






最初接触python爬虫我用的是Request。
随着各大网站反爬虫技术越来越厉害,现在我也就用这个爬爬小说了。
伸手党做了好多年,也该写一篇回馈一下了。
没写过几次文章,排版方面大家将就一下吧
-
selenium安装
pip install selenium
#如果经常连不上 可以选用下一句
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simplepip命令网络连接不上的微坑
-
selenium启动的各种姿势...方式
-
最初的版本
from selenium import webdriver
cb = webdriver.Chrome()
input('按回车结束')#如果不加暂停 程序直接退出可能会以为运行没成功这个是以前最简陋的启动
要根据谷歌浏览器版本 下载对应版本驱动chromedriver.exe
下载网址 CNPM Binaries Mirror![]() https://registry.npmmirror.com/binary.html?path=chromedriver/
https://registry.npmmirror.com/binary.html?path=chromedriver/
但随着谷歌驱动不再更新,你也可以找找谷歌浏览器旧版本停止更新,我是不喜欢旧的,所以我这方式已经弃用。
-
自动更新chromedriver驱动的启动方式
为了随时用新版本的谷歌,我找了找资料,最终选择了webdriver_manager 模块
代码如下
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import shutil
from selenium.webdriver.chrome.service import Service
print("--自动更新驱动中--看网速约10秒到1分钟")
t = ChromeDriverManager().install()#自动下载驱动 返回值是一个路径
# print(t)
shutil.copy(t, './') #拷贝过来
print('驱动更新完毕')
service = Service('./chromedriver.exe')
cb = webdriver.Chrome(service=service)
input('按回车结束')webdriver_manager 模块 会自动下载chromedriver驱动。
然后就可以愉快的玩耍了。
但每次都下载显得有点蠢。再改改代码,先try一下就行了
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import shutil
from selenium.webdriver.chrome.service import Service
service = Service('./chromedriver.exe')
try:
cb = webdriver.Chrome(service=service)
except:
print("--自动更新驱动中--看网速约10秒到1分钟")
t = ChromeDriverManager().install() # 返回值是一个路径
# print(t)
shutil.copy(t, './') # 拷贝过来
print('驱动更新完毕')
cb = webdriver.Chrome(service=service)
input('按回车结束')这样就无需每次下载了,只需要谷歌版本更新的时候花费一点时间即可。
-
增加用户目录启动
随着爬虫的深入使用,会遇到需要cookies文件,缓存文件等的时候。
这个解决方案就是设置增加谷歌系统的用户目录
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import shutil,os
from selenium.webdriver.chrome.service import Service
# 获取当前系统用户目录
user_home = os.path.expanduser('~')
# print(user_home)
p = r'{}\AppData\Local\Google\Chrome\User Data'.format(user_home)
#print(p)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--user-data-dir=' + p) # 设置成用户自己的数据目录
service = Service('./chromedriver.exe')
try:
cb = webdriver.Chrome(service=service,options=chrome_options)
except:
