






主键表使用 StarRocks 全新设计开发的存储引擎。其主要优势在于支撑实时数据更新的同时,也能保证高效的复杂即席查询性能。在实时分析业务中采用主键表,用最新的数据实时分析出结果来指导决策,使得数据分析不再受限于 T+1 数据延迟。
主键表中的主键具有唯一非空约束,用于唯一标识数据行。如果新数据的主键值与表中原数据的主键值相同,则存在唯一约束冲突,此时新数据会替代原数据,这也是主键表渐渐代替更新表的原因之一
应用场景
1.实时对接事务型数据至 StarRocks。事务型数据库中,除了插入数据外,一般还会涉及较多更新和删除数据的操作,因此事务型数据库的数据同步至 StarRocks 时,建议使用主键表。通过 Flink-CDC 等工具直接对接 TP 的 Binlog,实时同步增删改的数据至主键表,可以简化数据同步流程,并且相对于 Merge-On-Read 策略的更新表,查询性能能够提升 3~10 倍(oltp数据库数据经常需要变动的,可以使用主键表及实时同步实现数据的实时变更,此时使用主键表优势较大)
2.利用部分列更新轻松实现多流 JOIN。在用户画像等分析场景中,一般会采用大宽表方式来提升多维分析的性能,同时简化数据分析师的使用模型。而这种场景中的上游数据,往往可能来自于多个不同业务(比如来自购物消费业务、快递业务、银行业务等)或系统(比如计算用户不同标签属性的机器学习系统),主键表的部分列更新功能就很好地满足这种需求,不同业务直接各自按需更新与业务相关的列即可,并且继续享受主键表的实时同步增删改数据及高效的查询性能(对于大宽表来说,其各个指标的数据来源可能不同,此时使用主键表的部分列更新的特点,可以实现宽表实时同步及增删改及高效的查询能力)
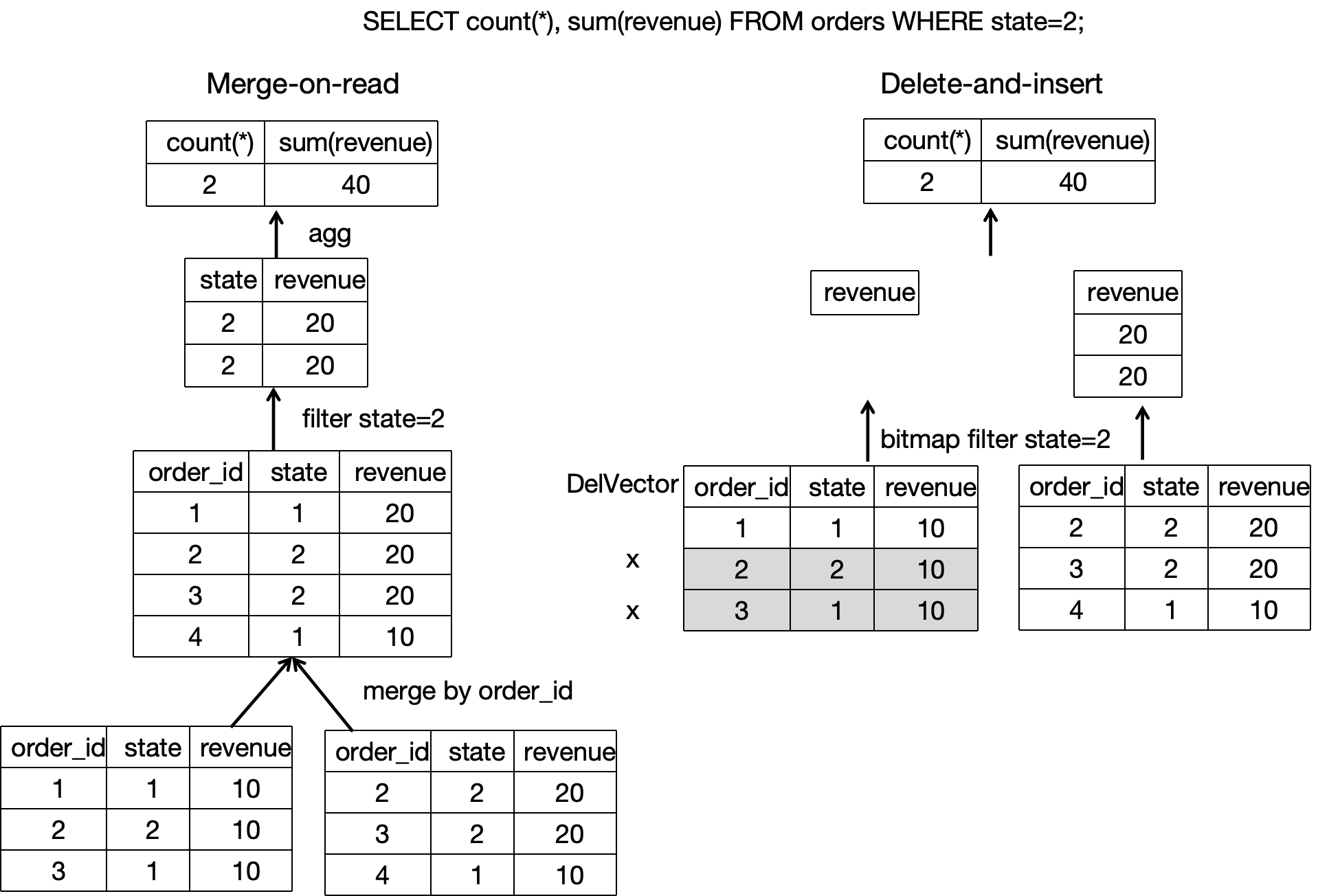
工作原理
不同于更新表及聚合表采用的 Merge-On-Read 策略,主键表采用了 Delete+Insert 策略,借助主键索引配合 DelVector 的方式实现,保证在查询时只需要读取具有相同主键值的数据中的最新数据
读取数据时,由于写入数据时各个数据文件中历史重复数据已经标记为删除,同一个主键值下仅需要读取最新的一条数据,无需在线 Merge 多个版本的数据文件,可以减少扫描开销,相对于 Merge-On-Read 策略的更新表,主键表的查询性能能够提升 3~10 倍
在https://docs.starrocks.io/zh/docs/table_design/table_types/primary_key_table/#主键中查看详细介绍
建表语句:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...]
[, index_definition1[, index_definition2, ...]])
[ENGINE = [olap|mysql|elasticsearch|hive|iceberg|hudi|jdbc]]
[key_desc]
[COMMENT "table comment"]
[partition_desc]
[distribution_desc]
[rollup_index]
[ORDER BY (column_definition1,...)]
[PROPERTIES ("key"="value", ...)]
[BROKER PROPERTIES ("key"="value", ...)]
参数说明
column_definition:
语法:
col_name col_type [agg_type] [NULL | NOT NULL] [DEFAULT "default_value"] [AUTO_INCREMENT] [AS generation_expr]
说明:
- col_name:列名称
- col_type:列数据类型
- agg_type:聚合类型,如果不指定,则该列为 key 列。否则,该列为 value 列(主键表不涉及)
