感想
篇幅有限,这是接着上面的续篇,let's continue
4.2 基于Autoencoder的推荐系统
现存的两种把autoencoder运用到推荐系统上的方法为:(1)使用autoencoder在bottleneck层学习低维特征表达;(2)直接在重构层填充评分矩阵的空白。
4.2.1 仅仅依赖于Autoencoder的推荐
AutoRec
AutoRec把用户部分向量r^((u))或者物品部分向量r^((i))作为输入,旨在在输出层重构它们。明显的,它有两个变体:基于物品的AtuoRec(Item-based AutoRec, I-AutoRec)和基于用户的AutoRec(User-based AutoRec, U-AutoRec)。对应两种类型的输入。这里,我们只介绍I-AutoRec, U-AutoRec可以很容易的推导出来。
上图为I-AutoRec的结构。给定输入r^((i)),重构输出为:
其中f和g是激励函数,参数θ={W,V,μ,b}. I-AutoRec的目标函数定义为:
其中,

表示的仅仅考虑观察的评级,目标函数可以通过Resilient Propagation(收敛得更快,产生较好的结果)或者L-BFGS(Limited-memory Broyden FletcherGoldfarb Shanno algorithm).)进行优化。Auto在部署前有四个值得注意的点:
1.
I-AutoRec比U-AutoRec表现得更好,这可能是由于用户部分观测向量的偏差过大造成的。
2.
不同激励函数的结合会对结果影响很大。
3.
增加隐藏单元的大小会提升结果,因为拓展隐藏层的维度会给予AutoRec对输入特征(the characteristics of the input)更多的建模能力。
4.
增加更多的层来构造更深的网络会有效的提升性能。
Collaborative Filtering Neural network(CFN)
它是AutoRec的一个拓展,有两个优点:(1)它利用了降噪的技术,使得CFN更加的鲁棒;(2)它融合了边信息来缓解稀疏性和冷启动的影响,例如用户画像和物品描述。CFN的输入是部分观察向量,它有两个变体:I-CFN和U-CFN,分别把r^((i))和r^((u))作为输入。
作者用了三种corruption的方法来corrupt输入:Gaussian noise,masking Noise和salt-and-pepper noise。为了处理丢失的元素(它们的值为0),我们强加了masking noise,作为在CFN中的强正则项。
让r^((i))表示腐败的输入(the corrupted input),训练损失的定义如下:
在这个等式中,

