







 本文介绍了一个使用Java爬虫从巨潮资讯网下载沪深信息科技类上市公司年度报告的实战案例。通过HttpURLConnection模拟POST请求获取JSON数据,解析JSON并构造GET请求下载文件。文中还涉及到线程池和同步机制的使用。
本文介绍了一个使用Java爬虫从巨潮资讯网下载沪深信息科技类上市公司年度报告的实战案例。通过HttpURLConnection模拟POST请求获取JSON数据,解析JSON并构造GET请求下载文件。文中还涉及到线程池和同步机制的使用。
java爬虫实战(2):下载沪深信息科技类上市公司年度报告
*本实战仅作为学习和技术交流使用,转载请注明出处;
本篇实战来源于一位朋友需要进行学术研究,涉及数据内容是2010年-2016年的沪深主板上市信息科技类公司年报,由于并没有现成的数据源,百度之后发现“巨潮咨询网(http://www.cninfo.com.cn/)”中含有所需信息,但需要自己手动下载,工程量大。因此,程序作为提高效率的工具,它的价值就在此。
HttpURLConnection
Java网络编程中经常使用的网络连接类库无疑是HttpClient和HttpURLConnection, 其种HttpURLConnection能实现的,HttpClient都能实现,简单说来HttpCilent是近似于HttpURLConnection的封装。具体二者的区别将另外用一篇博文进行讲解。鉴于本次数据下载只有提交请求及获取Response数据,因此用HttpURLConnection足够。
首先分析目标网站请求响应情况
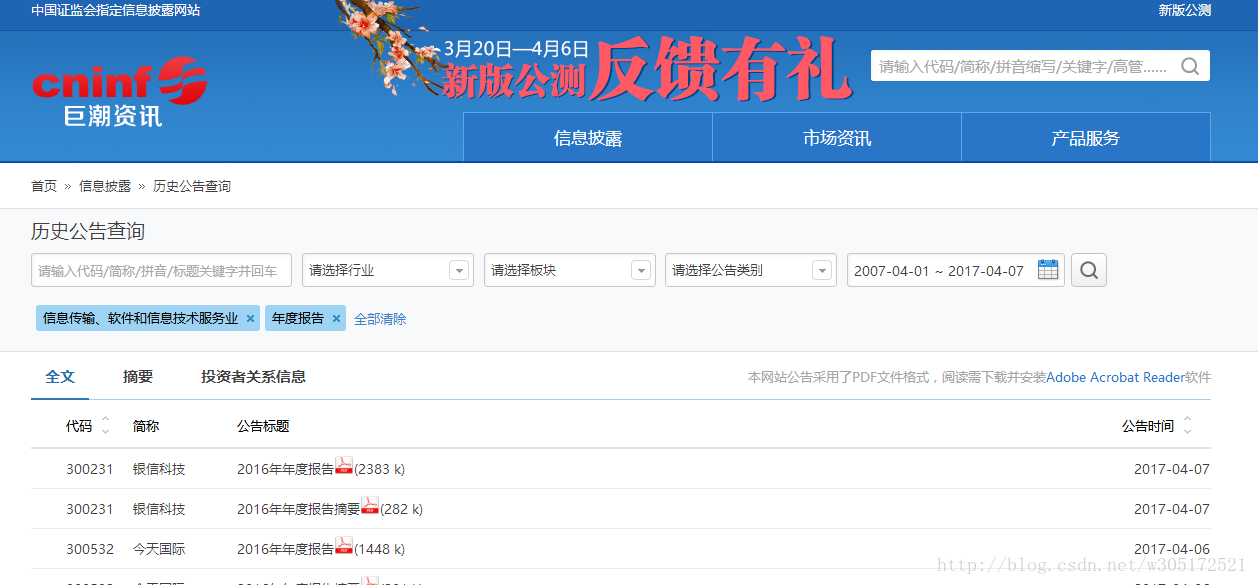
该搜索页面已经提供了详细的搜索条件,选择相应的条目,选择搜索之后,页面通过JQuery的AJAX进行请求封装,而每次页面仅显示30条记录,选择下页将再次触发AJAX请求,进行页面的异步刷新。同时,利用浏览器的调试器中Network可以发现,每次页面请求为POST请求,返回的则是一个JSON对象;JSON对象中包含了下载文件链接的必要参数。到此可知本次下载主要分两个过程:
1.通过POST方式获取到查询结果的所有JSON对象;
2.提取JSON对象中的相应参数,构造下载URL字段;
3.通过GET方式下载文件;
通过POST方式获取JSON
查看网页请求中的post参数,主要有category,trade,pagenum, pageSize,showTitle,seDate等,因此可以根据参数构造post请求。在HttpURLConnection中post请求实质是一个字符串,因此可以按照如下构造请求Content:
String content = "stock=&searchkey=&plate=&category=category_ndbg_szsh;&trade="+URLEncoder.encode("信息传输、软件和信息技术服务业;", "utf-8")+"&column=szse&columnTitle="+URLEncoder.encode("历史公告查询","utf-8")+"&pageNum="+pagenum+"&pageSize=30&tabName=fulltext&sortName=code&sortType=asc&limit=&showTitle="+URLEncoder.encode("信息传输、软件和信息技术服务业/trade/信息传输、软件和信息技术服务业;category_ndbg_szsh/category/年度报告&seDate=请选择日期","utf-8");此处使用了URLEncoder解决url地址中的中文编码问题,在网络编程中也是最常使用的。
URLDecoder.decode("测试", "UTF-8");//解码
URLEncoder.encode("测试", "UTF-8");//编码之后便是构造POST请求的代码
URL url = new URL(urlStr);//利用urlStr字符串构造URL对象
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setConnectTimeout(50000);//设置超时
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36");//设置请求头部User-Agent,防止对方服务器屏蔽程序
//设置post,HttpURLConnection的post设置
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setRequestMethod("POST");
conn.setUseCaches(false);
conn.setInstanceFollowRedirects(true);
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
conn.setChunkedStreamingMode(5); 提交post请求
conn.connect();
DataOutputStream out = new DataOutputStream(conn.getOutputStream());//封装conn的post字节流
//发送post请求
out.writeUTF(content);
out.flush();
out.close();获取Response,即JSON数据流
InputStream inputStream = conn.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream,"UTF-8"));//此处利用InputStreanReader()对返回的字节流做了utf-8编码处理,正是为了完美解决中文乱码问题,利用BufferedReaeder进行流读取,也是java最常见的多写方式
while((line=br.readLine())!=null){
bw.append(line);//bw = new BufferedWriter(new FileWriter("file"));
}通过GET请求获取文件
假设我们用JSON-Lib(下节介绍)已经处理返回的JSON文件,并得到想要的参数构造了GET请求的url地址,此时发起HttpURLConnection的GET请求:
URL url = new URL(urlStr);//urlStr此时为get请求url
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setConnectTimeout(500000);
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36");//同post请求
//通过连接头部截取文件名
String contentDisposition = new String(conn.getHeaderField("Content-Disposition").getBytes("ISO-8859-1"), "GBK");//获取中文文件名
contentDisposition = URLDecoder.decode(contentDisposition,"utf-8");
String filename = contentDisposition.substring(contentDisposition.indexOf('\"') + 1, contentDisposition.lastIndexOf("\""));
//保存文件
File saveDir = new File(savePath);
if(!saveDir.exists())
saveDir.mkdir();
filename = filename.replace("*", "");
File file = new File(saveDir+File.separator+filename);
FileOutputStream fos =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7687
7687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









