










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:Python语言、 Flask框架、 Echarts可视化 MySQL数据库、HTML
前端: html css js juery bootstrap Echarts
后端:flask (python语言后端框架)
数据库: mysql
数据分析库:
numpy pandas matplotlib 数据处理
WordCloud 词云
jieba 分词
2、项目界面
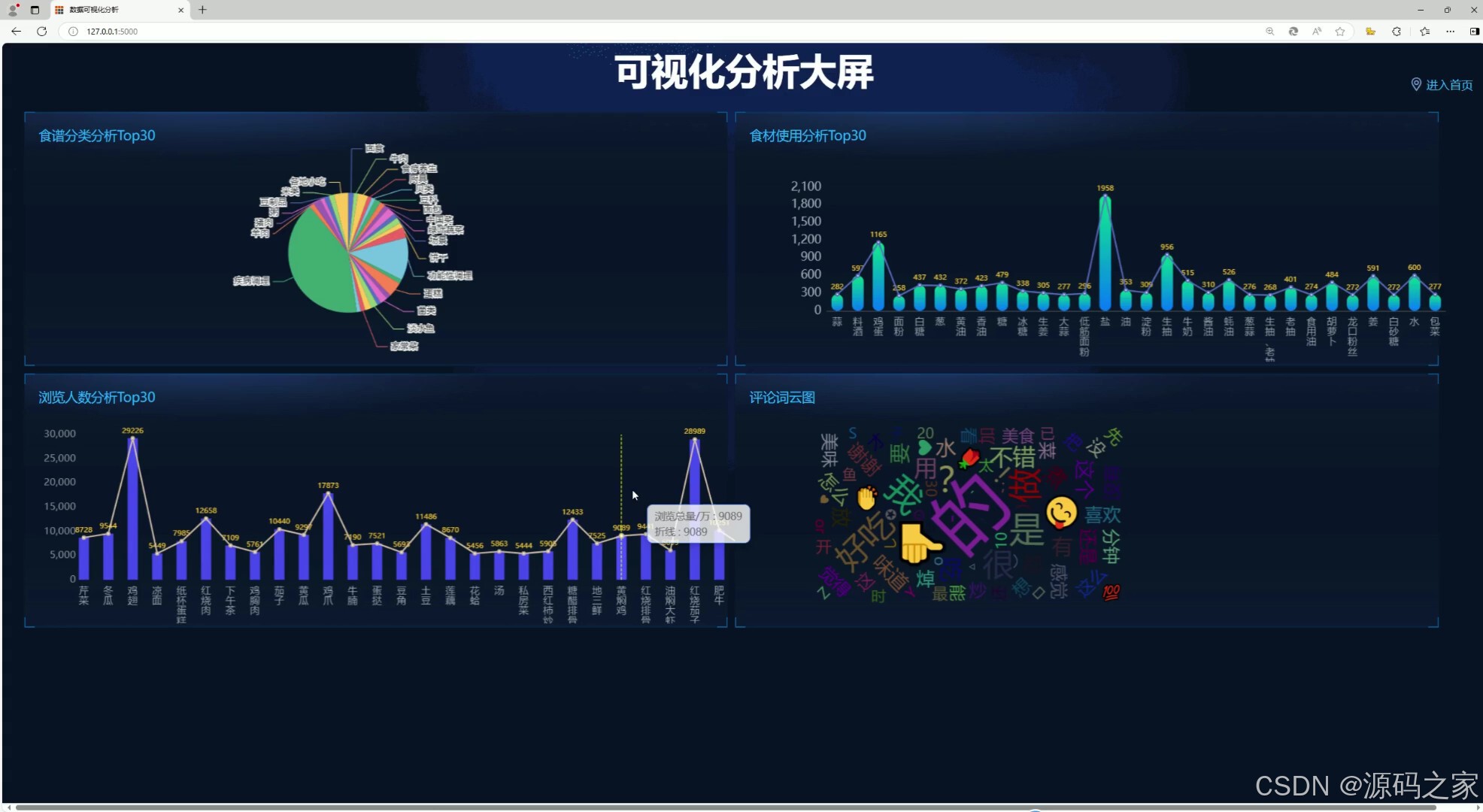
(1)可视化分析大屏
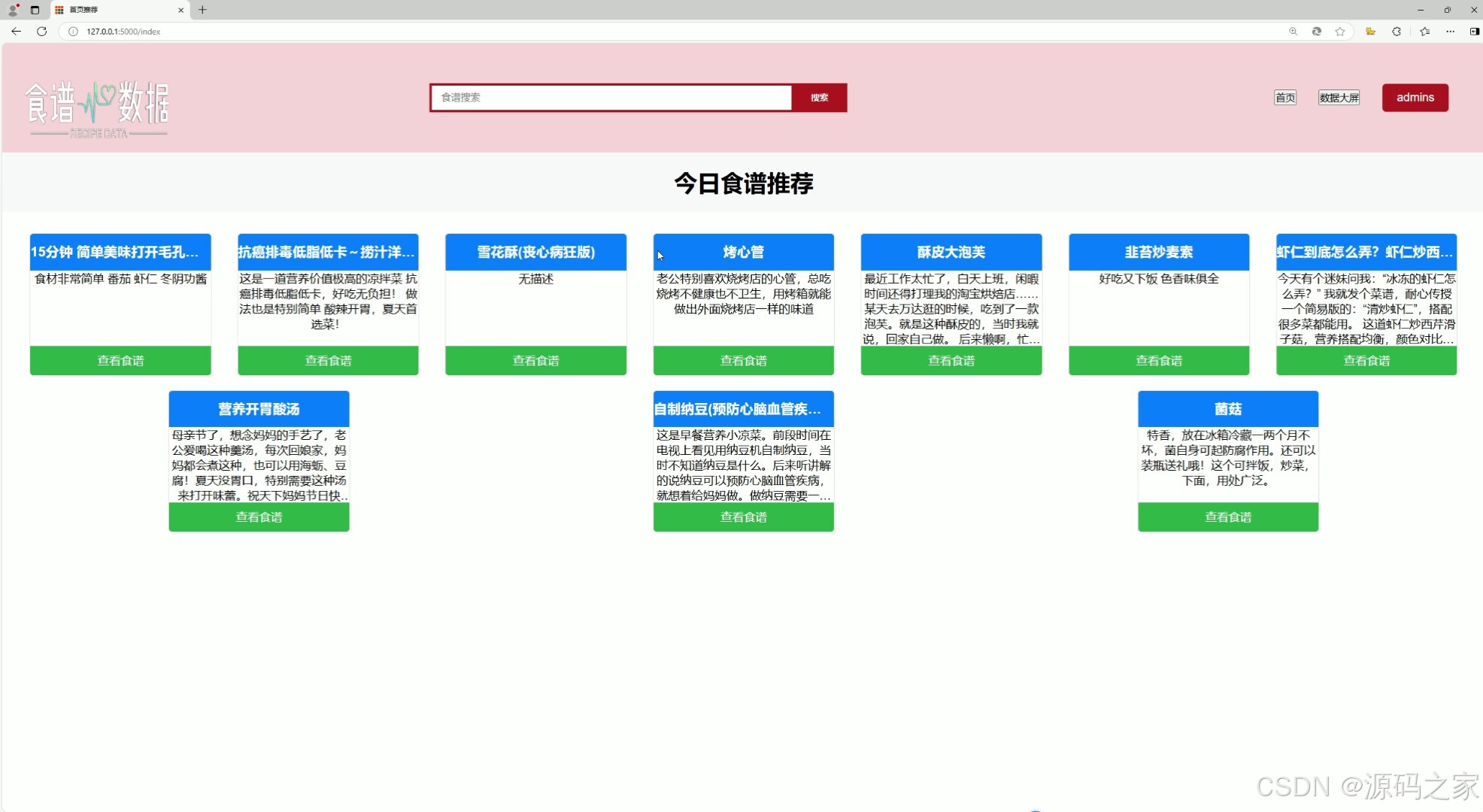
(2)食谱推荐
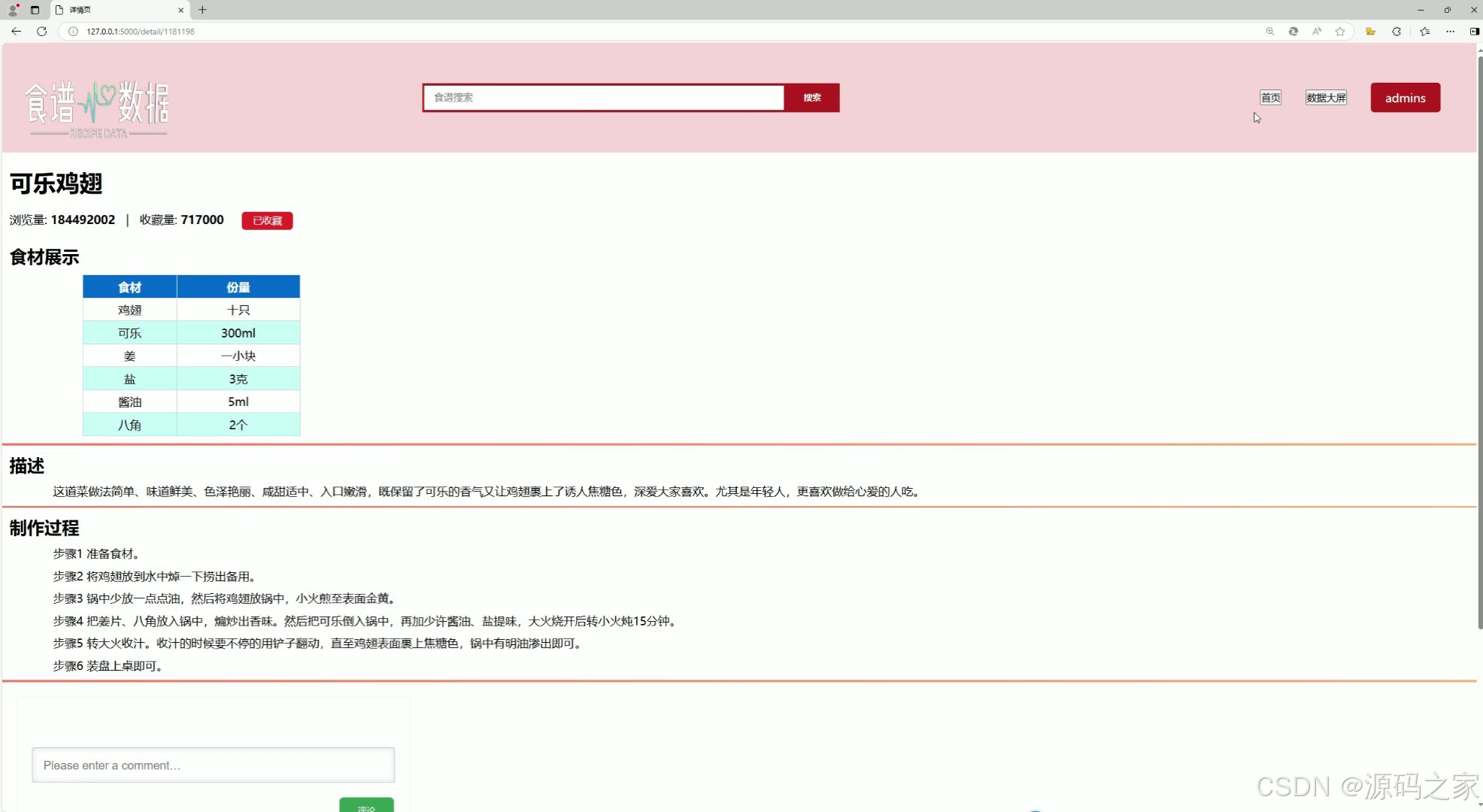
(3)食谱详情
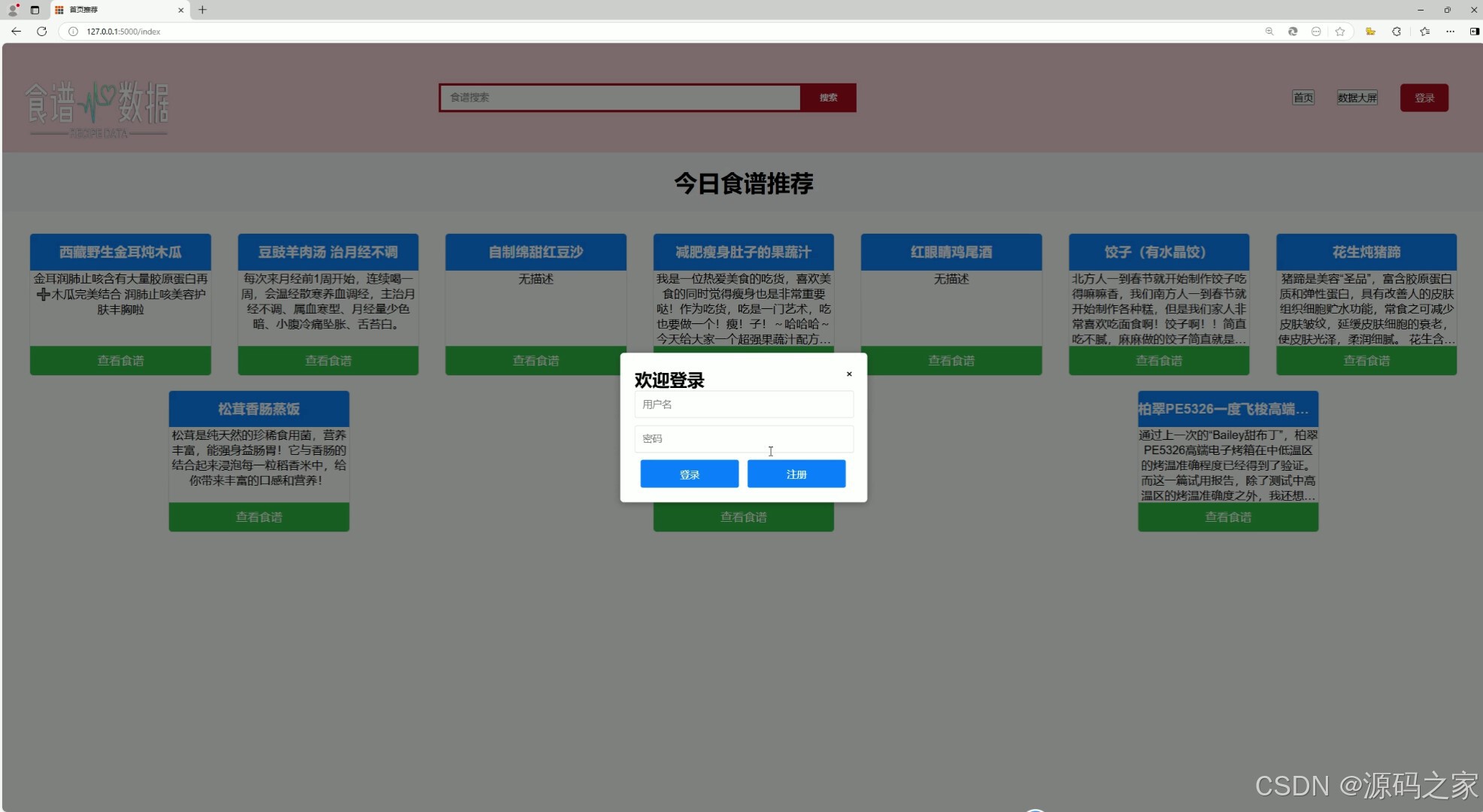
(4)注册登录
3、项目说明
1. 可视化分析大屏
- 功能描述:展示食谱相关的数据分析结果,如热门食材、营养成分分布、用户偏好等。
- 技术实现:
- 使用 Echarts 绘制各种可视化图表,如柱状图、饼图、折线图等。
- 通过 Flask 后端从 MySQL 数据库中提取数据,并传递到前端页面。
- 使用 HTML/CSS/JavaScript 构建前端页面,展示图表和数据。
2. 食谱推荐
- 功能描述:根据用户的偏好、营养需求或历史记录,推荐合适的食谱。
- 技术实现:
- 使用 Python 的数据分析库(如 Pandas、Numpy)处理用户数据和食谱数据。
