






StarRocks文件导入之Stream Load
Stream Load 是一种基于 HTTP 协议的同步导入方式,支持将本地文件或数据流导入到 StarRocks 中。您提交导入作业以后,StarRocks 会同步地执行导入作业,并返回导入作业的结果信息。您可以通过返回的结果信息来判断导入作业是否成功
语法
curl --location-trusted -u <username>:<password> -XPUT <url>
(
data_desc
)
[opt_properties]
参数说明
username 和 password
用于指定 StarRocks 集群账号的用户名和密码。必选参数。如果账号没有设置密码,这里只需要传入 :。
XPUT
用于指定 HTTP 请求方法。必选参数。Stream Load 当前只支持 PUT 方法。
url
用于指定 StarRocks 表的 URL 地址。必选参数。语法如下:
http://<fe_host>:<fe_http_port>/api/<database_name>/<table_name>/_stream_load
可以通过 SHOW FRONTENDS 命令查看 FE 节点的 IP 地址和 HTTP 端口号。
data_desc
data_desc:用于描述源数据文件,包括源数据文件的名称、格式、列分隔符、行分隔符、目标分区、以及与 StarRocks 表之间的列对应关系等。语法如下:
-T <file_path>
-H "format: CSV | JSON"
-H "column_separator: <column_separator>"
-H "row_delimiter: <row_delimiter>"
-H "columns: <column1_name>[, <column2_name>,... ]"
-H "partitions: <partition1_name>[, <partition2_name>, ...]"
-H "temporary_partitions: <temporary_partition1_name>[, <temporary_partition2_name>, ...]"
-H "jsonpaths: [ \"<json_path1>\"[, \"<json_path2>\", ...] ]"
-H "strip_outer_array: true | false"
-H "json_root: <json_path>"
data_desc 中的参数可以分为三类:公共参数、CSV 适用的参数、以及 JSON 适用的参数
公共参数
file_path:指定源数据文件的保存路径。文件名里可选包含或者不包含扩展名。
format:指定待导入数据的格式。取值包括 CSV 和 JSON。默认值:CSV。
partitions:指定要把数据导入哪些分区。如果不指定该参数,则默认导入到 StarRocks 表所在的所有分区中。
temporary_partitions:指定要把数据导入哪些临时分区
columns:指定源数据文件和 StarRocks 表之间的列对应关系。如果源数据文件中的列与 StarRocks 表中的列按顺序一一对应,则不需要指定 columns 参数。您可以通过 columns 参数实现数据转换。例如,要导入一个 CSV 格式的数据文件,文件中有两列,分别可以对应到目标 StarRocks 表的 id 和 city 两列。如果要实现把数据文件中第一列的数据乘以 100 以后再落入 StarRocks 表的转换,可以指定 “columns: city,tmp_id, id = tmp_id * 100”
CSV 适用参数
column_separator:用于指定源数据文件中的列分隔符
row_delimiter:用于指定源数据文件中的行分隔符。如果不指定该参数,则默认为 \n
skip_header:用于指定跳过 CSV 文件最开头的几行数据。取值类型:INTEGER。默认值:0。
trim_space:用于指定是否去除 CSV 文件中列分隔符前后的空格。取值类型:BOOLEAN。默认值:false
enclose:用于指定把 CSV 文件中的字段括起来的字符。取值类型:单字节字符。默认值:NONE。最常用 enclose 字符为单引号 (') 或双引号 (")
escape:指定用于转义的字符。用来转义各种特殊字符,比如行分隔符、列分隔符、转义符、enclose 指定字符等,使 StarRocks 把这些特殊字符当做普通字符而解析成字段值的一部分。取值类型:单字节字符。默认值:NONE。最常用的 escape 字符为斜杠 (),在 SQL 语句中应该写作双斜杠 (\)
JSON 适用参数
jsonpaths:用于指定待导入的字段的名称。仅在使用匹配模式导入 JSON 数据时需要指定该参数
strip_outer_array:用于指定是否裁剪最外层的数组结构。取值范围:true 和 false。默认值:false。真实业务场景中,待导入的 JSON 数据可能在最外层有一对表示数组结构的中括号 []。这种情况下,一般建议您指定该参数取值为 true,这样 StarRocks 会剪裁掉外层的中括号 [],并把中括号 [] 里的每个内层数组都作为一行单独的数据导入
json_root:用于指定待导入 JSON 数据的根元素
ignore_json_size:用于指定是否检查 HTTP 请求中 JSON Body 的大小。
opt_properties
opt_properties用于指定一些导入相关的可选参数。指定的参数设置作用于整个导入作业。语法如下:
-H "label: <label_name>"
-H "where: <condition1>[, <condition2>, ...]"
-H "max_filter_ratio: <num>"
-H "timeout: <num>"
-H "strict_mode: true | false"
-H "timezone: <string>"
-H "load_mem_limit: <num>"
-H "merge_condition: <column_name>"
label:用于指定导入作业的标签。如果您不指定标签,StarRocks 会自动为导入作业生成一个标签。相同标签的数据无法多次成功导入,这样可以避免一份数据重复导入
where:用于指定过滤条件。如果指定该参数,StarRocks 会按照指定的过滤条件对转换后的数据进行过滤。只有符合 WHERE 子句中指定的过滤条件的数据才会导入。
max_filter_ratio:用于指定导入作业的最大容错率,即导入作业能够容忍的因数据质量不合格而过滤掉的数据行所占的最大比例。取值范围:0~1。默认值:0
