合,这样不断地递归下去,客户代码中,任何用到基本对象的地方都可以使用组合对象了。)(用户是不用关心到底是处理一个叶节点还是处理一个组合组件,也就用不着为定义组合而写一些选择判断语句了。)
++++组合模式让客户可以一致地使用组合结构和单个对象。
++++组合模式(Composite Pattern)也叫合成模式,有时又叫做部分-整体模式(Part-Whole),主要是用来描述部分与整体的关系,定义:Compose objects into tree structures to represent part-whole hierarchies. Composite lets clients treat individual objects and compositions of objects uniformly.(将对象组合成树形结构以表示“部分-整体”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。)
++++组合模式有两种不同的实现:透明模式和安全模式。(透明模式是把用来组合使用的方法放到抽象类中。)
++++组合模式在项目中到处都有,比如页面结构一般都是上下结构,上面放系统的Logo,下边分为两部分:左边是导航菜单,右边是展示区,左边的导航菜单一般都是树形的结构,比较清晰。(常用的XML结构也是一个树形结构,根节点、元素节点、值元素这些都与我们的组合模式相匹配。)
++++组合模式的意图:将对象组合成树形结构以表示“部分-整体”的层次结构。Composite使得用户对单个对象和组合对象的使用具有一致性。
++++Composite模式的关键是一个抽象类。
++2.9.1、组合模式实现
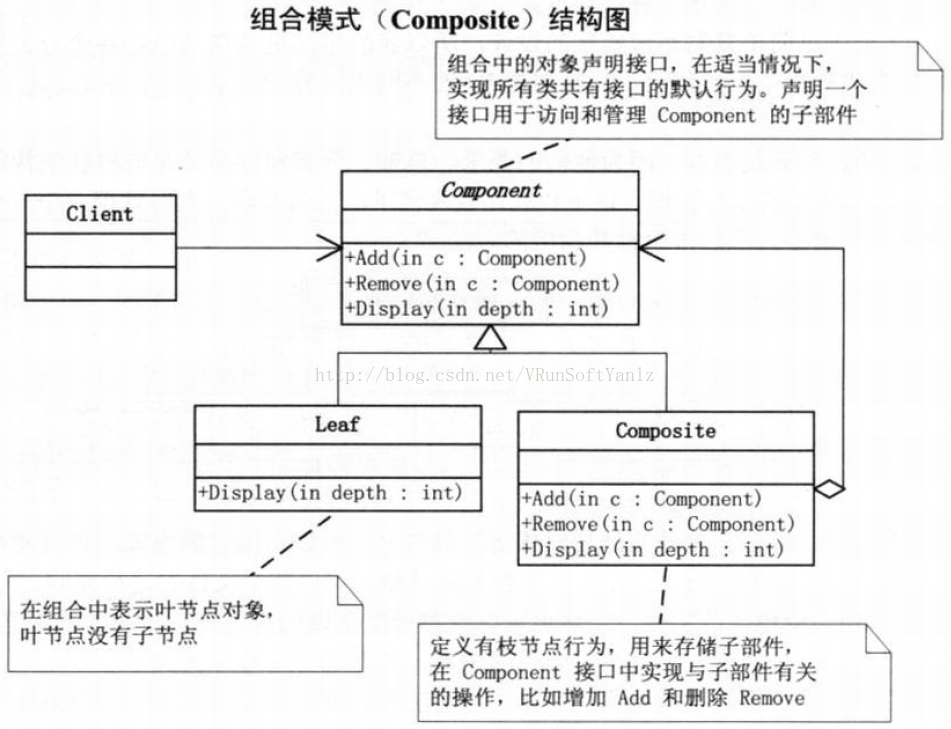
++++Component抽象构件角色。(定义参与组合对象的共有方法和属性,可以定义一些默认的行为或属性。)(为组合中的对象声明接口。)(在适当的情况下,实现所有类共有接口的缺省行为。)(声明一个接口用于访问和管理Component的子组件。)(在递归结构中定义一个接口,用于访问一个父部件,并在合适的情况下实现它。)
++++Leaf叶子构件。(叶子对象,其下再也没有其他的分支,也就是遍历的最小单位。)(在组合中表示叶节点对象,叶节点没有子节点。)(在组合中定义图元对象的行为。)
++++Composite树枝构件。(树枝对象,它的作用是组合树枝节点和叶子节点形成一个树形结构。)(定义有子部件的那些部件的行为。存储子部件。)(在Component接口中实现与子部件有关的操作。)
++++Client。(通过Component接口操纵组合部件的对象。)
++++协作: 用户使用Component类接口与组合结构中的对象进行交互。(如果接受者是一个叶节点,则直接处理请求。如果接收者是Composite,它通常将请求发送给它的子部件,在转发请求之前与/或之后可能执行一些辅助操作。)
++++在实现Composite模式时需要考虑的问题:
--问题1:显式的父部件引用。(保持从子部件到父部件的引用能简化组合结构的遍历和管理。父部件引用可以简化结构的上移和组件的删除,同时父部件引用也支持职责链模式(Chain of Responsibility))(通常在Component类中定义父部件引用。Leaf和Composite类可以继承这个引用以及管理这个引用的那些操作。)(对于父部件的引用,必须维护一个不变式,即一个组合的所有子节点以这个组合为父节点,而反之该组合以这些节点为子节点。保证这一点最容易的方法是,仅当在一个组合中增加或删除一个组件时,才改变这个组件的父部件。如果能在Composite类的Add和Remove操作中实现这种方法,那么所有的子类都可以继承这一方法,并且将自动维护这一不变式。)
--问题2:共享组件。(共享组件是很有用的,比如它可以减少对存贮的需求。但是当一个组件只有一个父部件时,很难共享组件。)(一个可行的解决方法是为子部件存贮多个父部件,但当一个请求在结构中向上传递时,这种方法会导致多义性。享元模式(FlyWeight)讨论了如何修改设计以避免将父部件存贮在一起的方法。如果子部件可以将一些状态(或是所有的状态)存储在外部,从而不需要向父部件发送请求,那么这种方法是可行的。)
--问题3:最大化Component接口。(Composite模式的目的之一是使得用户不知道他们正在使用的具体的Leaf和Composite类。为了达到这一目的,Composite类应为Leaf和Composite类尽可能多定义一些公共操作。)(Composite类通常为这些操作提供缺省的实现,而Leaf和Composite子类可以对它们进行重定义。)
--问题4:声明管理子部件的操作。(虽然Composite类实现了Add和Remove操作用于管理子部件,但在Composite模式中一个重要的问题是:在Composite类层次结构中哪一些类声明这些操作。)
--问题5:Component是否应该实现一个Component列表。(可以希望在Component类中将子节点集合定义为一个实例变量,而这个Component类中也声明了一些操作对子节点进行访问和管理。)
--问题6:子部件排序。(许多设计指定了Composite的子部件顺序。)(如果需要考虑子节点的顺序时,必须仔细地设计对子节点的访问和管理接口,以便管理子节点序列。)
--问题7:使用高速缓冲存贮改善性能。(如果需要对组合进行频繁的遍历或查找,Composite类可以缓冲存储对它的子节点进行遍历或查找的相关信息。)(Composite可以缓冲存储实际结果或者仅仅是一些用于缩短遍历或查询长度的信息。)
--问题8:应该由谁删除Component。(在没有垃圾回收机制的语言中,当一个Composite被销毁时,通常最好由Composite负责删除其子节点。但有一种情况除外,即Leaf对象不会改变,因此可以被共享。)
--问题9:存贮组件最好用哪一种数据结构。(Composite可使用多种数据结构存储它们的子节点,包括连接列表、树、数组和hash表。数据结构的选择取决于效率。)
++2.9.2、组合模式代码
++++Component为组合中的对象声明接口,在适当情况下,实现所有类共有接口的默认行为。声明一个接口用于访问和管理Component的子部件。
abstract class Component{
protected string name;
public Component(string name){
this.name = name;
}
//通常都用Add和Remove方法来提供增加或移除树叶或树枝的功能
public abstract void Add(Component c);
public abstract void Remove(Component c);
public abstract void Display(int depth);
}
++++Leaf在组合中表示叶节点对象,叶节点没有子节点。
class Leaf : Component{
public Leaf(string name) :base(name){
}
//由于叶子没有再增加分枝和树叶,所以Add和Remove方法实现它没有意义,但这样做可以消除叶节点和枝节点对象在抽象层次的区别,它们具备完全一致的接口
public override void Add(Component c){
Console.WriteLine(“YanlzPrint:----Cannot add to a leaf.”);
}
public override void Remove(Component c){
Console.WriteLine(“YanlzPrint:----Cannot remove from a leaf.”);
}
//叶节点的具体方法,此处是显示其名称和级别
public override void Display(int depth){
Console.WriteLine(new String(‘-’, depth) + name);
}
}
++++Composite定义有枝节点行为,用来存储子部件,在Component接口中实现与子部件有关的操作,比如增加Add和删除Remove。
class Composite :Component{
//一个子对象集合用来存储其下属的枝节点和叶节点
private List<Component> children = new List<Component>();
public Composite(string name) :base(name) {
}
public override void Add(Component c){
children.Add(c);
}
public override void Remove(Component c){
children.Remove(c);
}
public override void Display(int depth){
Console.WriteLine(new String(‘-’, depth) + name);
foreach(Component component in children){
component.Display(depth+ 2);
}
}
}
++++客户端代码,能通过Component接口操作组合部件的对象。
static void Main(string[] args){
//生成树根root,根上长出两叶LeafA和LeafB
Composite root = new Composite(“root”);
root.Add(new Leaf(“Leaf A”));
root.Add(new Leaf(“Leaf B”));
//根上长出分枝Composite X,分枝上也有两叶LeafXA和LeafXB
Composite comp = new Composite(“Composite X”);
comp.Add(new Leaf(“Leaf XA”));
comp.Add(new Leaf(“Leaf XB”));
root.Add(comp);
//在Composite X上再长出分枝CompositeXY,分枝上也有两叶LeafXYA和LeafXYB
Composite comp2 = new Composite(“Composite XY”);
comp2.Add(new Leaf(“Leaf XYA”));
comp2.Add(new Leaf(“Leaf XYB”));
comp.Add(comp2);
//根部又长出两叶LeafC和LeafD,可惜LeafD没长牢,被风吹走了
root.Add(new Leaf(“Leaf C”));
Leaf leaf = new Leaf(“Leaf D”);
root.Add(leaf);
root.Remove(leaf);
//显示大树的样子
root.Display(1);
Console.Read();
}
++++结果显示:
-root
---Leaf A
---Leaf B
---Composite X
-----Leaf XA
-----Leaf XB
-----Composite XY
-------Leaf XYA
-------Leaf XYB
---Leaf C
++2.9.3、透明方式与安全方式
++++透明方式,也就是说在Component中声明所有用来管理子对象的方法,其中包括Add、Remove等。(这样实现Component接口的所有子类都具备了Add和Remove。这样做的好处就是叶节点和枝节点对于外界没有区别,它们具有完全一致的行为接口。但问题也很明显,因为Leaf类本身不具备Add()、Remove()方法的功能,所有实现它是没有意义的。)
++++安全方式,也就是在Component接口中不去声明Add和Remove方法,那么子类的Leaf也就不需要去实现它,而是在Composite声明所有用来管理子类的方法,不过由于不够透明,所有树叶和树枝类将不具有相同的接口,客户端的调用需要做相应的判断,带来了不便。
++2.9.4、组合模式的应用
++++组合模式的优点:
--优点1:高层模式调用简单。(一棵树形机构中的所有节点都是Component,局部和整体对调用者来说没有任何区别,也就是说,高层模块不必关心自己处理的单个对象还是整个组合结构,简化了高层模块的代码。)
--优点2:节点自由增加。(使用了组合模式后,如果想增加一个树枝节点、树叶节点是不是很都很容易,只要找到它的父节点就成,非常容易扩展,符合开闭原则,对以后的维护非常有利。)
++++组合模式的缺点:
--缺点1:组合模式有一个非常明显的缺点,直接使用了实现类!这在面向接口编程上是很不恰当的,与依赖倒置原则冲突,在使用的时候要考虑清楚,它限制了接口的影响范围。
++++组合模式的使用场景:
--场景1:维护和展示部分-整体关系的场景,如树形菜单、文件和文件夹管理。
--场景2:从一个整体中能够独立出部分模块或功能的场景。
++++组合模式的注意事项:
--注意点1:只要是树形结构,就要考虑使用组合模式,只要是要体现局部和整体的关系的时候,而且这种关系还可能比较深,考虑使用组合模式吧!
++2.9.5、Composite模式效果:
++++效果1:定义了包含基本对象和组合对象的类层次结构。(基本对象可以被组合成更复杂的组合对象,而这个组合对象又可以被组合,这样不断的递归下去。客户代码中,任何用到基本对象的地方都可以使用组合对象。)
++++效果2:简化客户代码。(客户可以一致地使用组合结构和单个对象。通常用户不知道(也不关心)处理的是一个叶节点还是一个组合组件。这就简化了客户代码,因为在定义组合的那些类中不需要写一些充斥着选择语句的函数。)
++++效果3:使得更容易增加新类型的组件。(新定义的Composite或Leaf子类自动地与已有的结构和客户代码一起工作,客户程序不需因新的Component类而改变。)
++++效果4:使我们的设计变得更加一般化。(容易增加新组件也会产生一些问题,那就是很难限制组合中的组件。有时我们希望一个组合只能有某些特定的组件。使用Composite时,我们不能依赖类型系统施加这些约束,而必须在运行时刻进行检查。)
++2.9.6、相关模式
++++通常部件-父部件连接用于Responsibility of Chain模式。
++++Decorator模式经常与Composite模式一起使用。当装饰和组合一起使用是,它们通常有一个公共的父类。因此装饰必须支持具有Add、Remove和GetChild操作的Component接口。
++++Flyweight让我们共享组件,但不再能引用他们的父部件。
++++Iterator模式可以用来遍历Composite。
++++Visitor模式将本来应该分布在Composite和Leaf类中的操作和行为局部化。
##2.10、享元模式
++2.10、享元模式
++++【享元模式(Flyweight)】:运用共享技术有效地支持大量细粒度的对象。
++++享元模式可以避免大量非常相似类的开销。(在程序设计中,有时需要生成大量细粒度的类实例来表示数据。如果能发现这些实例除了几个参数外基本上都是相同的,有时就能够受大幅度地减少需要实例化的类的数量。如果能把这些参数移到类实例的外面,在方法调用时将它们传递进来,就可以通过共享大幅度地减少单个实例的数目。)
++++如果一个应用程序使用了大量的对象,而大量的这些对象造成了很大的存储开销时就应该考虑使用;还有就是对象的大多数状态可以外部状态,如果删除对象的外部状态,那么可以用相对较少的共享对象取代很多组对象,此时可以考虑使用享元模式。
++++享元模式(Flyweight Pattern)是池技术的重要实现方式,定义:Use sharing to support large numbers of fine-grained objects efficiently.(使用共享对象可有效地支持大量的细粒度的对象。)(享元模式定义提出了两个要求:细粒度的对象和共享对象。)(分配太多的对象到应用程序中将有损程序的性能,同时还容易造成内存溢出。)(要求细粒度对象,使得对象数量多且性质相近,将这些对象的信息分为两个部分:内部状态(intrinsic)与外部状态(extrinsic)。)(内部状态:是对象可共享出来的信息,存储在享元对象内部并且不会随环境改变而改变,它们可以作为一个对象的动态附加信息,不必直接存储在具体某个对象中,属于可以共享的部分。)(外部状态:是对象得以依赖的一个标记,是随环境改变而改变的、可以共享的状态,它是一批对象的统一标识,是唯一的一个索引值。)
++++享元模式的目的在于运用共享技术,使得一些细粒度的对象可以共享,我们的设计确实也应该这样,多使用细粒度的对象,便于重用或重构。
++++Flyweight是拳击比赛中的特用名词,意思是“特轻量级”,指的是51公斤级比赛,用到设计模式中是指我们的类要轻量级,粒度要小,这才是它要表达的意思。(粒度小了,带来的问题就是对象太多,那就用共享技术来解决。)
++++享元模式可以实现对象池,但这两者还是由比较大的差异,对象池着重在对象的复用上,池中的每个对象是可替换的,从同一个池中获得A对象和B对象对客户端来说是完全相同的,它主要解决复用,而享元模式在主要解决对象的共享问题,如何建立多个可共享的细粒度对象则是其关注的重点。
++++享元模式的意图:运用共享技术有效地支持大量细粒度的对象。
++++Flyweight模式对那些通常因为数量太大而难以用对象来表示的概念或实体进行建模。
++2.10.1、享元模式的实现
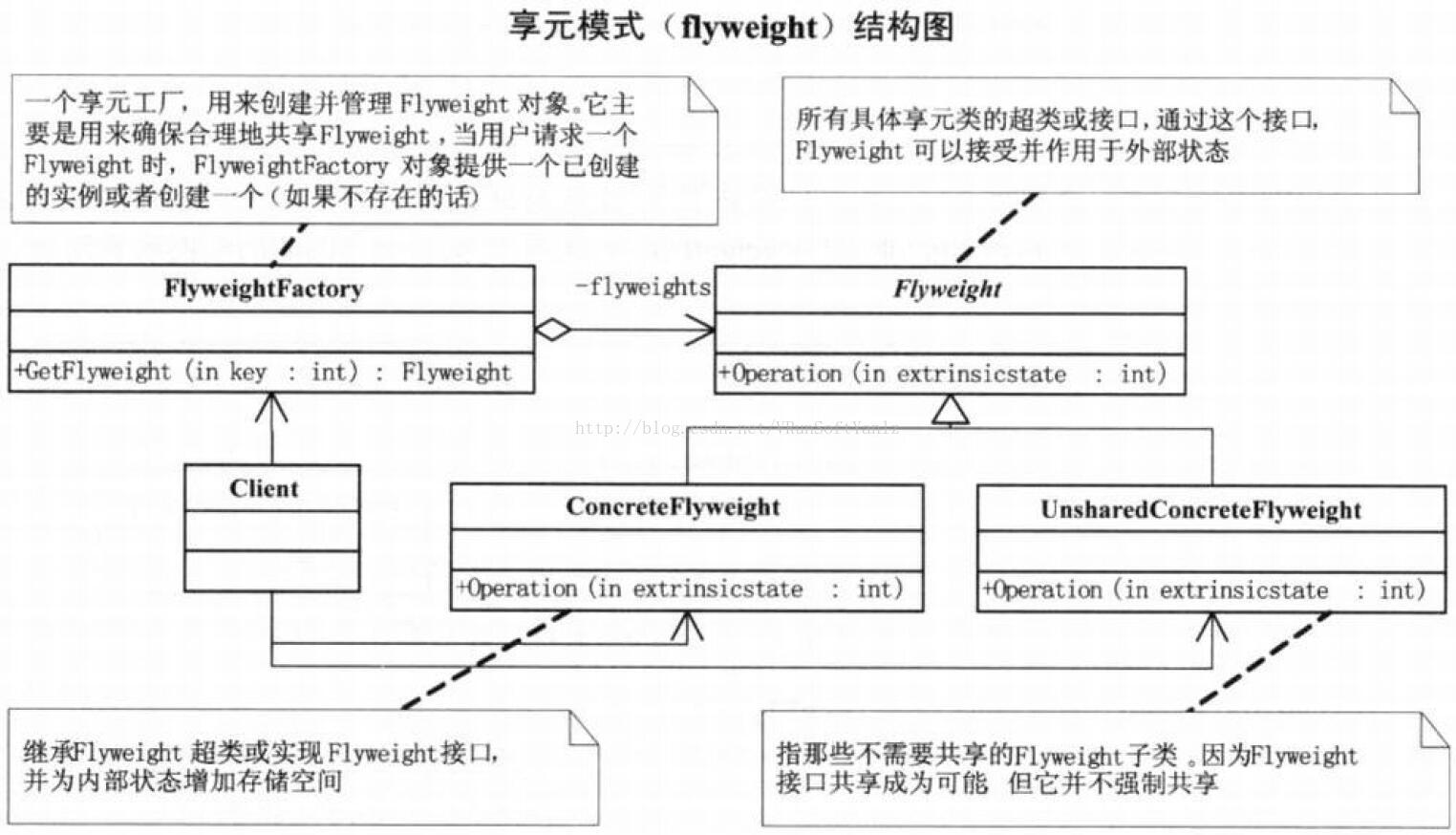
++++Flyweight:抽象享元角色。(简单地说就是一个产品的抽象类,同时定义出对象的外部状态和内部状态的接口或实现。)(描述一个接口,通过接口flyweight可以接受并作用于外部状态。)
++++ConcreteFlyweight:具体享元角色。(具体的一个产品类,实现抽象角色定义的业务。该角色中需要注意的是内部状态处理应该与环境无关,不应该出现一个操作改变了内部状态,同时修改了外部状态,这是绝对不允许的。)(实现Flyweight接口,并为内部状态(如果有的话)增加存储空间。ConcreteFlyweight对象必须是可共享的。它所存储的状态必须是内部的,即,它必须独立于ConcreteFlyweight对象的场景。)
++++unsharedConcreteFlyweight:不可共享的享元角色。(不存在外部状态或者安全要求(如线程安全)不能够使用共享技术的对象,该对象一般不会出现在享元工厂中。)
++++FlyweightFactory:享元工厂。(职责非常简单,就是构造一个池容器,同时提供从池中获得对象的方法。)
++++Client。(维持一个对flyweight的引用。)(计算或存储一个(多个)flyweight的外部状态。)
++++协作:flyweight执行时所需的状态必定是内部的或外部的。(内部状态存储于ConcreteFlyweight对象之中;而外部对象则由Client对象存储或计算。当用户调用flyweight对象的操作时,将该状态传递给它。)(用户不应直接对ConcreteFlyweight类进行实例化,而只能从FlyweightFactory对象得到ConcreteFlyweight对象,这可以保证对它们适当地进行共享。)
++2.10.2、享元模式代码
++++Flyweight类,它是所有具有享元类的超类或接口,通过这个接口,Flyweight可以接受并作用于外部状态。
abstract class Flyweight{
public abstract void Operation(int extrinsicstate);
}
++++ConcreteFlyweight是继承Flyweight超类或实现Flyweight接口,并为内部状态增加存储空间。
class ConcreteFlyweight :Flyweight{
public override void Operation(int extrinsicstate){
Console.WriteLine(“立钻哥哥:具体Flyweight:” + extrinsicstate);
}
}
++++UnsharedConcreteFlyweight是指那些不需要共享的Flyweight子类。因为Flyweight接口共享为可能,但并不强制共享。
class UnsharedConcreteFlyweight :Flyweight{
public override void Operation(int extrinsicstate){
Console.WriteLine(“立钻哥哥:不共享的具体Flyweight:” + extrinsicstate);
}
}
++++FlyweightFactory,是一个享元工厂,用来创建并管理Flyweight对象。它主要是用来确保合理地共享Flyweight,当用户请求一个Flyweight时,FlyweightFactory对象提供一个已创建的实例或者创建一个(如果不存在的话)。
class FlyweightFactory{
private Hashtable flyweights = new Hashtable();
public FlyweightFactory(){
flyweights.Add(“X”,new ConcreteFlyweight());
flyweights.Add(“Y”,new ConcreteFlyweight());
flyweights.Add(“Z”,new ConcreteFlyweight());
}
public Flyweight GetFlyweight(string key){
return ((Flyweight)flyweights[key]);
}
}
++++客户端代码:
static void Main(string[] args){
int extrinsicstate = 22;
FlyweightFactory f = new FlyweightFactory();
Flyweight fx = f.GetFlyweight(“X”);
fx.Operation(--extrinsicstate);
Flyweight fy = f.GetFlyweight(“Y”);
fy.Operation(--extrinsicstate);
Flyweight fz = f.GetFlyweight(“Z”);
fz.Operation(--extrinsicstate);
UnsharedConcreteFlyweight uf = new UnsharedConcreteFlyweight();
uf.Operation(--extrinsicstate);
Console.Read();
}
++++结果表示:
具体Flyweight: 21
具体Flyweight: 20
具体Flyweight: 19
不共享的具体Flyweight: 18
++2.10.3、享元模式的应用
++++享元模式的优点和缺点:享元模式是一个非常简单的模式,它可以大大减少应用程序创建的对象,降低程序内存的占用,增强程序的性能,但它同时也提高了系统复杂性,需要分离出外部状态和内部状态,而且外部状态具有固化特性,不应该随内部状态改变而改变,否则导致系统的逻辑混乱。
++++享元模式的使用场景:
--场景1:系统中存在大量的相似对象。
--场景2:细粒度的对象都具备较接近的外部状态,而且内部状态与环境无关,也就是说对象没有特定身份。
--场景3:需要缓冲池的场景。
++2.10.4、Flyweight模式的适用性:
++++Flyweight模式的有效性很大程度上取决于如何使用它以及在何处使用它。
++++适用性1:一个应用程序使用了大量的对象。
++++适用性2:完全由于使用大量的对象,造成很大的存储开销。
++++适用性3:对象的大多数状态都可变为外部状态。
++++适用性4:如果删除对象的外部状态,那么可以用相对较少的共享对象取代很多组对象。
++++适用性5:应用程序不依赖于对象标识。(由于Flyweight对象可以被共享,对于概念上明显有别的对象,标识测试将返回真值。)
++2.10.5、相关模式
++++Flyweight模式通常和Composite模式结合起来,用共享叶节点的有向无环图实现一个逻辑上的层次结构。
++++最好用Flyweight实现State和Strategy对象。
##2.11、代理模式
++2.11、代理模式
++++【代理模式(Proxy)】:为其他对象提供一种代理以控制这个对象的访问。
++++一般来说代理分为:远程代理、虚拟代理、安全代理、智能指引等。(远程代理:也就是为一个对象在不同的地址空间提供局部代理。这样可以隐藏一个对象存在于不同地址空间的事实。)(虚拟代理:是根据需要创建开销很大的对象。通过它来存放实例化需要很长时间的真实对象。)(安全代理:用来控制真实对象访问时的权限。)(智能指引:是指当调用真实的对象时,代理处理另外一些事。)
++++代理模式(Proxy Pattern)是一个使用率非常高的模式,定义:Provide a surrogate or placeholder for another object to control access to it.(为其他对象提供一种代理以控制对这个对象的访问。)
++++代理模式也叫委托模式,它是一项基本设计技巧。(许多其他的模式,如状态模式、策略模式、访问者模式本质上是在更特殊的场合采用了委托模式,而且在日常的应用中,代理模式可以提供非常好的访问控制。)
++++代理模式应用得非常广泛,大到一个系统框架、企业平台,小到代码片段、事务处理。
++++代理模式的意图:为其他对象提供一种代理以控制对这个对象的访问。
++2.11.1、代理模式的实现
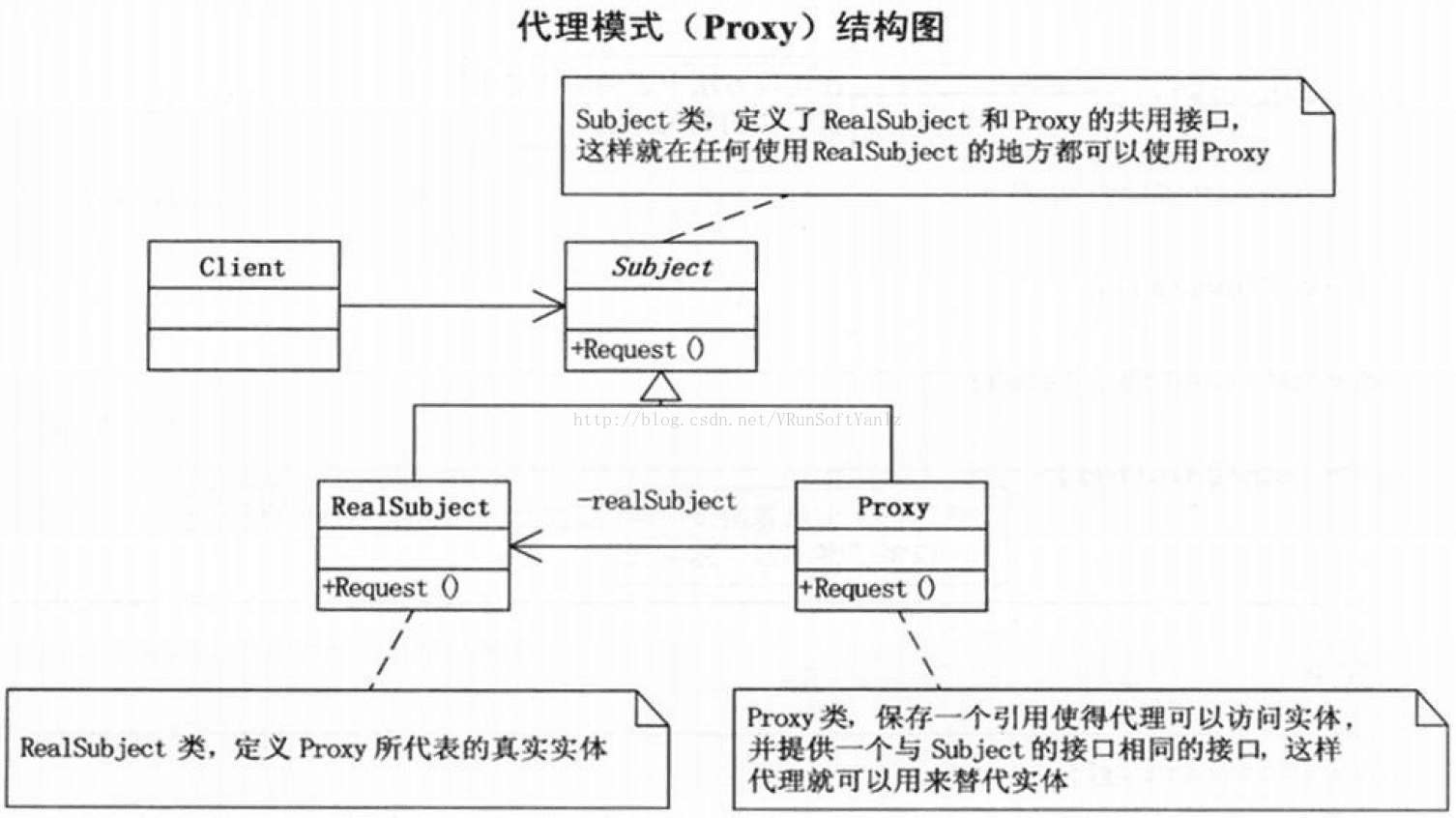
++++Subject抽象主题角色。(抽象主题类可以是抽象类也可以是接口,是一个最普通的业务类型定义,无特殊要求。)(定义RealSubject和Proxy的共用接口,这样就在任何使用RealSubject的地方都可以使用Proxy。)
