








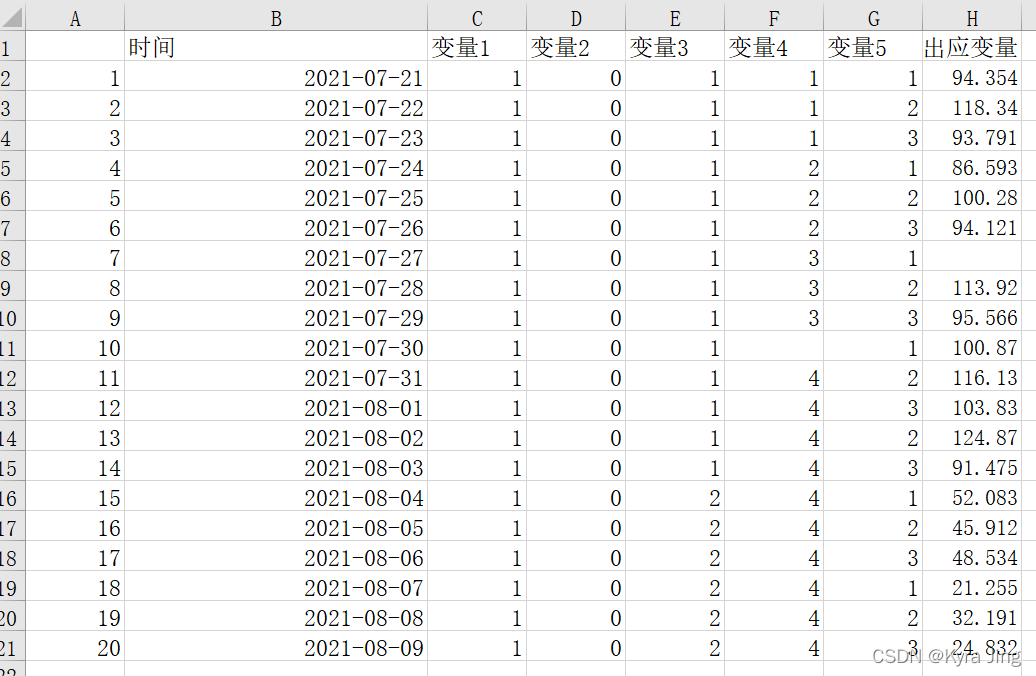
excel文件数据为:
首先导入Pandas模块
import pandas as pd读取excel文件
# 读取excel文件
file_01 = pd.read_excel("data.xls")
print(file_01, '\n')
print('数据维度为:', file_01.shape, '\n', 'file_01的类型为:', type(file_01))返回的结果 为
Unnamed: 0 时间 变量1 变量2 变量3 变量4 变量5 输出应变量
0 1 2021-07-21 00:00:00 1 0 1 1.0 1 94.354
1 2 2021-07-22 00:00:00 1 0 1 1.0 2 118.340
2 3 2021-07-23 00:00:00 1 0 1 1.0 3 93.791
3 4 2021-07-24 00:00:00 1 0 1 2.0 1 86.593
4 5 2021-07-25 17:55:00 1  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2644
2644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









