







一、集群安装流程
- 准备工作:
首先,有三台linux主机,主机名分别为master,slave1,slave2,各用户名均为hadoop.(尽量不要用root账户,因为root的权限太大了。) - 配置SSH无密码登陆(配置hadoop用户的无密码登录)
- 安装Java环境
- 安装hadoop集群
二、安装Hadoop集群
在master节点上:
下载hadoop压缩包
首先,去apache hadoop官网下载,hadoop压缩包,下载的压缩包都是32位的,如果主机是64位,需要自己编译或者网上下载已经编译好的对应位数的。我下载的为:hadoop-2.6.4.tar.gz
解压
sudo tar -zxvf hadoop-2.6.4.tar.gz -C /home/hadoop/apps/ #解压
修改配置文件
集群分布式安装需要修改hadoop的6个配置文件,分别是:hadoop-env.sh,slaves,core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml。这六个配置文件在/home/hadoop/apps/hadoop-2.6.4/etc/hadoop路径下
(1)hadoop-env.sh
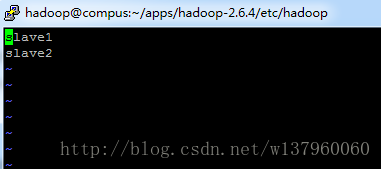
(2)slaves文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。(本教程让 master 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,添加两行内容:)
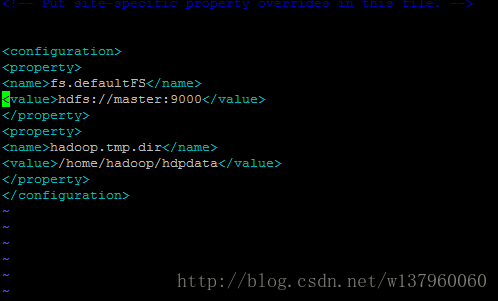
(3)core-site.xml
(4)hdfs-site.xml
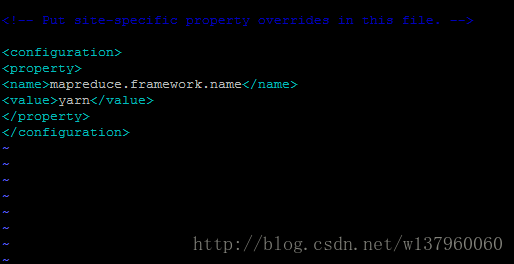
(5)mapred-site.xml文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
(6)yarn-site.xml



4.配置hadoop环境变量
sudo vi /etc/profile #配置

source /etc/profile #使配置的环境变量生效
5.配置好后,将master上的/home/hadoop/apps/hadoop-2.6.4文件夹复制到slave1,slave2节点上。
三、启动hadoop集群
首次启动需要先在 master 节点执行 NameNode 的格式化:
hdfs namenode -format # 首次运行需要执行初始化,之后不需要。
接着,可以启动 hadoop 了,启动需要在 master 节点上进行:
start-dfs.sh
start-yarn.sh
四、网页可视化
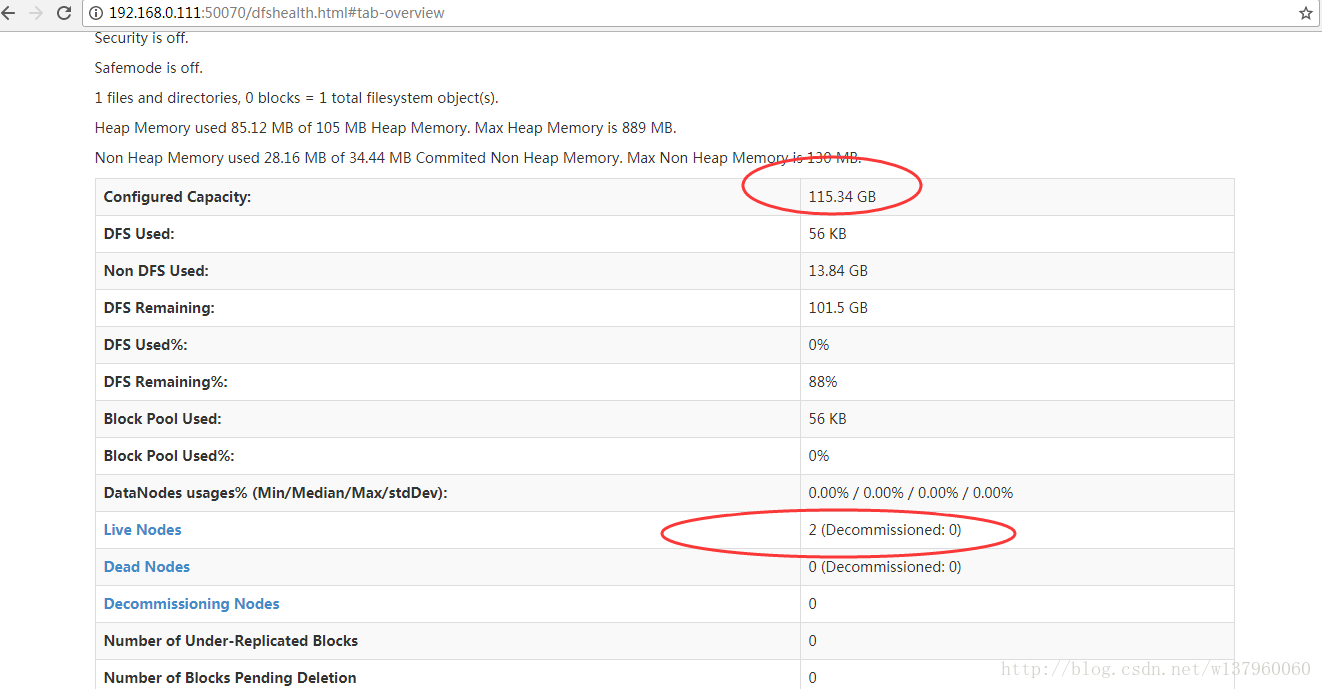
打开浏览器,输入网址:http://master:50070,可以看到如下图效果:















 1631
1631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









