







前言
由于其某种垄断优势不得不在部分场合加入DGL,不得不学一下API。
用户手册
中文 https://docs.dgl.ai/guide_cn/
英文 https://docs.dgl.ai/guide/index.html
API 手册
https://docs.dgl.ai/en/latest/api/python/dgl.DGLGraph.html
Github
https://github.com/dmlc/dgl
本文通用头,基于PyTorch
import dgl
import torch
import torch as th
import numpy as np
一、数据
dgl储存数据的方式非常古典而且反人类,字典式索引,既不自由也不标准,既不灵活也不便捷。
1 图的初始化
1.1 dgl.graph
先看图的初始化
dgl.graph等价于from dgl.convert import graph
位于/dgl/convert.py: def graph(...) --> DGLGraph
定位就是转化函数。
https://github.com/dmlc/dgl/blob/acd21a6d60e40ab0da39ffd30ffa943c798b52a9/python/dgl/convert.py
注意
DGLGraph 的边总是有向的。
案例
g = dgl.graph(([0, 0, 1, 5], [1, 2, 2, 0]))
#等价于
g = dgl.graph(data=([0, 0, 1, 5], [1, 2, 2, 0]))
print(g.adj())
>tensor(indices=tensor([[0, 0, 1, 5],
[1, 2, 2, 0]]),
values=tensor([1., 1., 1., 1.]),
size=(6, 6), nnz=4, layout=torch.sparse_coo)
#dgl.graph返回值默认是一个异构图
print(type(g))
>dgl.heterograph.DGLHeteroGraph
dgl支持用2个 1-d node index list进行初始化,
其中 node index list支持的格式如
① (tensor,tensor)
row = torch.tensor([0, 0, 1, 5])
col = torch.tensor([1, 2, 2, 0])
g = dgl.graph(data=(row,col))
注意支持的是1-D的(tensor, tensor),必须是tuple。
如果写成
dgl.graph(data=[row,col])
会报错too many values to unpack (expected 2)
要注意是tensor而不是Tensor
row = torch.Tensor([0, 0, 1, 5])
col = torch.Tensor([1, 2, 2, 0])
dgl.graph(data=(row,col)).adj()
报错DGLError: [08:21:00] /opt/dgl/src/graph/unit_graph.cc:67: Check failed: aten::IsValidIdArray(src): Stack trace:
不知道为什么支持tuple不支持list,支持tensor不支持Tensor。
学学numpy对传入数据的多样性支持。
②coo_matrix
coo_matrix等价于① 。
dgl.graph(data=(‘coo’,(row,col)) )
举例
row = np.array([0, 0, 1, 5])
col = np.array([1, 2, 2, 0])
data = np.array([1, 1, 1, 1])
g_coo = sp.coo_matrix( arg1=(data,[row,col]),shape=(6,6))
row = torch.tensor([0, 0, 1, 5])
col = torch.tensor([1, 2, 2, 0])
#data= torch.tensor([1,2,3,5])
g = dgl.graph(data=('coo',(row,col))).adj()
print(g_coo.todense())
>matrix([[0, 1, 1, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0]])
print(g.adj().to_dense())
>tensor([[0., 1., 1., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[1., 0., 0., 0., 0., 0.]])