++++RealSubject具体主题角色。(也叫做被委托角色、被代理角色。是业务逻辑的具体执行者。)(定义Proxy所代表的实体。)
++++Proxy代理主题角色。(也叫做委托类、代理类。它负责对真实角色的应用,把所有抽象主题类定义的方法限制委托给真实主题角色实现,并且在真实主题角色处理完毕前后做预处理和善后处理工作。)(保存一个引用使得代理可以访问实体。若RealSubject和Subject的接口相同,Proxy会引用Subject。)(提供一个与Subject的接口相同的接口,这样代理就可以用来替代实体。)(控制对实体的存取,并可能负责创建和删除它。)
++2.11.2、代码模式的代码
++++Subject类,定义了RealSubject和Proxy的共用接口,这样就在任何使用RealSubject的地方都可以使用Proxy。
abstract class Subject{
public abstract void Request();
}
++++RealSubject类,定义Proxy所代表的真实实体。
class RealSubject :Subject{
public override void Request(){
Console.WriteLine(“立钻哥哥Print:真实的请求”);
}
}
++++Proxy类,保存一个引用使得代理可以访问实体,并提供一个与Subject的接口相同的接口,这样代理就可以用来替代实体。
class Proxy : Subject{
RealSubject realSubject;
public override void Request(){
if(realSubject == null){
realSubject = new RealSubject();
}
realSubject.Request();
}
}
++++客户端代码:
static void Main(string[] args){
Proxy proxy = new Proxy();
proxy.Request();
Console.Read();
}
++2.11.3、代理模式的优点
++++优点1:职责清晰。(真实的角色就是实现实际的业务逻辑,不用关心其他非本职责的事务,通过后期的代理完成一件事务,附带的结果就是编程简洁清晰。)
++++优点2:高扩展性。(具体主题角色是随时都会发生变化的,只要它实现了接口,那代理类完全就可以在不做任何修改的情况下使用。)
++++优点3:智能化。
++2.11.4、代理模式的拓展:
++++拓展1:普通代理。(普通代理要求客户端只能访问代理角色,而不能访问真实角色,这是比较简单的。)
++++拓展2:强制代理。(强制代理就是要从真实角色查找到代理角色,不允许直接访问真实角色。)
++++拓展3:代理是有个性的。(一个类可以实现多个接口,完成不同任务的整合。也就是说代理类不仅仅可以实现主题接口,也可以实现其他接口完成不同的任务,而且代理的目的是在目前对象方法的基础上作增强,这种增强的本质通常就是对目标对象的方法济宁拦截和过滤。)
++++拓展4:虚拟代理。(虚拟代理(Virtual Proxy),只要把代理模式的通用代码修改成虚拟代理。在需要的时候才初始化主题对象,可以避免被代理对象较多而引起的初始化缓慢的问题。其缺点是需要在每个方法中判断主题对象是否被创建,这就是虚拟代理。)
++++拓展5:动态代理。(动态代理是在实现阶段不用关心代理谁,而在运行阶段才指定代理哪一个对象。相对来说,自己写代理类的方式就是静态代理。)(要实现动态代理的首要条件是:被代理类必须实现一个接口。)
++2.11.5、代理模式的适用性
++++在需要用比较通用和复杂的对象指针代替简单的指针的时候,使用Proxy模式。
++++适用性1:远程代理(Remote Proxy):为一个对象在不同的地址空间提供局部代表。
++++适用性2:虚代理(Virtual Proxy):根据需要创建开销很大的对象。
++++适用性3:保护代理(Protection Proxy):控制对原始对象的访问。(保护代理用于对象应该有不同的访问权限的时候。)
++++适用性4:智能指引(Smart Reference):取代了简单的指针,它在访问对象时执行一些附加操作。(对指向实际对象的引用计数,这样当该对象没有引用时,可以自动释放它(也称为Smart Pointers)。)(当第一次引用一个持久对象时,将它装入内存。)(在访问一个实际对象前,检查是否已经锁定了它,以确保其他对象不能改变它。)
++2.11.6、相关模式
++++Adapter:适配器Adapter为它所适配的对象提供了一个不同的接口。(相反,代理提供了与它的实体相同的接口。然而,用于访问保护的代理可能会拒绝执行实体会执行的操作,因此,它的接口实际上可能只是实体接口的一个子集。)
++++Decorator:尽管decorator的实现部分与代理相似,但decorator的目的不一样。(Decorator为对象添加一个或多个功能,而代理则控制对对象的访问。)
++++代理的实现与decorator的实现类似,但是在相似的程度上有所差别。(Protection Proxy的实现可能与decorator的实现差不多。)(Remote Proxy不包含对实体的直接引用,而只是一个间接引用。)(Virtual Proxy开始的时候使用一个间接引用,但最终将获取并使用一个直接引用。)
##2.12、外观模式
++2.12、外观模式
++++【外观模式(Facade)】:为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
++++外观模式的使用分三个阶段:首先,在设计初期阶段,应该要有意识的将不同的两个层分离,层与层之间建立外观Facade;其次,在开发阶段,子系统往往因为不断的重构演化而变得越来越复杂,增加外观Facade可以提供一个简单的接口,减少它们之间的依赖;第三,在维护一个遗留的大型系统时,可能这个系统已经非常难以维护和扩展了,为新系统开发一个外观Facade类,来提供设计粗糙或高度复杂的遗留代码的比较清晰简单的接口,让新系统与Facade对象交互,Facade与遗留代码交互所有复杂的工作。
++++外观模式(Facade Pattern)也叫做门面模式,是一种比较常用的封装模式,定义:Provide a unified interface to a set of interfaces in a subsystem. Facade defines a highter-level interface that makes the subsystem easier to use.(要求一个子系统的外部与其内部的通信必须通过一个统一的对象进行。门面模式提供一个高层次的接口,使得子系统更易于使用。)
++++门面模式注重“统一的对象”,也就是提供一个访问子系统的接口,除了这个接口不允许有任何访问子系统的行为发生。(门面对象时外界访问子系统内部的唯一通道,不管子系统内部是多么杂乱无章,只要有门面对象在,就可以做到“金玉其外,败絮其中”。)
++++门面模式是一个很好的封装方法,一个子系统比较复杂时,比如算法或者业务比较复杂,就可以封装出一个或多个门面出来,项目的结构简单,而且扩展性非常好。(对于一个较大项目,为了避免人员带来的风险,也可以使用门面模式,技术水平比较差的成员,尽量安排独立的模块,然后把他写的程序封装到一个门面里,尽量让其他项目成员不用看到这些人的代码。)(使用门面模式后,对门面进行单元测试,约束项目成员的代码质量,对项目整体质量的提升也是一个比较好的帮助。)
++++外观模式的意图:为子系统中的一组接口提供一个一致的界面,Facade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。(将一个系统划分为若干个子系统有利于降低系统的复杂性。一个常见的设计目标是使子系统间的通信和相互依赖关系达到最小。达到该目标的途径之一就是引入一个外观(facade)对象,它为子系统中较一般的设施提供了一个单一而简单的界面。)
++2.12.1、外观模式实现
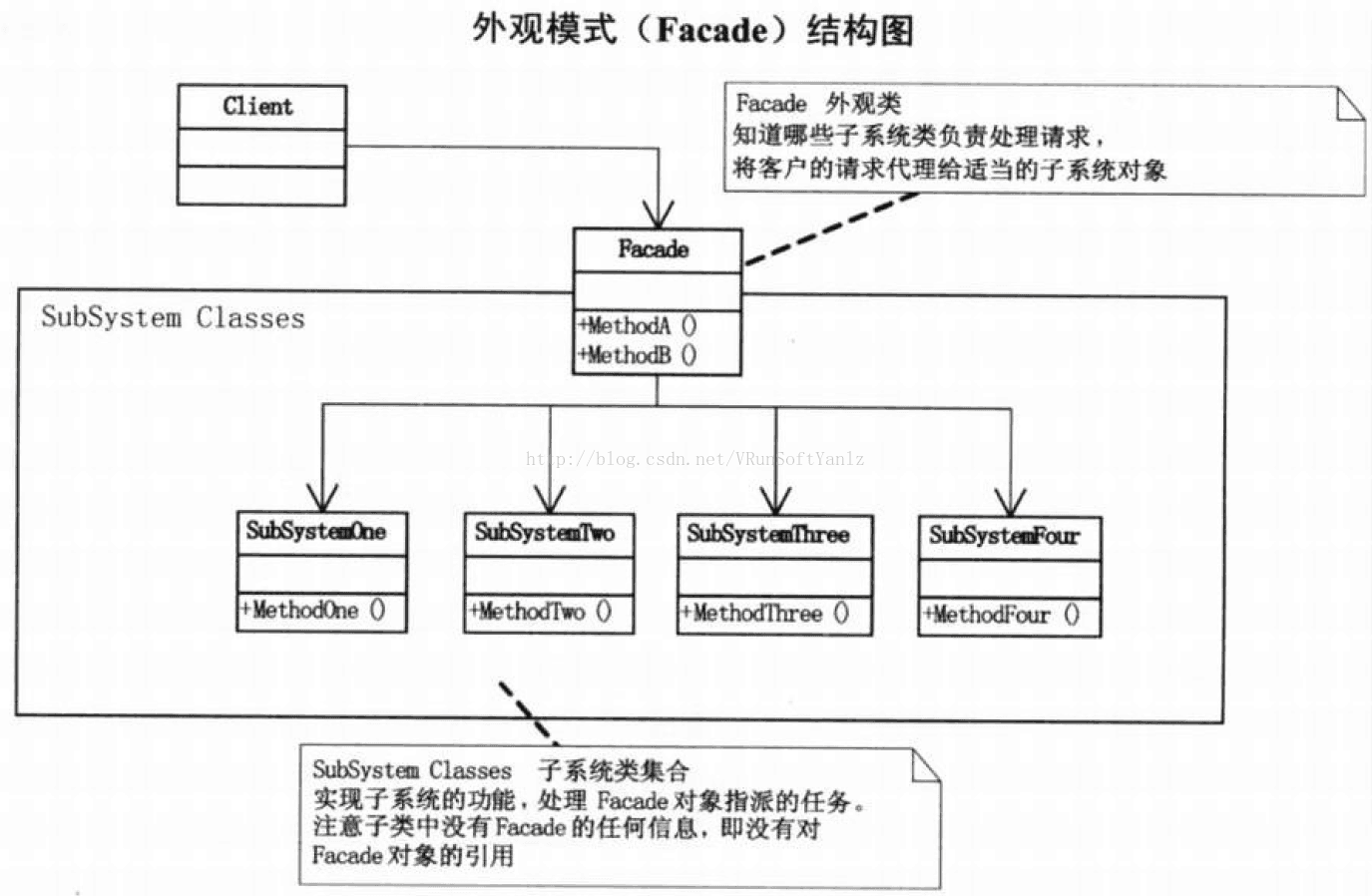
++++Facade门面角色。(客户端可以调用这个角色的方法。此角色知晓子系统的所有功能和责任。一般情况下,会将所有从客户端发来的请求委派到相应的子系统去,也就是说该角色没有实际的业务逻辑,只是一个委托类。)(知道哪些子系统类负责处理请求。)(将客户的请求代理给适当的子系统对象。)
++++subsystem子系统角色。(可以同时又一个或者多个子系统。每一个子系统都不是一个单独的类,而是一个类的集合。子系统并不知道门面的存在。对于子系统而言,门面仅仅是另外一个客户端而已。)(实现子系统的功能。)(处理由Facade对象指派的任务。)(没有facade的任何信息,即,没有指向facade的指针。)
++++协作:客户程序通过发生请求给Facade的方式与子系统通讯,Facade将这些消息转发给适当的子系统对象。尽管是子系统中的有关对象在做实际工作,但Facade模式本身也必须将它的接口转换成子系统的接口。(使用Facade的客户程序不需要直接访问子系统对象。)
++2.12.3、外观模式代码
++++四个子系统的类
class SubSystemOne{
public void MethodOne(){
Console.WriteLine(“立钻哥哥Print:子系统方法一”);
}
}
class SubSystemTwo{
public void MethodTwo{
Console.WriteLine(“立钻哥哥Print:子系统方法二”);
}
}
class SubSystemThree{
public void MethodThree(){
Console.WriteLine(“立钻哥哥Print:子系统方法三”);
}
}
class SubSystemFour{
public void MethodFour(){
Console.WriteLine(“立钻哥哥Print:子系统方法四”);
}
}
++++外观类
class Facade{
SubSystemOne one;
SubSystemTwo two;
SubSystemThree three;
SubSystemFour four;
public Facade(){
one = new SubSystemOne();
two = new SubSystemTwo();
three = new SubSystemThree();
four = new SubSystemFour();
}
public void MethodA(){
Console.WriteLine(“立钻哥哥Print:方法组A()----”);
one.MethodOne();
two.MethodTwo();
four.MethodFour();
}
public void MethodB(){
Console.WriteLine(“立钻哥哥Print:方法组B()----”);
two.MethodTwo();
three.MethodThree();
}
}
++++客户端调用
static void Main(string[] args){
Facade facade = new Facade();
facade.MethodA();
facade.MethodB();
Console.Read();
}
++++外观模式完美体现了依赖倒置原则和迪米特法则的思想,所以是非常常用的模式之一。
++2.12.4、门面模式的优缺点
++++优点1:减少系统的相互依赖。(如果我们不使用门面模式,外界访问直接深入到子系统内部,相互之间是一种强耦合关系,这样的强依赖是系统设计所不能接受的,门面模式的出现就很好地解决了该问题,所有的依赖都是对门面对象的依赖,与子系统无关。)
++++优点2:提供了灵活性。(依赖减少了,灵活性自然提高了。不管子系统内部如何变化,只要不影响到门面对象,任你自由活动。)
++++优点3:提高安全性。(想让访问子系统的哪些业务就开通哪些逻辑,不在门面上开通的方法,休想访问到。)
++++缺点1:门面模式最大的缺点就是不符合开闭原则。(后期维护,继承?覆写?都不顶用,唯一能做的一件事就是修改门面角色的代码,这个风险相当大。)
++2.12.5、门面模式的使用场景
++++场景1:为一个复杂的模块或子系统提供一个供外界访问的接口。
++++场景2:子系统相对独立:外界对子系统的访问只要黑箱操作即可。
++++场景3:预防低水平人员带来的风险扩散。(“画地为牢”,只能在指定的子系统中开发,然后再提供门面接口进行访问操作。)
++2.12.6、外观模式的适用性
++++适用性1:当要为一个复杂子系统提供一个简单接口时。(子系统往往因为不断演化而变得越来越复杂。大多数模式使用时都会产生更多更小的类。这使得子系统更具可重用性,也更容易对子系统进行定制,但这也给那些不需要定制子系统的用户带来一些使用上的困难。)(Facade可以提供一个简单的缺省视图,这一视图对大多数用户来说已经足够,而那些需要更多的可定制性的用户可以越过facade层。)
++++适用性2:客户程序与抽象类的实现部分之间存在着很大的依赖性。(引入facade将这个子系统与客户以及其他的子系统分离,可以提高子系统的独立性和可移植性。)
++++适用性3:当需要构建一个层次结构的子系统时,使用facade模式定义子系统中每层的入口点。(如果子系统之间是相互依赖的,可以让它们仅通过facade进行通讯,从而简化了它们之间的依赖关系。)
++2.12.7、相关模式
++++Abstract Factory模式可以与Facade模式一起使用以提供一个接口,这一接口可用来以一种子系统独立的方式创建子系统对象。(Abstract Factory也可以代替Facade模式隐藏那些与平台相关的类。)
++++Mediator模式与Facade模式的相似之处是,它抽象了一些已有的类的功能。然而,Mediator的目的是对同事之间的任意通讯进行抽象,通常集中不属于任何单个对象的功能。Mediator的同事对象知道中介者并与它通信,而不是直接与其他同类对象通信。(相对而言,Facade模式仅对子系统对象的接口进行抽象,从而使它们更容易使用;它并不定义新功能,子系统也不知道facade的存在。)
++++通常来讲,仅需要一个Facade对象,因此Facade对象通常属于Singleton模式。
##2.13、观察者模式
++2.13、观察者模式
++++【观察者模式(Observer)】:定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态发生变化时,会通知所有观察者对象,使它们能够自动更新自己。
++++观察者模式(Observer Pattern)又叫发布-订阅(Publish/Subscribe)模式,它是一个在项目中经常使用的模式,定义:Define a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically.(定义对象间一种一对多的依赖关系,使得每当一个对象改变状态,则所有依赖于它的对象都会得到通知并被自动更新。)
++++观察者模式的意图:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。(将一个系统分割成一系列相互协作的类有一个常见的副作用:需要维护相关对象间的一致性。我们不希望为了维持一致性而使各类紧密耦合,因为这样降低了它们的可重用性。)
++2.13.1、观察者模式实现
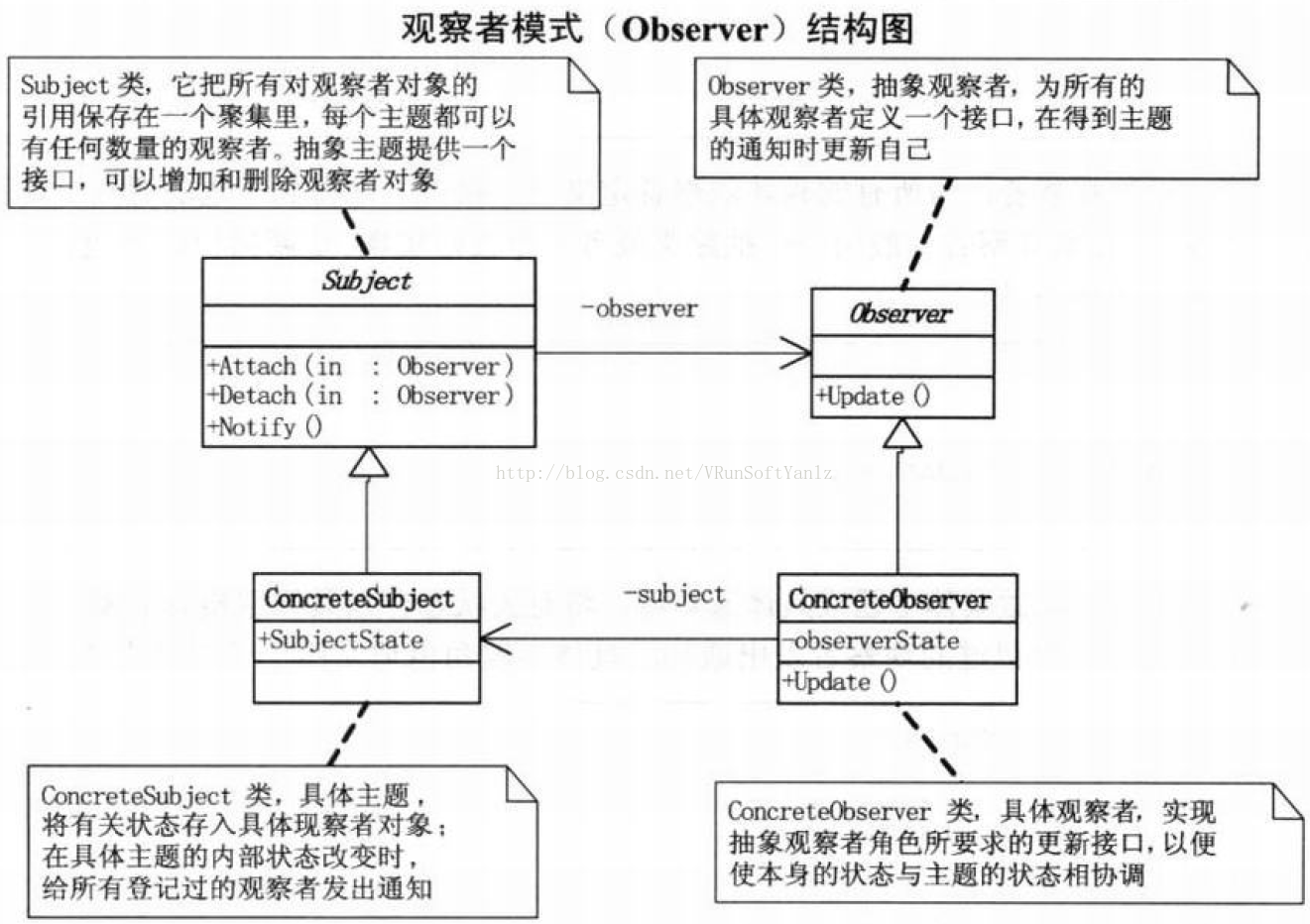
++++Subject被观察者。(定义被观察者必须实现的职责,它必须能够动态地增加、取消观察者。它一般是抽象类或者是实现类,仅仅完成作为被观察者必须实现的职责:管理观察者并通知观察者。)(目标知道它的观察者。可以有任意多个观察者观察同一个目标。)(提供注册和删除观察者对象的接口。)
++++Observer观察者。(观察者接收到消息后,即进行update(更新方法)操作,对接收到的信息进行处理。)(为那些在目标发生改变时需获得通知的对象定义一个更新接口。)
++++ConcreteSubject具体的被观察者。(定义被观察者自己的业务逻辑,同时定义对哪些事件进行通知。)(将有关状态存入各ConcreteObserver对象。)(当它的状态发生改变时,向它的各个观察者发出通知。)
++++ConcreteObserver具体的观察者。(每个观察者在接收到消息后的处理反映是不同的,各个观察者有自己的处理逻辑。)(维护一个指向ConcreteSubject对象的引用。)(存储有关状态,这些状态应与目标的状态保持一致。)(实现Observer的更新接口以使自身状态与目标的状态保持一致。)
++++协作:当ConcreteSubject发生任何可能导致其观察者与其本身状态不一致的改变时,它将通知它的各个观察者。(在得到一个具体目标的改变通知后,ConcreteObsevrer对象可向目标对象查询信息。ConcreteObserver使用这些信息以使它的状态与目标对象的状态一致。)
++++注意发出改变请求的Observer对象并不立即更新,而是将其推迟到它从目标得到一个通知之后。Notify不总是由目标对象调用。它也可被一个观察者或其它对象调用。
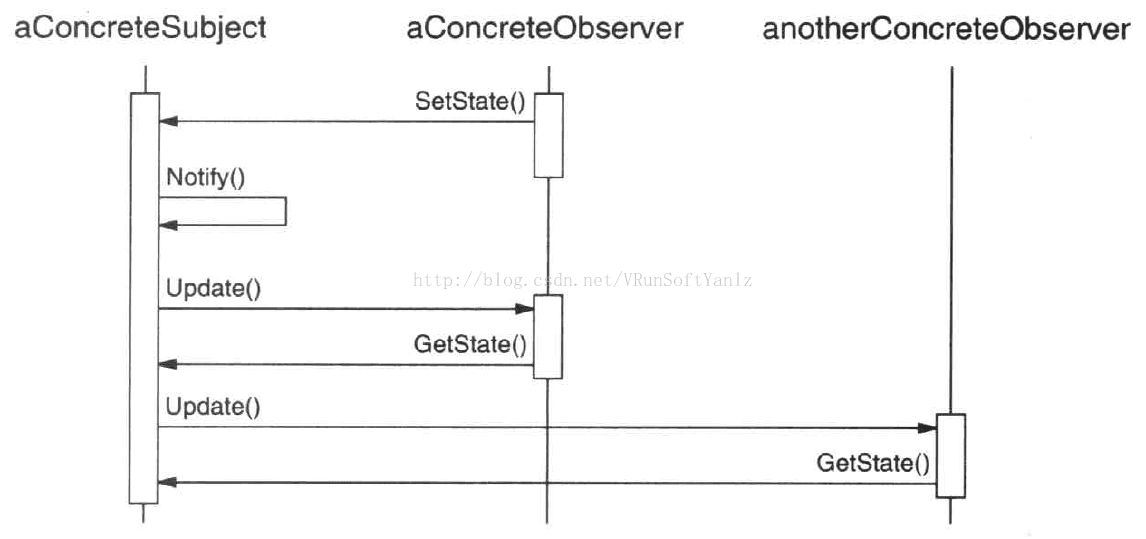
++2.13.2、观察者模式代码
++++Subject类,可翻译为主题或抽象通知者,一般用一个抽象类或者一个接口实现。它把所有对观察者对象的引用保存在一个聚集里,每个主题都可以有任何数量的观察者。抽象主题提供一个接口,可以增加和删除观察者对象。
abstract classSubject{
private List<Observer> observers = new List<Observer>();
//增加观察者
public void Attach(Observer observer){
observers.Add(observer);
}
//移除观察者
public void Detach(Observer observer){
observers.Remove(observer);
}
//通知
public void Notify(){
foreach(Observer o in observers){
o.Update();
}
}
}
++++Observer类,抽象观察者,为所有的具体观察者定义一个接口,在得到主题的通知时更新自己。这个接口叫做更新接口。抽象观察者一般用一个抽象类或者一个接口实现。更新接口通常包含一个Update()方法,这个方法叫做更新方法。
abstract class Observer{
public abstract void Update();
}
++++ConcreteSubject类,叫做具体主题或具体通知者,将有关状态存入具体观察者对象;在具体主题的内部状态改变时,给所有登记过的观察者发出通知。具体主题角色通常用一个具体子类实现。
class ConcreteSubject :Subject{
private string subjectState;
//具体被观察者状态
public string SubjectState{
get{ return subjectState; }
set{ subjectState = value; }
}
}
++++ConcreteObserver类,具体观察者,实现抽象观察者角色所要求的更新接口,以便使本身的状态与主题的状态相协调。具体观察者角色可以保持一个指向具体主题对象的引用。具体观察者角色通常用一个具体子类实现。
class ConcreteObserver :Observer{
private string name;
private string observerState;
private ConcreteSubject subject;
public ConcreteObserver(ConcreteSubject subject, string name){
this.subject = subject;
this.name = name;
}
public overridevoid Update(){
observerState = subject.SubjectState;
Console.WriteLine(“立钻哥哥Print:观察者{0}的新状态是{1}”, name, observerState);
}
public ConcreteSubject Subject{
get{ return subject; }
set{ subject = value; }
}
}
++++客户端代码
static void Main(string[] args){
ConcreteSubject s = new ConcreteSubject();
s.Attach(new ConcreteObserver(s,“X”));
s.Attach(new ConcreteObserver(s,“Y”));
s.Attach(new ConcreteObserver(s,“Z”));
s.SubjectState = “ABC”;
s.Notify();
Console.Read();
}
++++结果显示:
观察者X的新状态是ABC
观察者Y的新状态是ABC
观察者Z的新状态是ABC
++2.13.3、观察者模式特点
++++观察者模式的关键对象是主题Subject和观察者Observer,一个Subject可以有任意数目的依赖它的Observer,一旦Subject的状态发生了改变,所有的Observer都可以得到通知。Subject发出通知时并不需要知道谁是它的观察者,也就是说,具体观察者是谁,它根本不需要知道。而任何一个具体观察者不知道耶不需要知道其他观察者的存在。(将一个系统分割成一系列相互协作的类有一个很不好的副作用,那就是需要维护相关对象间的一致性。我们不希望为了维持一致性而使各类紧密耦合,这样会给维护、扩展和重用都带来不便。)
++++当一个对象的改变需要同时改变其他对象,而且它不知道具体有多少对象有待改变时,应该考虑使用观察者模式。(一个抽象模型有两个方法,其中一方面依赖于另一方面,这时用观察者模式可以将这两者封装在独立的对象中使它们各自独立地改变和复用。)
++++观察者模式所做的工作其实就是在解除耦合。让耦合的双方都依赖于抽象,而不是依赖于具体。从而使得各自的变化都不会影响另一边的变化。
++2.13.4、事件委托说明
++++委托就是一种引用方法的类型。一旦为委托分配了方法,委托将与该方法具有完全相同的行为。(委托方法的使用可以像其他任何方法一样,具有参数和返回值。)(委托可以看做是对函数的抽象,是函数的“类”,委托的实例将代表一个具体的函数。)
++++举例:delegate void EventHandler();可以理解为声明了一个特殊的“类”。(而public event EventHandler Update;可以理解为声明了一个“类”的变量。=>声明了一个事件委托变量叫Update)
++++一个委托可以搭载多个方法,所有方法被依次唤起。(可以使得委托对象所搭载的方法并不需要属于同一个类。)
++++委托对象所搭载的所有方法必须具有相同的原形和形式,也就是拥有相同的参数列表和返回值类型。
++2.13.5、观察者模式的优缺点
++++Observer模式允许我们独立的改变目标和观察者。(我们可以单独复用目标对象而无需同时复用其观察者,反之亦然。)(观察者模式也使我们可以在不改动目标和其他的观察者的前提下增加观察者。)
++++优点A.1:目标和观察者间的抽象耦合。(一个目标所知道的仅仅是它有一系列观察者,每个都符合抽象的Observer类的简单接口。目标不知道任何一个观察者属于哪一个具体的类。这样目标和观察者之间的耦合是抽象的和最小的。)(因为目标和观察者不是紧密耦合的,它们可以属于一个系统中的不同抽象层次。一个处于较低层次的目标对象可与一个处于较高层次的观察者通信并通知它,这样就保持了系统层次的完整。如果目标和观察者混在一起,那么得到的对象要么横贯两个层次(违反了层次性),要么必须放在这两层的某一层中(这可能会损害层次抽象。))
++++优点A.2:支持广播通信。(不像通常的请求,目标发送的通知不需指定它的接受者。通知被自动广播给所有已向该目标对象登记的有关对象。目标对象并不关心到底有多少对象对自己感兴趣;它唯一的责任就是通知它的各观察者。这给了我们在任何时刻增加和删除观察者的自由。处理还是忽略一个通知取决于观察者。)
++++缺点A.1:意外的更新。(因为一个观察者并不知道其它观察者的存在,它可能对改变目标的最终代价一无所知。在目标上一个看似无害的操作可能会引起一系列对观察者以及依赖于这些观察者的那些对象的更新。此外,如果依赖准则的定义或维护不当,常常会引起错误的更新,这种错误通常很难捕捉。)(简单的更新协议不提供具体细节说明目标中什么被改变了,这就使得问题更加严重。如果没有其他协议帮助观察者发现什么发生了改变,它们可能会被迫尽力减少改变。)
++++优点B.1:观察者和被观察者之间是抽象耦合。(如此设计,则不管是增加观察者还是被观察者都非常容易扩展。)
++++优点B.2:建立一套触发机制。(根据单一职责原则,每个类的职责是单一的,把各个单一的职责串联成真实世界的复杂的逻辑关系,这就是一个触发机制,形成了一个触发链。观察者模式可以完美地实现这里的链条形式。)
++++缺点B.1:观察者模式需要考虑开发效率和运行效率问题,一个被观察者,多个观察者,开发和调试就会比较复杂,消息的通知默认是顺序执行,一个观察者卡壳,会影响整体的执行效率。(在这种情况下,一般考虑采用异步的方式。)(多级触发时的效率更是让人担忧,大家在设计时注意考虑。)
++2.13.6、观察者模式的使用场景
++++场景1:关联行为场景。(需要注意的是,关联行为是可拆分的,而不是“组合”关系。)
++++场景2:事件多级触发场景。
++++场景3:跨系统的消息交换场景,如消息队列的处理机制。
++2.13.7、观察者模式适用性
