






所用到的库:import pandas as pd
使用pandas工具读取csv文件
data = pd.read_csv(r"文件路径")
选取csv文件中“age”列为例
x = data["age"]
打印csv文件中所有列的空值数量
print(data.isnull().sum())
打印结果如下:
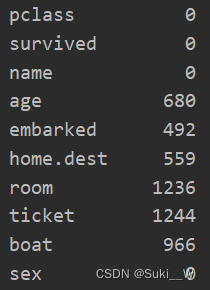
左侧表示列名,右侧表示该列的缺失值数量。
对age列中的缺失值进行处理:使用age的平均值填充缺失值,inplace=True表示直接修改原对象。
data["age"].fillna(x["age"].mean(),inplace=True)
最终,data中age列的缺失值得到了处理。















 743
743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