你看看人家scipy都支持list [row , col]。
事实上,应该说①(tensor,tensor)等价于②(‘coo’, (tensor,tensor))
dgl.Graph()会调用graphdata2tensors()来处理数据。
在graphdata2tensors()中。如果没有一开始的str指示format,会默认补上’coo’。
见代码:
#/dgl/python/dgl/utils/data.py -> graphdata2tensors()
if isinstance(data, tuple):
if not isinstance(data[0], str):
# (row, col) format, convert to ('coo', (row, col))
data = ('coo', data)
data = SparseAdjTuple(*data)
③ csr_matrix, csc_matrix
类似②
row = np.array([0, 0, 1, 5])
col = np.array([1, 2, 2, 0])
data = np.array([1, 1, 1, 1])
g_coo = sp.coo_matrix( arg1=(data,[row,col]),shape=(6,6))
g_csr = g_coo.to_csr()
g_csc = g_coo.to_csc()
data = g_csr.data
csr_indices = g_csr.indices
csr_indptr = g_csr.indptr
csc_indices = g_csc.indices
csc_indptr = g_csc.indptr
#dgl里不支持传入data,而需要为edge编号。
# 这里默认用0开始顺序编号
edgeids = range(len(data))
g = dgl.graph(data=('csr',(csr_indptr, csr_indices, edgeids)))
print(g.adj().to_dense())
g = dgl.graph(data=('csc',(csc_indptr, csc_indices, edgeids)))
print(g.adj().to_dense())
1.2 dgl.from_scipy()
会自动识别scipy格式,自动编号,好评。
row = np.array([0, 0, 1, 5])
col = np.array([1, 2, 2, 0])
data = np.array([1, 1, 1, 1])
g_coo = sp.coo_matrix( arg1=(data,[row,col]),shape=(6,6))
g_csr = g_coo.tocsr()
g_csc = g_coo.toscs()
dgl.from_scipy(g_coo)
dgl.from_scipy(g_csr)
dgl.from_scipy(g_csc)
1.3 增加结点特征
本例默认g为同构图。
直接赋值
tensor_a = torch.zeros((num_nodes, num_features))
g.ndata['key1'] = tensor_a
Q:异构图图中,直接使用
g.ndata[key]赋值,可能会出错?
g.nodes['drug'].data[‘hv’]等价于g.ndata[‘hv’]['drug']。其中g.ndata['hv']返回一个dict,默认keys由node_types组成。
1.4 增加边特征
增加边特征
DGLGraph.apply_edges(edge_fn)
其中edge_fn是一个接受edges为参数,返回dict的处理函数。
返回值必须是字典,不同的边属性包裹在不同的key里。
如果不返回字典会报错
DGLError: Expect dictionary type for feature data. Got "xxxx" instead.。
example:
def edge_fn(edges):
print(type(edges))
# 获得边的数量
print(len(edges))
print(edges.batch_size())
# 边的类型
print(edges.canonical_etype)
# 边的数据
print(edges.data)
# 获得边的索引
rows,cols, indices = edges.edges()
print(edges.edges())
# (tensor([0, 0, 1, 5]), tensor([1, 2, 2, 0]), tensor([0, 1, 2, 3]))
# 其中 indices == edges._eid
print(edges._eid)
# 访问两端结点
src_nodes, dst_nodes = edges.src, edges.dst
print('src_nodes',src_nodes)
print('dst_nodes',dst_nodes)
# 简单一点
print(edges._src_data, edges._dst_data)
return {}
"""
<class 'dgl.udf.EdgeBatch'>
4
4
('_N', '_E', '_N')
{}
(tensor([0, 0, 1, 5]), tensor([1, 2, 2, 0]), tensor([0, 1, 2, 3]))
tensor([0, 1, 2, 3])
src_nodes {'key1': tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])}
dst_nodes {'key1': tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])}
{'key1': tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])} {'key1': tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])}
"""
其他处理
dgl.to_bidirected(g) 变成对称图。
dgl.line_graph
按plot那边的意思是折线图。
按定义我觉得翻译成“边图”比较好。
The line graph
L(G)of a given graphGis defined as another graph where
the nodes inL(G)correspond to the edges inG. For any pair of edges(u, v)
and(v, w)inG, the corresponding node of edge(u, v)inL(G)will
have an edge connecting to the corresponding node of edge(v, w).
“边图”上的一个结点对应原图上的一条边。
“边图”上的两个结点之间有边,对应着原图上的这两条边之间有公共结点。
由于dgl中的edge都是有向的。
边图上的一条边 Node(u,v) -> Node(v,w) 代表 原图上的两条边 (u,v) 与 (v,w) 可首尾连接。
代表 原图上的结点 u -> 结点w 可到达。
代表 start(Node(u,v)) -> end(Node(v,w)) 可到达。
所以默认情况下, 在“边图”上,应该存在两条边。
Node(u,v) -> Node(v,u),
Node(v,u) -> Node(u,v)。
这两条边对应原图上的 self-edge,
即 start(Node(u,v)) -> end(Node(v,u)) = u->u 的可到达,
与 start(Node(v,u)) -> end(Node(u,v)) = v->v 的可到达。
这种关系对我们来说可能是没有意义的。
所以dgl允许我们关闭这种表示
dgl.line_graph(g, backtracking=True, shared=False)
设置backtracking=False,就能删掉 Node(u,v) -> Node(v,u), Node(v,u) -> Node(u,v) 两条自边。
2.异构图
上文说到dgl.graph返回值默认是一个异构图。
dgl里的异构图,就是允许给不同 name 的node和edge添加独立的id空间和feature空间,通关类似字典的形式存储。
在DGL中,一个异构图由一系列子图构成,一个子图对应一种关系。每个关系由一个字符串三元组定义 (源节点类型, 边类型, 目标节点类型) 。由于这里的关系定义消除了边类型的歧义,DGL称它们为规范边类型。
In DGL, a heterogeneous graph (heterograph for short) is specified with a series of graphs as below, one per relation. Each relation is a string triplet
(source node type, edge type, destination node type). Since relations disambiguate the edge types, DGL calls them canonical edge types.