表示观察元素的索引,
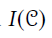
表示corrupted元素的索引。α和β是平衡这两个部件影响的超参数,
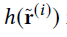
代表对corrupted输入的重构。
进一步拓展的CFN也融合了边信息,不同于以前把边信息融入第一层,CFN在每一层都注入了边信息。于是,重构输入变为:
其中,si是边信息,{r ̃^((i) ),s_i}表示r ̃^((i) )和s_i的连接操作,混合边信息来改进预测精度,加速训练过程,使得模型更加鲁棒。
Autoencoder-based Collaborative Filtering(ACF)
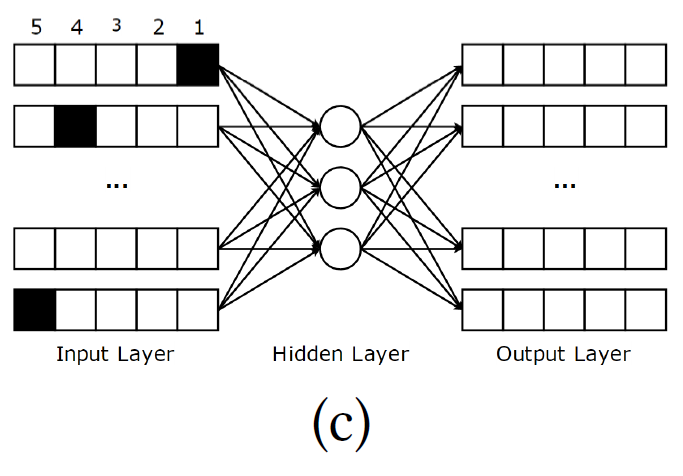
据我们所知,ACF是第一个基于Autoencoder的协同推荐模型。和以前使用部分观察向量不同,它把向量分解为整数评级。例如,如果评级分数是整数,在[1,5]的范围内,每个r^((i))被分为5部分向量。
上图是一个ACF的例子,评级范围是[1,5],阴影的条目表示用户已经对电影进行了相应的评级,例如用户给物品i评级为1,给物品2评级为4。和AutoRec以及CFN相似,ACF的代价函数旨在减少均方平方损失,ACF的评级预测的计算是对每个条目的五个向量的求和,在这个样例中,评级的最大值为5。它使用RBM去预训练参数以避免局部最优值,堆叠一些autoencoder在一起也可以稍稍提高精度。可是,ACF有两个缺点:(1)它不能解决非整数评级;(2)部分观察向量的分解会增加输入数据的稀疏性,导致精度的降低。
Collaborative Denoising Auto-Encoder(CDAE)
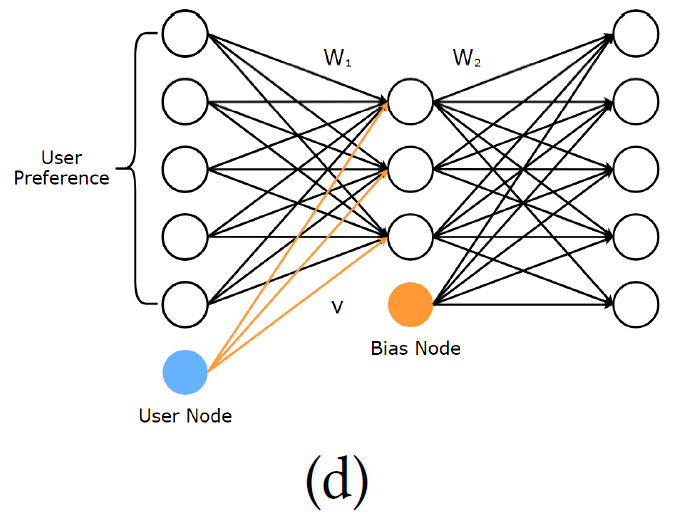
回顾的这三个模型早期主要是为评级预测而设计的,CDAE主要用于排序预测(ranking prediction)。CDAE的输入是用户部分观察的隐式反馈r_pref^((u)),如果用户喜欢电影,输入的值为1,否则为0。它也可以被认为是一个偏好向量,用来把用户的兴趣映射到物品上。
上图表示的是CDAE的结构,CDAE的输入用高斯噪声进行了处理,corrupted的输入r ̃_pref^((u))遵循一个条件高斯分布
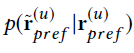
重构输入的定义为:
其中,V_u∈R^K表示上述用户结点的权重矩阵,每个用户的权重矩阵都是唯一的,并且极大地提高的性能。参数是通过最小化重构误差获得的。
其中,损失函数可以是平方损失或者logistic损失,采用l2-norm来正则化权重项和偏置项,而没有采用Frobenius范数.
这里解释一下Frobenius norm:向量v的欧几里得范数或者说l2范数为,v有n个元素,
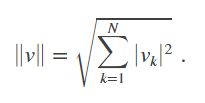
一个m*n(m>2,n>2)的矩阵的x的Frobenius Norm定义为,
CDAE使用SGD初始的更新所有反馈的参数。可是,作者认为这对将所有的评级考虑在内的真实世界应用是不实用的,因此它们采用一个负采样技术从负集合(用户没有进行交互的物品)中采样一小部分数据集,这减少了时间复杂度,而且评级质量没有退化。
4.2.2 把传统的推荐系统和Autoencoder整合
紧耦合模型(Tightly coupled model)同时学习autoencoder和推荐模型的参数,这使得推荐模型为autoencoder提供指导,以学习更多的语义特征。松耦合模型分两步来做的:通过autoencoder来学习突出的特征,然后把这些特征用于推荐系统。这两种形式都有其优点和缺点。例如,紧耦合模型需要精心的设计和优化,以避免局部最优,但是推荐和特征学习可以同时进行;松耦合方法可以很容易地拓展现有的先进的模型(advanced models),但是需要更多的训练步。
紧耦合模型
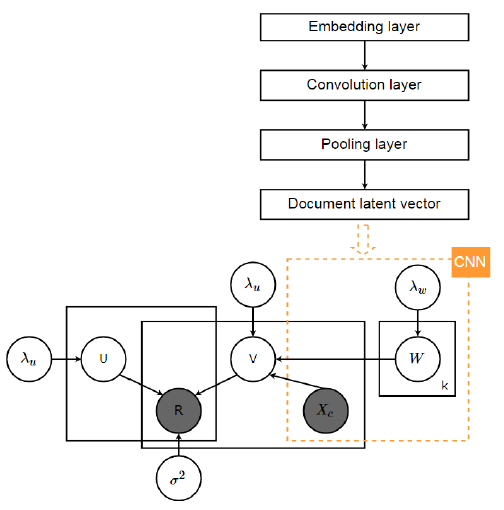
协同深度学习(Collaborative Deep Learning, CDL)
CDL是一个层级的贝叶斯模型,它把SDAE(stacked denoising autoencoder)融入到了概率矩阵分解中;为了无缝的结合深度学习和推荐模型,作者提出了一个一般的贝叶斯深度学习框架,框架由两个紧铰链组件组成:感知组件(深度神经网络)和特定任务组件。特别地,CDL的感知组件是一个序数的SDAE的概率解释,PMF扮演的是特定任务的组件。这种紧耦合可是使CDL平衡边信息和评级的影响。CDL的生成过程如下:
其中,Wl为l层的权重矩阵,bl为l层的偏置矩阵,Xl代表第l层。λ_w,λ_s,λ_n,λ_v,λ_u是超参数,C_ui是一个置信参数,用来衡量观察的置信度。
上图的红色方框为CDL的图模型。作者利用EM风格的算法来学习参数,在每一次迭代中,首先更新U和V,随后通过固定U和V来更新W和b.作者也引入了一个基于采样的算法来避免局部最优。
在CDL之前,Wang等人提出了一个相似的模型用于标签推荐(tag recommendation),relational stacked denoising autoencoders(RSDAE)。RSDAE和CDL的区别为RSDAE用一个关系信息矩阵代替了PMF.CDL的另一个拓展是collaborative variational autoencoder(CVAE),它用variational autoencoder来替换CDL的深度神经组件。CVAE学习内容概率因子变量(probabilistic latent variables),用于表示内容信息(content information),这可以很容易的融合多媒体数据源。
Collaborative Deep Ranking(CDR)
CDR是一个特别为top-n推荐的成对的框架,CDL是一个point-wise模型,最初是为评分预测而提出来的。可是,研究证明成对的模型对评分列表产生更合适。实验结果也证明CDR在评分预测上超过了CDL的表现。