++++适用性1:当一个抽象模型有两个方面,其中一个方面依赖于另一个方面。(将这两者封装在独立的对象中以使它们可以各自独立地改变和复用。)
++++适用性2:当对一个对象的改变需要同时改变其它对象,而不知道具体由多少对象有待改变。
++++适用性3:当一个对象必须通知其它对象,而它又不能假定其它对象是谁。(换言之,我们不希望这些对象时紧密耦合的。)
++2.13.8、相关模式
++++Mediator:通过封装复杂的更新语义,ChangeManager充当目标和观察者之间的中介者。
++++Singleton:ChangeManager可使用Singleton模式来保证它是唯一的并且是可全局访问的。
##2.14、模板方法模式
++2.14、模板方法模式
++++【模板方法(TemplateMethod)模式】:定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
++++模板方法模式(Template Method Pattern)是如此简单,定义:Define the skeleton of algorithm in an operation, deferring some steps to subclasses. Template Method lets subclasses redefine certain steps of an algorithm without changing the algorithm’s structure.(定义一个操作中的算法的框架,而将一些步骤延迟到子类中。使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。)
++++模板方法模式确实非常简单,其中AbstractClass叫做抽象模板,它的方法分两类:基本方法、模板方法。(基本方法也叫做基本操作,是由子类实现的方法,并且在模板方法被调用。)(模板方法:可以有一个或几个,一般是一个具体方法,也就是一个框架,实现对基本方法的调度,完成固定的逻辑。)
++++注意:为了防止恶意的操作,一般模板方法都加上final关键字,不允许被覆写。
++++注意:抽象模板中的基本方法尽量设计为protected类型,符合迪米特法则,不需要暴露的属性或方法尽量不要设置为protected类型。(实现类若非必要,尽量不要扩大父类中的访问权限。)
++++模板方法在一些开源框架中应用非常多,它提供了一个抽象类,然后开源框架谢了一堆子类。(如果你需要扩展功能,可以继承这个抽象类,然后覆写protected方法,再然后就是调用一个类似execute方法,就完成你的扩展开发,非常容易扩展的一种方式。)
++++父类建立框架,子类在重写了父类部分的方法后,再调用从父类继承的方法,产生不同的结果(这正是模板方法模式)。(曲线救国的方式实现了父类依赖子类的场景,模板方法模式就是这种效果)(把子类传递到父类的有参构造中,然后调用。)(使用反射的方式调用,使用了反射还有谁不能调用的?!)(父类调用子类的静态方法。)
++++模板方法模式的意图:定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。TemplateMethod使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。(一次性实现一个算法的不变的部分,并将可变的行为留给子类来实现。)(各子类中公共的行为应被提取出来并集中到一个公共父类中以避免代码重复。首先识别现有代码的不同之处,并且将不同之处分离为新的操作。最后,用一个调用这些新的操作的模板方法来替换这些不同的代码。)(控制子类扩展。模板方法只在特定点调用“hook”操作,这样就只允许在这些点进行扩展。)
++++模板方法是一种代码复用的基本技术。它们在类库中尤为重要,它们提取了类库中的公共行为。(模板方法导致一种反向的控制结构,这种结构有时被称为“好莱坞法则”,即,“别找我们,我们找你”。这指的是一个父类调用一个子类的操作,而不是相反。)
++2.14.1、模板方法模式的实现
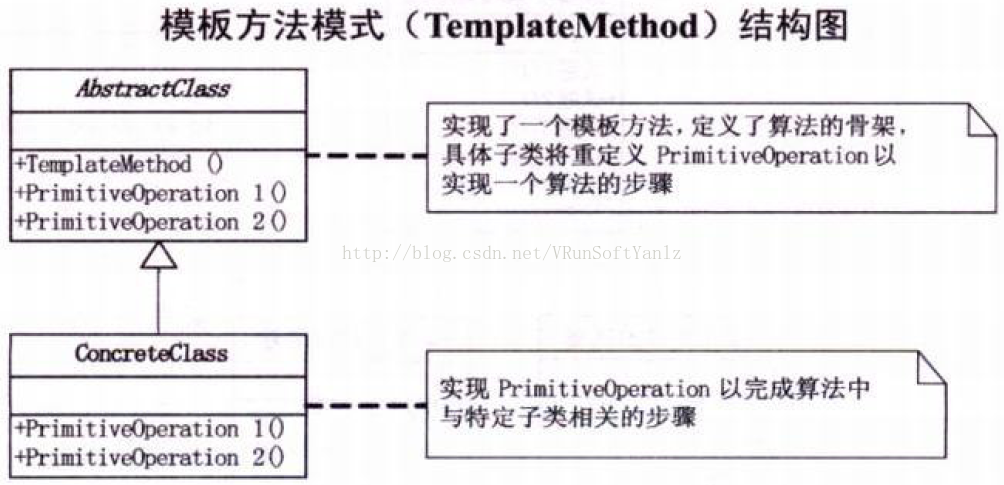
++++AbstractClass抽象类。(定义抽象的原语操作(primitive operation),具体的子类将重定义它们以实现一个算法的各步骤。)(实现一个模板方法,定义一个算法的骨架。该模板方法不仅调用原语操作,也调用定义在AbstractClass或其他对象中的操作。)
++++ConcreteClass具体类。(实现原语操作以完成算法中与特定子类相关的步骤。)
++++协作:ConcreteClass靠AbstractClass来实现算法中不变的步骤。
++++模板方法调用下列类型的操作:
--类型1:具体的操作(ConcreteClass或对客户类的操作)。
--类型2:具体的AbstractClass的操作(即,通常对子类有用的操作)。
--类型3:原语操作(即,抽象操作)。
--类型4:Factory Method。
--类型5:钩子操作(hook operations),它提供了缺省的行为,子类可以在必要时进行扩展。(钩子操作在缺省操作通常是一个空操作。)
++++很重要的一点是模板方法应该指明哪些操作是钩子操作(可以被重定义)以及哪些是抽象操作(必须被重定义)。要有效地重用一个抽象类,子类编写者必须明确了解哪些操作是设计为有待重定义的。(子类可以通过重定义父类的操作来扩展该操作的行为,其间可显式地调用父类操作。)(我们可以将一个操作转换为一个模板方法,以使得父类可以对子类的扩展方式进行控制。也就是,在父类的模板方法中调用钩子操作。)
++2.14.2、模板方法模式的代码
++++AbstractClass是抽象类,其实也就是一抽象模板,定义并实现了一个模板方法。这个模板方法一般是一个具体方法,它给出了一个顶级逻辑的骨架,而逻辑的组成步骤在相应的抽象操作中,推迟到子类实现。顶级逻辑也有可能调用一些具体方法。
abstract class AbstractClass{
//一些抽象行为,放到子类去实现
public abstract void PrimitiveOperation1();
public abstract void PrimitiveOperation2();
//模板方法,给出了逻辑的骨架,而逻辑的组成是一些相应的抽象操作,它们都推迟到子类实现
public void TemplateMethod(){
PrimitiveOperation1();
PrimitiveOperation2();
Console.WriteLine(“”);
}
}
++++ConcreteClass,实现父类所定义的一个或多个抽象方法。每一个AbstractClass都可以有任意多个ConcreteClass与之对应,而每一个ConcreteClass都可以给出这些抽象方法(也就是顶级逻辑的组成步骤)的不同实现,从而使得顶级逻辑的实现各不相同。
class ConcreteClassA :AbstractClass{
public override void PrimitiveOperation1(){
Console.WriteLine(“立钻哥哥Print:具体类A方法1实现”);
}
public override void PrimitiveOperation2(){
Console.WriteLine(“立钻哥哥Print:具体类A方法2实现”);
}
}
class ConcreteClassB :AbstractClass{
public override void PrimitiveOperation1(){
Console.WriteLine(“立钻哥哥Print:具体类B方法1实现”);
}
public override void PrimitiveOperation2(){
Console.WriteLine(“立钻哥哥Print:具体类B方法2实现”);
}
}
++++客户端调用:
static void Main(string[] args){
AbstractClass c;
c = new ConcreteClassA();
c.TemplateMethod();
c = new ConcreteClassB();
c.TemplateMethod();
Console.Read();
}
++2.14.3、模板方法模式特点:
++++特点1:模板方法模式是通过把不变行为搬移到超类,去除子类中的重复代码来体现它的优势。
++++特点2:模板方法模式就是提供了一个很好的代码复用平台。
++++特点3:当不变的和可变的行为在方法的子类实现中混合在一起的时候,不变的行为就会在子类中重复出现。我们通过模板方法模式把这些行为搬移到单一的地方,这样就帮助子类摆脱重复的不变行为的纠缠。
++2.14.4、模板方法模式的优缺点
++++优点1:封装不变部分,扩展可变部分。(把认为是不变部分的算法封装到父类实现,而可变部分的则可以通过继承来继承扩展。)
++++优点2:提取公共部分代码,便于维护。
++++优点3:行为由父类控制,子类实现。(基本方法是由子类实现的,因此子类可以通过扩展的方式增加相应的功能,符合开闭原则。)
++++缺点1:按照我们的设计习惯,抽象类负责声明最抽象、最一般的事物属性和方法,实现类完成具体的事物属性和方法。但是模板方法模式却颠倒了,抽象类定义了部分抽象方法,由子类实现,子类执行的结果影响了父类的结果,也就是子类对父类产生了影响,这在复杂的项目中,会带来代码阅读的难度,而且也会让新手产生不适感。
++++模板方法模式的使用场景:
--场景1:多个子类有公有的方法,并且逻辑基本相同时。
--场景2:重复、复杂的算法,可以把核心算法设计为模板方法,周边的相关细节功能则由各个子类实现。
--场景3:重构时,模板方法模式是一个经常使用的模式,把相同的代码抽取到父类中,然后通过钩子函数约束其行为。(有了钩子方法,模板方法模式才算完美,由子类的一个方法返回值决定公共部分的执行结果,是不是很有吸引力呀!)
++2.14.5、相关模式
++++Factory Method模式常被模板方法调用。
++++Strategy:模板方法使用继承来改变算法的一部分。(Strategy使用委托来改变整个算法。)
##2.15、命令模式
++2.15、命令模式
++++【命令模式(Command)】:将一个请求封装为一个对象,从而使我们可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作。
++++命令模式是一个高内聚的模式,定义:Encapsulate a request as an object, thereby letting you parameterize clients with different requests, queue or long requests, and support undoable operations.(将一个请求封装成一个对象,从而让我们使用不同的请求把客户端参数化,对请求排队或者记录请求日志,可以提供命令的撤销和恢复功能。)
++++命令模式比较简单,但是在项目中非常频繁地使用,因为它的封装性非常好,把请求方(Invoker)和执行方(Receiver)分开了,扩展性也有很好的保障,通用代码比较简单。
++++命令模式的意图:将一个请求封装为一个对象,从而使我们可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作。(有时必须向某对象提交请求,但并不知道关于被请求的操作或请求的接受者的任何信息。)
++2.15.1、命令模式的实现
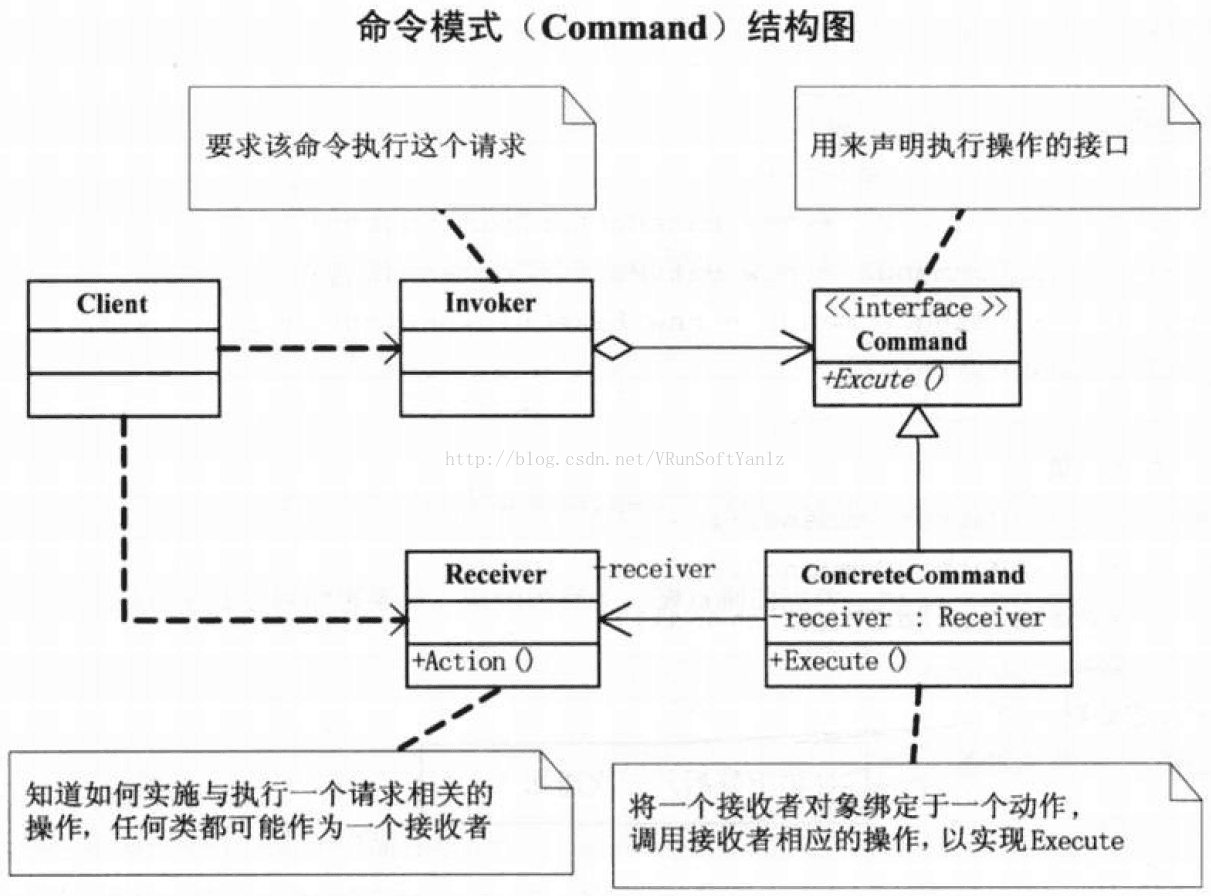
++++Receiver接收者角色。(该角色就是干活的角色,命令传递到这里是应该被执行的。)(知道如何实施与执行一个请求相关的操作。任何类都可能作为一个接收者。)
++++Command命令角色。(需要执行的所有命令都在这里声明。)(声明执行操作的接口。)
++++ConcreteCommand。(将一个接收者对象绑定于一个动作。)(调用接收者相应的操作,以实现Execute。)
++++Client。(创建一个具体命令对象并设定它的接收者。)
++++Invoker调用者角色。(接收到命令,并执行命令。)(要求该命令执行这个请求。)
++++实践:每一个模式到实际应用的时候都有一些变形,命令模式的Receiver在实际应用中一般都会被封装掉,那是因为在项目中:约定的优先级最高,每一个命令是对一个或多个Receiver的封装,我们可以在项目中通过有意义的类名或命令处理命令角色和接受者角色耦合关系(这就是约定),减少高层模块(Client类)对低层模块(Receiver角色类)的依赖关系,提高系统整体的稳定性。(在实际的项目开发时采用封闭Receiver的方式,减少Client对Receiver的依赖。)
++++协作:Client创建一个ConcreteCommand对象并指定它的Receiver对象。(某Invoker对象存储该ConcreteCommand对象。)(该Invoker通过调用Command对象的Execute操作来提交一个请求。若该命令是可撤销的,ConcreteCommand就在执行Excute操作之前存储当前状态以用于取消该命令。)(ConcreteCommand对象对调用它的Receiver的一些操作以执行该请求。)
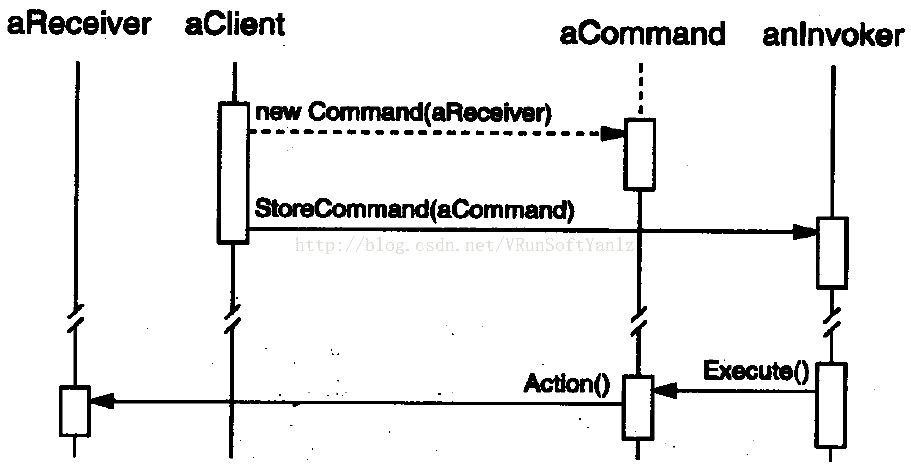
++2.15.2、命令模式的代码
++++Command类,用来声明执行操作的接口。
abstract class Command{
protected Receiver receiver;
public Command(Receiver receiver){
this.receiver = receiver;
}
abstract public void Execute();
}
++++ConcreteCommand类,将一个接受者对象绑定于一个动作,调用接受者相应的操作,以实现Execute。
class ConcreteCommand :Command{
public ConcreteCommand(Receiver receiver) :base(receiver){
}
public override void Execute(){
receiver.Action();
}
}
++++Invoker类,要求改命令执行这个请求。
class Invoker{
private Command command;
public void SetCommand(Command command){
this.command = command;
}
public void ExecuteCommand(){
command.Execute();
}
}
++++Receiver类,知道如何实施与执行一个与请求相关的操作,任何类都可能作为一个接受者。
class Receiver{
public void Action(){
Console.WriteLine(“立钻哥哥Print:执行请求!”);
}
}
++++客户端代码,创建一个具体命令对象并设定它的接受者。
static void Main(string[] args){
Receiver r = new Receiver();
Command c = new ConcreteCommand(r);
Invoker i= new Invoker();
i.SetCommand();
i.ExecuteCommand();
Console.Read();
}
++2.15.3、命名模式的作用
++++作用1:它能较容易地设计一个命令队列;
++++作用2:在需要的情况下,可以较容易地将命令记入日志;
++++作用3:允许接收请求的一方决定是否要否决请求。
++++作用4:可以容易地实现对请求的撤销和重做;
++++作用5:由于加进新的具体命令类不影响其他的类,因此增加新的具体命令类很容易。
++++作用6:命令模式把请求一个操作的对象与知道怎么执行一个操作的对象分隔开。
++++提示:敏捷开发原则告诉我们,不要为代码添加基于猜测的、实际不需要的功能。如果不清楚一个系统是否需要命令模式,一般就不要着急去实现它,事实上,在需要的时候通过重构实现这个模式并不困难,只有在真正需要如撤销/恢复操作等功能时,把原来的代码重构为命令模式才有意义。
++2.15.4、命令模式的优缺点
++++优点1:类间解耦。(调用者角色与接收者之间没有任何依赖关系,调用者实现功能时只须调用Command抽象类的execute方法就可以,不需要了解到底是哪个接收者执行。)
++++优点2:可扩展性。(Command的子类可以非常容易地扩展,而调用者Invoker和高层次的模块Client不产生严重的代码耦合。)
++++优点3:命令模式结合其他模式会更优秀。(命令模式可以结合责任链模式,实现命令族解析任务;结合模板方法模式,则可以减少Command子类的膨胀问题。)
++++缺点1:如果有N个命令,问题就出来了,Command的子类就有N个,这个类膨胀得非常大,在项目中慎重考虑使用。
++++场景1:只要认为是命令的地方就可以采用命令模式。(在GUI开发中,一个按钮的点击是一个命令,可以采用命令模式。)(触发-反馈机制的处理。)
++2.15.5、相关模式
++++Composite模式可被用来实现宏命令。
++++Memento模式可用来保持某个状态,命令用这一状态来取消它的效果。
++++在被放入历史表列前必须被拷贝的命令起到一种原型的作用。
##2.16、状态模式
++2.16、状态模式
++++【状态模式(State)】:当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类。
++++状态模式主要解决的是当控制一个对象状态转换的条件表达式过于复杂时的情况。(把状态的判断逻辑转移到表示不同状态的一系列类当中,可以把复杂的判断逻辑简化。)
++++状态模式的好处是将与特定状态的行为局部化,并且将不同状态的行为分割开来。(将特定的状态相关的行为都放入一个对象中,由于所有与状态相关的代码都存在于某个ConcreteState中,所以通过定义新的子类可以很容易地增加新的状态和转换。)(消除庞大的条件分支语句。)(状态模式通过把各种状态转移逻辑分布到State的子类之间,来减少相互间的依赖。)(当一个对象的行为取决于它的状态,并且它必须在运行时刻根据状态改变它的行为时,就可以考虑使用状态模式了。)
++++状态模式的定义:Allow an object to alter its behaviour when its internal state changes. The object will appear to change its class.(当一个对象内在状态改变时允许其改变行为,这个对象看起来像改变了其类。)
++++状态模式的核心是封装,状态的变化引起了行为的变更,从外部看起来就好像这个对象对应的类发生了改变一样。
++++状态模式相对来说比较复杂,它提供了一种对物质运动的另一个观察视角,通过状态变更促使行为的变化。
++++状态模式适用于当某个对象在它的状态发生改变时,它的行为也随着发生比较大的变化,也就是说在行为受状态约束的情况下可以使用状态模式,而且使用时对象的状态最好不要超过5个。
++++状态模式的意图:允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。(状态模式也叫:状态对象(Objects for States))
++2.16.1、状态模式的实现
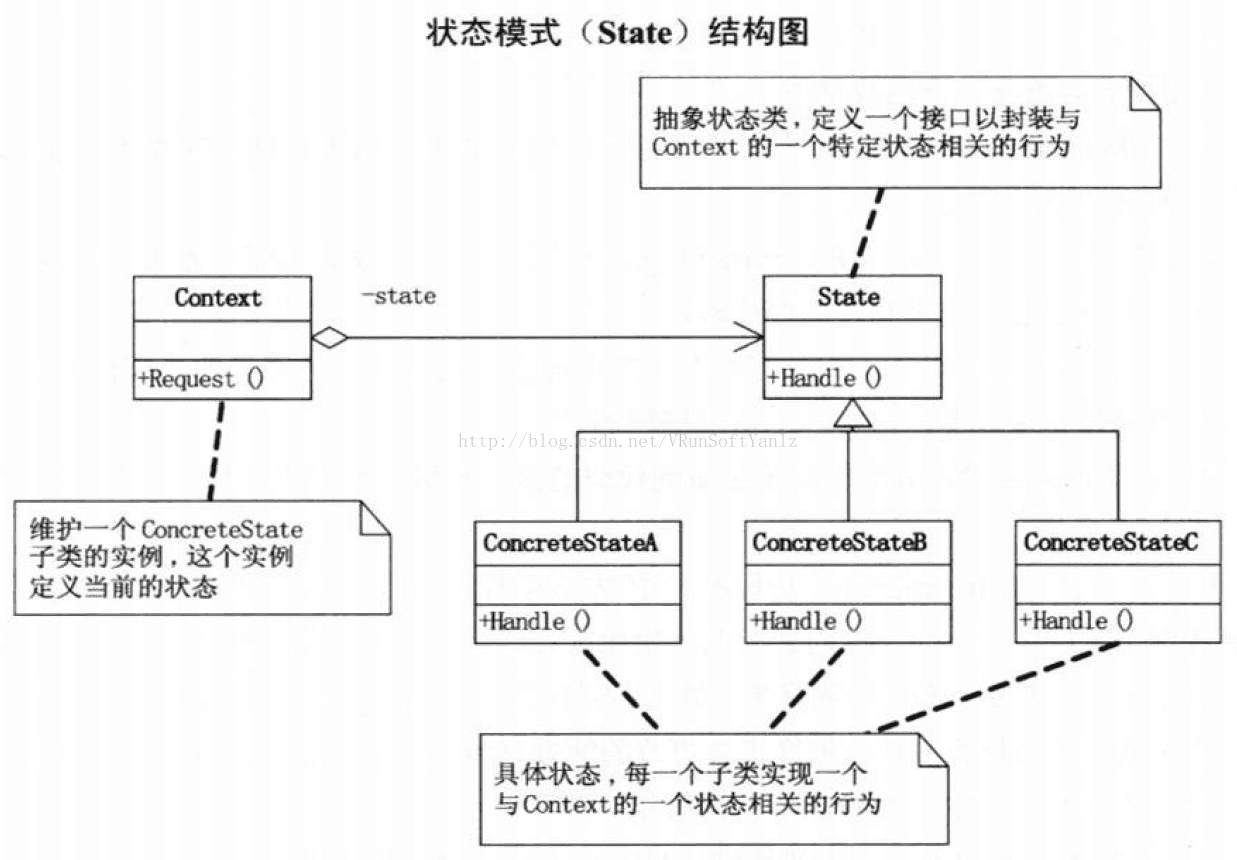
++++State:抽象状态角色。(接口或抽象类,负责对象状态定义,并且封装环境角色以实现状态切换。)(定义一个封装以封装与Context的一个特定状态相关的行为。)
++++ConcreteState:具体状态角色。(每一个具体状态必须完成两个职责:本状态的行为管理以及趋向状态处理,就是本状态下要做的事情,以及本状态如何过渡到其他状态。)(每一子类实现一个与Context的一个状态相关的行为。)
++++Context:环境角色。(定义客户端需要的接口,并且负责具体状态的切换。)(定义客户感兴趣的接口。)(维护一个ConcreteState子类的实例,这个实例定义当前的状态。)
++++适用性1:一个对象的行为取决于它的状态,并且它必须在运行时刻根据状态改变它的行为。
++++适用性2:一个操作中含有庞大的多分支的条件语句,且这些分支依赖于该对象的状态。这个状态通常用一个或多个枚举常量表示。(通常,有多个操作包含这一相同条件结构。)(State模式将每一个条件分支放入一个独立的类中。这使得我们可以根据对象自身的情况将对象的状态作为一个对象,这一对象可以不依赖于其他对象而独立变化。)
++++协作:Context将与状态相关的请求委托给当前的ConcreteState对象处理。(Context可将自身作为一个参数传递给处理该请求的状态对象。这使得状态对象在必要时可访问Context。)(Context是客户使用的主要接口。客户可用状态对象来配置一个Context,一旦一个Context配置完毕,它的客户不再需要直接与状态对象打交道。)(Context或ConcreteState子类都可决定哪个状态是另外哪一个的后继者,以及是在何种条件下进行状态转换。)
++2.16.2、状态模式的代码
++++State类,抽象状态类,定义一个接口以封装与Context的一个特定状态相关的行为。
abstract class State{
public abstract void Handle(Context context);
}
++++ConcreteState类,具体状态,每一个子类实现一个与Context的一个状态相关的行为。
class ConcreteStateA :State{
//设置ConcreteStateA的下一状态是ConcreteStateB
public override void Handle(Context context){
context.State = new ConcreteStateB();
}
}
class ConcreteStateB :State{
public override void Handle(Context context){
context.State = new ConcreteStateA();
}
}
++++Context类,维护一个ConcreteState子类的实例,这个实例定义当前的状态。
class Context{
private State state;
//定义Context的初始状态
public Context(State state){
this.state = state;
}
//可读写的状态属性,用于读取当前状态和设置新状态
public State State{
get{ return state; }
set{
state = value;
Console.WriteLine(“立钻哥哥Print:当前状态:” + state.GetType().Name);
}
}
public void Request(){
//对请求做处理,并设置下一状态
state.Handle(this);
}
}
++++客户端代码:
static void Main(string[] args){
//设置Context的初始状态为ConcreteStateA
Context c = new Context(new ConcreteStateA());
//不断的请求,同时更改状态
c.Request();
c.Request();
c.Request();
c.Request();
Console.Read();
}
++2.16.3、状态模式的优缺点
++++优点1:结构清晰。(避免了过多的switch...case或者if...else语句的使用,避免了程序的复杂性,提高系统的可维护性。)
++++优点2:遵循设计原则。(很好地体现了开闭原则和单一职责原则,每个状态都是一个子类,要增加状态就要增加子类,要修改状态,只修改一个子类就可以了。)
++++优点3:封装性非常好。(这是状态模式的基本要求,状态变换放置到类的内部来实现,外部的调用不用知道类内部如何实现状态和行为的变换。)
++++缺点1:状态模式只有一个缺点:子类会很多,类膨胀。(如果一个事物有很多个状态,完全使用状态模式就会有太多的子类,不好管理。)
++++使用场景1:行为随状态而改变的场景。(这是状态模式的根本出发点,例如权限设计,人员的状态不同即使执行相同的行为结果也会不同,在这种情况下需要考虑使用状态模式。)
++++使用场景2:条件、分支判断语句的替代者。(在程序中大量使用switch语句或者if判断语句会导致程序结构不清晰,逻辑混乱,使用状态模式可以很好地避免这一问题,它通过扩展子类实现了条件的判断处理。)
++2.16.4、相关模式
++++Flyweight模式解释了何时以及怎样共享状态对象。
++++状态对象通常是Singleton。
##2.17、职责链模式
++2.17、职责链模式
++++【职责链模式(Chain of Responsibility)】:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这个对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
++++职责链的好处:当客户提交一个请求时,请求是沿链传值直至有一个ConcreteHandler对象负责处理它。(接收者和发送者都没有对象的明确信息,且链中的对象自己也并不知道链的结构。结果是职责链可简化对象的相互连接,它们仅需保持一个指向其后继者的引用,而不需保持它所有的候选接受者的引用。)(随时地增加或修改处理一个请求的结构。增强了对象指派职责的灵活性。)(缺点:一个请求极有可能到了链的末端都得不到处理,或者因为么有正确配置而得不到处理。)
