






这里写目录标题
一、集群搭建
单机搭建hadoop之前已经在博客中写过,这里就不再做过多描述,见Hadoop安装及配置
我就以hadoop111这个主机来做主节点,并且主机上已安装并配置好hadoop及jdk
-
关闭hadoop11主机,克隆两份分别为hadoop12、hadoop13(虚拟机的名称),记住克隆的虚拟机一定要重新生成MAC地址



【注】两个网络适配器都要重新生成MAC地址

注意!!!,开启zookeeper需要时间同步

按照相同的方法再克隆一个hadoop113,完成后全部启动并登录
-
因为三台机器都一样,所以要配置IP地址、主机名hostname、hosts
hadoop111:因为克隆的是hadoop111,所以不用修改它的IP地址了
(1) 查看hostname是否改为hadoop111,输入:vi /etc/hostname
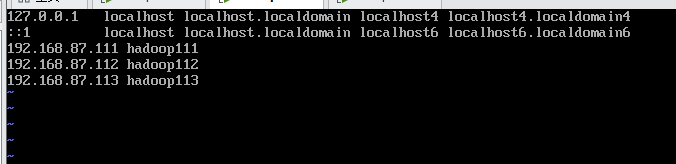
(2)修改hosts,输入:vi /etc/profile192.168.87.111 hadoop111 192.168.87.112 hadoop112 192.168.87.113 hadoop113
hadoop112
(1)修改ip地址,输入:vi /etc/sysconfig/network-scripts/ifcfg-ens33,修改ip地址
把192.168.87.111改为192.168.87.112,保存并退出,修改完后一定要重启网络
输入:systemctl restart network

(2)修改主机名,输入:hostnamectl set-hostname hadoop112,
(3)修改host,和hadoop111中修改的一样
hadoop113:按照hadoop112配置即可三个主机配置完后,就可以远程连接了
-
使用密钥通信(重要!!!)
由于hadoop111已经配过密钥,所以三台主机需要重新生成密钥每个主机都需要生成密钥
- 生成密钥,输入:
ssh-keygen -t rsa -P ""

- 输入:
cat .ssh/id_rsa.pub > .ssh/authorized_keys,>表示覆盖,>>表示追加,需要覆盖旧的密钥 - 如果三个主机都生成好了,就可以开启远程免密登录配置,输入:
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@hadoop112
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@hadoop113