上图的右边为CDR的结构,CDR的第一个和第二个生成步骤和CDL一样,第三步和第四步如下:
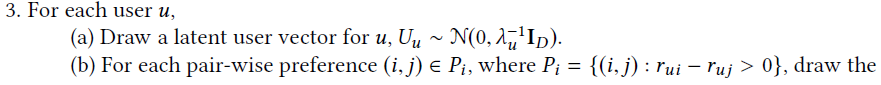
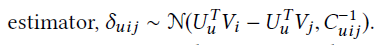
其中δ_uij=rui-ruj,代表用户对物品i和j的成对的关系,C_uij^(-1)是一个置信度的值,它表示用户u对物品i比对物品j的偏好程度,优化过程和CDL一样。
Deep Collaborative Filtering Framework
它是一个融合深度学习方法和协同过滤模型的一般框架,有了这个框架,我们就很容易利用深度学习技术来辅助协同推荐。正式地,深度协同过滤框架定义如下:
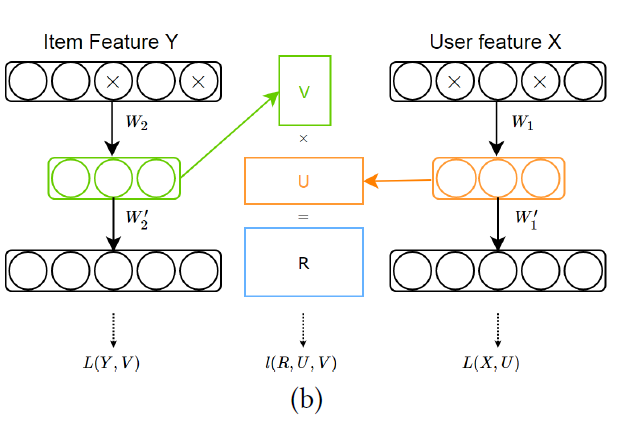
其中,β,ℽ和δ是权衡参数,用来均衡这三个部分的影响,X和Y是边信息,l(.)是协同过滤的损失,L(X,U)和L(Y,V)扮演着铰链的角色,连接深度学习和协同过滤模型,以及连接边信息和隐式因子。这个框架的顶部,作者提出了基于协同过滤模型的marginalized denoising autoencoder(mDA-CF)。和CDL相比,mDA-CF是一个autoencoder计算高效的变体。它通过边缘化损坏的输入,以节省了寻找充足的损坏输入版本(searching sufficient corrupted version of input)的代价,这使得mDA-CF比CDL可拓展性更强。另外,mDA-CF嵌入了用户和物品的内容信息,而CDL只考虑物品特征的影响。
框架图如下:
松耦合模型
AutoSVD++利用的是contractive autoencoder去学习物品的特征表示,之后把特征整合到经典的推荐模型,SVD++。提出的模型有如下的优点:(1)和其它autoencoder变体相比,contractive autoencoder能捕获无穷小的输入变化;(2)它对隐式反馈进行建模,以进一步提高精度;(3)有一个高效的训练算法,可以减少训练时间。
HRCD是一个基于autoencoder和timeSVD++的混合协同模型,这是一个时间感知模型,它使用SDAE学习从原始特征中学习物品表示,目的是解决冷启动问题。可是,基于相似度的冷物品的推荐就算代价很高。
4.3 基于卷积神经网络的推荐系统
卷积神经网络能强有力的处理视觉,文本和声音信息。大多数基于CNN的推荐系统都是利用CNN做特征提取。
4.3.1 仅依赖于CNN做推荐
Attention based CNN.
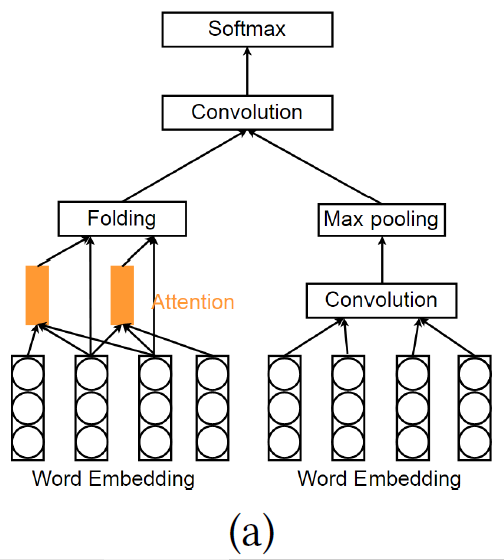
Gong等人提出了一个基于注意力机制的CNN系统做微博的hashtag推荐,它把hashtag推荐看作是一个多类别分类问题。提出的模型由全局通道(global channel)和局部注意力通道(local attention channel)组成。global channel由卷积滤波器和最大池化层组成。所有的词都编码为global channel的输入,local attention channel有一个attention层,窗口大小为h,阈值为η,用来选择有信息的单词(在这个工作中被称为触发词)。因此,只有触发词在下面的层中起作用。这里,我们讲一下局部注意力channel的细节。令w_(i:i+h)表示单词wi,…wi+h的连接,窗口的中间的单词(w_((2i+h-1)/2))计算:
其中,W为权重矩阵,g(.)为非线性激励。只有得分超过η的单词会保留下来。
上图为attention-based CNN模型。左边的部分代表局部注意力channel,右边的部分代表CNN全局channel。在接下来的工作中,Seo等人利用两个神经网络来学习用户和物品文本评论的特征表示,在最后一层用点积预测得分。
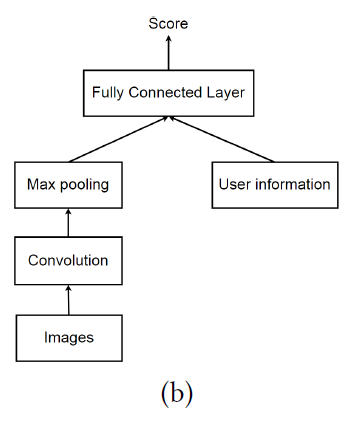
Personalized CNN Tag Recommendation
Nguyen提出了基于CNN的个性化标签推荐系统。
