






StarRocks 支持通过 INSERT 语句导入数据,可以使用 INSERT INTO VALUES 语句直接向表中插入数据,还可以通过 INSERT INTO SELECT 语句将其他 StarRocks 表中的数据导入到新的 StarRocks 表中,或者将其他数据源的数据通过外部表功能导入至 StarRocks 内部表中。自 v3.1 起,可以使用 INSERT 语句和 FILES() 函数直接导入云存储或 HDFS 中的文件
通过 INSERT INTO VALUES 语句导入数据
建表
CREATE TABLE insert_edit
(
user VARCHAR(128) DEFAULT '',
is_new TINYINT DEFAULT '0',
is_robot TINYINT DEFAULT '0',
is_unpatrolled TINYINT DEFAULT '0',
delta INT DEFAULT '0',
added INT DEFAULT '0',
deleted INT DEFAULT '0'
)
DUPLICATE KEY(
user,
is_new,
is_robot,
is_unpatrolled
)
DISTRIBUTED BY HASH(user)
PROPERTIES(
"replication_num" = "1"
);
导入数据
INSERT INTO insert_edit
WITH LABEL insert_load1
VALUES
("AustinFF",0,0,0,0,0,21),
("helloSR",0,1,0,1,0,3);
查询

具体insert语句参数如下
INSERT { INTO | OVERWRITE } [db_name.]<table_name>
[ PARTITION (<partition_name> [, ...] ) ]
[ TEMPORARY PARTITION (<temporary_partition_name> [, ...] ) ]
[ WITH LABEL <label>]
[ (<column_name>[, ...]) ]
{ VALUES ( { <expression> | DEFAULT } [, ...] ) | <query> }
INTO:将数据追加写入目标表。
OVERWRITE:将数据覆盖写入目标表。
table_name:导入数据的目标表。
PARTITION:导入的目标分区。此参数必须是目标表中存在的分区,多个分区名称用逗号(,)分隔。如果指定该参数,数据只会被导入相应分区内。如果未指定,则默认将数据导入至目标表的所有分区。
TEMPORARY PARTITION:指定要把数据导入哪些临时分区
label:导入作业的标识,数据库内唯一,指定了 Label,可以通过 SQL 命令 SHOW LOAD WHERE label=“label”; 查看任务结果
column_name:导入的目标列,必须是目标表中存在的列。该参数的对应关系与列名无关,但与其顺序一一对应。如果不指定目标列,默认为目标表中的所有列。如果源表中的某个列在目标列不存在,则写入默认值
expression:表达式
DEFAULT:为对应列赋予默认值。
query:查询语句,查询的结果会导入至目标表中
FILES():表函数 FILES()。您可以通过该函数将数据导出至远端存储
通过 INSERT INTO SELECT 语句导入数据
通过 INSERT INTO SELECT 语句将源表中的数据导入至目标表中。INSERT INTO SELECT 将源表中的数据进行 ETL 转换之后,导入到 StarRocks 内表中。源表可以是一张或多张内部表或者外部表,甚至云存储或 HDFS 中的数据文件。目标表必须是 StarRocks 的内表。执行该语句之后,系统将 SELECT 语句结果导入目标表
通过 INSERT INTO SELECT 将内外表数据导入内表
导入内部表数据,其操作过程与导入外部表数据相同
建表
CREATE TABLE insert_edit2
(
user VARCHAR(128) DEFAULT '',
is_new TINYINT DEFAULT '0',
is_robot TINYINT DEFAULT '0',
is_unpatrolled TINYINT DEFAULT '0',
delta INT DEFAULT '0',
added INT DEFAULT '0',
deleted INT DEFAULT '0'
)
DUPLICATE KEY(
user,
is_new,
is_robot,
is_unpatrolled
)
DISTRIBUTED BY HASH(user)
PROPERTIES(
"replication_num" = "1"
);
导入
insert into insert_edit2
with label insert_load2
select * from insert_edit
查询

导入指定列
INSERT INTO insert_edit2
WITH LABEL insert_load3
(
`user`
)
SELECT `user`FROM insert_edit;
查询
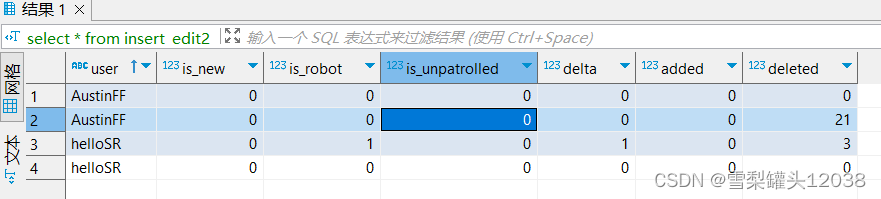
未被导入的列被赋予默认值
通过 INSERT INTO SELECT 以及表函数 FILES() 导入外部数据文件
自 v3.1 起,StarRocks 支持使用 INSERT 语句和 FILES() 表函数直接导入云存储或 HDFS 中的文件,无需提前创建 External Catalog 或文件外部表。除此之外,FILES() 支持自动推断 Table Schema,大大简化导入过程
不过暂时只支持parquet 和 orc格式数据
从hdfs导入数据
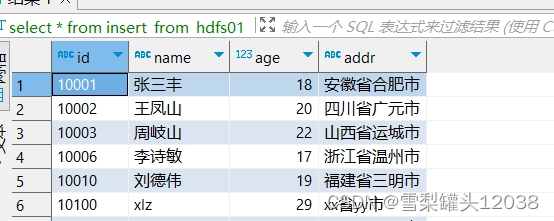
准备数据
10001 张三丰 18 安徽省合肥市
10002 王凤山 20 四川省广元市
10003 周岐山 22 山西省运城市
10006 李诗敏 17 浙江省温州市
10010 刘德伟 19 福建省三明市
10100 xlz 29 xx省yy市
建表
CREATE TABLE `insert_csv_from_hdfs01` (
`id` varchar(65533) NULL COMMENT "id",
`name` varchar(65533) NULL COMMENT "姓名",
`age` int(11) NULL COMMENT "年龄",
`addr` varchar(65533) NULL COMMENT "地址"
) ENGINE=OLAP
DUPLICATE KEY(`id`)
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"enable_persistent_index" = "false",
"replicated_storage" = "true",
"compression" = "LZ4"
);
导入数据
INSERT INTO insert_from_hdfs01
SELECT * FROM FILES(
"path" = "hdfs://192.168.219.102:9000/user/root/starrocks/insert_test_hdfs.parquet",
"format" = "parquet",
"username" = "root",
"password" = "123456"
);
查询
通过 INSERT OVERWRITE VALUES 语句覆盖写入数据
可以通过 INSERT OVERWRITE VALUES 语句向指定的表中覆盖写入数据。此导入方式中,多条数据用逗号(,)分隔
INSERT OVERWRITE insert_csv_from_hdfs02
WITH LABEL insert_csv_from_hdfs02
VALUES
("10001","18","王凤山","安徽省合肥市"),
("10010","20","李诗敏","山西省运城市");
通过 INSERT OVERWRITE SELECT 语句覆盖写入数据
可以通过 INSERT OVERWRITE SELECT 语句将源表中的数据覆盖写入至目标表中。INSERT OVERWRITE SELECT 将源表中的数据进行 ETL 转换之后,覆盖写入到 StarRocks 内表中。源表可以是一张或多张内部表或者外部表。目标表必须是 StarRocks 的内表。执行该语句之后,系统使用 SELECT 语句结果覆盖目标表的数据
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









