







背景描述
接上一节的内容:
StableDiffusion-04 炼丹篇
请你确保:
- 已按照前几节完成了配置
- 已按照前几节正常运行
- 已按照前几节正常出图
- 上一节结尾:已经完成了对图片的打标签操作,接下来我们就要进行
炼丹了!
上节说到:
从小就非常喜欢小樱!从小樱的动画到动漫书我都看了个遍,包括C妈几年前更新了(哇这么久了都)Clear Card。
直到最近C妈终于更新完了 Clear Card 的漫画,听说好像新的视频在筹备了,我好期待!!!



炼丹配置
按照我们上节的情况,我们打开:http://server:6006页面,请图文对比着一起配置。
由于我们是学习,所以按照图中可以跑起来是第一要义,不用调整太多了。
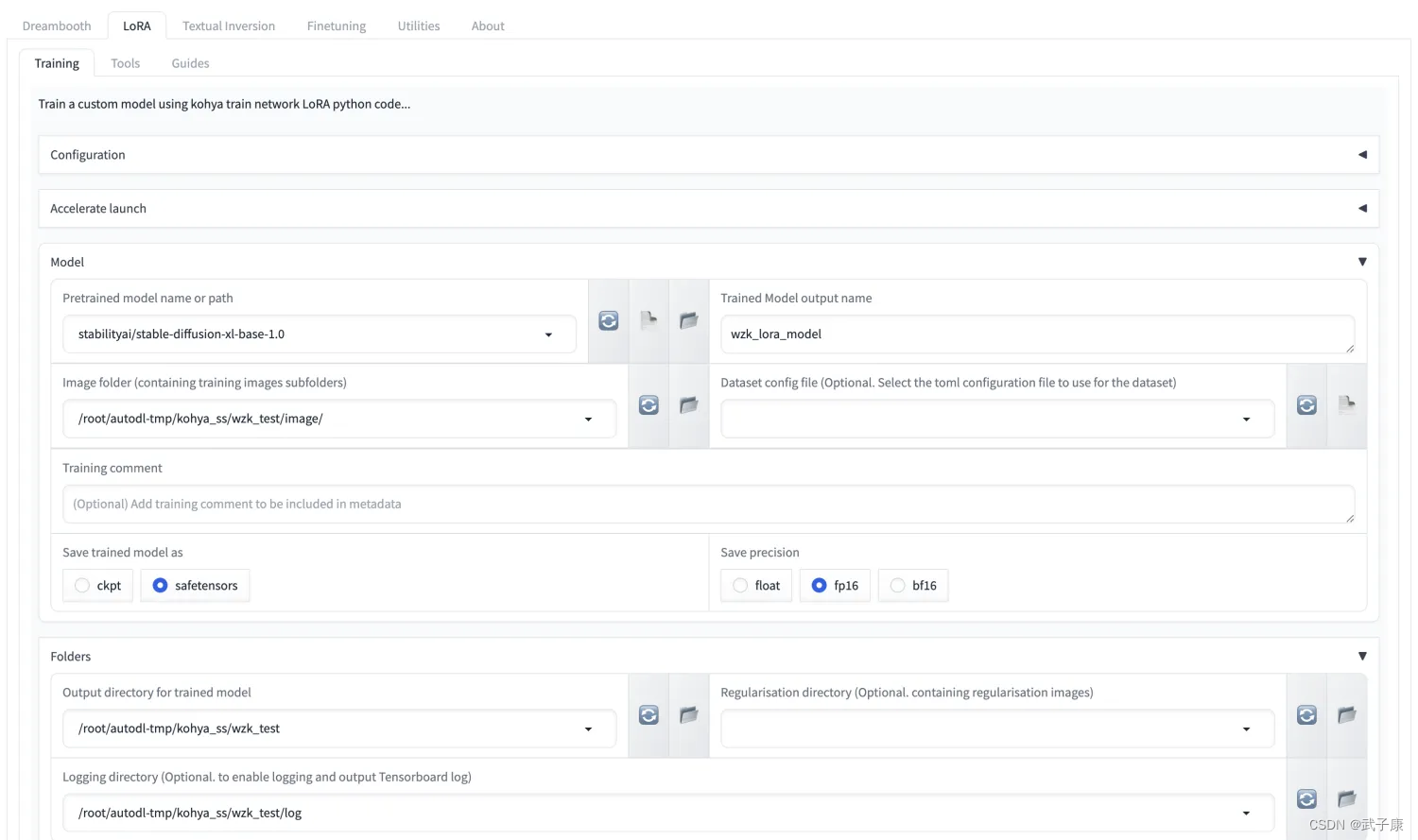
选择如下标签并配置
● Model-Pretrained model name or path: 基础模型的位置,如果没有将下载
● Model-Trained Model output name: 输出的模型名称
● Model-Image folder: 图片的上一级目录,(不要写到30_sakura这一级)
● Folders-Output directory for trained model: 训练完保存的目录
● Folders-Logging directory:日志的文件夹
详情如下图:
- Paramters-基本配置默认即可(暂时先跑通)
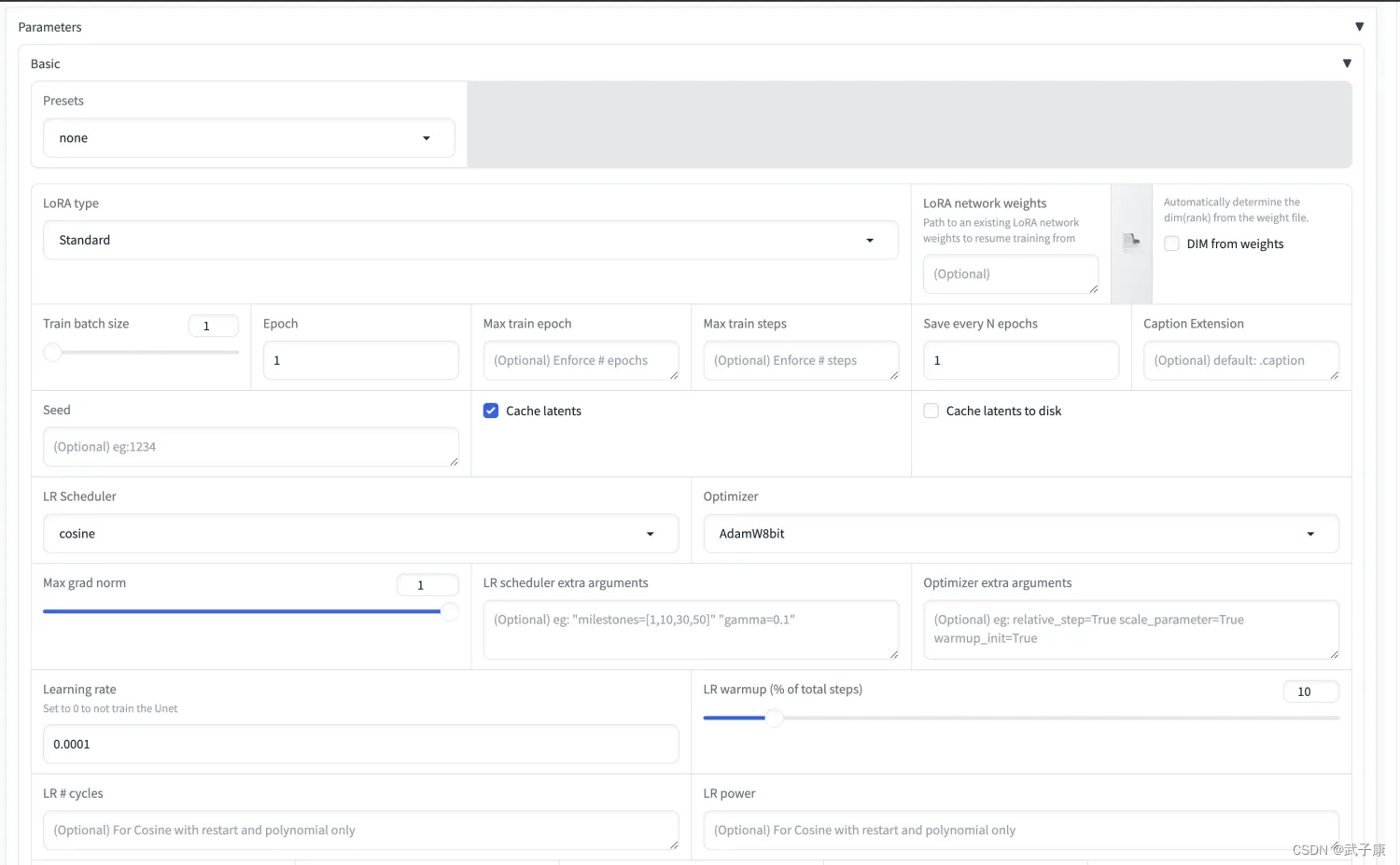
