







 本文提出一种结合用户偏好和视觉信息的个性化图片标签推荐方法。利用深度学习模型CNN-PerMLP提取图片特征,并通过个性化全连接层融合用户信息,有效提升了推荐标签的相关性和个性化水平。
本文提出一种结合用户偏好和视觉信息的个性化图片标签推荐方法。利用深度学习模型CNN-PerMLP提取图片特征,并通过个性化全连接层融合用户信息,有效提升了推荐标签的相关性和个性化水平。
感想
1 介绍
用户随意指定标签,用于支持用户组织或查找社交媒体的内容。可是,许多分享的内容有很少或者没有标签的,这是由于打标签的任务是非常耗费时机的。例如,2004年2月到2007年6月,Flickr上大约60%上传的照片有1到3个标签,大约20%的照片是没有标签的。为了鼓励用户标注他们的资源,标签系统用于使得打标签的任务变得方便。这些系统可以是个性化的系统,根据用户的偏好或省略用户兴趣的非个性化偏好(non-personalized ones)来推荐不同的标签,因为标签代表用户对其资源的观点,一个用户的推荐标签列表是一个包含“favorite””关键字的个性化列表。这个个性化模型可以给予用户,项和标签的关系,或者标签信息之间的关系(correlation information of tags)。
个性化方法对没有历史信息的新图片是无效的。正如Sigurbjornsson和Van Zwol提到的,人们通常选择跟内容和环境相关的词语去标注图片,例如地点,时间等。视觉信息可以被用于个性化推荐模型,用以增强预测的质量。基于个性化内容感知的推荐的推荐标签表达了个性和和内容感知的特点,如下图:
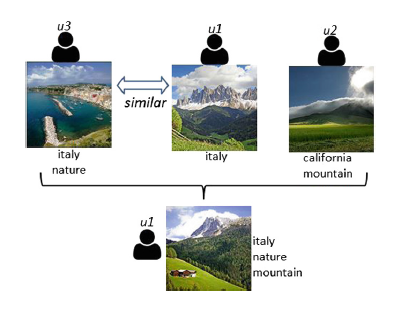
U1的推荐标签包含他喜爱的单词italy,和图片内容相关的单词mountain,来自u3的单词nature,u3和u1相似。
在这个工作中,我们用了深度学习的方法来解决一个个性化图片标签推荐问题。对于一个个性化问题,深度学习模型中的特征得包含一个用户和相关图片的信息。我们提出了一个新的添加用户信息到CNN模型的方式。
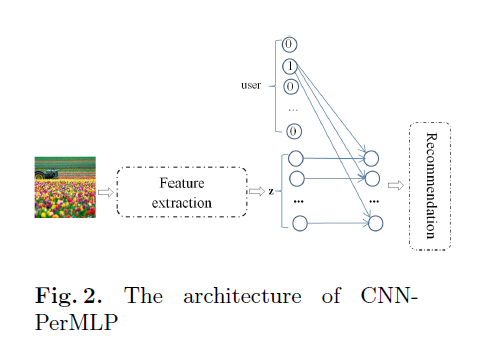
一个新的层捕捉用户的交互,视觉特征在CNN图像特征提取器和多层感知机上扮演者桥梁的作用,如下图:
另外,我们以不同的方式采用了一个贝叶斯个性化排序优化(Bayesian PersonalizedRanking optimization)用于这个模型中,即NUSWIDE和Flickr-PTR,我们提出的模型超过了最新的个性化推荐模型,因为个性化标签推荐模型完全依靠标签的历史,达到了至少4个百分点。实验也表明,有监督特征增加了预测的质量,至少相比低级别的特征提高了至少2个百分点。
2 提出的模型
2.1 问题定式化
A=(au,i,t)∈R^(|U|x|I|x|T|),
观察的标签集合定义为
S={(u,i,t)|a_(u,i,t)∈A∩a_(u,i,t)=1}
相关标签集合的用户-图像元组(u,i)用
T_(u,i)={t∈T|(u,i,t)∈S}
所有的观察的帖子(posts)用Ps表示
P_S={(u,i)|∃t∈T,(u,i,t)∈S}
另外,所有的RGB方形图片的结合用R表示,第i张图片Ri的视觉特征是一个向量zi∈R^m,在这篇文章中,我们把图片截成Q个片段,这是为了增强提取的特征的值,因此我们定义图片集合
R={R_(i,q)∈R^dxdx3∩i∈I∩q∈Q}