结构如上图,它利用卷积核池化层去得到图片片段的视觉特征,注入用户信息来产生个性化推荐。为了优化网络,采用了Bayesian Personalized Ranking(BPR)算法最大化相关和不相关的标签(tags)。
4.3.2 把CNN融入到传统的推荐系统中
和AE一样,CNN可以融入到传统模型中。可是,现有的集成类型没有像建立在AE上的类型那样丰富,前面基于AE的回顾应该向CNN拓展。
紧耦合模型
Deep Cooperative Neural Network (DeepCoNN)
DeepCoNN采用了两个并行的卷积神经网络,来对用户行为和物品属性进行建模,这些来自评论文本。在最后一层,运用因子分解机(the factorization machine)来捕捉评分预测的交互。利用评论文本丰富的语义表示,缓解了稀疏性问题,增强了模型的可解释性。它利用word embedding技术,把评论文本映射到一个低维的语义空间,也保留了单词序列的信息。抽取的评论表示通过一个卷积层,一个最大池化层,一个连续的全连接层。用户网络的输出x_u和物品网络的输出x_i最终连接在一起作为因子分
解机的输入。
ConvMF. ConvMF结合了CNN和PMF模型,结合的方式和CDL相似。CDL使用autoencoder学习物品特征表示,而ConvMF利用CNN学习高阶物品表示。ConvMF和CDL相比,其优点为CNN可以捕获更精确的物品上下文信息,这些是通过word embedding和卷积核实现的。
上图为ConvMF的图结构,通过替换CDL中的 和CNN输出cnn(W,X_i),
和CNN输出cnn(W,X_i),
其中W为CNN的参数,我们很容易得出这个概率模型的公式。ConvMF的目标函数定义为
其中,λ_u,λ_v,λ_w是超参数。U和V通过坐标下降法学到,CNN的参数是通过固定U和V得到的。
这里解释一下坐标下降法:(1)坐标下降法在每次迭代中在当前点处沿一个坐标方向进行一维搜索 ,固定其他的坐标方向,找到一个函数的局部极小值。(2)坐标下降优化方法是一种非梯度优化算法。在整个过程中依次循环使用不同的坐标方向进行迭代,一个周期的一维搜索迭代过程相当于一个梯度迭代。(3)gradient descent 方法是利用目标函数的导数(梯度)来确定搜索方向的,该梯度方向可能不与任何坐标轴平行。而coordinate descent方法是利用当前坐标方向进行搜索,不需要求目标函数的导数,只按照某一坐标方向进行搜索最小值。
详情请看我的参考文献。
松耦合模型
根据CNN处理的特征类型的不同,我们把松耦合模型分为以下的三个类别。
CNN for Image Feature Extraction
Wang等人调研了视觉特征对POI(Point-of-Interest)推荐的影响,提出了一个视觉内容增强的POI推荐系统(POI recommender system,VPOI)。VPOI采用了CNN去提取图片特征。推荐模型建立在PMF之上,利用(1)视觉内容和隐式用户因子的交互;(2)视觉内容和隐式位置因子的交互。Chu等人利用了餐厅推荐上的视觉信息(例如食物的图片和餐厅的陈设)的有效性,通过CNN提取视觉信息,加上文本表示,作为MF,BPRMF和FM的输入,用来测试他们的效果,结果表明视觉信息在一定程度上提升了性能,但是不明显。He等人设计了一个视觉贝叶斯个性化排序(visual Bayesian personalized ranking)算法,把视觉特征融入到矩阵分解中;He等人又对VBPR进行了拓展,探索用户的时尚感知,以及当用户考虑选择物品的时候,视觉因素的进化。
CNN for Audio Feature Extraction
Van等人提出了使用CNN来从音乐信号中提取特征。卷积核和池化层允许在不同时间尺度上操作。这个基于内容的模型可以缓解音乐推荐中的冷启动问题。让y^'表示CNN的输出,y表示从权重矩阵分解学到的物品隐式因子,CNN的目标是最小化y和y^'的平方误差。
CNN for Text Feature Extraction
Shen等人建立了一个e-learning资源推荐模型,它使用CNN从学习资源的文本信息中提取物品特征,例如学习材料的介绍和内容,然后做推荐。