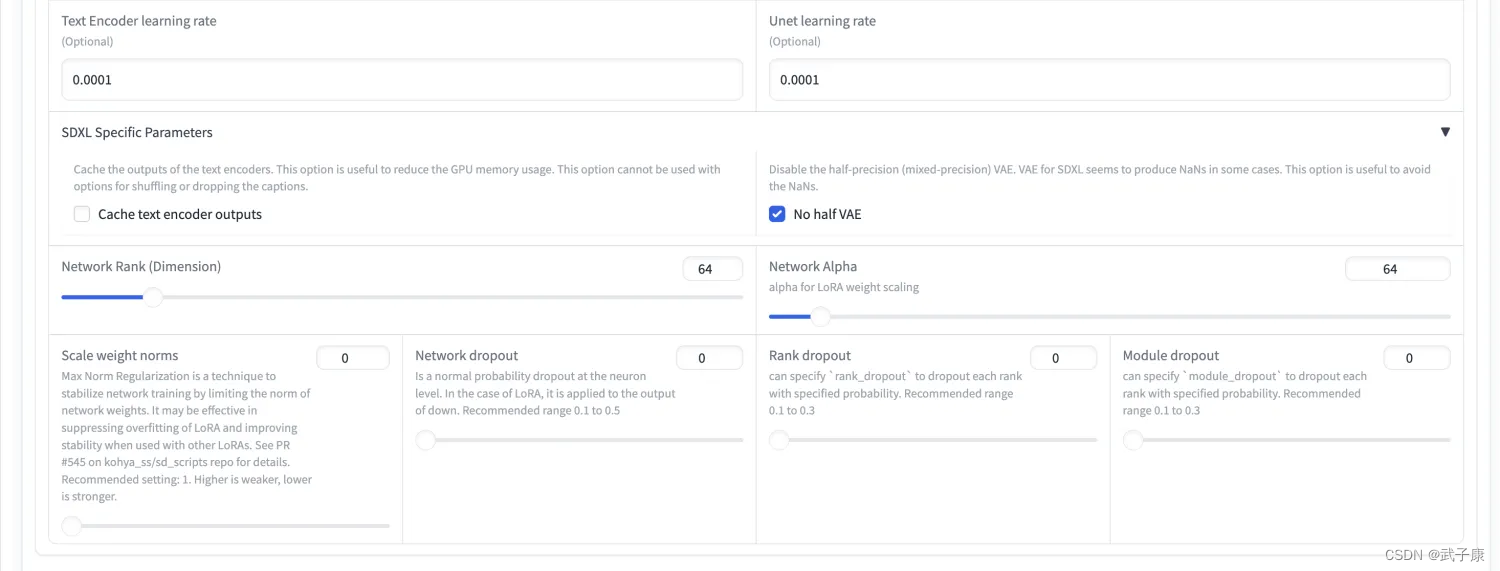
● Paramters-Text Encoder learning rate: 网上推荐 5e-5
● Paramters-No half VAE
● Paramters-Network Rank: 64
● Paramters-Network Alpha: 64
开始训练
完成上述的配置之后,我们点击按钮开始训练

页面上是不会有什么变化的,我们可以看后台的日志。过程中如果你是第一次运行,那你需要下载一部分模型。
可以看到下图,正在进行一些别的模型下载。
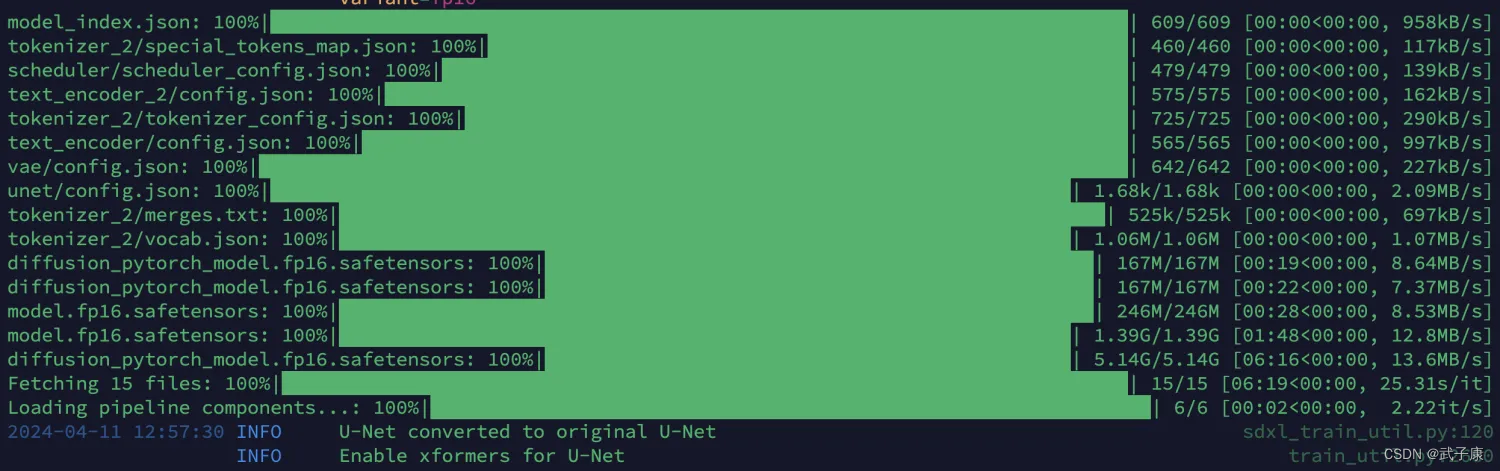