推荐模型的得分函数是计算给定post p_(u,i)的标签的分数,这被用来进行排序标签。在给定post下,标签的得分表示为:
y ̂(u,i,t):UxIxT→R
如果y ̂u,i,ta的分数比y ̂u,i,tb大,标签ta就和p_(u,i)更相关。
标签推荐模型提供标签的top-K列表Tu,i,这个列表按照pu,i得分的倒序排列。
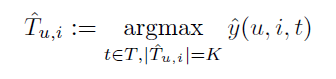
2.2 个性化内容感知标签推荐(PersonalizedContent-Aware Tag Recommendation)
模型叫做CNN-PerMLP,其结构是基于给定图片的用户和视觉特征的关系,如上图2.把图片i的片段q送入CNN特征提取器来获得视觉特征。为了使视觉特征个性化,个性化全连接层是从下面的提取器获得的。这层捕获用户和每个视觉特征的交互,产生post pu,i的隐式特征。
神经网络作为一个预测器,用来计算相关标签的可能性。网络用用户-图像特征作为输入,输出用来作为推荐标签的排序。
在这篇论文中,我们把图片分成一些片段,标签的最终得分是不同片段的平均得分。如果对于给定post pu,i和一个片段q的标签得分用如下表示:
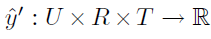
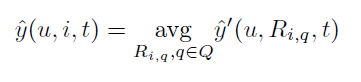
CNN
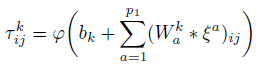

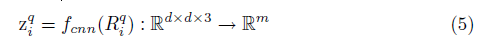
个性化全连接层
CNN提取的特征仅仅包含图片i的信息,为了得到一张图片的个性化视觉特征,需要加入用户的信息或者结合这些特征。对于这个原因,在特征层和预测器之间的加了一层,用以产生用户感知特征,这些特征作为预测器的输入。如果模型仅仅使用用户的id作为个性化信息,用户的特征u用一个系数的向量表示Ku={0,1}|U|。视觉特征向量z_i^q和稀疏向量K_u作为这一层的输入。这层可以捕捉用户和每个视觉特征的交互信息。如果这层的输出使用ψ∈R^m表示,则:
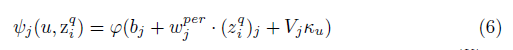
多层感知机作为预测器
为了计算标签的分数,我们使用了多层感知机作为预测器,它的输入是个性化全连接层ψ的输出。网络的输出是这个post (u,i)标签的相关分数,图片i的片段q.因为这个网络有一个隐藏层,我们用如下的神经网络分数函数(neural network score function)表示: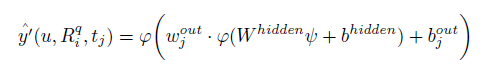
2.3 优化

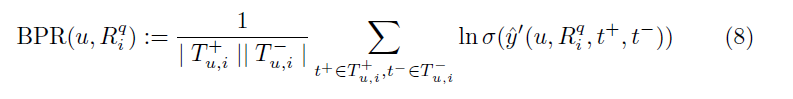
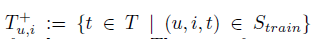
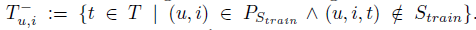
函数σ(x)为
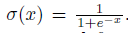
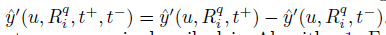
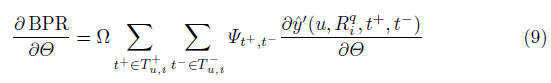
其中
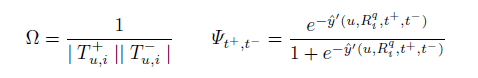
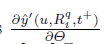
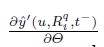