++++职责链模式定义:Avoid coupling the sender of a request to its receiver by giving more than one object a chance to handle the request. Chain the receiving objects and pass the request along the chain until an object handles it.(使多个对象都有机会处理请求,从而避免了请求的发送者和接受者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有对象处理它为止。)
++++职责链模式的重点在“链”上,由一条链去处理相似的请求在链中决定谁来处理这个请求,并返回相应的结果。(在职责链模式中一个请求发送到链中后,前一节点消费部分消息,然后交由后续节点继续处理,最终可以有处理结果也可以没有处理结果。)
++++职责链模式屏蔽了请求的处理过程,我们发起一起请求到底是谁处理的,只要把请求抛给职责链的第一个处理者,最终会返回一个处理结果(当然也可以不做任何处理),作为请求者可以不用知道到底是需要谁来处理的,这是职责链模式的核心,同时职责链模式也可以作为一种补救模式来使用。
++++职责链模式的意图:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
++2.17.1、职责链模式的实现
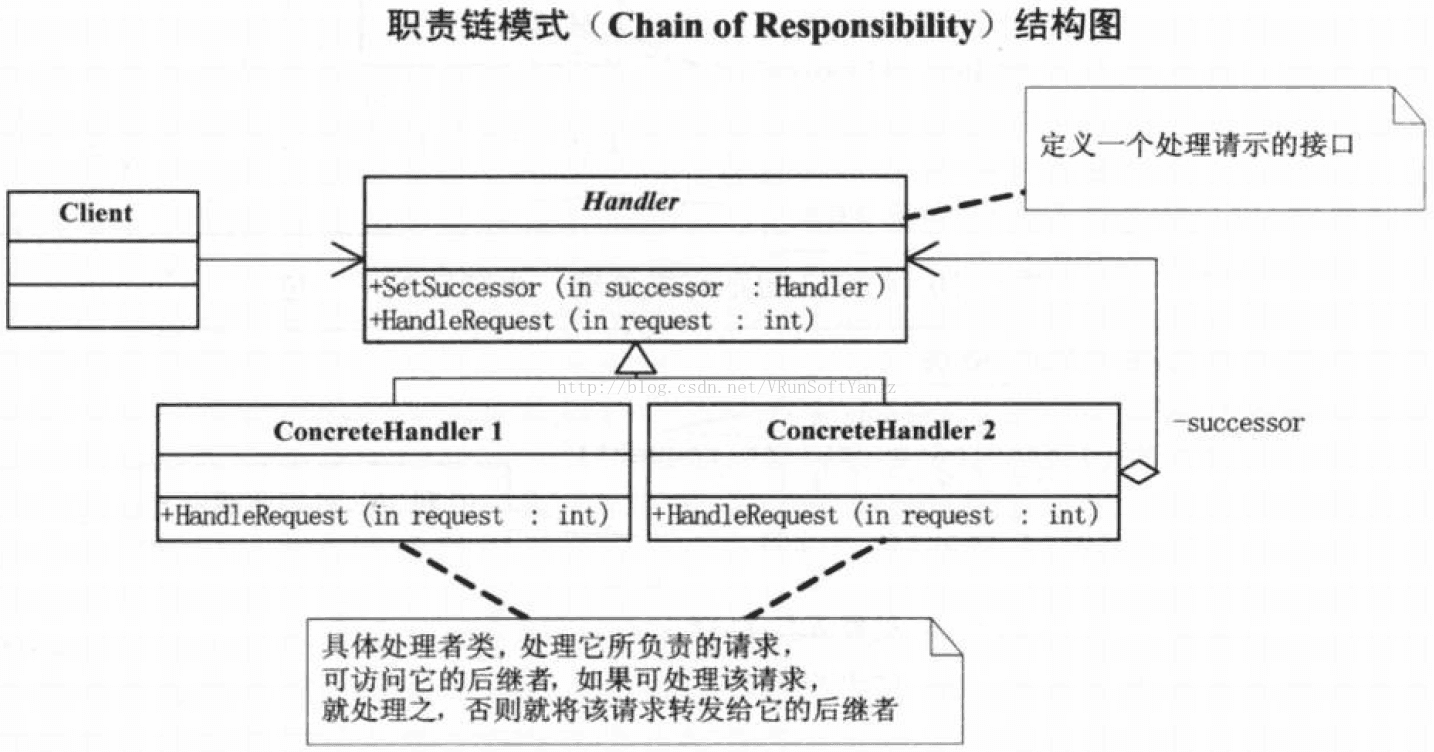
++++Handler。(定义一个处理请求的接口。)(实现后继链。)
++++ConcreteHandler。(处理它所负责的请求。)(可访问它的后继者。)(如果可处理该请求,就处理之;否则将该请求转发给它的后继者。)
++++Client。(向链上的具体处理者(ConcreteHandler)对象提交请求。)
++++适用性:有多个的对象可以处理一个请求,哪个对象处理该请求运行时刻自动确定。(你想在不明确指定接收者的情况下,向多个对象中的一个提交一个请求。)(可处理一个请求的对象集合应被动态指定。)
++++协作:当客户提交一个请求时,请求沿链传递直到有一个ConcreteHandler对象负责处理它。
++2.17.2、职责链模式代码
++++Handler类,定义一个处理请示的接口。
abstract class Handler{
protected Handler successor;
//设置继任者
public void SetSuccessor(Handler successor){
this.successor = successor;
}
//处理请求的抽象方法
public abstract void HandleRequest(int request);
}
++++ConcreteHandler类,具体处理者类,处理它所负责的请求,可访问它的后继者,如何可处理该请求,就处理之,否则就将该请求转发给它的后继者。
++++ConcreteHandler1,当请求数在0到10之间则有权处理,否则转到下一位。
class ConcreteHandler1 :Handler{
public override void HandleRequest(int request){
//0到10,处理此请求
if(request >=0&& request <10){
Console.WriteLine(“立钻哥哥Print: {0}处理请求{1}”, this.GetType().Name, request);
}else if(successor != null){
//转移到下一位
successor.HandleRequest(request);
}
}
}
++++ConcreteHandler2,当请求输在10到20之间则有权处理,否则转到下一位。
class ConcreteHandler2 :Handler{
public override void HandleRequest(int request){
//10到20,处理此请求
if(request>=10&& request<20){
Console.WriteLine(“立钻哥哥Print: {0}处理请求{1}”, this.GetType().Name, request);
}else if(successor != null){
//转到下一位
successor.HandlerRequest(request);
}
}
}
++++ConcreteHandler3,当请求数在20到30之间则有权处理,否则转到下一位。
class ConcreteHandler3 :Handler{
public override void HandleRequest(int request){
//20到30,处理此请求
if(request>=20&&request<30){
Console.WriteLine(“立钻哥哥Print: {0}处理请求{1}”, this.GetType().Name, request);
}else if(successor != null){
//转移到下一位
successor.HandleRequest(request);
}
}
}
++++客户端代码,向链上的具体处理者对象提交请求。
static void Main(string[] args){
Handler h1= new ConcreteHandler1();
Handler h2= new ConcreteHandler2();
Handler h3= new ConcreteHandler3();
//设置职责链上家和下家
h1.SetSuccessor(h2);
h2.SetSuccessor(h3);
int[] requests= { 2, 5, 14, 22, 18, 3, 27, 20 };
foreach(int request in requests){
//循环给最小处理者提交请求,不同的数额,由不同权限处理者处理
h1.HandleRequest(request);
}
Console.Read();
}
++2.17.3、职责链模式的优缺点
++++优点1:职责链模式非常显著的优点是将请求和处理分开。(请求者可以不用知道是谁处理的,处理者可以不用知道请求的全貌。)
++++缺点1:性能问题,每个请求都是从链头遍历到链尾,特别是在链比较长的时候,性能是一个非常大的问题。
++++缺点2:调试不方便,特别是链条比较长,环节比较多的时候,由于采用了类似递归的方式,调试的时候逻辑可能比较复杂。
++++注意事项1:链中节点数量需要控制,避免出现超长链的情况,一般的做法是在Handler中设置一个最大节点数量,在setNext方法中判断是否已经是超过其阀值,超过则不允许该链建立,避免无意识地破坏系统性能。
++2.17.4、相关模式
++++职责链常与Composite一起使用。这种情况下,一个构件的父构件可作为它的后继。
##2.18、解释器模式
++2.18、解释器模式
++++【解释器模式(interpreter)】:给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
++++如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。(这样就可以构件一个解释器,该解释器通过解释这些句子来解决该问题。)
++++当一个语言需要解释执行,并且我们可将该语言中的句子表示为一个抽象语法树时,可使用解释器模式。(容易地改变和扩展文法,因为该模式使用类来表示文法规则,我们可使用继承来改变或扩展该文法。也比较容易实现文法,因为定义抽象语法树中各个节点的类的实现大体类似,这些类都易于直接编写。)
++++解释器模式的不足:解释器模式为文法中的每一条规则至少定义了一个类,因此包含许多规则的文法可能难以管理和维护。(建议当文法非常复杂时,使用其他的技术如语法分析程序或编译器生成器来处理。)
++++解释器模式(Interpreter Pattern)是一种按照规定语法进行解析的方案,定义:Given a language, define a representation for its grammar along with an interpreter that uses the representation to interpret sentences in the language.(给定一门语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。)
++++解释器模式在实际的系统开发中使用得非常少,因为它会引起效率、性能以及维护等问题,一般在大中型的框架型项目能够找到它的身影,如一些数据分析工具、报表设计工具、科学计算工具等。
++++解释器模式的意图:给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。(如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。)
++2.18.1、解释器模式的实现
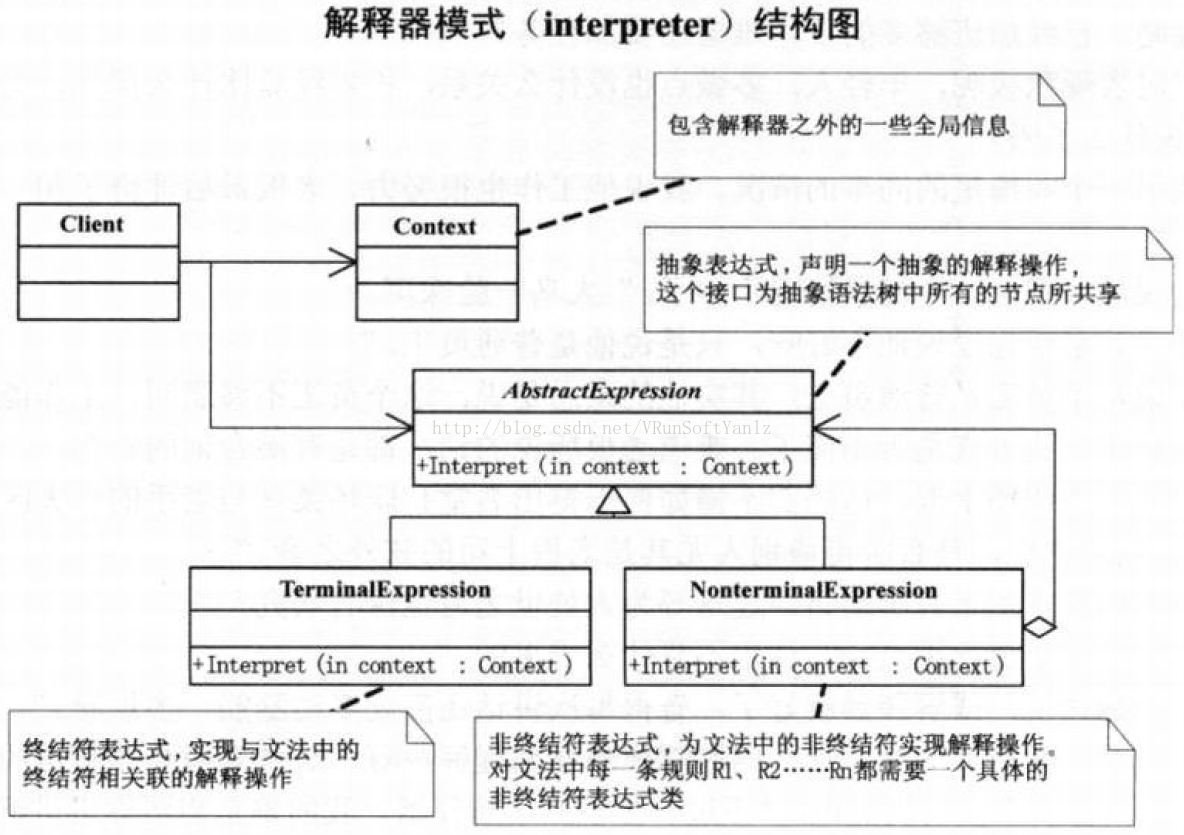
++++AbstractExpression:抽象解释器。(具体的解释任务由各个实现类实现,具体的解释器分别由TerminalExpression和NonterminalExpression完成。)(声明一个抽象的解释操作,这个接口为抽象语法树中所有的节点所共享。)
++++TerminalExpression:终结符表达式。(实现与文法中的元素相关联的解释操作,通常一个解释器模式只有一个终结符表达式,但有多个实例,对应不同的终结符。)(实现与文法中的终结符相关联的解释操作。)(一个句子中的每个终结符需要该类的一个实例。)
++++NonterminalExpression:非终结符表达式。(文法中的每条规则对应于一个非终结表达式。非终结符表达式根据逻辑的复杂程度而增加,原则上每个文法规则都对应一个非终结符表达式。)(对文法中的每一条规则R::=R1R2...Rn都需要一个NonterminalExpression类。)(为从R1到Rn的每个字符都维护一个AbstractExpression类型的实例变量。)(为文法中的非终结符实现解释(Interpret)操作。解释(Interpret)一般要递归地调用表示R1到R2的那些对象的解释操作。)
++++Context:环境角色。(上下文。)(包含解释器之外的一些全局信息。)
++++Client(客户)。(构建(或被给定)表示该文法定义的语言中一个特定的句子的抽象语法树。该抽象语法树由NonterminalExpression和TerminalExpression的实例装配而成。)(调用解释操作。)
++++适用性:当有一个语言需要解释执行,并且我们可将该语言中的句子表示为一个抽象语法树时,可使用解释器模式。(该文法简单。对于复杂的文法,文法的类层次变得庞大而无法管理。此时语法分析程序生成器这样的工具是更好的选择。它们无需构建抽象语法树即可解释表达式,这样可以节省空间而且还可能节省时间。)(效率不是一个关键问题。最高效的解释器通常不是通过直接解释语法分析树实现的,而是首先将它们转换成另一种形式。例如,正则表达式通常被转换成状态机。但即使在这种情况下,转换器仍可用解释器模式实现,该模式仍是有用的。)
++++协作:Client构建(或被给定)一个句子,它是NonterminalExpression和TerminalExpression的实例的一个抽象语法树,然后初始化上下文并调用解释操作。(每一非终结符表达式节点定义相应子表达式的解释操作。而各终结符表达式的解释操作构成了递归的基础。)(每一节点的解释操作用上下文来存储和访问解释器的状态。)
++2.18.2、解释器模式的代码
++++AbstractExpression(抽象表达式),声明一个抽象的解释操作,这个接口为抽象语法树中所有的节点所共享。
abstract class AbstractExpression{
public abstractvoid Interpret(Context context);
}
++++TerminalExpression(终结符表达式),实现与文法中的终结符相关联的解释操作。实现抽象表达式中所要求的接口,主要是一个interpret()方法。文法中每一个终结符都有一个具体终结表达式与之相对应。
class TerminalExpression :AbstractExpression{
public override void Interpret(Context context){
Console.WriteLine(“立钻哥哥Print:终端解释器”);
}
}
++++NonterminalExpression(非终结符表达式),为文法中的非终结符实现解释操作。对文法中每一条规则R1、R2......Rn都需要一个具体的非终结符表达式类。通过实现抽象表达式的interpret()方法实现解释操作。解释操作以递归方式调用上面所提到的代表R1、R2、......、Rn中各个符号的实例变量。
class NonterminalExpression :AbstractExpression{
public override void Interpret(Context context){
Console.WriteLine(“立钻哥哥Print:非终端解释器”);
}
}
++++Context,包含解释器之外的一些全局信息。
class Context{
private string input;
public string Input{
get{ return input; }
set{ input = value; }
}
privatestringoutput;
public string Output{
get{ return output; }
set{ output = value; }
}
}
++++客户端代码,构建表示该文法定义的语言中一个特定的句子的抽象语法树。调用解释操作。
static void Main(string[]args){
Context context = new Context();
List<AbstractExpression> list = new List<AbstractExpression>();
list.Add(new TerminalExpression());
list.Add(new NonterminalExpression());
list.Add(new TerminalExpression());
list.Add(new TerminalExpression());
foreach(AbstractExpreesion exp in list){
exp.Interpret(context);
}
Console.Read();
}
++++结果显示:
终端解释器
非终端解释器
终端解释器
终端解释器
++2.18.3、解释器模式的优缺点
++++优点1:解释器是一个简单语法分析工具,它最显著的优点就是扩展性,修改语法规则只要修改相应的非终结符表达式就可以了,若扩展语法,则只要增加非终结符类就可以了。
++++缺点1:解释器模式会引起类膨胀。(每个语法都要产生一个非终结符表达式,语法规则比较复杂时,就可能产生大量的类文件,为维护带来了非常多的麻烦。)
++++缺点2:解释器模式采用递归调用方法。(每个非终结符表达式只关心与自己有关的表达式,每个表达式需要知道最终的结果,必须一层一层地剥茧,无论是面向过程的语言还是面向对象的语言,递归都是在必要条件下使用的,它导致调试非常复杂。如果要排查一个语法错误,要一个一个断点地调试下去,直到最小的语法单元。)
++++缺点3:效率问题。(解释器模式由于使用了大量的循环和递归,效率是一个不容忽略的问题,特别是用于解析复杂、冗长的语法时,效率是难以忍受的。)
++++使用场景1:重复发生的问题可以使用解释器模式。
++++使用场景2:一个简单语法需要解释的场景。(解释器模式一般用来解析比较标准的字符集。)
++++注意事项1:尽量不要在重要的模块中使用解释器模式,否则维护会是一个很大的问题。
++2.18.4、相关模式
++++Composite模式:抽象语法树是一个复合模式的实例。
++++Flyweight模式:说明了如何在抽象语法树中共享终结符。
++++Iterator:解释器可用一个迭代器遍历该结构。
++++Visitor:可用来在一个类中维护抽象语法树中的各节点的行为。
##2.19、中介者模式
++2.19、中介者模式
++++【中介者模式(Mediator)】:用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
++++中介者模式一般应用于一组对象以定义良好但是复杂的方式进行通信的场合,以及想定制一个分布在多个类中的行为,而又不想生成太多的子类的场合。
++++中介者模式的定义:Define an object that encapsulates how a set of objects interact. Mediator promotes loose coupling by keeping objects from referring to each other explicitly, and it lets you vary their interaction independently.(用一个中介对象封装一系列的对象交互,中介者使各对象不需要显式地相互作用,从而使其耦合松散,而且可以独立地改变它们之间的交互。)
++++中介者模式的优点就是减少类间的依赖,把原有的一对多的依赖变成了一对一的依赖,同事类只依赖中介者,减少了依赖,当然同时也降低了类间的耦合。
++++中介者模式的缺点就是中介者会膨胀得很大,而且逻辑复杂,原本N个对象直接的相互依赖关系转换为中介者和同事类的依赖关系,同事类越多,中介者的逻辑就越复杂。
++++中介者模式简单,但是简单不代表容易使用,很容易被误用。(在面向对象的编程中,对象和对象之间必然会有依赖关系,如果某个类和其他类没有任何相互依赖的关系,那这个类就是一个“孤岛”,在项目中就没有存在的必要了)(中介者模式适用于多个对象之间紧密耦合的情况,紧密耦合的标准是:在类图中出现了蜘蛛网状结构。在这种情况下一定要考虑使用中介者模式,这有利于把蜘蛛网梳理为星型结构,使原本复杂混乱的关系变得清晰简单。)
++++中介者模式也叫做调停者模式,一个对象要和N多个对象交流,就像对象间的战争,很混乱。(这是,需要加入一个中心,所有的类都和中心交流,中心说怎么处理就怎么处理。)
++++中介者模式是一个非常好的封装模式,也是一个很容易被滥用的模式,一个对象依赖几个对象是再正常不过的事情,但是纯理论家就会要求使用中介者模式来封装这种依赖关系,这是非常危险的!(使用中介者模式就必然会带来中介者的膨胀问题,这在一个项目中是很不恰当的。)
++++中介者模式的意图:用一个中介对象来封装一系列的对象交互。(中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。)
++2.19.1、中介者模式的实现
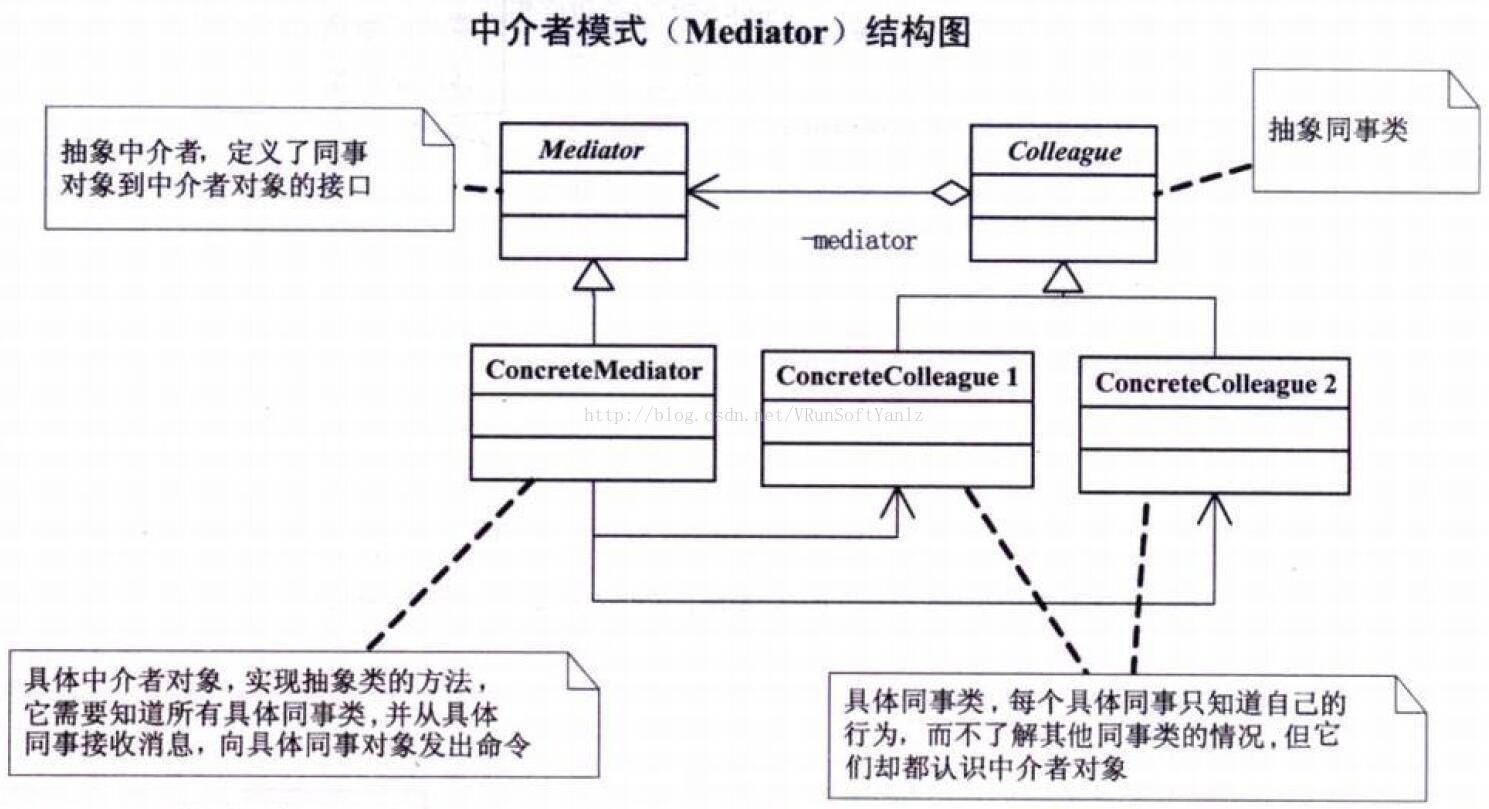
++++Mediator:抽象中介者角色。(抽象中介者角色定义统一的接口,用于各同事角色之间的通信。)(中介者定义一个接口用于与各同事(Colleague)对象通信。)
++++Concrete Mediator:具体中介者角色。(具体中介者角色通过协调各同事角色实现协作行为,因此它必须依赖于各个同事角色。)(具体中介者通过协调各同事对象实现协作行为。)(了解并维护它的各个同事。)
++++Colleague:同事角色。(每一个同事角色都知道中介者角色,而且与其他的同事角色通信的时候,一定要通过中介者角色协作。)(每个同事类的行为分为两种:一种是同事本身的行为,比如改变对象本身的状态,处理自己的行为等,这种方法叫做自发行为(Self-Method),与其他的同事类或中介者没有任何的依赖;第二种是必须依赖中介者才能完成的行为,叫做依赖方法(Dep-Method)。)(每一个同事类都知道它的中介者对象。)(每一个同事对象在需与其他的同时通信的时候,与它的中介者通信。)
++++适用性:一组对象以定义良好但是复杂的方式进行通信,产生的相互依赖关系结构混乱且难以理解。(一个对象引用其他很多对象并且直接与这些对象通信,导致难以复用该对象。)(想定制一个分布在多个类中的行为,而又不想生成太多的子类。)
++++协作:同事向一个中介者对象发送和接收请求。(中介者在各同事间适当地转发请求以实现协作行为。)
++2.19.2、中介者模式的代码
++++Colleague叫做抽象同事类,而ConcreteColleague是具体同事类,每个具体同事只知道自己的行为,而不了解其他同事类的情况,但它们却都认识中介者对象,Mediator是抽象中介者,定义了同事对象到中介者对象的接口,ConcreteMediator是具体中介者对象,实现抽象类的方法,它需要知道所有具体同事类,并从具体同事接收消息,向具体同事对象发出命令。
++++Mediator类(抽象中介者类)
abstract class Mediator{
//定义一个抽象的发送消息方法,得到同事对象和发送消息
public abstract void Send(string message,Colleague colleague);
}
++++Colleague类(抽象同事类)
abstract class Colleague{
protected Mediatormediator;
// 构造方法,得到中介者对象
public Colleague(Mediator mediator){
this.mediator = mediator;
}
}
++++ConcreteMediator类(具体中介者类)
class ConcreteMediator :Mediator{
private ConcreteColleague1 colleague1;
private ConcreteColleague2 colleague2;
//需要了解所有的具体同事对象
public ConcreteColleague1 Colleague1{
set{ colleague1 = value; }
}
public ConcreteColleague2 Colleague2{
set{ colleague2 = value; }
}
//重写发送消息的方法,根据对象做出选择判断,通知对象
public overridevoid Send(string message,Colleague colleague){
if(colleague == colleague1){
colleague2.Notify(message);
}else{
colleague1.Notify(message);
}
}
}
++++ConcreteColleague1和ConcreteColleague2等各种同事对象。
class ConcreteColleague1 :Colleague{
public ConcreteColleague1(Mediator mediator) :base(mediator){
}
//发送消息时通常是中介者发送出去的
public void Send(string message){
mediator.Send(message,this);
}
public void Notify(string message){
Console.WriteLine(“立钻哥哥Print:同事1得到消息:” + message);
}
}
class ConcreteColleague2 :Colleague{
public ConcreteColleague2(Mediator mediator) :base(mediator){
}
public void Send(string message){
mediator.Send(message, this);
}
public void Notify(string message){
Console.WriteLine(“立钻哥哥Print:同事2得到信息:” + message);
}
}
++++客户端调用:
static void Main(string[] args){
ConcreteMediator m = newConcreteMediator();
//让两个具体同事类认识中介者对象
ConcreteColleague1 c1= newConcreteColleague1(m);
ConcreteColleague2 c2= newConcreteColleague2(m);
//让中介者认识各个各个具体同事类对象
m.Colleague1 = c1;
m.Colleague2 = c2;
c1.Send(“立钻哥哥:吃过饭了吗?”);
c2.Send(“立钻哥哥:没有呢,你打算请客?”);
Console.Read();
}
++2.19.3、中介者模式优缺点
++++优点A.1、减少了子类生成。(Mediator将原本分布于多个对象间的行为集中在一起。改变这些行为只需生成Meditator的子类即可。这样各个Colleague类可被重用。)
++++优点A.2、它将各Colleague解耦。(Mediator有利于各Colleague间的松耦合,可以独立的改变和复用各Colleague类和Mediator类。)
++++优点A.3、它简化了对象协议。(用Mediator和各Colleague间的一对多的交互来代替多对多的交互。一对多的关系更易于理解、维护和扩展。)
++++优点A.4、它对对象如何协作进行了抽象。(将中介作为一个独立的概念并将其封装在一个对象中,使我们将注意力从对象各自本身的行为转移到它们之间的交互上来。这有助于弄清楚一个系统中的对象是如何交互的。)