这是再hadoop111中操作的,在hadoop112和hadoop113中可以按照hadoop111来操作
都设置好了之后,可以输入:ssh root@主机名来测试三个主机是否可以免密登录
二、集群安装hadoop
现在已经有三个主机,都安装好了hadoop和jdk,且配置都一样,因为是克隆主机hadoop111的,每个主机互相之间可以免密登录,如果单机版hadoop还没搭好的,可以翻看我之前写的Hadoop安装及配置
下面就开始搭建hadoop集群了,我已hadoop111为主节点,在hadoop111上配置再通过发送文件的方式把hadoop112和hadoop113的文件覆盖掉,完成了修改
- 输入:
cd /opt/hadoop/etc/hadoop,进入配置文件的目录 - 输入:
vi hdfs-site.xml,修改以下信息
<configuration>
<property>
<name>dfs.replication</name>
<!-- 把1修改成3 -->
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<!-- hadoop111改为hadoop112 -->
<value>hadoop112:50090</value>
</property>
</configuration>
- 输入:
vi slaves,把隶属节点的主机名写入
hadoop112
hadoop113
- 修改完hdfs-site.xml和slaves配置文件后就可以把这两个文件发送给hadoop112和Hadoop113,输入:
scp /opt/hadoop/etc/hadoop/hdfs-site.xml root@hadoop112:/opt/hadoop/etc/hadoop/hdfs-site.xml
scp /opt/hadoop/etc/hadoop/hdfs-site.xml root@hadoop113:/opt/hadoop/etc/hadoop/hdfs-site.xml
scp /opt/hadoop/etc/hadoop/slaves root@hadoop112:/opt/hadoop/etc/hadoop/slaves
scp /opt/hadoop/etc/hadoop/slaves root@hadoop113:/opt/hadoop/etc/hadoop/slaves - 把每个主机的/opt/hadoop/目录下的tmp文件夹删除,tmp文件夹用来保存一些格式化的一些信息,如果修改了hadoop的配置文件,那么就要把tmp文件删除,重新格式化一遍
rm -rf /opt/hadoop/tmp
【注】每个主机上的tmp都要删除 - 在主节点hadoop111上格式化,输入:
hadoop namenode -format - 启动hadoop,输入:
start-all.sh - 输入:
jps查看进程信息
三、安装zoopkeeper、hbase、hive(推荐在单机节点上装好了后再进行克隆!!!)
zookeeper、hive、hbase相关压缩包下载:
链接:https://pan.baidu.com/s/1Vz9ETO7G2yZY_4y1EPKKrQ
提取码:xear
- 把zookeeper、hive、hbase下载好的压缩包都放入hadoop111中的software文件夹中,并解压至/opt目录下,在给解压好的文件夹重命名,分别为:hive、zookpr、hbse
做好这些差不多有5个安装好的
- 输入:
vi /etc/profile,环境配置
一下是总的一些配置,可以对照一下,配置完了不要忘记source /etc/profile
export JAVA_HOME=/opt/jdk8
export JRE_HOME=/opt/jdk8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
export HADOOP_HOME=/opt/hadoop
export HBASE_HOME=/opt/hbase
export HIVE_HOME=/opt/hive
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin
四、配置zookeeper
【注】我的zookeeper命名为zookpr
- 输入:
cd /zookpr/conf进入zookpr的conf目录下 - 输入:
mv zoo_sample.cfg zoo.cfg,修改一下名字变为zoo.cfg - 输入:
vi zoo.cfg,作以下的修改
maxClientCnxns=0
initLimit=50
dataDir=/opt/hadoop/zookprdata
server.1=hadoop111:2888:3888
server.2=hadoop112:2888:3888
server.3=hadoop113:2888:3888

4. 把zoo.cfg复制到hadoop112和hadoop113上,输入:
scp zoo.cfg root@hadoop112:/opt/zookpr/conf/
scp zoo.cfg root@hadoop113:/opt/zookpr/conf/

5. 在/opt/hadoop的目录下创建zookprdata目录,输入:mkdir /opt/hadoop/zookprdata
6. 再在zookprdata目录下创建myid的文件,输入如:vi /opt/hadoop/zookprdata/myid,里面的内容是该节点对应的server号,如hadoop111对应的myid文件内容就是:1

每个主机都要这样配置,myid写入想要的server号。
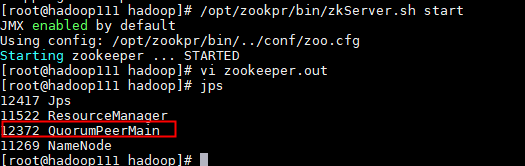
7. 启动zookpr,输入:/opt/zookpr/bin/zkServer.sh start
8. 查看zookeeper的日志文件查看,输入:tail -200f /opt/hadoop/zookeeper.out
如果日志不报错,并且启动成功,说明zookeeper启动成功
五、配置Hbase
安装Hbase需要先安装并配置好好hadoop和ZooKeeper。
Hbase的复制解压部分已经完成安装。这部分介绍Hbase的配置。
- 输入:
cd /opt/hbase/conf,进入conf目录下 - 输入:
vi hbase-env.sh,在末尾配置
export HBASE_OFFHEAPSIZE=1G
export HBASE_HEAPSIZE=4000
export JAVA_HOME=/opt/jdk8
export HBASE_OPTS="-Xmx4g -Xms4g -Xmn128m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC-XX:CMSInitiatingOccupancyFraction=70 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:$HBASE_HOME/logs/gc-$(hostname)-hbase.log"
export HBASE_MANAGES_ZK=false
【注】要把配置中的HBASE_OPTS注掉,因为我们重新配置了