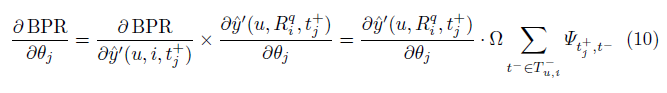
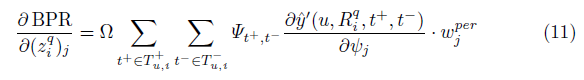
3评估
在评估中,我们用实验来处理有监督视觉特征和个性化因素在标签推荐过程上的影响。3.1 数据集
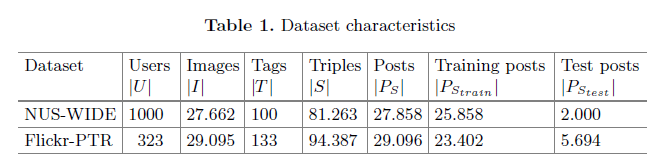
保留为图片标注的100个最流行的标签,从1000个用户中进行采样,根据用户和标签把他们分为10个核心数据集,其中用户或者标签至少出现在10个posts上,移除了用户为超过50%的图片打的标签,这是为了避免用户用对所有的标签都打相同的关键字。相似的,我们把Flickr-PTR的所有标签映射到WordNet上,细化数据集已得到40个核心用户,400个核心标签数据集。这是通过从500个用户中采样和移除用户给超过50%的图片指派的标签实现的。
我们对用户使用leave-one-post-out去分割数据集。对于每个用户,随机选择Flickr-PTR posts和2 NUS-WIDE posts的20%来当测试集,这个子数据集可以用表1来描述。
从Flickr API爬取的图片是从纵横比为75*75的NUS-WIDE或纵横比为50*50的Flickr-PTR上截取3个片段,从三个位置左上,中心,右下,这用于训练和预测的输入片段。
3.2 实验装置
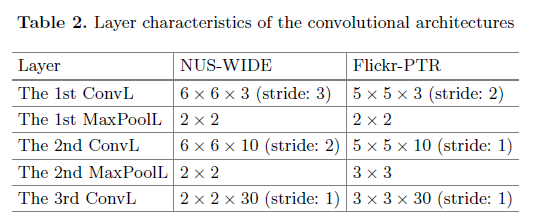
用于两个数据集的结构包含3个卷积层(ConvL),两个最大池化层(MaxPoolL)。在这些结构中国,ConvL有相同的核,第一层有10个核,第二层有30个核,第三层有128个核。因为图片的大小不同,卷积核和池化块的维数是不同的,如图2:
预测器的隐藏层的维数为128,用rectifier函数max(0,x)作为激励函数。这篇文章的评估矩阵是:
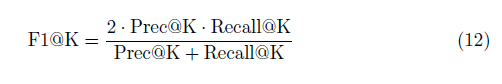
其中
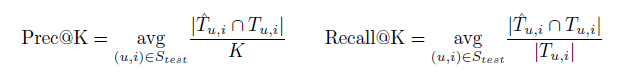
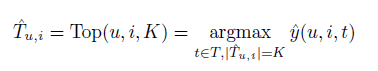
网格搜索策略被用于寻找最佳学习率α,其中ConvLs层的学习率是{0.001, 0.0001, 0.00001},全连接层的学习率是{0.01, 0.0001, 0.0001},最佳的L2正则λ的范围为λ∈{0.0,0.0001,0.00001},momentum的值μ固定为0.9。 64维的颜色直方图(CH)和225维块级别的颜色矩(CM55),这是NUS-WIDE作者提供的,Flickr-PTR图片的64维颜色直方图(CH)用来做比较实验。
CNN-PerMLP和下面的个性化标签推荐方法作比较,这些标签推荐方法仅仅使用用户的偏好信息,不考虑视觉信息:Pairwise Interaction Tensor Factorization(PITF),Factorization Machine (FM),most popular tags by users(MP-u)。
我们也比较了非个性化模型,包括most popular tags (MP),the multilabel neural networks (BP-MLLs),BP-MLLs用低级别的视觉特征(CH-BPMLL, CM55-BPMLL)作为输入,CNNs用来做图片标注,优化成对排序损失来学习参数(optimizes the pairwise ranking loss to learn