- NULL | NOT NULL:列数据是否允许为 NULL
- DEFAULT “default_value”:列数据的默认值
- AUTO_INCREMENT:指定自增列
- AS generation_expr:指定生成列和其使用的表达式
index_definition:
创建 bitmap 索引
INDEX index_name (col_name[, col_name, ...]) [USING BITMAP] [COMMENT '']
ENGINE 类型:
默认为 olap,表示创建的是 StarRocks 内部表
可选值:mysql、elasticsearch、hive、jdbc (2.3 及以后)、iceberg、hudi(2.2 及以后)。如果指定了可选值,则创建的是对应类型的外部表 (external table),在建表时需要使用 CREATE EXTERNAL TABLE
相应的如果为mysql,则需要在 properties 提供以下信息
PROPERTIES (
"host" = "mysql_server_host",
"port" = "mysql_server_port",
"user" = "your_user_name",
"password" = "your_password",
"database" = "database_name",
"table" = "table_name"
)
如果是 elasticsearch,则需要在 properties 提供以下信息:
PROPERTIES (
"hosts" = "http://192.168.0.1:8200,http://192.168.0.2:8200",
"user" = "root",
"password" = "root",
"index" = "tindex",
"type" = "doc"
)
如果是 hive,则需要在 properties 提供以下信息:
PROPERTIES (
"database" = "hive_db_name",
"table" = "hive_table_name",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083"
)
如果是 jdbc,则需要在 properties 提供以下信息:
PROPERTIES (
"resource"="jdbc0",
"table"="dest_tbl"
)
如果是 iceberg,则需要在 properties 提供以下信息:
PROPERTIES (
"resource" = "iceberg0",
"database" = "iceberg",
"table" = "iceberg_table"
)
如果是 hudi,则需要在 properties 提供以下信息:
PROPERTIES (
"resource" = "hudi0",
"database" = "hudi",
"table" = "hudi_table"
)
key_desc:
语法:
`key_type(k1[,k2 ...])`
数据按照指定的 key 列进行排序,且根据不同的 key_type 具有不同特性。 key_type 支持以下类型:
AGGREGATE KEY: key 列相同的记录,value 列按照指定的聚合类型进行聚合,适合报表、多维分析等业务场景。(聚合表)
UNIQUE KEY/PRIMARY KEY: key 列相同的记录,value 列按导入顺序进行覆盖,适合按 key 列进行增删改查的点查询 (point query) 业务。(更新表/主键表)
DUPLICATE KEY: key 列相同的记录,同时存在于 StarRocks 中,适合存储明细数据或者数据无聚合特性的业务场景。(明细表)
默认为 DUPLICATE KEY,数据按 key 列做排序。主键表为PRIMARY KEY
partition_desc:
主键表支持三种分区方式,表达式分区(推荐)、Range 分区 和 List 分区。
distribution_desc:
主键表只支持哈希分桶,语法
DISTRIBUTED BY HASH (k1[,k2 ...]) [BUCKETS num]
ORDER BY:
3.0 版本起,主键表解耦了主键和排序键,排序键通过 ORDER BY 指定,可以为任意列的排列组合
PROPERTIES:
表的参数
常用的有:
- replication_num:分区 Tablet 副本数。默认为 3
- “bloom_filter_columns” = “k1, k2, k3”,指定某列使用 bloom filter 索引
- “colocate_with” = “table1” 希望使用 Colocate Join 特性,需要在 properties 中指定
- “dynamic_partition.enable” = “true|false”,开启动态分区
- “dynamic_partition.time_unit” = “DAY|WEEK|MONTH”,动态分区的时间粒度
- “dynamic_partition.start” = “${integer_value}”,保留的动态分区的起始偏移
- “dynamic_partition.end” = “${integer_value}”,提前创建的分区数量
- “dynamic_partition.prefix” = “${string_value}”,动态分区的前缀名
- “dynamic_partition.buckets” = "${integer_value}"动态分区的分桶数量
- “bucket_size” = “1073741824” 指定分桶大小
- compression 指定压缩算法(LZ4、ZSTD、ZLIB、SNAPPY,默认LZ4)
举例:
创建一个主键表
CREATE TABLE my_table (
id BIGINT NOT NULL COMMENT '唯一标识',
age TINYINT COMMENT '年龄',
registration_date DATE COMMENT '注册日期',
name STRING COMMENT '姓名',
height FLOAT COMMENT '身高',
is_active BOOLEAN COMMENT '是否活跃'
)
ENGINE = olap
PRIMARY KEY(id,age,registration_date)
PARTITION BY date_trunc('day', registration_date)
DISTRIBUTED BY HASH(age)
PROPERTIES (
"replication_num" = "1", -- 数据副本数
"storage_medium" = "SSD"
)
注意事项:
主键:
- 在建表语句中,主键列必须定义在其他列之前
- 主键必须包含分区列和分桶列
- 主键列支持以下数据类型:数值(包括整型和布尔)、日期和字符串。
- 单条主键值编码后的最大长度为 128 字节。
- 建表后不支持修改主键。
- 主键列的值不能更新,避免破坏数据一致性。
主键索引:
- 持久化主键索引:enable_persistent_index:设置为 true;导入时少部分主键索引存在内存中,大部分主键索引存在磁盘中,避免占用过大内存空间
- 全内存主键索引:enable_persistent_index:设置为 false;导入时会加载数据导入涉及到的 Tablet 的主键索引在内存中,可能会导致占用内存较多
排序键:
3.0 起,主键表解耦了排序键和主键,排序键由 ORDER BY 定义的排序列组成,可以为任意列的排列组合,只要列的数据类型满足排序键的要求
















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