++++缺点A.1、它使控制集中化。(中介者模式将交互的复杂性变为中介者的复杂性。因为中介者封装了协议,它可能变得比任一个Colleague都复杂。这可能使得中介者自身成为一个难于维护的庞然大物。)
++++中介者模式很容易在系统中应用,也很容易在系统中误用。(当系统出现了“多对多”交互复杂的对象群时,不要急于使用中介者模式,而要先反思你的系统在设计上是不是合理。)
++++优点B.1:Mediator的出现减少了各个Colleague的耦合,使得可以独立地改变和复用各个Colleague类和Mediator,由于把对象如何协作进行了抽象,将中介作为一个独立的概念并将其封装在一个对象中,这样关注的对象就从对象各自本身的行为转移到它们之间的交互上来,也就是站在一个更宏观的角度去看待系统。
++++缺点B.1:由于ConcreteMediator控制了集中化,于是就把交互复杂性变味了中介者的复杂性,这就使得中介者会变得比任何一个ConcreteColleague都复杂。
++2.19.4、中介者模式的实际应用
++++中介者模式也叫做调停者模式,一个对象要和N多个对象交流,就像对象间的战争,很混乱。这是,需要加入一个中心,所有的类都和中心交流,中心说怎么处理就怎么处理。
++++应用1:机场调度中心。
++++应用2:MVC框架。(C(Controller)就是一个中介者,叫做前端控制器(Front Controller),它的作用就是把M(Model,业务逻辑)和V(View,视图)隔离开,协调M和V协同工作,把M运行的结果和V代表的视图融合成一个前端可展示的页面,减少M和V的依赖关系。)(MVC框架已经成为一个非常流行、成熟的开发框架,这也是中介者模式的优点的一个体现。)
++++应用3:媒体网关。
++++应用4:中介服务。
++2.19.5、相关模式
++++Facade与中介者的不同之处在于它是对一个对象子系统进行抽象,从而提供了一个更为方便的接口。它的协议是单向的,即Facade对象对这个子系统类提出请求,但反之则不行。相反,Mediator提供了各Colleague对象不支持或不能支持的协作行为,而且协议是多向的。
++++Colleague可使用Observer模式与Mediator通信。
##2.20、访问者模式
++2.20、访问者模式
++++【访问者模式(Visitor)】:表示一个作用于某对象结构中的各元素的操作。它使我们可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
++++访问者模式适用于数据结构相对稳定的系统。(它把数据结构和作用于结构上的操作之间的耦合解脱开,使得操作集合可以相对自由地演化。)
++++访问者模式的目的是要把处理从数据结构分离出来。(有比较稳定的数据结构,又有易于变化的算法的话,使用访问者模式就是比较合适的,因为访问者模式使得算法操作的增加变得容易。)
++++访问者模式的优点就是增加新的操作很容易,因为增加新的操作就意味着增加一个新的访问者。(访问者模式将有关的行为集中到一个访问者对象中。)
++++访问者的缺点就是增加新的数据结构变得困难了。
++++访问者模式的能力和复杂性是把双刃剑,只有当我们真正需要它的时候,才考虑使用它。(不要为了展示自己的面向对象的能力或是沉迷于模式当中,往往会误用这个模式,所以一定要好好理解它的适用性。)
++++访问者模式(Visitor Pattern)是一个相对简单的模式,定义:Represent an operation to be performed on the elements of an object structure. Visitor lets you define a new operation without changing the classes of the elements on which it operates.(封装一些作用于某种数据结构中的各元素的操作,它可以在不改变数据结构的前提下定义作用于这些元素的新的操作。)
++++访问者模式是一种集中规则模式,特别适用于大规模重构的项目,在这一阶段需求已经非常清晰,原系统的功能点也已经明确,通过访问者模式可以很容易把一些功能进行梳理,达到最终目的:功能集中化。
++++访问者模式的意图:表示一个作用于某对象结构中的各元素的操作。它使我们可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
++2.20.1、访问者模式的实现
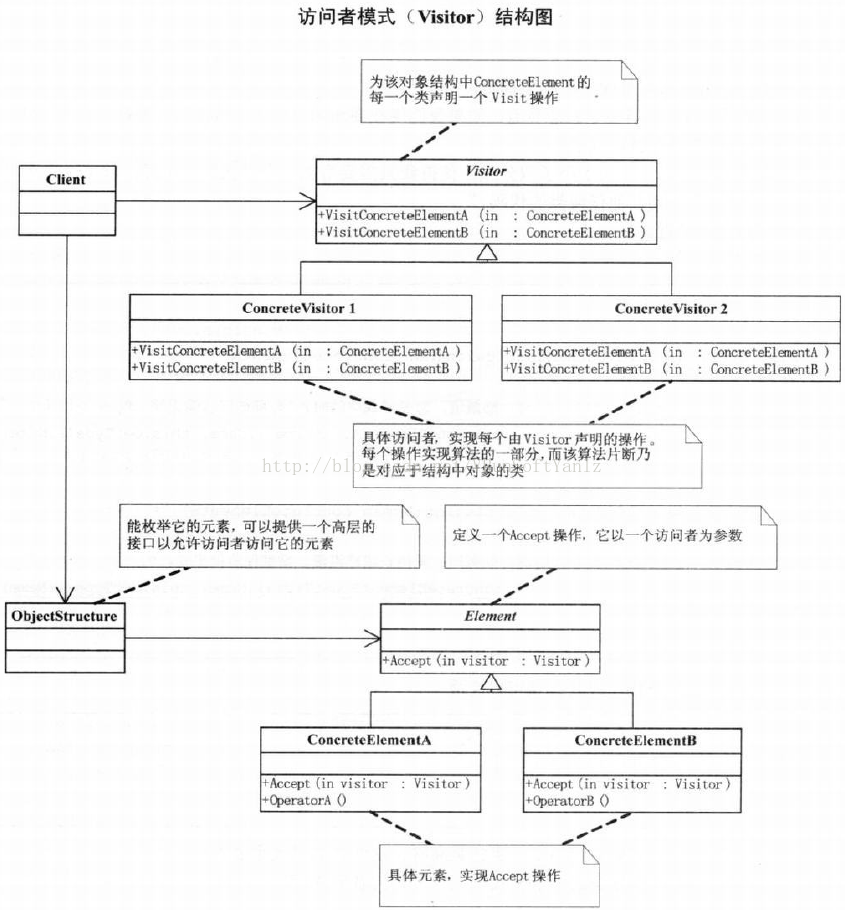
++++Visitor:抽象访问者。(抽象类或者接口,声明访问者可以访问哪些元素,具体到程序中就是visit方法的参数定义哪些对象是可以被访问的。)(为该对象结构中ConcreteElement的每一个类声明一个Visit操作。该操作的名字和特征标识了发送Visit请求给该访问者的那个类。这使得访问者可以确定正被访问元素的具体的类。这样访问者就可以通过该元素的特定接口直接访问它。)
++++ConcreteVisitor:具体访问者。(它影响访问者访问到一个类后该怎么干,要做什么事情。)(实现每个由Visitor声明的操作。每个操作实现本算法的一部分,而该算法片段乃是对应于结构中的对象的类。ConcreteVisitor为该算法提供了上下文并存储它的局部状态。这一状态常常在遍历该结构的过程中累计结果。)
++++Element:抽象元素。(接口或者抽象类,声明接受哪一类访问者访问,程序上是通过accept方法中的参数来定义的。)(抽象元素有两类方法:一是本身的业务逻辑,也就是元素作为一个业务处理单元必须完成的职责;另外一个是允许哪一个访问者来访问。)(定义一个Accept操作,它以一个访问者为参数。)
++++ConcreteElement:具体元素。(实现accept方法,通常是visitor.visit(this),基本上都形成了一种模式了。)(实现Accept操作,该操作以一个访问者为参数。)
++++ObjectStruture:结构对象。(元素产生者,一般容纳在多个不同类、不同接口的容器,如List、Set、Map等。在项目中,一般很少抽象出这个角色。)(能枚举它的元素。)(可以提供一个高层的接口以允许该访问者访问它的元素。)(可以是一个复合(Composite模式)或者一个集合,如一个列表或一个无序集合。)
++++适用性:一个对象结构包含很多类对象,它们有不同的接口,而我们想对这些对象实施一些依赖于其具体类的操作。(需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而我们想避免让这些操作“污染”这些对象的类。Visitor使得我们可以将相关的操作集中起来定义在一个类中。当该对象结构被很多应用共享时,用Visitor模式让每个应用仅包含需要用到的操作。)
++++协作:一个使用Visitor模式的客户必须创建一个ConcreteVisitor对象,然后遍历该对象结构,并用该访问者访问每一个元素。(当一个元素被访问时,它调用对应于它的类的Visitor操作。如果必要,该元素将自身作为这个操作的一个参数以便使访问者访问它的状态。)
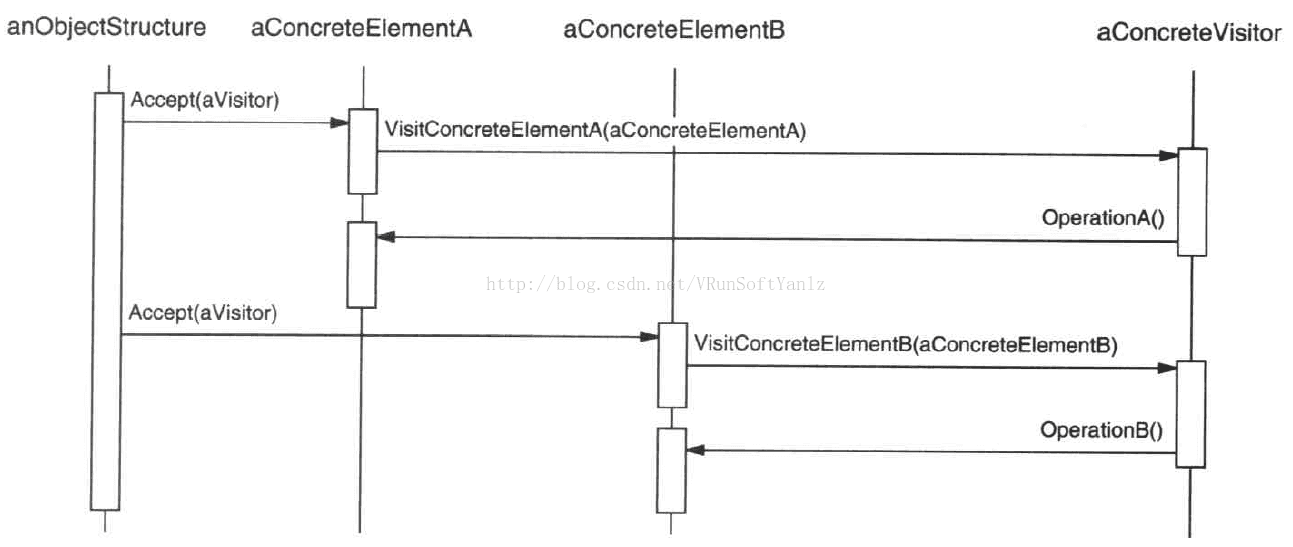
++2.20.2、访问者模式的代码
++++Visitor类,为该对象结构中ConcreteElement的每一个类声明一个Visit操作。
abstract class Visitor{
public abstract void VisitConcreteElementA(ConcreteElementA concreteElementA);
public abstractvoid VisitConcreteElementB(ConcreteElementB concreteElementB);
}
++++ConcreteVisitor1和ConcreteVisitor2类,具体访问者,实现每个由Visitor声明的操作。每个操作实现算法的一部分,而该算法片段乃是对应于结构中对象的类。
class ConcreteVisitor1 :Visitor{
public override void VisitConcreteElementA(ConcreteElementA concreteElementA){
Console.WriteLine(“立钻哥哥Print: {0}被{1}访问”, concreteElementA.GetType().Name, this.GetType().Name);
}
public override void VisitConcreteElementB(ConcreteElementB concreteElementB){
Console.WriteLine(“立钻哥哥Print: {0}被{1}访问”, concreteElementB.GetType().Name, this.GetType().Name);
}
}
class ConcreteVisitor2 :Visitor{
//代码与上类类似,省略....
}
++++Element类,定义一个Accept操作,它以一个访问者为参数:
abstract class Element{
public abstract void Accept(Visitor visitor);
}
++++ConcreteElementA和ConcreteElementB类,具体元素,实现Accept操作。
class ConcreteElementA :Element{
//充分利用双分派技术,实现处理与数据结构的分离。
public overridevoid Accept(Visitor visitor){
visitor.VisitConcreteElementA(this);
}
//其他的相关方法
public void OperationA(){
}
}
class ConcreteElementB :Element{
public overridevoid Accept(Visitor visitor){
visitor.VisitConcreteElementB(this);
}
public void OperationB(){
}
}
++++ObjectStructure类,能枚举它的元素,可以提供一个高层的接口以允许访问者访问它的元素。
class ObjectStructure{
private List<Element> elements= new List<Element>();
public void Attach(Element element){
elements.Add(element);
}
public void Detach(Element element){
elements.Remove(element);
}
public void Accept(Visitor visitor){
foreach(Element e in elements){
e.Accept(visitor);
}
}
}
++++客户端代码:
static void Main(string[] args){
ObjectStructure o = newObjectStructure();
o.Attach(new ConcreteElementA());
o.Attach(new ConcreteElementB());
ConcreteVisitor1 v1= new ConcreteVisitor1();
ConcreteVisitor2 v2= new ConcreteVisitor2();
o.Accept(v1);
o.Accept(v2);
Console.Read();
}
++2.20.3、访问者模式的优缺点
++++优点A.1、访问者模式使得易于增加新的操作。(访问者使得增加依赖于复杂对象结构的构件的操作变得容易了。仅需增加一个新的访问者即可在一个对象结构上定义一个新的操作。相反,如果每个功能都分散在多个类之上的话,定义新的操作时必须修改每一类。)
++++优点A.2、访问者集中相关的操作而分离无关的操作。(相关的行为不是分布在定义该对象结构的各个类上,而是集中在一个访问者中。无关行为却被分别放在它们各自的访问者子类中。这就既简化了这些元素的类,也简化了再这些访问者中定义的算法。所有与它的算法相关的数据结构都可以被隐藏在访问者中。)
++++缺点A.1、增加新的ConcreteElement类很困难.(Visitor模式使得难以增加新的Element的子类。每添加一个新的ConcreteElement都要在Vistor中添加一个新的抽象操作,并在每一个ConcretVisitor类中实现相应的操作。有时可以在Visitor中提供一个缺省的实现,这一实现可以被大多数的ConcreteVisitor继承,但这与其说是一个规律还不如说是一种例外。)(在应用访问者模式时考虑关键的问题是系统的哪个部分会经常变化,是作用于对象结构上的算法呢还是构成该结构的各个对象的类。如果老是有新的ConcreteElement类加入进来的话,Visitor类层次将变得难以维护。在这种情况下,直接在构成该结构的类中定义这些操作可能更容易一些。如果Element类层次时稳定的,而我们不断地增加操作或修改算法,访问者模式可以帮助我们管理这些改动。)
++++说明1:通过类层次进行访问。(一个迭代器(Iterator模式)可以通过调用节点对象的特定操作来遍历整个对象结构,同时访问这些对象。但是迭代器不能对具有不同元素类型的对象结构进行操作。)
++++说明2:累计状态。(当访问者访问对象结构中的每一个元素时,它可能会累积状态。如果没有访问者,这一状态将作为额外的参数传递给进行遍历的操作,或者定义为全局变量。)
++++说明3:破坏封装。(访问者方法假定ConcreteElement接口的功能足够强,足以让访问者进行它们的工作。结果是,该模式常常迫使我们提供访问元素内部状态的公共操作,这可能会破坏它的封装性。)
++++优点B.1:符合单一职责原则。(具体元素角色也就是Employee抽象类的两个子类负责数据的加载,而Visitor类则负责报表的展现,两个不同的职责非常明确地分离开来,各自演绎变化。)
++++优点B.2:优秀的扩展性。(由于职责分开,继续增加对数据的操作是非常快捷的。)
++++优点B.3:灵活性非常高。
++++缺点B.1:具体元素对访问者公布细节。(访问者要访问一个类就必然要求这个类公布一些方法和数据,也就是说访问者关注了其他类的内部细节,这是迪米特法则所不建议的。)
++++缺点B.2:具体元素变更比较困难。(具体元素角色的增加、删除、修改都是比较困难的。)
++++缺点B.3:违背了依赖倒置原则。(访问者依赖的是具体元素,而不是抽象元素,这破坏了依赖倒置原则,特别是在面向对象的编程中,抛弃了对接口的依赖,而直接依赖实现类,扩展比较难。)
++++使用场景1:一个对象结构包含很多类对象,它们有不同的接口,而我们想对这些对象实施一些依赖于其具体类的操作。(也就是说用迭代器模式已经不能胜任的情景。)
++++使用场景2:需要对一个对象结构中的对象进行很多不同并且不相关的操作,而我们想避免让这些操作“污染”这些对象的类。
++++使用场景3:一定要考虑使用访问者模式的场景:业务规则要求遍历多个不同的对象。(这本身也是访问者模式出发点,迭代器模式只能访问同类或同接口的数据,而访问者模式是对迭代器模式的扩充,可以遍历不同的对象,然后执行不同的操作,也就是针对访问的对象不同,执行不同的操作。)
++2.20.4、相关模式
++++Composite:访问者可以用于对一个由Composite模式定义的对象结构进行操作。
++++Interpreter:访问者可以用于解释。
##2.21、策略模式
++2.21、策略模式
++++【策略模式(Strategy)】:它定义了算法家族,分别封装起来,让它们之间可以相互替换,此模式让算法的变化,不会影响到使用算法的客户。
++++策略模式是一种定义一系列算法的方法,从概念上来看,所有这些算法完成的都是相同的工作,只是实现不同,它可以以相同的方式调用所有的算法,减少了各种算法类与使用算法类之间的耦合。(策略模式的Strategy类层次为Context定义了一系列的可供重用的算法或行为。继承有助于析取出这些算法中的公共功能。)
++++策略模式的优点是简化了单元测试,因为每个算法都有自己的类,可以通过自己的接口单独测试。
++++当不同的行为堆砌在一个类中时,就很难避免使用条件语句来选择合适的行为。(将这些行为封装在一个个独立的Strategy类中,可以在使用这些行为的类中消除条件语句。)
++++策略模式就是用来封装算法的,但在实践中,我们发现可以用它来封装几乎任何类型的规则,只要在分析过程中听到需要在不同时间应用不同的业务规则,就可以考虑使用策略模式处理这种变化的可能性。
++++在基本的策略模式中,选择所用具体实现的职责由客户端对象承担,并转给策略模式的Context对象。
++++策略模式(Strategy Pattern)是一种比较简单的模式,也叫做政策模式(Policy Pattern),定义:Define a family of algorithms, encapsulate each one, and make them interchangeable.(定义一组算法,将每个算法都封装起来,并且使它们之间可以互换。)
++++策略模式使用的就是面向对象的继承和多态机制,非常容易理解和掌握。
++++策略模式的意图:定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。
++2.21.1、策略模式的实现
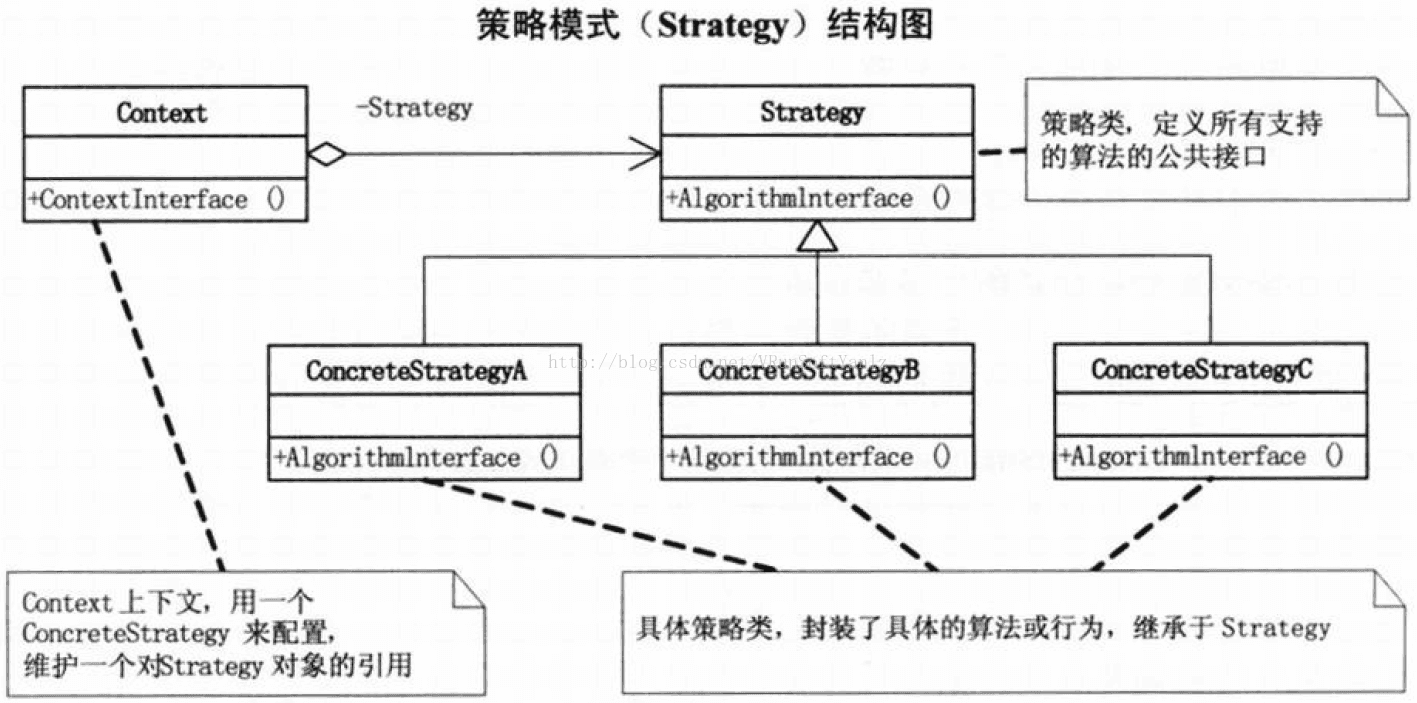
++++Context封装角色。(它也叫做上下文角色,起承上启下封装作用,屏蔽高层模块对策略、算法的直接访问,封装可能存在的变化。)(用一个ConcreteStrategy对象类配置。)(维护一个对Strategy对象的引用。)(可定义一个接口来让Stategy访问它的数据。)
++++Strategy抽象策略角色。(策略、算法家族的抽象,通常为接口,定义每个策略或算法必须具有的方法和属性。)(定义所有支持的算法的公共接口。Context使用这个接口来调用某ConcreteStrategy定义的算法。)
++++ConcreteStrategy具体策略角色。(实现抽象策略中的操作,该类含有具体的算法。)(以Strategy接口实现某具体算法。)
++++策略模式是一个非常简单的模式。(它在项目中使用得非常多,但它单独使用的地方就比较少了,因为它有致命缺陷:所有的策略都需要暴露出去,这样才方便客户端决定使用哪一个策略。)(策略模式只是实现了锦囊的管理,没有严格定义“适当的场景”拆开“适当的锦囊”,在实际项目中,我们一般通过工厂方法模式来实现策略类的声明。)
++++适用性:许多相关的类仅仅是行为有异。“策略”提供了一种用多个行为中的一个行为来配置一个类的方法。(需要使用一个算法的不同变体。)(算法使用客户不应该知道的数据。可使用策略模式以避免暴露复杂的、与算法相关的数据结构。)(一个类定义了多种行为,兵器这些行为在这个类的操作中以多个条件语句的形式出现。将相关的条件分支移入它们各自的Strategy类中以代替这些条件语句。)
++++协作:Strategy和Context相互作用以实现选定的算法。当算法被调用时,Context可以将该算法所需要的所有数据都传递给该Strategy。或者,Context可以将自身作为一个参数传递给Strategy操作。这就让Strategy在需要时可以回调Context。(Context将它的客户的请求转发给它的Strategy。客户通常创建并传递衣蛾ConcreteStrategy对象给该Context;这样,客户仅与Context交互。通常有一系列的ConcreteStrategy类可供客户从中选择。)
++2.21.2、策略模式的代码
++++Strategy类,定义所有支持的算法的公共接口
//抽象算法类
abstract class Strategy{
//算法方法
public abstract void AlgorithmInterface();
}
++++ConcreteStrategy,封装了具体的算法或行为,继承于Strategy
//具体算法A
class ConcreteStrategyA :Strategy{
//算法A实现方法
public override void AlgorithmInterface(){
Console.WriteLine(“立钻哥哥Print:算法A实现”);
}
}
//具体算法B
class ConcreteStrategyB :Strategy{
//算法B实现方法
public override void AlgorithmInterface(){
Console.WriteLine(“立钻哥哥Print:算法B实现”);
}
}
//具体算法C
class ConcreteStrategyC :Strategy{
//算法C实现方法
public overridevoid AlgorithmInterface(){
Console.WriteLine(“算法C实现”);
}
}
++++Context,用一个ConcreteStrategy来配置,维护一个对Strategy对象的引用。
//上下文
class Context{
Strategy strategy;
//初始化时,传入具体的策略对象
public Context(Strategy strategy){
this.strategy = strategy;
}
//上下文接口
//根据具体的策略对象,调用其算法的方法
public void ContextInterface(){
strategy.AlgorithmInterface();
}
}
++++客户端代码:
static void Main(string[] args){
Context context;
//由于实例化不同的策略,所以最终在调用context.ContextInterface();时,所获得的结果就不尽相同
context = new Context(new ConcreteStrategyA());
context.ContextInterface();
context = new Context(new ConcreteStrategyB());
context.ContextInterface();
context = new Context(new ConcreteStrategyC());
context.ContextInterface();
Console.Read();
}
++2.21.3、策略模式的优缺点
++++说明1:相关算法系列。(Strategy类层次为Context定义了一系列的可供重用的算法或行为。继承有助于析取出这些算法中的公共功能。)
++++说明2:一个替代继承的方法。(继承提供了另一种支持多种算法或行为的方法。我们可以直接生成一个Context类的子类,从而给它以不同的行为。但这会将行为硬行编制到Context中,而将算法的实现与Context的实现混合起来,从而使Context难以理解、难以维护和难以扩展,而且还不能动态地改变算法。最后我们得到一堆相关的类,它们之间的唯一差别是它们所使用的算法或行为。将算法封装在独立的Strategy类中使得我们可以独立于其Context改变它,使它易于切换、易于理解、易于扩展。)
++++说明3:消除了一些条件语句。(Strategy模式提供了用条件语句选择所需的行为以外的另一种选择。当不同的行为堆砌在一个类中时,很难避免使用条件语句来选择合适的行为。将行为封装在一个个独立的Strategy类中消除了这些条件语句。)
++++说明4:实现的选择。(Strategy模式可以提供相同行为的不同实现。客户可以根据不同时间/空间权衡取舍要求从不同策略中进行选择。)
++++说明5:客户必须了解不同的Strategy。(本模式有一个潜在的缺点,就是一个客户要选择一个合适的Strategy就必须知道这些Strategy到底有何不同。此时可能不得不向客户暴露具体的实现问题。因此仅当这些不同行为变体与客户相关的行为时,才需要使用Strategy模式。)
++++说明6:Strategy和Context之间的通信开销。(无论各个ConcreteStrategy实现的算法是简单还是复杂,它们都共享Strategy定义的接口。因此很可能某些ConcreteStrategy不会都用到所有通过这个接口传递给它们的信息;简单的ConcreteStrategy可能不使用其中的任何信息!这就意味着有时Context会创建和初始化一些永远不会用到的参数。如果存在这样问题,那么将需要在Strategy和Context之间更进行紧密的耦合。)
++++说明7:增加了对象的数目。(Strategy增加了一个应用中的对象的数目。有时我们可以将Strategy实现为可供各Context共享的无状态的对象来减少这一开销。任何其余的状态都由Context维护。Context在每一次对Strategy对象的请求中都将这个状态传递过去。共享的Strategy不应在各次调用之间维护状态。)
++++优点B.1:算法可以自由切换。(这是策略模式本身定义的,只要实现抽象策略,它就成为策略家族的一个成员,通过封装角色对其进行封装,保证对外提供“可自由切换”的策略。)
++++优点B.2:避免使用多重条件判断。(多重条件语句不易维护,而且出错的概率大大增强。使用策略模式后,可以由其他模块决定采用何种策略,策略家族对外提供的访问接口就是封装类,简化了操作,同时避免了条件语句判断。)
++++优点B.3:扩展性良好。(在现有的系统中增加一个策略太容易了,只要实现接口就可以了,其他都不用修改,类似于一个可反复拆卸的插件,这大大地符合了OCP原则。)
++++缺点B.1:策略类数量增多。(每一个策略都是一个类,复用的可能性很小,类数量增多。)