如果你加载模型顺利的话,你会看到如下的训练过程:
模型已经正常加载,一共19张图片 ,epoch=1(默认配置的),一共570步训练,会显示着实时进度和预估完成的时间。
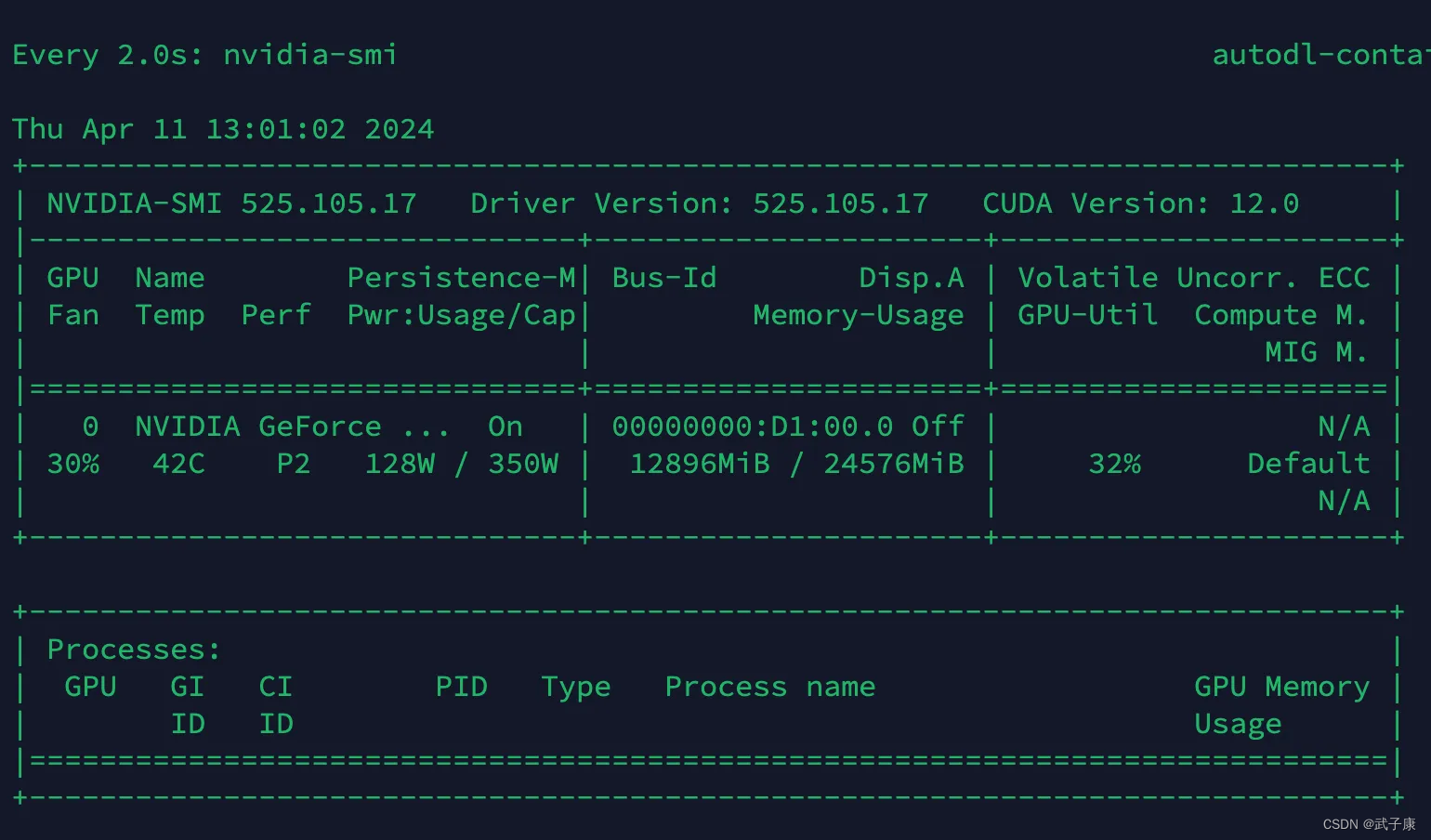
此时我们可以观察显卡的状态如下:
大约 13GB 的显存占用,所以底显卡跑的话,可能会遇到 OOM 的问题。
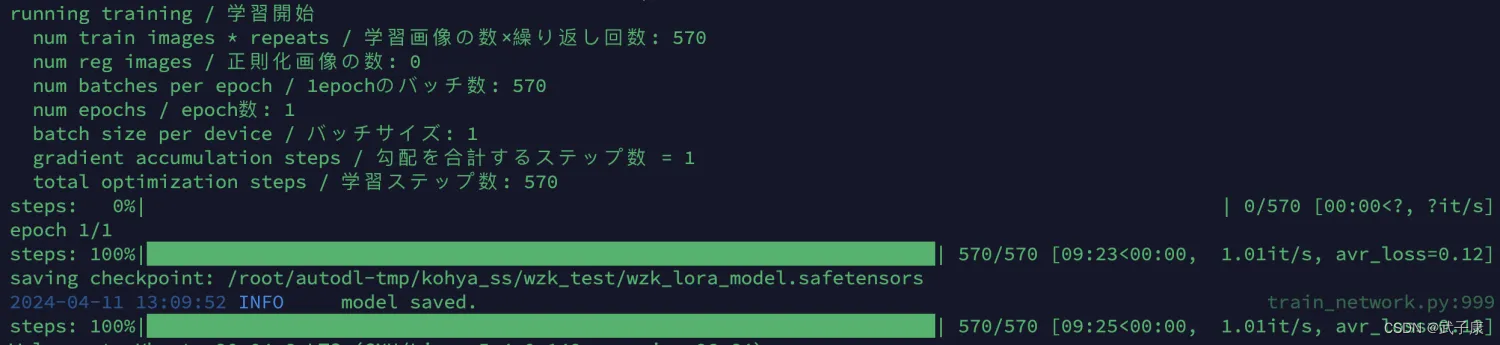
训练完毕
在经过漫长的等待之后··· 如果出现了如下图片的内容,那么恭喜你!已经成功练出了自己的第一炉丹!
上一节我们配置的保存目录是:
/root/autodl-tmp/kohya_ss/wzk_test
我的目录如下,你可以参考:

这个叫: wzk_lora_model.safetensors 便是我们的LoRA了,名字取决于你在配置中的名称。只要是.safetensors结尾即可。
测试效果
(这里随便选了一个基础模型)
无LoRA
其他图我就不放了

使用LoRA
为了更好更多的展示,这里直接把COUNT调到4,直接给大家展示4个一张的
提示词我也不放了!大家按照自己的喜欢使用即可!
多个LoRA搭配使用一下效果更佳!可以看这节内容,里边有详细的使用流程
StableDiffusion-02 LoRA上手使用实测





















 16万+
16万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