log_rejected_record_num:指定最多允许记录多少条因数据质量不合格而过滤掉的数据行数。该参数自 3.1 版本起支持。取值范围:0、-1、大于 0 的正整数。默认值:0。
取值为 0 表示不记录过滤掉的数据行。
取值为 -1 表示记录所有过滤掉的数据行。
取值为大于 0 的正整数(比如 n)表示每个 BE(或 CN)节点上最多可以记录 n 条过滤掉的数据行。
timeout:用于导入作业的超时时间。取值范围:1 ~ 259200。单位:秒。默认值:600。
strict_mode:用于指定是否开严格模式。取值范围:true 和 false。默认值:false。
timezone:用于指定导入作业所使用的时区。默认为东八区 (Asia/Shanghai)。
load_mem_limit:导入作业的内存限制,最大不超过 BE(或 CN)的内存限制。单位:字节。默认内存限制为 2 GB。
merge_condition:用于指定作为更新生效条件的列名。这样只有当导入的数据中该列的值大于等于当前值的时候,更新才会生效
列映射
导入 CSV 数据时配置列映射关系
1.如果源数据文件中的列与目标表中的列按顺序一一对应,不需要指定列映射和转换关系
2.如果源数据文件中的列与目标表中的列不能按顺序一一对应,包括数量或顺序不一致,则必须通过 COLUMNS 参数来指定列映射和转换关系
- 列数量一致、但是顺序不一致,并且数据不需要通过函数计算、可以直接落入目标表中对应的列:目标表中有三列,按顺序依次为 col1、col2 和 col3;源数据文件中也有三列,按顺序依次对应目标表中的 col3、col2 和 col1。这种情况下,需要指定 COLUMNS(col3, col2, col1)
- 列数量、顺序都不一致,并且某些列的数据需要通过函数计算以后才能落入目标表中对应的列:
2.1 按顺序依次为 col1、col2 和 col3 ;源数据文件中有四列,前三列按顺序依次对应目标表中的 col1、col2 和 col3,第四列在目标表中无对应的列。这种情况下,需要指定 COLUMNS(col1, col2, col3, temp),其中,最后一列可随意指定一个名称(如 temp)用于占位即可;
2.2 按顺序依次为 year、month 和 day。源数据文件中只有一个包含时间数据的列,格式为 yyyy-mm-dd hh:mm:ss。这种情况下,可以指定 COLUMNS (col, year = year(col), month=month(col), day=day(col))。其中,col 是源数据文件中所包含的列的临时命名,year = year(col)、month=month(col) 和 day=day(col) 用于指定从 col 列提取对应的数据并落入目标表中对应的列,如 year = year(col) 表示通过 year 函数提取源数据文件中 col 列的 yyyy 部分的数据并落入目标表中的 year 列
导入 JSON 数据时配置列映射关系
1.如果 JSON 文件中的 Key 名与目标表中的列名一致,您可以使用简单模式来导入数据。简单模式下,不需要设置 jsonpaths 参数,这种模式要求 JSON 数据是大括号 表示的对象类型,例如 {“category”: 1, “author”: 2, “price”: “3”} 中,category、author、price 是 Key 的名称,按名称直接对应目标 表中的 category、author、price 三列。
2.如果 JSON 文件中的 Key 名与目标表中的列名不一致,则需要使用匹配模式来导入数据。匹配模式下,需要通过 jsonpaths 和 COLUMNS 两个参数来指定 JSON 文件中的 Key 和目标表中的列之间的映射和转换关系:
jsonpaths 参数中按照 JSON 文件中 Key 的顺序一一指定待导入的 Key。
COLUMNS 参数中指定 JSON 文件中的 Key 与目标表中的列之间的映射关系和数据转换关系。
COLUMNS 参数中指定的列名与 jsonpaths 参数中指定的 Key 按顺序保持一一对应。
COLUMNS 参数中指定的列名与目标表中的列按名称保持一一对应。
返回值
{
"TxnId": 1003,
"Label": "label123",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 1000000,
"NumberLoadedRows": 999999,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 40888898,
"LoadTimeMs": 2144,
"BeginTxnTimeMs": 0,
"StreamLoadPlanTimeMs": 1,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 11,
"CommitAndPublishTimeMs": 16,
}
Success:表示数据导入成功,数据已经可见。
Publish Timeout:表示导入作业已经成功提交,但是由于某种原因数据并不能立即可见。可以视作已经成功、不必重试导入。
Label Already Exists:表示该标签已经被其他导入作业占用。数据可能导入成功,也可能是正在导入。
Fail:表示数据导入失败。您可以指定标签重试该导入作业。
示例
导入 CSV 格式的数据
在sr中创建表,
create table csv_test01 (
id STRING comment "id",
name STRING comment "姓名",
age INT comment "年龄",
addr STRING comment "地址"
);
在本地存储中创建csv文件,命名csv_test01.csv;写入
"10001","18","张三丰","安徽省合肥市"
"10002","20","王凤山","四川省广元市"
"10003","22","周岐山","山西省运城市"
"10006","17","李诗敏","浙江省温州市"
"10010","19","刘德伟","福建省三明市"
从本地文件中导入数据到sr中
curl --location-trusted -u root:123456 -H "label:csv_test02" \
-H "Expect:100-continue" \
-H "timeout:100" \
-H "column_separator:|" \
-H "columns:id,age,name,addr" \
-H "skip_header:0"\
-H "strict_mode: true" \
-T csv_test01.csv -XPUT \
http://192.168.219.102:8030/api/quickstart/csv_test01/_stream_load
导入完成查询