我必须强烈吐槽一下这个存储方式。
按这种存储方式,假设我们有3种relation。
‘customer’ ‘buy’ ‘milk’在 dgl里被拆成
‘customer’ ‘buy’ ‘meat’
‘market’ ‘sell’ ‘meat’
ntype:[ ‘customer’, ‘market’ , ‘milk’, ‘meat’]
etype:[‘buy’, ‘sell’ ]
这样存储。
问题是,
这样4种ntype和2种etype的理论组合上限是4C2 * 2 = 12种。
远大于实际的3种relation。
文件位置
#/site-packages/dgl/heterograph.py/
class DGLHeteroGraph:
见例子
graph_data = {
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'interacts', 'gene'): (th.tensor([0, 1]), th.tensor([2, 3])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2])),
('drug', 'treats', 'drug'): (th.tensor([1]), th.tensor([2]))
}
g = dgl.heterograph(graph_data)
print(type(g))
print(g.ntypes)
print(g.etypes)
>
<class 'dgl.heterograph.DGLHeteroGraph'>
['disease', 'drug', 'gene']
['interacts', 'interacts', 'treats', 'treats']
可以看到,etypes里存储了2个’interacts’和2个’treats’。
虽然他们名字长得一样,但在dgl里被识别为不同。
为什么会产生这种结果呢。
print(g)
>
Graph(num_nodes={'disease': 3, 'drug': 3, 'gene': 4},
num_edges={('drug', 'interacts', 'drug'): 2, ('drug', 'interacts', 'gene'): 2, ('drug', 'treats', 'disease'): 1, ('drug', 'treats', 'drug'): 1},
metagraph=[('drug', 'drug', 'interacts'), ('drug', 'drug', 'treats'), ('drug', 'gene', 'interacts'), ('drug', 'disease', 'treats')])
可以看到metagraph里完整地保留了原始的relations。
所以dgl并不会弄混2个同名的etype。
值得一提的是,
DGLHeteroGraph.metagraph()
返回值是networkx.MultiDiGraph。
内部先转成networkx再取…
于是dgl中获得metagraph信息的一般方式
print(g.metagraph().edges())
print(g.metagraph().edges(keys=True))
>
[('drug', 'drug'), ('drug', 'drug'), ('drug', 'gene'), ('drug', 'disease')]
[('drug', 'drug', 'interacts'), ('drug', 'drug', 'treats'), ('drug', 'gene', 'interacts'), ('drug', 'disease', 'treats')]
这个api似乎有点太长了,事实上不通过metagraph()也可以获得完整的relations。
print(g.etypes)
print(g.canonical_etypes)
>
>['interacts', 'interacts', 'treats', 'treats']
[('drug', 'interacts', 'drug'), ('drug', 'interacts', 'gene'), ('drug', 'treats', 'disease'), ('drug', 'treats', 'drug')]
g.canonical_etypes可以帮我们在单个etype不能唯一指向某个relation时帮助定位。
g.adj(etype='treats')
>DGLError: Edge type "treats" is ambiguous. Please use canonical edge type in the form of (srctype, etype, dsttype)
g.adj(etype=('drug', 'treats', 'disease'))
>tensor(indices=tensor([[1],
[2]]),
values=tensor([1.]),
size=(3, 3), nnz=1, layout=torch.sparse_coo)
两者之间可以通关api转换
DGLGraph.to_canonical_etype(etype)
g.to_canonical_etype(g.etypes[0])
但是也受模糊语义影响,如果etype不能唯一指向某个边类型,这个转换函数也会报错。
DGLError: Edge type "interacts" is ambiguous. Please use canonical edge type in the form of (srctype, etype, dsttype)
再引入类HeteroGraphIndex (/site-packages/dgl/heterograph_index.py)
DGLHeterograph中
self._graph = gidx
HeteroGraphIndex类存储了图的大部分关键数据。
DGLHeterograph通过操作self._graph获得这些数据,
例如self.number_of_src_nodes()。
另外来看
print(g.srctypes)
print(g.dsttypes)
>
['disease', 'drug', 'gene']
['disease', 'drug', 'gene']
这个很不符合直觉。
在我们的定义里,disease从未成为src node。
造成这个现象的原因是
@property