++++缺点B.2:所有的策略类都需要对外暴露。(上层模块必须知道有哪些策略,然后才能决定使用哪一个策略,这与迪米特法则是相违背的。我们可以使用其他模式来修正这个缺陷,如工厂方法模式、代理模式或享元模式。)
++++使用场景1:多个类只有在算法或行为上稍有不同的场景。
++++使用场景2:算法需要自由切换的场景。(算法的选择是由使用者决定的,或者算法始终在进化,特别是一些站在技术前沿的行业。)
++++使用场景3:需要屏蔽算法规则的场景。
++++注意事项1:如果系统中的一个策略家族的具体策略数量超过4个,则需要考虑使用混合模式,解决策略类膨胀和对外暴露的问题,否则日后的系统维护就会成为一个烫手山芋。
++2.21.4、相关模式
++++Flyweight:Strategy对象经常是很好的轻量级对象。
##2.22、备忘录模式
++2.22、备忘录模式
++++【备忘录(Memento)模式】:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态。
++++要保存的细节给封装在了Memento中了,哪一天要更改保存的细节也不用影响客户端了。(Memento模式比较适用于功能比较复杂的,但需要维护或记录属性历史的类,或者需要保存的属性只是众多属性中的一小部分时,Originator可以根据保存的Memento信息还原到前一状态。)
++++如果在某个系统中使用命令模式时,需要实现命令的撤销功能,那么命令模式可以使用备忘录模式来存储可撤销操作的状态。(使用备忘录可以把复杂的对象内部信息对其他的对象屏蔽起来。)
++++当角色的状态改变的时候,有可能这个状态无效,这时候就可以使用暂时存储起来的备忘录将状态复原。
++++备忘录模式(Memento Pattern)提供了一种弥补真实世界缺陷的方法,让“后悔药”在程序的世界中真实可行,定义:Without violating encapsulation, capture and externalize an object’s internal state so that the object can be restored to this state later.(在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态。)(备忘录模式就是一个对象的备份模式,提供了一种程序数据的备份方法。)
++++备忘录模式的意图:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态。
++2.22.1、备忘录模式的实现
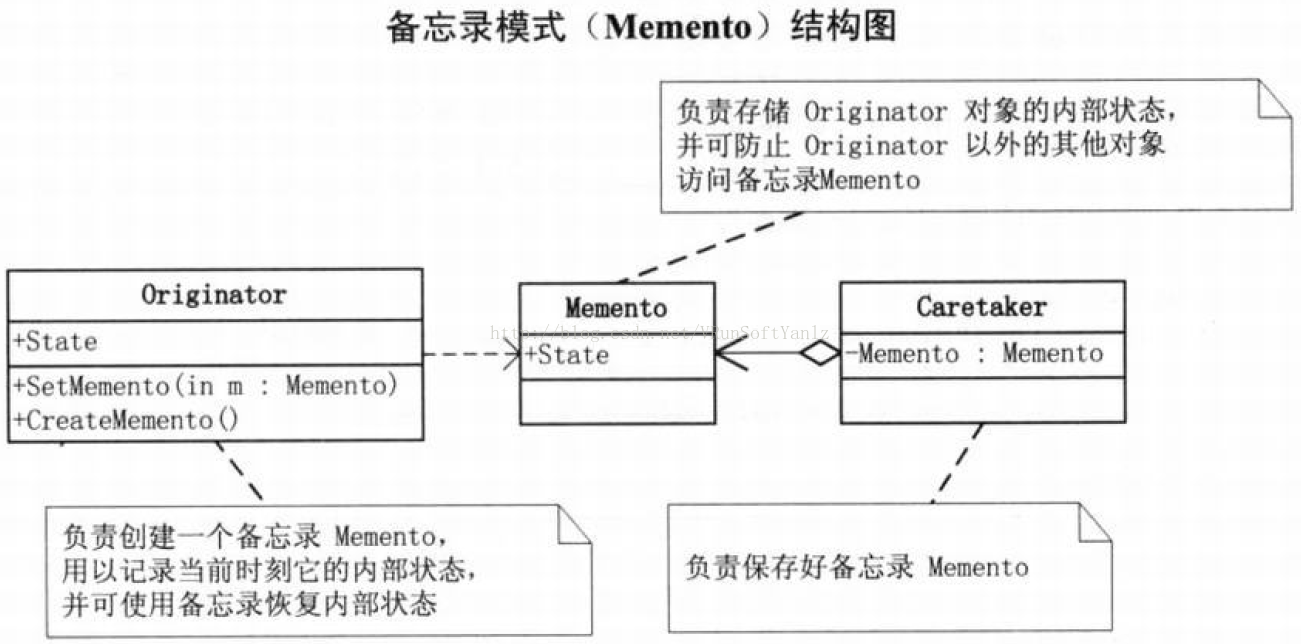
++++Originator:发起人(原发器)。(负责创建一个备忘录Memento,用以记录当前时刻它的内部状态,并可使用备忘录恢复内部状态。Originator可根据需要决定Memento存储Originator的哪些内部状态。)(记录当前时刻的内部状态,负责定义哪些属于备份范围的状态,负责创建和恢复备忘录数据。)(原发器创建一个备忘录,用以记录当前时刻它的内部状态。)(使用备忘录恢复内部状态。)
++++Memento:备忘录。(负责存储Originator对象的内部状态,并可防止Originator以外的其他对象访问备忘录Memento。)(备忘录有两个接口,Caretaker只能看到备忘录的窄接口,它只能将备忘录传递给其他对象。Originator能够看到一个宽接口,允许它访问返回到先前状态所需的所有数据。)(负责存储Originator发起人对象的内部状态,在需要的时候提供发起人需要的内部状态。)(备忘录存储原发器对象的内部状态。原发器根据需要决定备忘录存储原发器的哪些内部状态。)(防止原发器以外的其他对象访问备忘录。备忘录实际上有两个接口,管理者(caretaker)只能看到备忘录的窄接口:它只能将备忘录传递给其他对象。相反,原发器能够看到一个宽接口,允许它访问返回到先前状态所需的所有数据。理想的情况是只允许生成本备忘录的那个原发器访问本备忘录的内部状态。)
++++Caretaker:管理者。(负责保存好备忘录Memento,不能对备忘录的内容进行操作或检查。)(对备忘录进行管理、保存和提供备忘录。)(负责保存好备忘录。)(不能对备忘录的内容进行操作或检查。)
++++适用性:必须保存一个对象在某一个时刻的(部分)状态,这样以后需要时它才能恢复到先前的状态。(如果一个用接口来让其他对象直接得到这些状态,将会暴露对象的实现细节并破坏对象的封装性。)
++++协作:管理器向原发器请求一个备忘录,保存一段时间后,将其送回给原发器。(有时管理者不会将备忘录返回给原发器,因为原发器可能根本不需要退到先前的状态。)(备忘录是被动的。只有创建备忘录的原发器会对它的状态进行赋值和检索。)
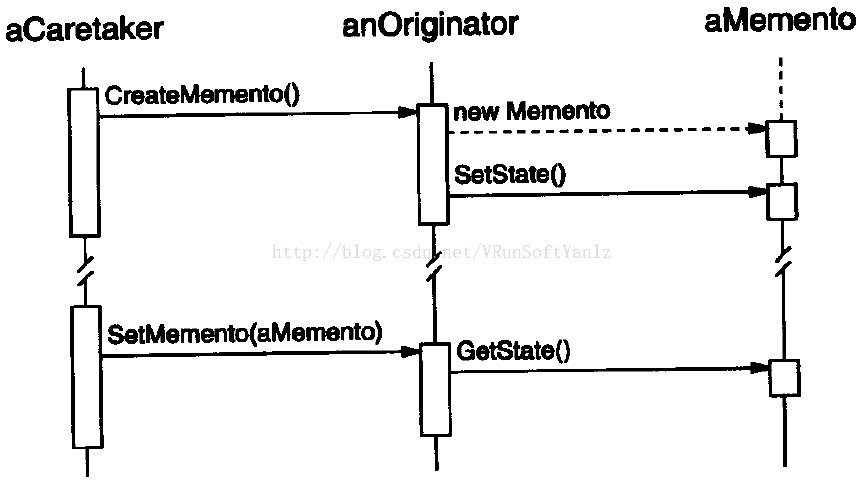
++2.22.2、备忘录模式的代码
++++发起人(Originator)类:
class Originator{
//需要保存的属性,可能有多个
private string state;
public string State{
get{ return state; }
set{ state = value; }
}
//创建备忘录,将当前需要保存的信息导入并实例化出一个Memento对象
public Memento CreateMemento(){
return (new Memento(state));
}
//恢复备忘录,将Memento导入并将相关数据恢复
public void SetMemento(Memento memento){
state = memento.State;
}
//显示数据
public void Show(){
Console.WriteLine(“立钻哥哥Print: State=” + state);
}
}
++++备忘录(Memento)类:
class Memento{
private string state;
//构造方法,将相关数据导入
public Memento(string state){
this.state=state;
}
//需要保存的数据属性,可以是多个
public string State{
get{ return state; }
}
}
++++管理者(Caretaker)类:
class Caretaker{
private Memento memento;
//得到或设置备忘录
public Memento Memento{
get{ return memento; }
set{ memento =value; }
}
}
++++客户端程序:
static void Main(string[] args){
Originator o = newOriginator();
//Originator初始状态,状态属性为“on”
o.State = “On”;
o.Show();
//保存状态时,由于有了很好的封装,可以隐藏Originator的实现细节
Caretaker c = newCaretaker();
c.Memento =o.CreateMemento();
//Originator改变了状态属性为“Off”
o.State = “Off”;
o.Show();
//恢复原初始状态
o.SetMemento(c.Memento);
o.Show();
Console.Read();
}
++2.22.3、备忘录模式的优缺点
++++由于备忘录模式有太多的变形和处理方式,每种方式都有它自己的优点和缺点,标准的备忘录模式很难在项目中遇到,基本上都有一些变换处理方式。因此,我们在使用备忘录模式时主要了解如何应用以及需要注意哪些事项就可以了。
++++使用场景1:需要保存和恢复数据的相关状态场景。
++++使用场景2:提供一个可回滚(rollback)的操作。
++++使用场景3:需要监控的副本场景中。
++++使用场景4:数据库连接的事务管理就是用的备忘录模式。
++++注意事项1:备忘录的生命期。(备忘录创建出来就要在“最近”的代码中使用,要主动管理它的生命周期,建立就要使用,不使用就要立刻删除其引用,等待垃圾回收器对它的回收处理。)
++++注意事项2:备忘录的性能。(不要在频繁建立备份的场景中使用备忘录模式(比如一个for循环中),原因有二:一是控制不了备忘录建立的对象数量;二是大对象的建立是要消耗资源的,系统的性能需要考虑。)
++2.22.4、相关模式
++++Command:命令可以使用备忘录来为可撤销的操作维护状态。
++++Iterator:备忘录可用于迭代。
##2.23、迭代器模式
++2.23、迭代器模式
++++【迭代器模式(Iterator)】:提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部表示。
++++当我们需要访问一个聚集对象,而且不管这些对象是什么都需要遍历的时候,我们就应该考虑用迭代器模式。(我们需要对聚集有多种方式遍历时,可以考虑用迭代器模式。)(为遍历不同的聚集结构提供如开始、下一个、是否结束、当前哪一项等统一的接口。)
++++迭代器(Iterator)模式就是分离了集合对象的遍历行为,抽象出一个迭代器类来复杂,这样既可以做到不暴露集合的内部结构,又可让外部代码透明地访问集合内部的数据。
++++迭代器模式(Iterator Pattern)是一个没落的模式,基本上没人会单独写一个迭代器,除非是产品性质的开发,定义:Provide a way to access the elements of an aggregate object sequentially without exposing its underlying representation.(它提供一种方法访问一个容器对象中各个元素,而又不需暴露该对象的内部细节。)
++++迭代器是为容器服务的。(能容纳对象的所有类型都可以称之为容器。迭代器模式就是为解决遍历这些容器中的元素而诞生的。)
++++迭代器模式提供了遍历容器的方便性,容器只要管理增减元素就可以了,需要遍历时交由迭代器进行。(迭代器模式正是由于使用得太频繁,所以大家才会忽略。)
++++迭代器模式的意图:提供一种方法顺序访问一个聚合对象中各个元素,而又不需暴露对象的内部表示。(一个聚合对象,如列表(list),应该提供一种方法来让别人可以访问它的元素,而又不需暴露它的内部结构。此外,针对不同的需要,可能要以不同的方式遍历这个列表。但是即使可以预见到所需的那些遍历操作,我们可能也不希望列表的接口中充斥着各种不同遍历的操作。有时还可能需要在同一个表列上同时进行多个遍历。)
++++迭代器模式的关键思想是将对列表的访问和遍历从列表对象中分离出来并放入一个迭代器(iterator)对象中。(迭代器类定义了一个访问该列表元素的接口。)(迭代器对象负责跟踪当前的元素,即,它知道哪些元素已经遍历过了。)
++++迭代器在面向对象系统中很普遍。(大多数集合类库都以不同的形式提供了迭代器。)
++2.23.1、迭代器模式的实现
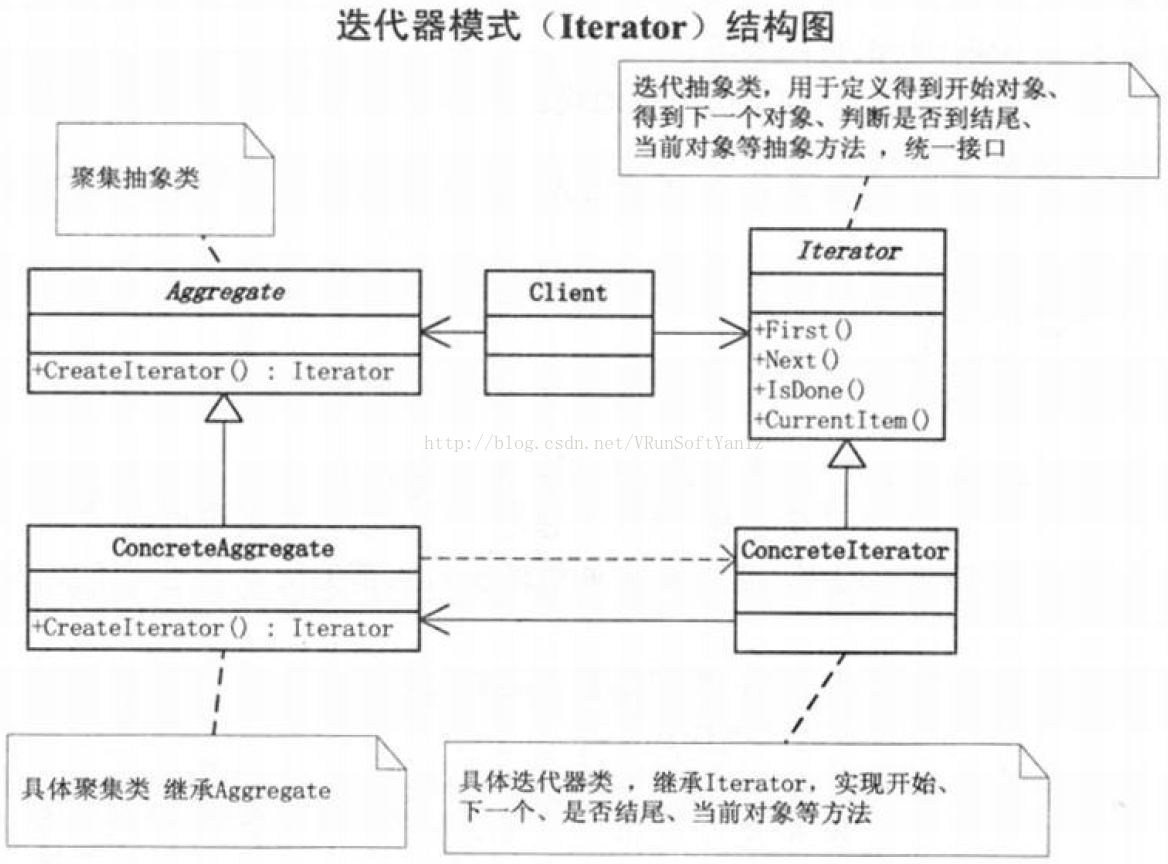
++++Iterator:抽象迭代器。(抽象迭代器负责定义访问和遍历元素的接口,而且基本上是有固定的3个方法:firest()获得第一个元素,next()访问下一个元素,isDone()是否已经访问到底部。)(迭代器定义访问和遍历元素的接口。)
++++ConcreteIterator:具体迭代器。(具体迭代器角色要实现迭代器接口,完成容器元素的遍历。)(具体迭代器实现迭代器接口。)(对该聚合遍历时跟踪当前位置。)
++++Aggregate:抽象容器(聚合)。(容器角色负责提供创建具体迭代器角色的接口,必须提供一个类似createIterator()这样的方法。)(聚合定义创建相应迭代器对象的接口。)
++++ConcreteAggregate:具体容器。(具体容器实现容器接口定义的方法,创造出容纳迭代器的对象。)(具体聚合实现创建相应迭代器的接口,该操作返回ConcreteIterator的一个适当的实例。)
++++适用性:访问一个聚合对象的内容而无需暴露它的内部表示。(支持对聚合对象的多种遍历。)(为遍历不同的聚合结构提供一个统一的接口,即支持多态迭代。)
++++协作:ConcreteIterator跟踪聚合中的当前对象,并能够计算出待遍历的后继对象。
++2.23.2、迭代器模式代码
++++Iterator迭代器抽象类
abstract classIterator{
//用于定义得到开始对象、得到下一个对象、判断是否到结尾、当前对象等抽象方法,统一接口
public abstract objectFirst();
public abstract object Next();
public abstract bool IsDone();
public abstract objectCurrentItem();
}
++++Aggregate聚集抽象类
abstract class Aggregate{
//创建迭代器
public abstract Iterator CreateIterator();
}
++++ConcreteIterator具体迭代器类,继承Iterator
class ConcreteIterator :Iterator{
//定义了一个具体聚集对象
private ConcreteAggregate aggregate;
private int current=0;
//初始化时将具体的聚集对象传入
public ConcreteIterator(ConcreteAggregate aggregate){
this.aggregate = aggregate;
}
//得到聚集的第一个对象
public override object First(){
return aggregate[0];
}
//得到聚集的下一个对象
publicoverrideobject Next(){
object ret =null;
current++;
if(current<aggregate.Count){
ret = aggregate[current];
}
returnret;
}
//判断当前是否遍历到结尾,到结尾返回true
public overridebool IsDone(){
return current >=aggregate.Count ? true: false;
}
//返回当前的聚集对象
public override object CurrentItem(){
return aggregate[current];
}
}
++++ConcreteAggregate具体聚集类,继承Aggregate
class ConcreteAggregate :Aggregate{
//声明一个List泛型变量,用于存放聚合对象,用ArrayList同样可以实现
private List<object> items= new List<object>();
public overrideIterator CreateIterator(){
return new ConcreteIterator(this);
}
public int Count{
//返回聚集总个数
get{ return items.Count; }
}
//声明一个索引器
public objectthis[int index]{
get{ return items[index]; }
set{ items.Insert(index,value); }
}
}
++++客户端代码:
static void Main(string[] args){
//聚集对象(公交车)
ConcreteAggregate a = newConcreteAggregate();
//对象数组(乘客)
a[0] =“立钻哥哥”;
a[1] =“美女1”;
a[2] =“美女2”;
a[3] =“美女3”;
a[4] = “帅哥4”;
a[5] =“帅哥5”;
//声明迭代器对象(售票员)
Iterator i= new ConcreteIterator(a);
//从第一个乘客开始
object item= i.First();
while(!i.IsDone()){
Console.WriteLine(“立钻哥哥Print: {0}请买车票!”, i.CurrentItem());
i.Next();
}
Console.Read();
}
++++运行结果:
立钻哥哥请买车票
美女1请买车票
美女2请买车票
美女3请买车票
帅哥1请买车票
帅哥2请买车票
++++当我们需要对聚集多种方式遍历时,可以考虑用迭代器模式。
++2.23.3、迭代器模式的作用
++++作用1:它支持以不同的方式遍历一个聚合。(复杂的聚合可用多种方式进行遍历。)
++++作用2:迭代器简化了聚合的接口。(有了迭代器的遍历接口,聚合本身就不再需要类似的遍历接口了。这样就简化了聚合的接口。)
++++作用3:在同一个聚合上可以有多个遍历。(每个迭代器保持它自己的遍历状态。因此我们可以同时进行多个遍历。)
++2.23.4、相关模式
++++Composite:迭代器常被应用到象复合这样的递归结构上。
++++Factory Method:多态迭代器靠Factory Method来例化适当的迭代器子类。
++++Memento:常与迭代器模式一起使用。迭代器可使用一个memento来捕获一个迭代的状态。迭代器在其内部存储memento。
#第三篇:模式大PK
#第三篇:模式大PK
++++3.1、创建类模式大PK
++++3.2、结构类模式大PK
++++3.3、行为类模式大PK
++++3.4、跨战区混合PK
++3.1、创建类模式大PK
++++创建类模式包括工厂方法模式、建造者模式、抽象工厂模式、单例模式和原型模式,它们都能够提供对象的创建和管理职责。其中的单例模式和原型模式非常容易理解,单例模式是要保持在内存中只有一个对象,原型模式是要求通过复制的方式产生一个新的对象,这两个不容易混淆。剩下的就是工厂方法模式、抽象工厂模式和建造者模式了,这三个之间有较多的相似性。
++3.2、结构类模式大PK
++++结构类模式包括适配器模式、桥梁模式、组合模式、装饰模式、门面模式、享元模式和代理模式。(结构类模式都是通过组合类或对象产生更大结构以适应更高层次的逻辑需求。)
++3.3、行为类模式大PK
++++行为类模式包括责任链模式、命令模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、模板方法模式、访问者模式。
++3.4、跨战区混合PK
++++创建类模式描述如何创建对象,行为类模式关注如何管理对象的行为,结构类模式则着重于如何建立一个软件结构,虽然三种模式的着重点不同,但是在实际应用中还是有重叠的,会出现一种模式适用、另外一种模式也适用的情况。
##3.1、创建类模式大PK
++3.1、创建类模式大PK
++++创建类模式包括工厂方法模式、建造者模式、抽象工厂模式、单例模式和原型模式,它们都能够提供对象的创建和管理职责。其中的单例模式和原型模式非常容易理解,单例模式是要保持在内存中只有一个对象,原型模式是要求通过复制的方式产生一个新的对象,这两个不容易混淆。剩下的就是工厂方法模式、抽象工厂模式和建造者模式了,这三个之间有较多的相似性。
++3.1.1、创建型模式
++++创建型模式抽象了实例化过程。它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给另一个对象。
++++随着系统演化得越来越依赖于对象复合而不是类继承,创建型模式变得更为重要。当这种情况发生时,重心从对一组固定行为的硬编码(hard-coding)转移为定义一个较小的基本行为集,这些行为可以被组合成任意数目的更复杂的行为。这样创建有特定行为的对象要求的不仅仅是实例化一个类。
++++在这些模式中有两个不断出现的主旋律。第一,它们都将关于该系统使用哪些具体的类的信息封装起来。第二,它们隐藏了这些类的实例是如何被创建和放在一起的。整个系统关于这些对象所知道的是由抽象类所定义的接口。因此,创建型模式在什么被创建,谁创建它,它是怎样被创建的,以及何时创建这些方面给予我们很大的灵活性。它们允许我们用结构和功能差别很大的“产品”对象配置一个系统。配置可以是静态的(即在编译时指定),也可以是动态的(在运行时)。
++++有时创建型模式是相互竞争的。例如,在有些情况下Prototype或Abstract Factory用起来都很好。而在另外一些情况下它们是互补的:Builder可以使用其他模式去实现某个构件的创建。Prototype可以在它的实现中使用Singleton。
++3.1.2、创建型模式总结
++++抽象工厂(Abstract Factory): 创建型模式隐藏了这些类的实例是如何被创建和放在一起,整个系统关于这些对象所知道的是由抽象类所定义的接口。这样,创建型模式在创建了什么、谁创建它、它是怎么被创建的,以及何时创建这些方面提供了很大的灵活性。
++++原型(Prototype): 建立相应数目的原型并克隆它们通常比每次用合适的状态手工实例化该类更方便一些。
++++建造者(Builder): 内聚性描述的是一个例程内部组成部分之间相关联系的紧密程度。(而耦合性描述的是一个例程与其他例程之间联系的紧密程度。)(软件开发的目标应该是创建这样的例程:内部完整,也就是高内聚,而与其他例程之间的联系则是小巧、直接、可见、灵活的,这就是松耦合。)
++++将一个复杂对象的构建与它的表示分离。(用同样的构建过程创建不同的产品给客户。)
++++单例(Singleton): 对一些类来说,一个实例是很重要的。(让类自身负责保存它的唯一实例。这个类可以保证没有其他实例可以被创建,并且提供了一个访问该实例的方法,对唯一的实例可以严格地控制客户怎样以及何时访问它。)
++++工厂方法(Factory Method): 创建型模式抽象了实例化的过程。(它们帮助一个系统独立于如何创建、组合和表示它的那些对象。)(创建型模式都会将关于该系统使用哪些具体的类的信息封装起来。欲奴客户用结构和功能差别很大的“产品”对象配置一个系统。配置可以是静态的,即在编译时指定,也可以是动态的,就是运行时再指定。)
++++工厂方法(Factory Method): 通常设计应该从工厂方法开始,当设计者发现需要更大的灵活性时,设计便会向其他创建型模式演化。当设计者在设计标准之间进行权衡的时候,了解多个创建型模式可以给设计者更多的选择余地。
++++【抽象工厂(Abstract Factory)】:提供一个创建一系列或相关依赖对象的接口,而无需指定它们具体的类。
++++【建造者(Builder)】:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
++++【工厂方法(Factory Method)】:定义一个用于创建对象的接口,让子类决定实例化哪一个类,工厂模式使一个类的实例化延迟到其子类。
++++【原型(Prototype)】:用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
++++【单例Singleton】:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
++3.1.3、工厂方法模式VS建造者模式
++++工厂方法模式注重的是整体对象的创建方法,而建造者模式注重的是部件构建的过程,旨在通过一步一步的精确构造创建出一个复杂的对象。
++++举例:要制造一个超人。(
--工厂方法模式:直接产生出来的就是一个力大无穷、能够飞翔、内裤外穿的超人。
--建造者模式:则需要组装手、头、脚、躯干等部分,然后再把内裤外穿,于是一个超人就诞生了。
++++注意1:通过工厂方法模式生产出对象,然后由客户端进行对象的其他操作,但是并不代表所有生产出的对象都必须具有相同的状态和行为,它是由产品所决定。
++++工厂方法模式和建造者模式都属于对象创建类模式,都用来创建类的对象。它们的区别:
--区别1:意图不同。(在工厂方法模式里,我们关注的是一个产品整体,如超人整体,无须关心产品的各部分是如何创建出来的。)(在建造者模式中,一个具体产品的产生是依赖各个部件的产生以及装配顺序,它关注的是“由零件一步一步地组装出产品对象。”)(工厂模式是一个对象创建的错线条应用,建造者模式则是通过细线条勾勒出一个复杂对象,关注的是产品组成部分的创建过程。)
--区别2:产品的复杂度不同。(工厂方法模式创建的产品一般都是单一性质产品,如成年超人,都是一个模样。)(建造者模式创建的则是一个复合产品,它由各个部件复合而成,部件不同产品对象当然不同。)(这不是说工厂方法模式创建的对象简单,而是指它们的粒度大小不同。一般来说,工厂方法模式的对象粒度比较粗,建造者模式的产品对象粒度比较细。)
++++在系统设计时,如果需要详细关注一个产品部件的生产、安装步骤,则选择建造者,否则选择工厂方法模式。
++3.1.4、抽象工厂模式VS建造者模式
++++抽象工厂模式实现对产品家族的创建,一个产品家族是这样的一系列产品:具有不同分类维度的产品组合,采用抽象工厂模式则是不需要关心构建过程,只关心什么产品由什么工厂生产即可。
++++建造者模式要求按照指定的蓝图建造产品,它的主要目的是通过组装零配件而产生一个新产品。
++++举例:车辆生产(现代化的汽车工厂能够批量生产汽车。不同的工厂生产不同的汽车。车不仅具有不同品牌,还有不同的用途分类。)
--抽象工厂: 按照抽象工厂模式,首先需要定义一个抽象的产品接口即汽车接口,然后宝马和奔驰分别实现该接口,由于它们只具有了一个品牌属性,还没有定义一个具体的型号,属于对象的抽象层次,每个具体车型由其子类实现,如R系列的奔驰车是商务车,X系列的宝马车属于SUV。
--建造者:按照建造者模式设计一个生产车辆需要把车辆进行拆分,拆分成引擎和车轮两部分,然后由建造者进行建造,想要什么车,只要有设计图纸就成,马上可以制造一辆车出来。它注重的是对零件的装配、组合、封装,它从一个细微构件装配角度看待一个对象。