the parameters)。就在ROC曲线下优化损失而言,复现的CNN和Gong等人的模型很像。
为了作比较,CH-PerMLP 和 CM55-PerMLP使用低级别的特征,我们使用Tagrec framework去学习MP和MP-u,使用Mulan llibrary去学习CH-BPMLL 和 CM55-BPMLL。
4.3 结果
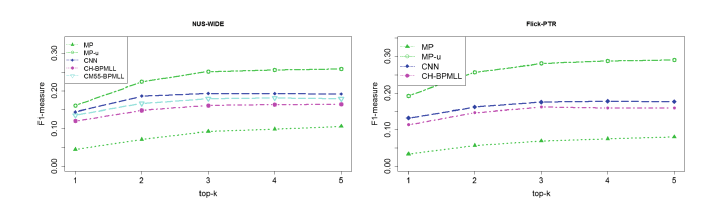
如上图,给个性化模型不能捕捉用户的交互,仅仅推荐与内容相关的标签。模型的预测质量很低,可是,用了CNN有监督特征能捕获更多的信息,性能提高了2%。
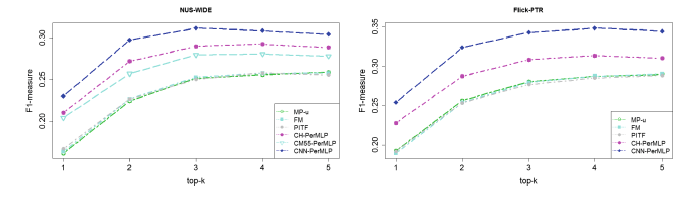
视觉特征提高了预测质量,在测试中,我们有很多新图片,和这些图片相关的权重没有进行学习。因此,个性化内容忽略的模型仅依赖于用户,例如FM和PITF.他们的结果在预测MP-u上的差别明显,个性化内容感知模型在这个情况下的效果更好,视觉特征大约提高了4%的预测质量。有监督特征也证明他们在推荐质量上的优势,使用学到的视觉特征,效果提高了大约2%到3%。

表3显示,我们的模型与MP-u相比,既可以预测个性化标签又可以预测内容标签,MP-u纯粹预测个性化标签和CNN推荐的内容标签。结果,CNN-PerMLP推荐了和图片相关的标签。例如,在第一幅图片上,推荐器会推进个性化标签,例如“flowers”,“ flower”,“ orange”,内容标签如“white”或“red”。
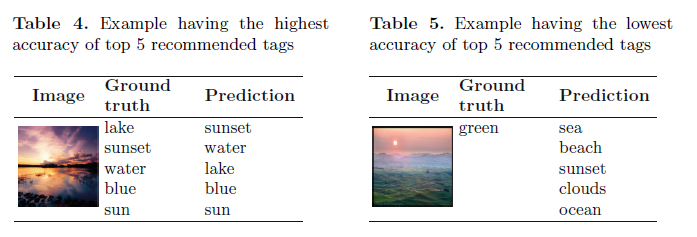
如表4和表5,在这种情况下,CNN-PerMLP工作得很好,人们使用他们频繁的标签或者和图片内容相关的标签去标注一个新图片。可是,如果模型为新图片指派和内容不相关的标签,模型的预测质量很差。
4 参考文献
[1]. Hanh T. H. Nguyen, Martin Wistuba, Josif Grabocka, Lucas Rêgo Drumond, Lars Schmidt-Thieme: Personalized Deep Learning for Tag Recommendation. PAKDD (1) 2017: 186-197[2]. Leandro Balby Marinho, Andreas Hotho, Robert Jäschke, Alexandros Nanopoulos, Steffen Rendle, Lars Schmidt-Thieme, Gerd Stumme, Panagiotis Symeonidis:Recommender Systems for Social Tagging Systems. Springer Briefs in Electrical and Computer Engineering,
Springer 2012, ISBN 978-1-4614-1893-1, pp. i-ix, 1-111
[3]. 交叉验证(Cross Validation)方法思想简介. http://blog.csdn.net/chl033/article/details/4671750


















 2025
2025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