def srctypes():
if self.is_unibipartite:
return sorted(list(self._srctypes_invmap.keys()))
else:
return self.ntypes
@property
def dsttypes():
if self.is_unibipartite:
return sorted(list(self._dsttypes_invmap.keys()))
else:
return self.ntypes
只有self.is_unibipartite == True时才区分src与dst。
否则统一返回self.ntypes。
取结点数与结点id。
print(g.num_nodes('drug'))
print(g.num_nodes('gene'))
>
3
4
print(g.nodes('drug'))
print(g.nodes('gene'))
>#不同nodetype单独编号
tensor([0, 1, 2])
tensor([0, 1, 2, 3])
注意,g.number_of_nodes()底层调用g.num_nodes()
不传入etype时,返回全部类别结点数的和。
取边数,入度,出度
#不指定类型时,sum所有边类型
print(g.g.num_edges())
#等价于 print(g.g.num_edges(etype=None))
#等价于 print(g.g.num_edges(None))
#指定类型
print(g.num_edges(etype=g.c)
# feature
截止上文,我们主要在做connection上的构筑。
这样得到的图有adj但没有feautre。
>为了设置/获取特定节点和边类型的特征,DGL提供了两种新类型的语法:
g.nodes[‘node_type’].data[‘feat_name’]
g.edges[‘edge_type’].data[‘feat_name’]
注意下面例子中的层级关系
```python
graph_data = {
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'interacts', 'gene'): (th.tensor([0, 1]), th.tensor([2, 3])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2])),
('drug', 'treats', 'drug'): (th.tensor([1]), th.tensor([2]))
}
g = dgl.heterograph(graph_data)
g.nodes['drug'].data['hv'] = th.ones(3, 1)
print(g.nodes['drug'])
>NodeSpace(data={'hv': tensor([[1.],
[1.],
[1.]])})
#这与下列api访问同一块内存
print(g.ndata['hv'])
>{'drug': tensor([[1.],
[1.],
[1.]])}
print(g.ndata['hv']['drug'] == g.nodes['drug'].data['hv'])
>tensor([[True],
[True],
[True]])
上面例子中需要注意几点
g.nodes('drug')得到tensor(0,1,2)即结点编号。g.nodes['drug']返回一个NodeSpace,其中默认含有属性data:dict。g.nodes['drug'].data['hv']等于g.ndata['hv']['drug']。其中g.ndata['hv']返回一个dict,默认keys由node_types组成。
3.异构转同构图
异构图为管理不同类型的节点和边及其相关特征提供了一个清晰的接口。这在以下情况下尤其有用:
- 不同类型的节点和边的特征具有不同的数据类型或大小。
- 用户希望对不同类型的节点和边应用不同的操作。
如果上述情况不适用,并且用户不希望在建模中区分节点和边的类型,则DGL允许使用 dgl.DGLGraph.to_homogeneous() API将异构图转换为同构图。 具体行为如下:
- 用从0开始的连续整数重新标记所有类型的节点和边。
- 对所有的节点和边合并用户指定的特征。
https://docs.dgl.ai/generated/dgl.to_homogeneous.html
https://docs.dgl.ai/generated/dgl.to_heterogeneous.html
3.1 样例
用官方example来看一下
g = dgl.heterograph({
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2]))})
hg = dgl.to_homogeneous(g)
对node的重编号
print(hg.ndata)
>{'_ID': tensor([0, 1, 2, 0, 1, 2]), '_TYPE': tensor([0, 0, 0, 1, 1, 1])}
#作为参考
print(g.ntypes)
>['disease', 'drug']
可以看到,原始异构图的编号和类别都存在两个key里。
这两个key被 dgl.NTYPE和dgl.NID定义。
print(dgl.NTYPE)
print(dgl.NID)
>
_TYPE
_ID
同时边的ID也被重新编号了。
类似的也有2个宏变量定义了这两个key。
print(hg.edata)
>{'_ID': tensor([0, 1, 0]), '_TYPE': tensor([0, 0, 1])}
print(dgl.ETYPE)
print(dgl.EID)
>
_TYPE
_ID
3.2 注意事项
3.2.1 由于异构图总是有向图,直接转为同构图后,adj未必对称
g = dgl.heterograph({
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2]))})
hg = dgl.to_homogeneous(g)
print(hg.adj().to_dense())
>
tensor([[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0.],
[0., 0., 1., 0., 0., 1.],
[0., 0., 0., 0., 0., 0.]])