 本文探讨了深度学习技术在推荐系统中的应用,包括基于Autoencoder和卷积神经网络的方法。详细介绍了AutoRec、CFN、CDAE等模型如何改善推荐准确性,以及CNN在处理视觉、文本和声音信息中的优势。
本文探讨了深度学习技术在推荐系统中的应用,包括基于Autoencoder和卷积神经网络的方法。详细介绍了AutoRec、CFN、CDAE等模型如何改善推荐准确性,以及CNN在处理视觉、文本和声音信息中的优势。

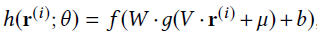


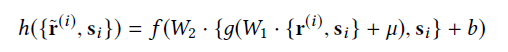

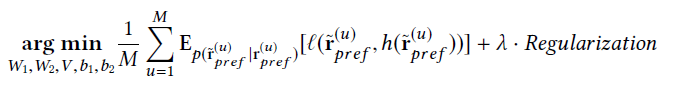
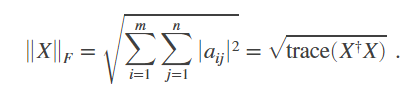


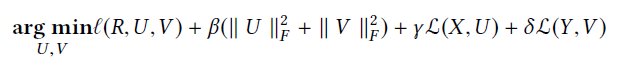
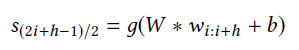
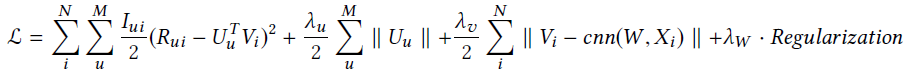



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