print("--自动更新驱动中--看网速约10秒到1分钟")
t = ChromeDriverManager().install() # 返回值是一个路径
# print(t)
shutil.copy(t, './') # 拷贝过来
print('驱动更新完毕')
cb = webdriver.Chrome(service=service,options=chrome_options)
input('按回车结束')
你可以把代码中 #print(p) 取消注释 查看路径是否正确。
这样就是含有自己用户目录的缓存了,会带有一些账号登录,缓存数据加载等,会更加方便的获取数据。
-
去掉selenium启动的指纹特征
我到了后期,如果获取一些大厂的网站,会有验证码,人机验证,滑动验证等 各种验证码。
有些自动可以过,有些手动都过不了。有些访问直接带验证selenium。
用selenium启动会带有一些标记。还有一些隐藏标记,全部称之为selenium指纹特征。
我以前遇到手动过不了的这个情况,只能先关闭selenium,重新打开谷歌,过了后,再启动selenium继续。太繁琐了,不符合程序员的身份。
在这个时候略微有点糟心的时候,我找了一种新的方法。
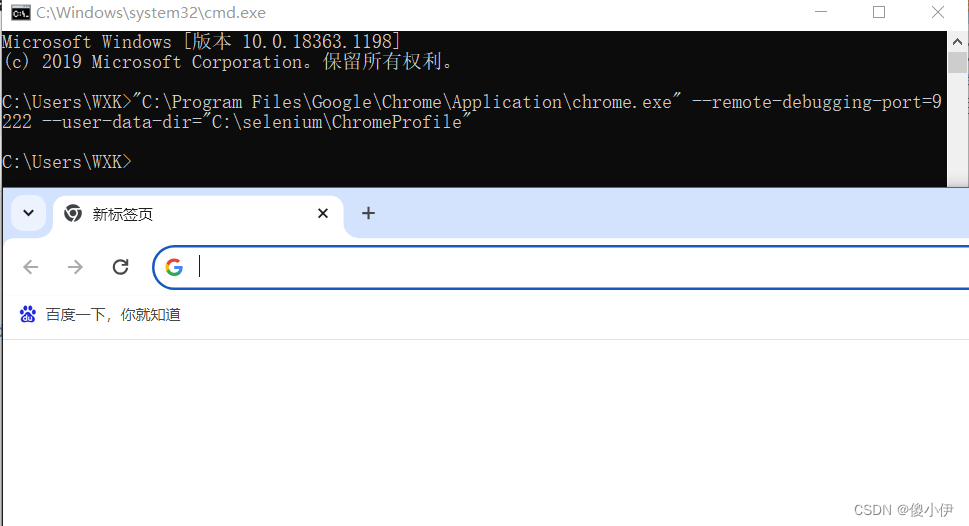
"C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222 --user-data-dir="C:\selenium\ChromeProfile"这是cmd命令启动谷歌的一个debug模式,可以远程连接。
其中"C:\Program Files\Google\Chrome\Application\chrome.exe" 是你的谷歌安装路径。
--remote-debugging-port=9222 这个9222是端口号,可以任意改。
--user-data-dir="C:\selenium\ChromeProfile" 则是自定义用户的缓存目录
 这个浏览器启动方式并不是selenium启动,所以不带selenium指纹特征,清清白白。
这个浏览器启动方式并不是selenium启动,所以不带selenium指纹特征,清清白白。
然后用selenium去远程链接这个已经启动的浏览器,就可以愉快的玩耍了。
上代码
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import shutil,os
from selenium.webdriver.chrome.service import Service
chrome_options = webdriver.ChromeOptions()
cmd=r'"C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222 --user-data-dir="C:\selenium\ChromeProfile"'
os.popen(cmd)#运行cmd命令
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")#端口一致
service = Service('./chromedriver.exe')
try:
cb = webdriver.Chrome(service=service,options=chrome_options)
except:
print("--自动更新驱动中--看网速约10秒到1分钟")
t = ChromeDriverManager().install() # 返回值是一个路径
# print(t)
shutil.copy(t, './') # 拷贝过来
print('驱动更新完毕')
cb = webdriver.Chrome(service=service,options=chrome_options)
cb.get('https://www.csdn.net/?spm=1011.2266.3001.4476')#测试网址
input('按回车结束')
这样一来,就没有selenium启动指纹特征,和一些隐藏的标记了。
可以保证验证码手动是必过的。自动的话看各家算法犀利程度了。
这个是我目前的终极方案,时间2023.10.28.
技术会不断进步更新,与君共勉。
-------------------------------------------------------
题外话
技术用之正则正,用之邪则邪。
各位千万不要写1秒并发好几百个线程去爬取数据,搞崩人家服务器,做人留一线。
不要去爬取重要网站的信息,多看看新闻,多学学法,悠着点自用就行了哈。















 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