观察上述adj显然不对称。
需要进一步转换
#numpy 形式
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
#torch 形式
adj = adj + adj.t() * (adj.t() > adj) - adj * (adj.t() > adj)
3.2.2 不指定feat field时,默认不携带feat
g = dgl.heterograph({
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2]))})
g.nodes['drug'].data['hv'] = th.zeros(3, 1)
g.nodes['disease'].data['hv'] = th.ones(3, 1)
#不指定feat field
hg = dgl.to_homogeneous(g)
print(hg.ndata)
>
{'_ID': tensor([0, 1, 2, 0, 1, 2]), '_TYPE': tensor([0, 0, 0, 1, 1, 1])}
#指定feat field
hg = dgl.to_homogeneous(g, ndata=['hv'])
print(hg.ndata)
>
{'hv': tensor([[1.],
[1.],
[1.],
[0.],
[0.],
[0.]]), '_ID': tensor([0, 1, 2, 0, 1, 2]), '_TYPE': tensor([0, 0, 0, 1, 1, 1])}
指定edata同理。
hg = dgl.to_homogeneous(g, edata=[‘hv’])
需要注意的是,指定ndata fields时,需要所有ntype上都绑定了这个field name才能有效保留。
否则dgl将自动丢弃该field。
g = dgl.heterograph({
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2]))})
g.nodes['drug'].data['hv'] = th.zeros(3, 1)
#我们不给'disease'这个ntype 绑定'hv' field
#g.nodes['disease'].data['hv'] = th.ones(3, 1)
hg = dgl.to_homogeneous(g, ndata=['hv'])
print(hg.ndata)
3.2.3 同质图不保存ntypes和etypes
print(hg.ntypes)
> '_N'
print(hg.etypes)
>'_E'
3.2.4 多种边类型,导致adj权重不为1
g = dgl.heterograph({
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'treats', 'drug'): (th.tensor([0]), th.tensor([1]))})
hg = dgl.to_homogeneous(g)
print(hg.adj().to_dense())
>tensor([[0., 2., 0.],
[0., 0., 1.],
[0., 0., 0.]])
结点0,1之间有2种关系的连边。
3.3 转回异构图
可以变成同构图,显然还能再转回异构图。
dgl.to_heterogeneous(G, ntypes, etypes, ntype_field='_TYPE', etype_field='_TYPE', metagraph=None)提供了这一功能
只不过转回去的时候,需要提供ntypes和etypes,注意到这两个数据是没有存储在homogeneous graph里的。
转换结束后,会额外存储每个type的结点和边,在同质图里的ID索引。
g = dgl.heterograph({
('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2]))})
hg = dgl.to_homogeneous(g)
g2 = dgl.to_heterogeneous(hg,ntypes=g.ntypes,etypes=g.etypes)
print(g2.ndata)
>
defaultdict(<class 'dict'>, {'_ID': {'disease': tensor([0, 1, 2]), 'drug': tensor([3, 4, 5])}})
print(g2.edata)
>
defaultdict(<class 'dict'>, {'_ID': {('drug', 'interacts', 'drug'): tensor([0, 1]), ('drug', 'treats', 'disease'): tensor([2])}})
#换一个写法的话
g2 = dgl.to_heterogeneous(hg,ntypes=g.ntypes,etypes=g.canonical_etypes)
print(g2.edata)