++++在抽象工厂模式中使用“工厂”来描述构建者,而在建造者模式中使用“车间”来描述构建者。(抽象工厂模式就好比是一个一个的工厂,宝马车工厂生产宝马SUV和宝马VAN,奔驰车工厂生产奔驰车SUV和奔驰VAN,它是从一个更高层次去看待的构建,具体到工厂内部还有很多的车间,如制造引擎的车间、装配引擎的车间等,但这些都隐藏在工厂内部的细节,对外不公布。也就是对领导者来说,他只要关心一个工厂到底是生产什么产品的,不用关心具体怎么生产。)(建造者模式是由车间组成,不同的车间完成不同的创建和装配任务,一个完整的汽车生产过程需要引擎制造车间、引擎装配车间的配合才能完成,它们配合的基础就是设计蓝图,而这个蓝图是掌握在车间主任(导演类)手中,它给建造车间什么蓝图就能生产什么产品,建造者模式更关心建造过程。虽然从外界来看一个车间还是生产车辆,但是这个车间的转型是非常快的,只要重新设计一个蓝图,即可产生不同的产品,这有赖于建造者模式的功劳。)
++++抽象工厂模式比建造者模式的尺度要大,它关注产品整体,而建造者模式关注构建过程,因此建造者模式可以很容易地构建出一个崭新的产品,只要导演类能够提供具体的工艺流程。(如果希望屏蔽对象的创建过程,只提供一个封装良好的对象,则可以选择抽象工厂方法模式。)(建造者模式可以用在构件的装配方面,如通过装配不同的组件或者相同组件的不同顺序,可以产生出一个新的对象,它可以产生一个非常灵活的架构,方便地扩展和维护系统。)
++3.1.5、创建模式的讨论
++++用一个系统创建的那些对象的类对系统进行参数化有两种常用方法。(一种是生成创建对象的类的子类;这对应于使用Factory Method模式。这种方法的主要缺点是,仅为了改变产品类,就可能需要创建一个新的子类。这样的改变可能是级联的(cascade)。例如,如果产品的创建者本身是一个工厂方法创建的,那么我们也必须重定义它的创建者。)(另一种对系统进行参数化的方法更多的依赖于对象复合:定义一个对象负责明确产品对象的类,并将它作为该系统的参数。这是Abstract Factory、Builder、和Prototype模式的关键特征。所有这三个模式都涉及到创建一个新的负责创建产品对象的“工厂对象”。Abstract Factory由这个工厂对象产生多个类的对象。Builder由这个工厂对象使用一个相对复杂的协议,逐步创建一个复杂产品。Prototype由该工厂对象通过拷贝原型对象来创建产品对象。在这种情况下,因为原型负责返回产品对象,所以工厂对象和原型是同一个对象。)
++++使用Abstract Factory、Prototype或者Builder的设计甚至比使用Factory Method的那些设计更灵活,但它们也更加复杂。(通常,设计以使用Factory Method开始,并且当设计者发现需要更大的灵活性是,设计便会向其他创建型模式演化。当我们在设计标准之间进行权衡的时候,了解多个模式可以给我们提供更多的选择余地。)
##3.2、结构类模式大PK
++3.2、结构类模式大PK
++++结构类模式包括适配器模式、桥梁模式、组合模式、装饰模式、门面模式、享元模式和代理模式。(结构类模式都是通过组合类或对象产生更大结构以适应更高层次的逻辑需求。)
++++结构型模式之间具有相似性,尤其是它们的参与者和协作之间的相似性。(这可能是因为结构型模式依赖于同一个很小的语言机制集合构造代码和对象:单继承和多重继承机制用于基于类的模式,而对象组合机制用于对象式模式。)
++3.2.1、结构型模式
++++结构型模式涉及到如何组合类和对象以获得更大的结构。结构型类模式采用继承机制来组合接口或实现。(一个简单的例子是采用多重继承方法将两个以上的类组合成一个类,结果这个类包含了所有父类的性质。这一模式尤其有助于多个独立开发的类库协同工作)(还有一个例子是类形成的Adapter模式。一般来说,适配器使得一个接口(adaptee的接口)与其他接口兼容,从而给出了多个不同接口的统一抽象。为此,类适配器对一个adaptee类进行私有继承。这样,适配器就可以用adaptee的接口表示它的接口。)
++++结构型对象模式不是对接口和实现进行组合,而是描述了如何对一些对象进行组合,从而实现新功能的一些方法。因为可以在运行时刻改变对象组合关系,所以对象组合方式具有更大的灵活性,而这种机制用静态类组合是不可能实现的。
++++Composite模式是结构型对象模式的一个实例。(它描述了如何构造一个类层次式结构,这一结构由两种类型的对象(基本对象和组合对象)所对应的类构成,其中的组合对象使得我们可以组合基本对象以及其他的组合对象,从而形成任意复杂的结构。)
++++在Proxy模式中,proxy对象作为其他对象的一个方便的替代或占位符。(它的使用可以有多种形式,例如它可以在局部空间中代表一个远程地址空间中的对象,也可以表示一个要求被加载的较大的对象,还可以用来保护对敏感对象的访问。)(Proxy模式还提供了对对象的一些特有性质的一定程度上的间接访问,从而它可以限制、增强或修改这些性质。)
++++Flyweight模式为了共享对象定义了一个结构。(至少有两个原因要求对象共享:效率和一致性。)(Flyweight的对象共享机制主要强调对象的空间效率。使用很多对象的应用必须考虑每一个对象的开销。使用对象共享而不是进行对象复制,可以节省大量的空间资源。但是仅当这些对象没有定义与上下文相关的状态时,它们才可以被共享。Flyweight的对象没有这样的状态。任何执行任务时需要的其他一些信息仅当需要时才传递过来。由于不存在与上下文相关的状态,因此Flyweight对象可以被自由地共享。)
++++如果说Flyweight模式说明了如何生成很多较小的对象,那么Facade模式则描述了如何用单个对象表示整个子系统。模式中的facade用来表示一组对象,facade的职责是将消息转发给它所表示的对象。(Bridge模式将对象的抽象和其实现分离,从而可以独立地改变它们。)
++++Decorator模式描述了如何动态地为对象添加职责。(Decorator模式是一种结构型模式。这一模式采用递归方式组合对象,从而允许我们添加任意多的对象职责。)
++++许多结构型模式在某种程度上具有相关性。
++3.2.2、结构型模式总结
++++适配器(Adapter): 将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。(想使用一个已经存在的类,而它的解耦不符合要求,或者希望创建一个可以复用的类,该类可以与其他不相关的类或不可预见的类协同工作,让这些接口不同的类通过适配后,协同工作。)(主要是为了解决两个已有接口之间不匹配的问题,不需要考虑这些接口是怎样实现的,也不考虑它们各自可能会如何演化。这种方式不需要对两个独立设计的类中任一个进行重新设计,就能够使它们协同工作。)
++++桥梁(Bridge): 将抽象部分与它的实现部分分离,使它们都可以独立地变化。(解耦这些不同方向的变化,通过对象组合的方式,把两个角色之间的继承关系改为了组合的关系,从而使这两者之间应对各自独立的变化,找出变化并封装之。)
++++组合(Composite): 将对象组合成树形结构以表示“部分-整体”的层次结构,组合模式使得用户对单个对象和组合对象的使用具有一致性。(客户可以一致地使用组合结构和单个对象。任何用到基本对象的地方都可以使用组合对象。)
++++装饰(Decorator): 动态地给一个对象添加一些额外的职责。就增加功能来说,装饰模式相比生成子类更加灵活。(以动态、透明的方式给单个对象添加职责。)
++++外观(Facade): 为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。(信息的隐藏促进了软件的复用。)(如果两个类不必彼此直接通信,那么就不要让这两个类发生直接的相互作用。)(应该让一个软件中的子系统间的通信和相互依赖关系达到最小,而具体办法就是引入一个外观对象,它为子系统间提供了一个单一而简单的屏障。)
++++享元(Flyweight): 为运用共享技术有效地支持大量细粒度的对象。(对象使得内存占用过多,而且如果都是大量重复的对象,那就是资源的极大浪费。)
++++代理(Proxy): 为其他对象提供一种代理以控制对这个对象的访问。
++++代理与外观的主要区别在于:代理对象代表一个单一的对象而外观对象代表一个子系统;代理的客户对象无法直接访问目标对象,由代理提供对单独的目标对象的访问控制,而外观的客户对象可以直接访问子系统中的各个对象,但通常由外观对象提供对子系统各元件功能的简化的共同层次的调用接口。(代理是一种原来对象的代表,其他需要与这个对象打交道的操作都是和这个代表交涉。而适配器则不需要虚构出一个代表者,只需要为应付特定使用目的,将原来的类进行一些组合。)
++3.2.3、代理模式VS装饰模式
++++装饰模式就是代理模式的一个特殊应用,两者的共同点是都具有相同的接口,不同点则是代理模式着重对代理过程的控制,而装饰模式则是对类的功能进行加强或减弱,它着重类的功能变化。
++++代理模式是把当前的行为或功能委托给其他对象执行,代理类负责接口限定:是否可以调用真实角色,以及是否对发送到真实角色的消息进行变形处理,它不对被主题角色(也就是代理类)的功能做任何处理,保证原汁原味的调用。
++++装饰模式是在要保证接口不变的情况下加强类的功能,它保证的是被修饰的对象功能比原始对象丰富(当然,也可以减弱),但不做准入条件判断和准入参数过滤,如是否可以执行类的功能,过滤输入参数是否合规等,这不是装饰模式关心的。
++3.2.4、装饰模式VS适配器模式
++++装饰模式和适配器模式在通用类图上没有太多的相似点,差别比较大,但是它们的功能有相似的地方:都是包装作用,都是通过委托方式实现其功能。(不同点是:装饰模式包装的是自己的兄弟类,隶属于统一家族(相同接口或父类),适配器模式则修饰非血缘关系类,把一个非本家族的对象伪装成本家族的对象,注意是伪装,因此它的本质还是非相同接口的对象。)
++++案例:描述实现丑小鸭(话说鸭妈妈有5个孩子,其中4个孩子都是黄白相间的颜色,而最小的那只也就是叫做丑小鸭的那只,是纯白色的,与兄弟姐妹不相同,在遭受了诸多嘲讽和讥笑后,最终丑小鸭变成了一只美丽的天鹅。)
--装饰模式:用装饰模式来描述丑小鸭,首先要肯定丑小鸭是一只天鹅,只是因为她小或者是鸭妈妈的无知才没有被认出是天鹅,经过一段时间后,它逐步变成一个漂亮、自信、优美的白天鹅。(根据分析我们可以这样设计,先设计一个丑小鸭,然后根据时间先后来进行不同的美化处理,先长出漂亮的羽毛,然后逐步展现出异于鸭子的不同行为,如飞行,最终在具备了所有的行为后,它就成为一只纯粹的白天鹅了。)
--适配器模式: 采用适配器模式实现丑小鸭变成白天鹅的过程要从鸭妈妈的角度来分析,它认为这5个孩子都是她的后代,都是鸭类,但是实际上只有一只(也就是丑小鸭)不是真正的鸭类,她是一只小白天鹅。(采用适配器模式讲述丑小鸭的故事,我们首先观察到的是鸭与天鹅的不同点,建立了不同的接口以实现不同的物种,然后在需要的时候(根据故事情节)把一个物种伪装成另外一个物种,实现不同物种的相同处理过程,这就是适配器模式的设计意图。)
++++装饰模式和适配器模式的不同点:
--不同点1:意图不同。(装饰模式的意图是加强对象的功能;而适配器模式关注的则是转化,它的主要意图是两个不同对象之间的转化。)
--不同点2:施与对象不同。(装饰模式装饰的对象必须是自己的同宗,也就是相同的接口或父类,只要在具有相同的属性和行为的情况下,才能比较行为是增加还是减弱;适配器模式则必须是两个不同的对象,因为它着重于转换,只有两个不同的对象才能转换的必要。)
--不同点3:场景不同。(装饰模式在任何时候都可以使用,只要是想增强类的功能,而适配器模式则是一个补救模式,一般出现在系统成熟或已经构建完毕的项目中,作为一个紧急处理手段采用。)
--不同点4:扩展性不同。(装饰模式很容易扩展,而且装饰类可以继续扩展下去;但是适配器模式在两个不同对象之间架起了一座沟通的桥梁,建立容易,去掉就比较困难了,需要从系统整体考虑是否能够撤销。)
++3.2.5、Adapte与Bridge
++++Adapter模式和Bridge模式具有一些共同的特征。它们都给另一对象提供了一定程度上的间接性,因而有利于系统的灵活性。它们都涉及到从自身以外的一个接口向这个对象转发请求。
++++这些模式的不同之处主要在于它们各自的用途。(Adapter模式主要是为了解决两个已有接口之间不匹配的问题。它不考虑这些接口是怎样实现的,也不考虑它们各自可能会如何演化。这种方式不需要对两个独立设计的类中的任一个进行重新设计,就能够使它们协同工作。)(Bridge模式则对抽象接口与它的(可能是多个)实现部分进行桥接。虽然这一模式允许我们修改实现它的类,它仍然为用户提供了一个稳定的接口。Bridge模式也会在系统演化时适应新的实现。)
++++由于这些不同点,Adapter和Bridge模式通常被用于软件生命周期的不同阶段。(当我们发现两个不兼容的类必须同时工作时,就有必要使用Adapter模式,其目的一般是为了避免代码重复。此处耦合不可预见。)(Bridge的使用者必须事先知道:一个抽象将有多个实现部分,并且抽象和实现两者是独立演化的。)(Adapter模式在类已经设计好后实施;而Bridge模式在设计类之前实施。这并不意味着Adapter模式不如Bridge模式,只是因为它们针对了不同的问题。)
++++有可能认为Facade是另外一组对象的适配器。但这种解释忽视了一个事实:即Facade定义一个新的接口,而Adapter则复用一个原有的接口。(适配器使两个已有的接口协同工作,而不是定义一个全新的接口。)
++3.2.6、Composite、Decorator与Proxy
++++Composite模式和Decorator模式具有类似的结构图,这说明它们都基于递归组合来组织可变数目的对象。这一共同点可能会使我们认为,decorator对象时一个退化的composite,但这一观点没有领会Decorator模式要点。(相似点仅止于递归组合,这是因为这两个模式的目的不同。)
++++Decorator旨在使我们能够不需要生成子类即可给对象添加职责。(这就避免了静态实现所有功能组合,从而导致子类急剧增加。)(Composite则有不同的目的,它旨在构造类,使多个相关的对象能够以统一的方式处理,而多重对象可以被当做一个对象来处理。它重点不在于装饰,而在于表示。)
++++尽管它们的目的截然不同,但却具有互补性。(因此Composite和Decorator模式通常协同使用。)(在使用这两种模式进行设计时,我们无需定义新的类,仅需将一些对象插接在一起即可构建应用。这时系统中将会有一个抽象类,它有一些composite子类和decorator子类,还有一些实现系统的基本构建模块。此时,composites和decorator将拥有共同的接口。从Decorator模式的角度看,composite是一个ConcreteComponent。而从composite模式的角度看,decorator则是一个Leaf。当然,他们不一定要同时使用,正如我们所见,它们的目的有很大的差别。)
++++另一种与Decorator模式结构相似的模式是Proxy。(这两种模式都描述了怎样为对象提供一定程度上的间接引用,proxy和decorator对象的实现部分都保留了指向另一个对象的指针,它们向这个对象发送请求。然而同时,它们具有不同的设计目的。)
++++像Decorator模式一样,Proxy模式构成一个对象并为用户提供一致的接口。但与Decorator模式不同的是,Proxy模式不能动态地添加或分离性质,它也不是为递归组合而设计的。它的目的是,当直接访问一个实体不方便或不符合需要时,为这个实体提供一个替代者,例如,实体在远程设备上,访问受到限制或者实体是持久存储的。
++++在Proxy模式中,实体定义了关键功能,而Proxy提供(或拒绝)对它的访问。在Decorator模式中,组件仅提供了部分功能,而一个或多个Decorator负责完成其他功能。Decorator模式适用于编译时不能(至少不方便)确定对象的全部功能的情况。这种开放性使递归组合成为Decorator模式中一个必不可少的部分。而在Proxy模式中则不是这样,因为Proxy模式强调一种关系(Proxy与它的实体之间的关系),这种关系可以静态的表达。
++++模式间的这些差异非常重要,因为它们针对了面向对象设计过程中一些特定的经常发生问题的解决方法。(但这并不意味着这些模式不能结合使用。可以设想有一个proxy-decorator,它可以给proxy添加功能,或是一个decorator-proxy用来修改一个远程对象。)(尽管这种混合可能有用,但它们可以分割成一些有用的模式。)
##3.3、行为类模式大PK
++3.3、行为类模式大PK
++++行为类模式包括责任链模式、命令模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、模板方法模式、访问者模式。
++++MVC模式是集观察者、组合、策略等优点于一身,包括三类对象:Model是应用对象,View是它在屏幕上的表示,Controller定义用户界面对用户输入的响应方式。(如果不使用MVC,则用户界面设计往往将这些对象混在一起,而MVC则将它们分离以提高灵活性和复用性。)(MVC是多种模式的综合应用,应该算是一种架构模式。)
++++设计良好的面向对象式系统通常有多个模式镶嵌在其中,但其设计者却未必使用这些术语进行思考。然而,在模式级别而不是在类或对象级别上的进行系统组装可以使我们更方便地获取同等的协同性。
++3.3.1、行为模式
++++行为模式涉及到算法和对象职责的分配。行为模式不仅描述对象或类的模式,还描述它们之间的通信模式。这些模式刻画了在运行时难以跟踪的复杂的控制流。它们将我们的注意力从控制流转移到对象间的联系方式上来。
++++行为类模式使用继承机制在类间分派行为。其中Template Method较为简单和常用。模板方法是一个算法的抽象定义,它逐步地定义该算法,每一步调用一个抽象操作或一个原语操作,子类定义抽象操作以具体实现该算法。(另一种行为类模式是Interpreter。它将一个文法表示为一个类层次,并实现一个解释器作为这些类的实例上的一个操作。)
++++行为对象模式使用对象复合而不是继承。(一些行为对象模式描述了一组对等的对象怎样相互协作以完成其中任一个对象都无法单独完成的任务。这里一个重要的问题是对等的对象如何相互了解对方。对等对象可以保持显式的对对方的引用,但那会增加它们的耦合度。在极端情况下,每一个对象都要了解所有其他的对象。)(Mediator在对等对象间引入一个mediator对象以避免这种情况的出现。Mediator提供了松耦合所需的间接性。)
++++Chain of Responsibility提供更松的耦合。(它让我们通过一条候选对象链隐式的向一个对象发送请求。根据运行时刻情况任一候选者都可以响应相应的请求。候选者的数目是任意的,我们可以在运行时刻决定哪些候选者参与到链中。)
++++Observer模式定义并保持对象间的依赖关系。(典型的是模型/视图/控制器,其中一旦模型的状态发生变化,模型的所有视图都会得到通知。)
++++其他的行为对象模式常将行为封装在一个对象中并将请求指派给它。(Strategy模式将算法封装在对象中,这样可以方便地指定和改变一个对象所使用的算法。)(Command模式将请求封装在对象中,这样它就可作为参数来传递,也可以被存储在历史列表里,或者以其他方式使用。)(State模式封装一个对象的状态,使得当这个对象的状态对象变化时,该对象可改变它的行为。)(Visitor封装分布于多个类之间的行为。)(Iterator则抽象了访问和遍历一个集合中的对象的方式。)
++3.3.2、行为模式总结
++++观察者(Observer): 定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
++++模板方法(Template Method): 定义一个操作的算法骨架,而将一些步骤延迟到子类中,模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。(代码重复是编程中最常见、最糟糕的“坏味道”,如果我们在一个以上的地方看到相同的程序结构,那么可以肯定,设法将它们合而为一,程序会变得更好。完全相同的代码当然存在明显的重复,而微妙的重复会出现在表面不同但是本质相同的结构或处理步骤中。)(模板方法模式由一个抽象类组成,这个抽象类定义了需要覆盖的可能不同实现的模板方法,每个从这个抽象类派生的具体类型将为此模板实现新方法。)
++++命令(Command): 将一个请求封装为一个对象,从而使我们可用不同的请求对客户进行参数化;可以对请求排队或记录请求日志,以及支持可撤销的操作。(将调用操作的对象与知道如何实现该操作的对象解耦。在不同的时刻指定、排列和执行请求。支持取消/重做的操作。)(记录整个操作的日志。)(支持事务。)
++++状态(State):允许一个对象在其内部状态改变时改变它的行为,让对象看起来似乎修改了它的类。(状态模式提供了一个更好的办法来组织与特定状态相关的代码,决定状态转移的逻辑不在单块的if或switch中,而是分布在各个状态子类之间,由于所有与状态相关的代码都存在于某个状态子类中,所以通过定义新的子类可以很容易地增加新的状态和转换。)
++++职责链(Chain of Responsibility):使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。(有多个对象可以处理一个请求,哪个对象处理该请求事先并不知道,要在运行时刻自动确定,让客户在不明确指定接收者的情况下,提交一个请求,然后由所有能处理这请求的对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。)
++++解释器(interpreter):给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。(如果一种特定类型的问题发生的频率足够高,那么就可以考虑将该问题的各个实例表述为一个简单语言中的句子。也就是说,通过构建一个解释器,该解释器解释这些句子来解决该问题。)
++++中介者(Mediator):用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。(面向对象设计鼓励将行为分布到各个对象中,这种分布可能会导致对象间有许多连接。也就是说,有可能每一个对象都需要知道其他许多对象。对象间的大量相互连接使得一个对象似乎不太可能在没有其他对象的支持下工作,这对于应对变化是不利的,任何较大的改动都很困难。将集体行为封装一个单独的中介者对象来避免这个问题,中介者负责控制和协调一组对象间的交互。中介者充当一个中介以使组中的对象不再相互显式引用。这些对象仅知道中介者,从而减少了相互连接的数目。)(最少知识原则,也就是如何减少耦合的问题,类之间的耦合越弱,越有利于复用。)
++++访问者(Visitor):表示一个作用于某对象结构中的各元素的操作。它使我们可以在不改变各元素的类的前提下定义作用于这些元素的新操作。(访问者增加具体的Element是困难的,但增加依赖于复杂对象结构的构件的操作就变得容易。仅需增加一个新的访问者即可在一个对象结构上定义一个新的操作。)
++++策略(Strategy):定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。(继承提供了一种支持多种算法或行为的方法,我们可以直接生成一个类A的子类B、C、D,从而给它以不同的行为。但这样会将行为硬行编制到父类A当中,而将算法的实现与类A的实现混合起来,从而使得类A难以理解、难以维护和难以扩展,而且还不能动态地改变算法。仔细分析会发现,它们之间的唯一差别是它们所使用的算法或行为,将算法封装在独立的策略Strategy类中使得我们可以独立于其类A改变它,使它易于切换、易于理解、易于扩展。)
++++备忘录(Memento):在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态。(使用备忘录,可以避免暴露一些只应由对象A管理却又必须存储在对象A之外的信息。备忘录模式把可能很复杂的对象A的内部信息对其他对象屏蔽起来,从而保持了封装边界。)
++++迭代器(Iterator):提供一种方法顺序访问一个聚合对象中各个元素,而又不需暴露该对象的内部表示。(迭代器模式的关键思想是将对列表的访问和遍历从列表对象中分离出来并放入一个迭代器对象中,迭代器定义了一个访问该列表元素的接口。迭代器对象负责跟踪当前的元素,并且知道哪些元素已经遍历过了。)
++3.3.3、命令模式VS策略模式
++++命令模式和策略模式的类图确实很相似,只是命令模式多了一个接收者(Receiver)角色。(策略模式的意图是封装算法,它认为“算法”已经是一个完整的、不可拆分的原子业务(注意这里是原子业务,而不是原子对象),即其意图是让这些算法独立,并且可以相互替换,让行为的变化独立于拥有行为的客户。)(命令模式则是对动作的解耦,把一个动作的执行分为执行对象(接收者角色)、执行行为(命令角色),让两者相互独立而不相互影响。)
++++策略模式和命令模式相似,特别是命令模式退化时,比如无接收者,在这种情况下,命令模式和策略模式的类图完全一样,代码实现也比较类似。
++++策略模式和命令模式的不同点:
--不同点1:关注点不同。(策略模式关注的是算法替换的问题,一个新的算法投产,旧算法退休,或者提供多种算法由调用者自己选择使用,算法的自由更替是它实现的要点。策略模式关注的是算法的完整性、封装性,只有具备了这两个条件才能保证其可以自由切换。)(命令模式则关注的是解耦问题,如何让请求者和执行者解耦是它需要首先解决的,解耦的要求就是把请求的内容封装为一个一个的命令,由接收者执行。由于封装成了命令,就同时可以对命令进行多种处理,例如撤销、记录等。)
--不同点2:角色功能不同。(策略模式中的抽象算法和具体算法与命令模式的接收者非常相似,但是它们的职责不同。策略模式中的具体算法是负责一个完整算法逻辑,它是不可再拆分的原子业务单元,一旦变更就是对算法整体的变更。)(命令模式则不同,它关注命令的实现,也就是功能的实现。命令模式中的接收者只要符合六大设计原则,完全不用关心它是否完成了一个具体逻辑,它的影响范围也仅仅是抽象命令和具体命令,对它的修改不会扩散到模式外的模块。)(如果在命令模式中需要指定接收者,则需要考虑接收者的变化和封装。)