- 结合 Flask 后端实现推荐逻辑,可能采用基于规则的推荐或简单的协同过滤算法。
- 将推荐结果通过 HTML 页面展示给用户。
3. 食谱详情
- 功能描述:展示单个食谱的详细信息,包括食材清单、烹饪步骤、营养成分等。
- 技术实现:
- 从 MySQL 数据库中查询特定食谱的详细数据。
- 使用 Flask 后端将数据传递到前端。
- 通过 HTML/CSS/Bootstrap 构建美观的食谱详情页面,提升用户体验。
4. 注册登录
- 功能描述:允许用户注册新账号或登录已有账号,以便保存用户偏好和历史记录。
- 技术实现:
- 使用 Flask 提供用户认证功能,包括用户注册、登录和密码管理。
- 使用 MySQL 数据库存储用户信息,包括用户名、密码(加密存储)、偏好设置等。
- 前端使用 HTML/CSS/JavaScript 构建注册和登录表单,并通过 Flask 后端进行验证和处理。
4、核心代码
import json
import random
import time
import requests
from lxml import etree
def get_fenlei():
url = "https://www.douguo.com/fenlei"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
try:
response = requests.get(url=url, headers=headers)
except Exception as e:
print("ERROR: 分类获取失败", url)
return
html = etree.HTML(response.text)
first_classify_items = html.xpath('//h2[@class="title sorttit"]')
classify_list = list()
for first_classify in first_classify_items:
first_title = "".join(first_classify.xpath('./text()')).strip()
second_classify_items = first_classify.xpath('./following-sibling::div[1]/div[@class="sort-item"]')
for second_classify in second_classify_items:
second_title = "".join(second_classify.xpath('./h2/text()')).strip()
third_classify_items = second_classify.xpath('./ul[@class="sortlist clearfix"]/li/a')
for third_classify in third_classify_items:
third_title = "".join(third_classify.xpath('./text()')).strip()
third_link = "".join(third_classify.xpath('./@href')).strip()