>defaultdict(<class 'dict'>, {'_ID': {('drug', ('drug', 'interacts', 'drug'), 'drug'): tensor([0, 1]), ('drug', ('drug', 'treats', 'disease'), 'disease'): tensor([2])}})
warning:
4. dataset
4.1 hetero node classfication
import dgl
from dgl.data.rdf import AIFBDataset, MUTAGDataset, BGSDataset, AMDataset
hg = dataset[0] #dgl.DGLGraph
dgl.save_graphs() 和 dgl.load_graphs()
二、模型
from dgl.nn.pytorch import GraphConv, GATConv, RelGraphConv
GraphConv
实现的GC操作是带norm的。
h
i
(
l
+
1
)
=
σ
(
b
(
l
)
+
∑
j
∈
N
(
i
)
1
c
i
j
h
j
(
l
)
W
(
l
)
)
h_i^{(l+1)} = \sigma(b^{(l)} + \sum_{j\in\mathcal{N}(i)}\frac{1}{c_{ij}}h_j^{(l)}W^{(l)})
hi(l+1)=σ(b(l)+∑j∈N(i)cij1hj(l)W(l))
以入度或出度为norm。
norm=‘right’ 表示
c
i
j
=
1
out_degree
c_{ij}=\frac{1}{\text{out\_degree}}
cij=out_degree1,就等于是对neighbors求均值了。
norm=‘both’ 表示
c
i
j
=
1
d
in
d
out
c_{ij}=\frac{1}{\sqrt{d_\text{in}}\sqrt{d_\text{out}}}
cij=dindout1
norm = ‘None’ 表示 c i j = 1 c_{ij}=1 cij=1,即不norm。
’both’的时候相当于 原版GCN,对A做了norm得到
A
^
\hat{A}
A^
'right’相当于randomwalk的
D
−
1
A
D^{-1}A
D−1A。
update_all
自带fn_sum自动沿着adj进行sum。
RelGraphConv
h i ( l + 1 ) = σ ( ∑ r ∈ R ∑ j ∈ N r ( i ) e j , i W r ( l ) h j ( l ) + W 0 ( l ) h i ( l ) ) h_i^{(l+1)} = \sigma(\sum_{r\in\mathcal{R}} \sum_{j\in\mathcal{N}^r(i)}e_{j,i}W_r^{(l)}h_j^{(l)}+W_0^{(l)}h_i^{(l)}) hi(l+1)=σ(∑r∈R∑j∈Nr(i)ej,iWr(l)hj(l)+W0(l)hi(l))
where
N
r
(
i
)
\mathcal{N}^r(i)
Nr(i) is the neighbor set of node
i
i
i w.r.t. relation
r
r
r.
e
j
,
i
e_{j,i}
ej,i is the normalizer.
σ
\sigma
σ is an activation function.
W
0
W_0
W0 is the self-loop weight.
The basis regularization decomposes
W
r
W_r
Wr by:
W
r
(
l
)
=
∑
b
=
1
B
a
r
b
(
l
)
V
b
(
l
)
W_r^{(l)} = \sum_{b=1}^B a_{rb}^{(l)}V_b^{(l)}
Wr(l)=∑b=1Barb(l)Vb(l)
where
B
B
B is the number of bases,
V
b
(
l
)
V_b^{(l)}
Vb(l) are linearly combined with coefficients
a
r
b
(
l
)
a_{rb}^{(l)}
arb(l).
The block-diagonal-decomposition regularization decomposes W r W_r Wr into B B B number of block diagonal matrices. We refer B B B as the number of bases.
The block regularization decomposes W r W_r Wr by:
W
r
(
l
)
=
⊕
b
=
1
B
Q
r
b
(
l
)
W_r^{(l)} = \oplus_{b=1}^B Q_{rb}^{(l)}
Wr(l)=⊕b=1BQrb(l)
where
B
B
B is the number of bases,
Q
r
b
(
l
)
Q_{rb}^{(l)}
Qrb(l) are block bases with shape
R
(
d
(
l
+
1
)
/
B
)
∗
(
d
l
/
B
)
R^{(d^{(l+1)}/B)*(d^{l}/B)}
R(d(l+1)/B)∗(dl/B).