配置完保存并退出
3. 输入:hbase-site.xml,配置如下,有两处要根据自己配置的主机名修改
<configuration>
<property>
<!--这里要根据自己设置的主机名修改,我的是hadoop111-->
<name>hbase.rootdir</name>
<value>hdfs://hadoop111:9000/hbase</value>
<description>Thedirectory shared by region servers.</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<!--配置集群-->
<name>hbase.zookeeper.quorum</name>
<value>hadoop111,hadoop112,hadoop113</value>
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>300</value>
</property>
<property>
<name>hbase.hstore.blockingStoreFiles</name>
<value>70</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>60000</value>
</property>
<property>
<name>hbase.regionserver.restart.on.zk.expire</name>
<value>true</value>
<description>
Zookeeper session expired will forceregionserver exit.
Enable this will make theregionserver restart.
</description>
</property>
<property>
<name>hbase.replication</name>
<value>false</value>
</property>
<property>
<name>hfile.block.cache.size</name>
<value>0.4</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.upperLimit</name>
<value>0.35</value>
</property>
<property>
<name>hbase.hregion.memstore.block.multiplier</name>
<value>8</value>
</property>
<property>
<name>hbase.server.thread.wakefrequency</name>
<value>100</value>
</property>
<property>
<name>hbase.master.distributed.log.splitting</name>
<value>false</value>
</property>
<property>
<name>hbase.regionserver.hlog.splitlog.writer.threads</name>
<value>3</value>
</property>
<property>
<name>hbase.hstore.blockingStoreFiles</name>
<value>20</value>
</property>
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
<property>
<name>hbase.hregion.memstore.mslab.enabled</name>
<value>true</value>
</property>
</configuration>
- 输入:
vi log4j.properties,有两处需要把INFO改为WARN
#第18行
hbase.root.logger=WARN,console
#第94行
log4j.logger.org.apache.hadoop.hbase=WARN
- 输入:
vi regionservers,把第一行删掉,把创建的主机名写进去
hadoop111
hadoop112
hadoop113
- 把配置好的文件复制给hadoop112和Hadoop113
scp hbase-env.sh root@hadoop112:/opt/hbase/conf
scp hbase-env.sh root@hadoop113:/opt/hbase/conf
scp hbase-site.xml root@hadoop112:/opt/hbase/conf
scp hbase-site.xml root@hadoop113:/opt/hbase/conf
scp log4j.properties root@hadoop113:/opt/hbase/conf
scp log4j.properties root@hadoop112:/opt/hbase/conf
scp regionservers root@hadoop112:/opt/hbase/conf
scp regionservers root@hadoop113:/opt/hbase/conf - 启动hbase,输入:
/opt/hbase/bin/start-hbase.sh - 测试hbse是否启动成功,输入:
hbase shell,如果如下图输入list后测试不报错,说明hbase安装成功

注意!!!如果是hbase是分布式配置,那么一定要把集群中的zookeeper都启动,否侧会报错
六、配置Hive
安装Hive需要先安装Mysql,我这已经安装好了Mysql数据库。
大家有兴趣的话可以查看我之前的博客,有用Mysql安装包安装的和用docker安装数据库,供大家参考。
Linux系统中安装Mysql
使用Docker安装Mysql数据库,及国内常用docker镜像地址
Hive的复制解压部分已经完成安装。这部分介绍Hive的配置。
- 通过docker容器启动msyql,输入:
docker start msyql-test - 进入msyql容器,输入:
docker exec -it mysql-test /bin/bash,后台启动mysql - 进入myslq容器后,输入:
mysql -uroot -p123456,进入mysql,如果密码修改过,就使用修改过的密码 - 创建一个普通用户用户
首先输入:use mysql
再输入:create user 'bigdata'@'hadoop111' identified by 'ok'; - 赋权,分别给普通用户和root赋权
普通用户:grant all privileges on *.* to 'bigdata'@'hadoop111';
root:grant all privileges on *.* to 'root'@'127.0.0.1'; - 创建一个数据库,输入:
create database hive_metadata; - 刷新权限,输入:
flush privileges; - 退出数据库,输入:
quit - 退出mysql容器,输入:
exit