--不同点3:使用场景不同。(策略模式适用于算法要求变换的场景,而命令模式适用于解耦两个有紧耦合关系的对象场合或者多命令多撤销的场景。)
++3.3.4、策略模式VS状态模式
++++在行为类设计模式中,状态模式和策略模式是亲兄弟,两者非常相似。(两个类图非常相似,都是通过Context类封装一个具体的行为,都提供了一个封装的方法,是高扩展性的设计模式。)(策略模式封装的是不同的算法,算法之间没有交互,以达到算法可以自由切换的目的。)(状态模式封装的是不同的状态,以达到状态切换行为随之发生改变的目的。)
++++策略模式和状态模式的不同点:
--不同点1:环境角色的职责不同。(两者都有一个叫做Context环境角色的类,但是两者的区别很大,策略模式的环境角色只是一个委托作用,负责算法的替换;而状态模式的环境角色不仅仅是委托行为,它还具有登记状态变化的功能,与具体的状态类协作,共同完成状态切换行为随之切换的任务。)
--不同点2:解决问题的重点不同。(策略模式旨在解决内部算法如何改变的问题,也就是将内部算法的改变对外界的影响降低到最小程度,它保证的是算法可以自由地切换;而状态模式旨在解决内在状态的改变而引起行为改变的问题,它的出发点是事物的状态,封装状态而暴露行为,一个对象的状态改变,从外界来看就好像是行为改变。)
--不同点3:解决问题的方法不同。(策略模式只是确保算法可以自由切换,但是什么时候用什么算法它决定不了;而状态模式对外暴露的是行为,状态的变化一般是由环境角色和具体状态共同完成的,也就是说状态模式封装了状态的变化而暴露了不同的行为或行为结果。)
--不同点4:应用场景不同。(策略模式只是一个算法的封装,可以是一个有意义的对象,也可以是一个无意义的逻辑片段。状态模式则要求有一系列状态发生变化的场景,它要求的是有状态且有行为的场景,也就是一个对象必须具有二维(状态和行为)描述才能采用状态模式,如果只有状态而没有行为,则状态的变化就失去了意义。)
--不同点5:复杂度不同。(通常策略模式比较简单,这里的简单指的是结构简单,扩展比较容易,而且代码也容易阅读。当然,一个具体的算法也可以写得很复杂,只有具备很高深的数学、物理等知识的人才可以看懂,这也是允许的,我们只是说从设计模式的角度来分析,它是很容易被看懂的。)(状态模式则通常比较复杂,因为它要从两个角色看到一个对象状态和行为的改变,也就是说它封装的是变化,要知道变化是无穷尽的,因此相对来说状态模式通常都比较复杂,涉及面很多,虽然也很容易扩展,但是一般不会进行大规模的扩张和修正。)
++3.3.5、观察者模式VS责任链模式
++++观察者模式和责任链模式看起来没有太多的相似性。(在观察者模式中有触发链(也叫做观察者链)的问题,一个具体的角色既可以是观察者,也可以是被观察者,这样就形成了一个观察者链。这与责任链模式非常类似,它们都实现了事务的链条化处理。)
++++观察者模式和责任链模式的不同点:
--不同点1:链中的消息对象不同。(从首节点开始到最终的尾节点,两个链中传递的消息对象是不同的。)(责任链模式基本上不改变消息对象的结构,虽然每个节点都可以参与消费(一般是不参与消费),类似于“雁过拔毛”,但是它的结构不会改变,比如从首节点传递进来一个String对象或者Person对象,不会到链尾的时候成了int对象或者Human对象,这在责任链模式中是不可能的,但是在触发链模式中是不允许的,链中传递的对象可以自由变化,只要上下级节点对传递对象了解即可,它不要求链中的消息对象不变化,它只要求链中相邻节点的消息对象固定。)
--不同点2:上下节点的关系不同。(在责任链模式中,上下节点没有关系,都是接收同样的对象,所有传递的对象都是从链首传递过来,上一节点是什么没有关系,只要按照自己的逻辑处理就成。)(触发链模式的上下级关系很亲密,下级对上级顶礼膜拜,上级对下级绝对信任,链中的任意两个相邻节点都是一个牢固的独立团体。)
--不同点3:消息的分销渠道不同。(在责任链模式中,一个消息从链首传递进来后,就开始沿着链条链尾运动,方向是单一的、固定的;而触发链模式则不同,由于它采用的是观察者模式,所以有非常大的灵活性,一个消息传递到链首后,具体怎样传递是不固定的,可以以广播方式传递,也可以以跳跃方式传递,这取决于处理消息的逻辑。)
++3.3.6、行为模式的讨论
++++讨论1:封装变化。(封装变化是很多行为模式的主题。当一个程序的某个方面的特征经常发生改变时,这些模式就定义一个封装这个方面的对象。这样当该程序的其他部分依赖于这个方面时,它们都可以与此对象协作。这些模式通常定义一个抽象类来描述这些封装变化的对象,并且通常该模式依据这个对象来命令。例如:一个Strategy对象封装一个算法。一个State对象封装一个与状态相关的行为。一个Mediator对象封装对象间的协议。一个Iterator对象封装访问和遍历一个聚集对象中的各个构件的方法。)(大多数模式有两种对象:封装该方面特征的新对象,和使用这些新的对象的已有对象。如果不使用这些模式的话,通常这些新对象的功能就会变成这些已有对象的难以分割的一部分。例如,一个Strategy的代码可能会被嵌入到其Context类中,而一个State的代码可能会在该状态的Context类中直接实现。)(Chain of Responsibility可以处理任意数目的对象(即一个链),而所有这些对象可能已经存在于系统中。职责链说明了行为模式间的另一个不同点:并非所有的行为模式都定义类之间的静态通信关系。职责链提供在数目可变的对象间进行通信的机制。其他模式涉及到一些作为参数传递的对象。)
++++讨论2:对象作为参数。(一些模式引入总是被用作参数的对象。例如Visitor。一个Visitor对象时一个多态的Accept操作的参数,这个操作作用于该Visitor对象访问的对象。虽然以前通常代替Visitor模式的方法是将Visitor代码分布在一些对象结构的类中,但visitor从来都不是它所访问的对象的一部分。)(其他模式定义一些可作为令牌到处传递的对象,这些对象将在稍后被调用。Command和Memento都属于这一类。)(在Command中,令牌代表一个请求;而在Memento中,它代表在一个对象在某个特定时刻的内部状态。在这两种情况下,令牌都可以有一个复杂的内部表示,但客户并不会意识到这一点。但这里还有一些区别:在Command模式中多态很重要,因为执行Command对象是一个多态的操作。相反,Memento接口非常小,以至于备忘录只能作为一个值传递。因此它很可能根本不给它的客户提供任何多态操作。)
++++讨论3:通信应该被封装还是被分布。(Mediator和Observer是相互竞争的模式。它们之间的差别是,Observer通过引入Observer和Subject对象分布通信,而Mediator对象则封装了其他对象间的通信。)(在Observer模式中,不存在封装一个约束的单个对象,而必须是由Observer和Subject对象相互协作来维护这个约束。通信模式由观察者和目标连接的方式决定:一个目标通常有多个观察者,并且有时一个目标的观察者也是另一个观察者的目标。)(Mediator模式的目的是集中而不是分布。它将维护一个约束的职责直接放在一个中介者中。)(我们发现生成可复用的Observer和Subject比生成可复用的Mediator容易一些。Observer模式有利于Observer和Subject间的分割和松耦合,同时这将产生粒度更细,从而更易于复用的类。)
++++讨论4:对发送者和接收者解耦。(当合作的对象直接互相引用时,它们变得互相依赖,这可能会对一个系统的分层和重用性产生负面影响。命令、观察者、中介者,和职责链等模式都涉及如何对发送者和接收者解耦,但它们又各有不同的权衡考虑。)(观察者模式通过定义一个接口来通知目标中发生的改变,从而将发送者(目标)与接收者(观察者)解耦。Observer定义了一个比Command更松的发送者-接收者绑定,因为一个目标可能有多个观察者,并且其数目可以在运行时变化。)(观察者模式中的Subject和Observer接口是为了处理Subject的变化而设计的,因此当对象间有数据依赖时,最好用观察者模式来对它们进行解耦。)(中介者模式让对象通过一个Mediator对象间接的互相引用,从而对它们解耦。)(中介者模式可以减少一个系统中的子类生成,因为它将通信行为集中到一个类中而不是将其分布在各个子类中。然而,特别在发布策略通常会降低类型安全性。)(职责链模式通过沿一个潜在接收者链传递请求而将发送者与接收者解耦。因为发送者和接收者之间的接口是固定的,职责链可能也需要一个定制的分发策略。因此它与Mediator一样存在类型安全的问题。如果职责链已经是系统结构的一部分,同时在链上的多个对象中总有一个可以处理请求,那么职责链将是一个很好的将发送者和接收者解耦的方法。此外,因为链可以被简单的改变和扩展,从而该模式提供了更大的灵活性。)
++++讨论5:总结。(除了少数例外情况,各个行为涉及模式之间是相互补充和相互加强的关系。例如,一个职责链中的类可能包括至少一个Template Method的应用。该模板方法可使用原语操纵确定该对象是否应处理该请求并选择应转发的对象。职责链可以使用Command模式将请求表示为对象。Interpreter可以使用State模式定义语法分析上下文。迭代器可以遍历一个聚合,而访问者可以对它的每一个元素进行一个操作。)(行为模式也能与其他模式很好地协同工作。例如,一个使用Composite模式的系统可以使用一个访问者对该复合的各成分进行一些操作。它可以使用职责链使得各成分可以通过它们的父类访问某些全局属性。它也可以使用Decorator对该复合的某些部分的这些属性进行改写。它可以使用Observer模式将一个对象结构与另一个对象结构联系起来,可以使用State模式使得一个构件在状态改变时可以改变自身的行为。复合本身可以使用Builder中的方法创建,并且它可以被系统中的其他部分当做一个Prototype。)
##3.4、跨战区混合PK
++3.4、跨战区混合PK
++++只要是在做面向对象的开发,创建对象的工作不可避免。创建对象时,负责创建的实体通常需要了解要创建的哪个具体的对象,以及何时创建这个而非那个对象的规则。而我们如果希望遵循开发-封闭原则、依赖倒转原则和里氏代换原则,那使用对象时,就不应该知道所用的是哪一个特选的对象。此时就需要“对象管理者”工厂来负责此事。
++++在创建对象时,使用抽象工厂、原型、建造者的设计比使用工厂方法要更灵活,但它们也更加复杂,通常,设计是以使用工厂方法开始,当设计者发现需要更大的灵活性时,设计便会向其他创建型模式演化。(工厂方法的实现并不能减少工作量,但是它能够在必须处理新情况时,避免使已经很复杂的代码更加复杂。)
++++面向对象设计模式体现的就是抽象的思想,类是对对象的抽象,抽象类是对类的抽象,接口是对行为的抽象。
++3.4.1、跨区域PK
++++创建类模式描述如何创建对象,行为类模式关注如何管理对象的行为,结构类模式则着重于如何建立一个软件结构,虽然三种模式的着重点不同,但是在实际应用中还是有重叠的,会出现一种模式适用、另外一种模式也适用的情况。
++3.4.2、策略模式VS桥梁模式
++++策略模式和桥梁模式是如此相似,简直就是孪生兄弟,要把它们两个分开可不太容易。
++++策略模式是一个行为模式,旨在封装一系列的行为。(桥梁模式是解决在不破坏封装的情况下如何抽取出它的抽象部分和实现部分,它的前提是不破坏封装,让抽象部分和实现部分都可以独立地变化。)
++++策略模式是使用继承和多态建立一套可以自由切换算法的模式。(桥梁模式是在不破坏封装的前提下解决抽象和实现都可以独立扩展的模式。)(桥梁模式必然有两个“桥墩”:抽象化角色和实现化角色,只要桥墩搭建好,桥就有了,而策略模式只有一个抽象角色,可以没有实现,也可以有很多实现。)
++++我们在做系统设计时,可以不考虑到底使用的是策略模式还是桥梁模式,只要好用,能够解决问题就成,“不管黑猫白猫,抓住老鼠的就是好猫。”
++3.4.3、门面模式VS中介者模式
++++门面模式为复杂的子系统提供一个统一的访问界面,它定义的是一个高层接口,该接口使得子系统更加容易使用,避免外部模式深入到子系统内部而产生与子系统内部细节耦合的问题。(中介者模式使用一个中介对象封装一系列同事对象的交互行为,它使各对象之间不再显式地引用,从而使其耦合松散,建立一个可扩展的应用架构。)
++++门面模式是以封装和隔离为主要任务,而中介者模式则是以调和同事类之间的关系为主,因为要调和,所以具有了部分的业务逻辑控制。
++++门面模式和中介者模式的区别:
--区别1:功能区别。(门面模式只是增加了一个门面,它对子系统来说没有增加任何的功能,子系统若脱离门面模式是完全可以独立运行的。而中介者模式则增加了业务功能,它把各个同事类中的原有耦合关系移植到了中介者,同事类不可能脱离中介者而独立存在,除非是想增加系统的复杂性和降低扩展性。)
--区别2:知晓状态不同。(对门面模式来说,子系统不知道有门面存在,而对中介者来说,每个同事类都知道中介者存在,因为要依靠中介者调和同事之间的关系,它们对中介者非常了解。)
--区别3:封装程度不同。(门面模式是一种简单的封装,所有的请求处理都委托给子系统完成,而中介者模式则需要有一个中心,由中心协调同事类完成,并且中心本身也完成部分业务,它属于更进一步的业务功能封装。)
++3.4.4、包装模式群PK
++++包装模式(wrapping pattern)是一组模式而不是一个。包装模式包括:装饰模式、适配器模式、门面模式、代理模式、桥梁模式。
++++代理模式是包装模式中的最一般的实现。
++++5个包装模式是我们在系统设计中经常会用到的模式,它们具有相似的特征:都是通过委托的方式对一个对象或一系列对象施行包装,有了包装,设计的系统才更加灵活、稳定,并且极具扩展性。(从实现的角度来看,它们都是代理的一种具体表现形式。)
++++代理模式主要用在不希望展示一个对象内部细节的场景中。(代理模式还可以用在一个对象的访问需要限制的场景中。)
++++装饰模式是一种特殊的代理模式,它倡导的是在不改变接口的前提下为对象增强功能,或者动态添加额外职责。(就扩展性而言,它比子类更加灵活,例如在一个已经运行的项目中,可以很轻松地通过增加装饰类来扩展系统的功能。)
++++适配器模式的主要意图是接口转换,把一个对象的接口转换成系统希望的另外一个接口,这里的系统指的不仅仅是一个应用,也可能是某个环境,比如通过接口转换可以屏蔽外界接口,以免外界接口深入系统内部,从而提高系统的稳定性和可靠性。
++++桥梁模式是在抽象层产生耦合,解决的是自行扩展的问题,它可以使两个有耦合关系的对象互不影响地扩展。
++++门面模式是一个粗粒度的封装,它提供一个方便访问子系统的接口,不具有任何的业务逻辑,仅仅是一个访问复杂系统的快速通道,没有它,子系统照样运行,有了它,只是更方便访问而已。
++3.4.5、命令模式+责任链模式
++++Command抽象类有两个作用:一是定义命令的执行方法,而是负责命令族(责任链)的建立。
++++责任链模式:负责对命令的参数进行解析,而且所有的扩展都是增加链数量好节点,不涉及原有的代码变更。
++++命令模式:负责命令的分发,把适当的命令发到指定的链上。
++++“命令模式+责任链模式”,该框架还有一个名词,叫做命令链(Chain of Command)模式,具体来说就是命令模式作为责任链模式的排头兵,由命令模式分发具体的消息到责任链模式。对于该框架,我们可以继续扩展下去。(可以融合模板方法模式、迭代器模式等模式。)
++3.4.6、工厂方法模式+策略模式
++++策略模式的具体策略必须暴露出去,而且还要由上层模块初始化,这不合适,与迪米特法则有冲突,高层次模块对低层次的模块应该仅仅处在“接触”的层次上,而不应该是“耦合”的关系,否则,维护的工作量就会非常大。正好工厂方法模式可以帮助我们产生指定的对象。(但问题又来了,工厂方法模式要指定一个类,它才能产生对象,引入一个配置文件进行映射,避免系统僵化情况的发生,我们一枚举类完成该任务。)
++++做设计要遵循的原则:先选最简单的业务,然后画出类图。
++3.4.7、观察者模式+中介者模式
++++观察者模式:观察者模式解决事件如何通过处理者的问题,观察者模式的优点是可以有多个观察者,也就是我们的架构是可以多多层次、多分类的处理者。想重新扩展一个新类型也没有问题。
++++中介者模式:事件有了,处理者有了,这些都会发生变化,并且处理者之间也有耦合关系,中介者则可以完美地处理这些复杂的关系。
++++该事件触发框架结构清晰,扩展性好,我们可以进行抽象化处理后应用于实际开发中。(工厂方法模式:负责产生产品对象,方便产品的修改和扩展,并且实现了产品和工厂的紧耦合,避免产品随意被创建而无触发事件的情况发生。)(桥梁模式:在产品和事件两个对象的关系中我们使用了桥梁模式,如此设计后,两者都可以自由地扩展(前提是需要抽取抽象化)而不会破坏原有的封装。)
++++我们来扩展一下这个框架:首先是责任链模式,它可以帮助我们解决一个处理者处理多个事件的问题;其次是模板方法模式,处理者的启用、停用等等,都可以通过模板方法模式来实现;再次是装饰模式,事件的包装、处理者功能的强化都会用到装饰模式。我们还可用到其他的模式,只要能够很好地解决我们的困境,那就好好使用吧,这也是我们学习设计模式的目的。
++3.4.8、规格模式
++++规格模式(Specification Pattern),它不属于23个设计模式,它是组合模式的扩展(是组合模式的一种特殊应用)。
++++规格模式已经是一个非常具体的应用框架了(相对于23个设计模式),大家遇到类似多个对象中筛选查找,或者业务规则不适于放在任何已有实体或值对象中,而且规则的变化和组合会掩盖那些领域对象的基本含义,或者是想自己编写一个类似LINQ的语言工具的时候就可以利用规格模式。
++3.4.9、MVC框架
++++MVC框架有诸如视图与逻辑解耦、灵活稳定、业务逻辑可重用等优点。(MVC,Model View Controller)(MVC框架的目的是通过控制器C将模型M(代表的是业务数据和业务逻辑)和视图V(人机交互的界面)实现代码分离,从而使同一个逻辑或行为或数据可以具有不同的表现形式,或者是同样的应用逻辑共享相同、不同视图。)
++++MVC框架还是比较简单的,它的优点:高重用性、低耦合、快速开发和便捷部署。(高重用性:一个模型可以有多个视图,比如同样是一批数据,可以是柱状展示,也可以是条形展示,还可以是波形展示。同样,多个模型也可以共享一个视图。)(低耦合:因为模型和视图分离,两者没有耦合关系,所以可以独立地扩展和修改而不会产生相互影响。)(快速开发和便捷部署:模型和视图分离,可以使各个开发人员自由发挥,做视图的人员和开发模型的人员可以指定自己的计划,然后在控制器的协作下实现完整的应用逻辑。)
++++MVC的系统架构包含的模块:核心控制器(FilterDispatcher)、拦截器(Interceptor)、过滤器(Filter)、模型管理器(Model Action)、视图管理器(View Provider)等。(核心控制器:MVC框架的入口,负责接收和反馈请求。)(过滤器:实现对数据的过滤处理。)(拦截器:对进出模型的数据进行过滤,它不依赖系统容器,只过滤MVC框架内的业务数据。)(模型管理器:提供一个模型框架,该框架内的所有业务操作都应该是无状态的,不关心容器对象。例如,Session、线程池等等。)(视图管理器:管理所有的视图。)(辅助工具:它其实就是一大堆的辅助管理工具,比如文件管理、对象管理等等。)
++++MVC框架中,核心控制器是最重要的。
++++MVC框架中的难点是:模型管理器。
++++视图管理器的功能很单一,按照模型指定的要求返回视图,用到的模式主要就是桥梁模式。
++++工具类:每个框架或项目都有大量的工具类,MVC也不例外。
++++一个MVC框架要考虑的外界环境因素太多了,所以编写一个框架不是一件容易的事情。
#第四篇:立钻哥哥对设计模式的拓展
#立钻哥哥Unity 学习空间: http://blog.csdn.net/VRunSoftYanlz/
++立钻哥哥推荐的拓展学习链接(Link_Url):
++++立钻哥哥Unity 学习空间: http://blog.csdn.net/VRunSoftYanlz/
++++设计模式简单整理:https://blog.csdn.net/vrunsoftyanlz/article/details/79839641
++++U3D小项目参考:https://blog.csdn.net/vrunsoftyanlz/article/details/80141811
++++UML类图:https://blog.csdn.net/vrunsoftyanlz/article/details/80289461
++++Unity知识点0001:https://blog.csdn.net/vrunsoftyanlz/article/details/80302012
++++U3D_Shader编程(第一篇:快速入门篇):https://blog.csdn.net/vrunsoftyanlz/article/details/80372071
++++U3D_Shader编程(第二篇:基础夯实篇):https://blog.csdn.net/vrunsoftyanlz/article/details/80372628
++++Unity引擎基础:https://blog.csdn.net/vrunsoftyanlz/article/details/78881685
++++Unity面向组件开发:https://blog.csdn.net/vrunsoftyanlz/article/details/78881752
++++Unity物理系统:https://blog.csdn.net/vrunsoftyanlz/article/details/78881879
++++Unity2D平台开发:https://blog.csdn.net/vrunsoftyanlz/article/details/78882034
++++UGUI基础:https://blog.csdn.net/vrunsoftyanlz/article/details/78884693
++++UGUI进阶:https://blog.csdn.net/vrunsoftyanlz/article/details/78884882
++++UGUI综合:https://blog.csdn.net/vrunsoftyanlz/article/details/78885013
++++Unity动画系统基础:https://blog.csdn.net/vrunsoftyanlz/article/details/78886068
++++Unity动画系统进阶:https://blog.csdn.net/vrunsoftyanlz/article/details/78886198
++++Navigation导航系统:https://blog.csdn.net/vrunsoftyanlz/article/details/78886281
++++Unity特效渲染:https://blog.csdn.net/vrunsoftyanlz/article/details/78886403
++++Unity数据存储:https://blog.csdn.net/vrunsoftyanlz/article/details/79251273
++++Unity中Sqlite数据库:https://blog.csdn.net/vrunsoftyanlz/article/details/79254162
++++WWW类和协程:https://blog.csdn.net/vrunsoftyanlz/article/details/79254559
++++Unity网络:https://blog.csdn.net/vrunsoftyanlz/article/details/79254902
++++C#事件:https://blog.csdn.net/vrunsoftyanlz/article/details/78631267
++++C#委托:https://blog.csdn.net/vrunsoftyanlz/article/details/78631183
++++C#集合:https://blog.csdn.net/vrunsoftyanlz/article/details/78631175
++++C#泛型:https://blog.csdn.net/vrunsoftyanlz/article/details/78631141
++++C#接口:https://blog.csdn.net/vrunsoftyanlz/article/details/78631122
++++C#静态类:https://blog.csdn.net/vrunsoftyanlz/article/details/78630979
++++C#中System.String类:https://blog.csdn.net/vrunsoftyanlz/article/details/78630945
++++C#数据类型:https://blog.csdn.net/vrunsoftyanlz/article/details/78630913
++++Unity3D默认的快捷键:https://blog.csdn.net/vrunsoftyanlz/article/details/78630838
++++游戏相关缩写:https://blog.csdn.net/vrunsoftyanlz/article/details/78630687
++++立钻哥哥Unity 学习空间: http://blog.csdn.net/VRunSoftYanlz/
--_--VRunSoft : lovezuanzuan--_--














 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