关注初始化和前向传播。
def __init__(self,
in_feat,
out_feat,
num_rels,
regularizer="basis",
num_bases=None,
bias=True,
activation=None,
self_loop=True,
low_mem=False,
dropout=0.0,
layer_norm=False):
初始化的必要参数。
in,out维数,很常规。
num_rels。
num_bases,不给就用num_rels.
def forward(self, g, feat, etypes, norm=None):
g 是 DGLGraph类的实例。
-
feat
- ( ∣ V ∣ , D ) (|V|, D) (∣V∣,D) 就是经典的feat。
- ( ∣ V ∣ , ) (|V|,) (∣V∣,) list of category ids. 例如 feat=torch.arange(num_nodes),自动处理成one-hot features。
传进来如果是1d,feat会被处理成 ( ∣ V ∣ , ∣ V ∣ ) (|V|,|V|) (∣V∣,∣V∣),即默认 D = ∣ V ∣ D=|V| D=∣V∣。
因此需要在__init__中提前将 in_feat=num_nodes。 -
etypes
torch.Tensor or list[int].
Edge type data. Could be either-
(
∣
E
∣
,
)
(|E|,)
(∣E∣,) dense tensor。 Each element corresponds to the edge’s type ID. Preferred format if
lowmem == False. -
list[int]
\text{list[int]}
list[int], The
i
t
h
i^{th}
ith element is the number of edges of the
i
t
h
i^{th}
ith type. 要求按etype顺序存储。This requires the input graph to store edges sorted by their type IDs. Preferred format if
lowmem == True.
list类型的etypes会被转回(|E|,)类型的dense tensor
if isinstance(etypes, list): etypes = th.repeat_interleave( th.arange(len(etypes), device=device), th.tensor(etypes, device=device)) ``` -
(
∣
E
∣
,
)
(|E|,)
(∣E∣,) dense tensor。 Each element corresponds to the edge’s type ID. Preferred format if
-
norm
( ∣ E ∣ , 1 ) (|E|, 1) (∣E∣,1) tensor
feat.ndim==1的时候,默认feat是node’s ID, 就会根据etype,从(n_rel*n_node,outdim)的W中选出(|E|,outdim)。依据是当前edge的 etype和srcnode的id(即feat)
flatidx = etypes * input_dim + feat 。
flatidx = etypes * n_nodes+ src_nodes
看完forward会发现,只有ndata作为feature被用到了。
edata没有用到。
但是etype很有意义。
update_all
dgl里的核心消息传递+聚合函数。
我们常见的形式是这样的
g.update_all(message_func, reduce_func, apply_func)
我们可以自由定义其中的message_func,reduce_func, apply_func.
然后dgl不鼓励我们在update_all里面作apply。(我的理解是,这样会使得整个过程不那么函数式…但是他们设计这个update_all我就觉得很反人类了,还要靠对使用者的规范来达成某种合规就更离谱了。)
所以更简单一点,我们只需要自定义message_func和reduce_func就可以了。
其中message_func的通用范式是一个接受唯一参数edges的func。
edges是dgl.udf.EdgeBatch的实例(dgl/python/dgl/udf.py)。
def my_message_func(edges):
#键名可以不是'msg',只要跟下一步的聚合函数对应上就行。
# 上文中我们使用了 fn.sum(msg='msg', out='h')作为聚合函数,
# 表示从键名'msg'取消息,所以此处用'msg'。
# bianliang msg.shape=(|E|,outdim)
return {'msg':msg}
你可以认为底层的调用遵循下列伪代码
for canonical_etype in g.canonical_etypes:
edges = g.edges(canonical_etype)
res_dict = my_message_func(edges) #{'msg': msg}
g.edata.update(res_dict)
他们这个relvconv
用
h = edges.src[‘h’]
w = (|E|,in_dim,out_dim)
E,1,I X E I O -> E 1 O -> E O
msg = torch.bmm(edges.src[‘h’].unsqueeze(1), w).squeeze()
消息传递阶段,读edges.src[feature_field]和edges.dst[feature_field]进行某种操作,然后存到某个key里 g.edata[key]。
聚合(reduce)阶段 ,读 nodes.mailbox[key],
这里一开始看会有点疑惑。
消息传递是逐边进行的,产生的edata[key]有(|E|,D)个结果。
但到了reduce阶段,传入的参数又是nodes,是逐node运算的,|V|个结果。
根据图拓扑结构的不同,部分node在message阶段会有多个消息(多个relation上都作为dst node)。
也有部分node可能没有消息。
nodes.mailbox就是一个统合这种不确定消息的结构。
class NodeBatch(object):
@property
def mailbox(self):
return self._msgs #dict[str, Tensor]
nodes.mailbox[msg_key].shape = (N, num_msg, msg_dim)
其中num_msg应该以当前batch的最大数量为准。
dgl会自动将没有msg的部分置0。
一个很常见的内置api是dgl.function.sum(‘m’, ‘h’)
差不多等于
def reduce_func(nodes):
return {'h': torch.sum(nodes.mailbox['m'], dim=1)}
直接把num_msg条全部相加。得到(N,msg_dim)
EdegBatchyou
\core.py
evoke udf func
dgl.metapath_reachable_graph
按metapath重新定义adj。
g.canonical_etypes
[('author', 'ap', 'paper'),
('field', 'fp', 'paper'),
('paper', 'pa', 'author'),
('paper', 'pf', 'field')]
new_g = dgl.metapath_reachable_graph(g,metapath=['pa','ap'])
new_g.canonical_etypes
[('paper', '_E', 'paper')]
那么问题来了!!!