third_link = "https://www.douguo.com" + third_link
classify_list.append(
{
"first_title": first_title,
"second_title": second_title,
"third_title": third_title,
"third_link": third_link
}
)
return classify_list
def get_items(classify):
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
item_url = classify["third_link"]
try:
response = requests.get(url=item_url, headers=headers)
except Exception as e:
print("ERROR: 列表页获取失败", item_url)
return
html = etree.HTML(response.text)
items = html.xpath('//li[@class="clearfix"]')
items = items[:5] if len(items) > 5 else items
for item in items:
detail_url = "https://www.douguo.com" + item.xpath('./a[@class="cook-img"]/@href')[0]
stat = "".join(item.xpath('./div/div[@class="score"]/span[contains(text(), "分")]/text()')).strip()
# item.xpath('./div/div[@class="score"]/span[contains(text(), "分")]/text()')
stat = stat.replace("分", "").strip()
classify["detail_url"] = detail_url
classify["stat"] = stat
file.write("{}\n".format(json.dumps(classify, ensure_ascii=False)))
if __name__ == '__main__':
# 获取食谱分类
classify_list = get_fenlei()
print("classify_list:", len(classify_list))
# 采集每个分类下的食谱,翻页
file = open("cookbook.txt", "w", encoding="utf-8")
for index, classify in enumerate(classify_list, start=1):
print("第 {} 个分类".format(index))
get_items(classify)
time.sleep(random.random())
file.close()
5、项目获取
biyesheji0005 或 biyesheji0001 (绿色聊天软件)
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