我们发现数据已经成功的导入了,但是我们可以看到其string类型数据都带有引号(“),如果我们不需要引号又该如何去除呢?执行以下命令即可,通过指定enclose,来实现双引号的去除
curl --location-trusted -u root:123456 -H "label:csv_test01" \
-H "Expect:100-continue" \
-H "column_separator:|" \
-H "enclose:\"" \
-H "columns:id,age,name,addr" \
-T csv_test01.csv -XPUT \
http://192.168.219.102:8030/api/quickstart/csv_test01/_stream_load

还有别的方式嘛?我们可以尝试一下衍生列
curl --location-trusted -u root:123456 -H "label:csv_test04" \
-H "Expect:100-continue" \
-H "column_separator:|" \
-H "columns:tmp_id,age,tmp_name,tmp_addr,id=replace(tmp_id,'\"',''),name=replace(tmp_name,'\"',''),addr=replace(tmp_addr,'\"','')" \
-T csv_test01.csv -XPUT \
http://192.168.219.102:8030/api/quickstart/csv_test01/_stream_load
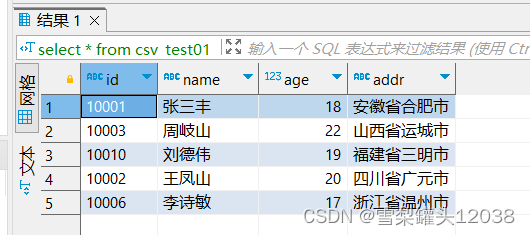
我们发现通过衍生列也可做到
csv文件我们已经尝试导入了,如果是json文件呢?
导入json文件
首先先建表
create table json_test01 (
category STRING comment "种类",
author STRING comment "作者",
title string comment "主题",
price INT comment "价格",
timestamp int comment "时间"
);
然后在本地写入json文件
[
{"category":"xuxb111","author":"1avc","title":"SayingsoftheCentury","price":895,"timestamp":1589191587},
{"category":"xuxb222","author":"2avc","title":"SayingsoftheCentury","price":895},
{"category":"xuxb333","author":"3avc","title":"SayingsoftheCentury","price":895}
]
从本地文件中导入数据到sr中
curl --location-trusted -u root:123456 -H "label:json_test01" \
-H "format: json" \
-H "strip_outer_array: true" \
-H "jsonpaths: [\"$.category\",\"$.price\",\"$.author\",\"$.title\",\"$.timestamp\"]" \
-H "columns: category, price, author, title, timestamp" \
-T json_test01.json -XPUT \
http://192.168.219.102:8030/api/quickstart/json_test01/_stream_load
写入成功
{
"TxnId": 6034,
"Label": "json_test01",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 3,
"NumberLoadedRows": 3,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 284,
"LoadTimeMs": 47,
"BeginTxnTimeMs": 1,
"StreamLoadPlanTimeMs": 4,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 17,
"CommitAndPublishTimeMs": 22
}
查询结果

现在试试多层json,老规矩先在本地保存
{
"id": 10001,
"RECORDS":[
{"category":"11","title":"SayingsoftheCentury","price":895,"timestamp":1589191587},
{"category":"22","author":"张山","price":895,"timestamp":1589191487},
{"category":"33","author":"李氏","title":"SayingsoftheCentury","timestamp":1589191387}
],
"comments": ["3 records", "there will be 3 rows"]
}
导入
curl --location-trusted -u root:123456 -H "label:json_test02" \
-H "format: json" \
-H "json_root: $.RECORDS" \
-H "strip_outer_array: true" \
-H "jsonpaths: [\"$.category\",\"$.price\",\"$.author\",\"$.title\",\"$.timestamp\"]" \
-H "columns: category, price, author, title, timestamp" \
-T json_test02.json -XPUT \
http://192.168.219.102:8030/api/quickstart/json_test01/_stream_load
这里呢,使用json_root来指定外层的key

















 1748
1748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