我有2条metapath,分别提取了两个new_g出来 !!
怎么才能合并到一起 ???
这应该是一个很直观的能力,但对不起不好意思,合并不了。
只能手动,重新。
提取出edges,然后dgl. heterograph()重新构造一个图。再把feat赋值过去。
Bug
这个Bug是升级到torch 1.10之后, dgl停留在0.6版本导致的。
RuntimeError: Bool type is not supported by dlpack
https://data.dgl.ai/wheels-test/dgl_cu102-0.9a220516-cp37-cp37m-manylinux1_x86_64.whl
dgl在0.7.2版本中修复了这个bug。
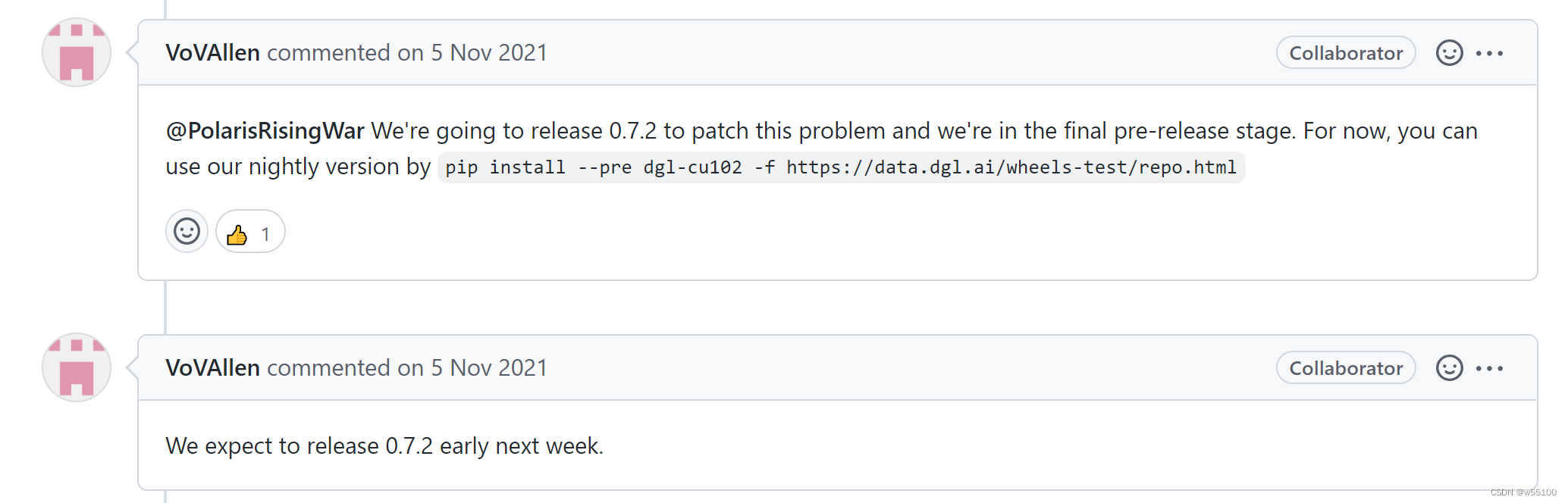
只要安装比0.7.2更高版本的dgl即可。
这里需要吐槽的是,dgl的高版本包都带上了日期。
这里看全部的包
https://data.dgl.ai/wheels-test/repo.html
我升级了一下dgl就好了
pip install https://data.dgl.ai/wheels-test/dgl_cu102-0.9a220516-cp37-cp37m-manylinux1_x86_64.whl














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