数据库配置好了之后就可以配置Hive了 - 输入:
cd /opt/hive/conf,进入hive的conf目录下 - 输入:
cp hive-env.sh.template hive-env.sh复制一个hive-env.sh - 输入:
vi hive-env.sh,配置如下信息
export HADOOP_HOME=/opt/hadoop
export HIVE_CONF_DIR=/opt/hive/conf
export HIVE_AUX_JARS_PATH=/opt/hive/lib
export JAVA_HOME=/opt/jdk8

13. 输入:vi hive-site.xml,我发现没有hive-site.xml这个配置文件,所以我直接创建一个
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/opt/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<!-- 如果是远程mysql数据库的话需要在这里写入远程的IP或hosts -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<!--需要填本地地址127.0.0.1-->
<value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- 我root用户的密码为123456,如果你改了密码需要输入你自己修改的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--后面三条配置,为了后面连java-->
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>
<property>
<name>hive.server2.thrift.client.user</name>
<value>root</value>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>root</value>
</property>
</configuration>
- 把
mysql-connector-java-5.1.38-bin.jar包拖入到/opt/hive/lib目录下 - 创建hdfs文件夹,输入:
hadoop fs -mkdir -p /opt/hive/warehouse,与之前的对应
- 给创建的文件夹赋权,输入:
hadoop fs -chmod -p 777 /opt/hive/warehouse-p:表示递归创建
hadoop fs -chmod -R 777 /opt/hive/warehouse-R:表示以递回的方式逐个变更 - 初始化hive,输入:
schematool -dbType mysql -initSchema,效果图如下:

- 后台启动元数据服务,输入:
nohup hive --service metastore &,记得多按一次回车 - 后台启动beeline,输入:
nohup hive --service hiveserver2 &
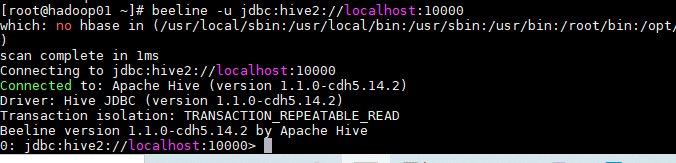
可用两种方式运行hive,一种是直接hive,第二种使用beeline启动 - beeline启动,输入:
beeline -u jdbc:hive2://localhost:10000,这种启动可以看见表格边框,但是创建的数据表文件的拥有者是anonymous,root用户不能对表内信息做修改,但能查询
- 启动hive,输入:
hive,启动成功效果图如下:

- 测试hive
创建表:create table aaa(name varchar(20));
添加数据:insert into aaa values ('hhhhhhhhh');
查询:select * from aaa;

- 退出hive,输入:
quit; - 登录
192.168.87.111:50070查看,发现数据表创建记录再/opt/hive/warehouse目录下

七、Hadoop启动顺序
以安装好所有环境
- 启动HDFS,只要主节点启动,输入:
start-all.sh
同时可访问HDFS监控页面:http://192.168.87.111:50070 查看各节点状况。 - 启动zookeeper,所有节点都要启动一般三个,输入:
/etc/zookpr/bin/zkServer.sh start - 启动Hbase,主节点启动,输入:
vi /opt/hbase/bin/start-hbase.sh - 启动docker容器,输入:
docker start mysql-test - 启动Hive,输入:
hive
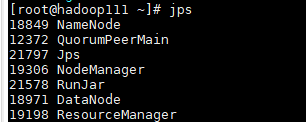
可以在各个节点用jps命令查看
- 主节点的
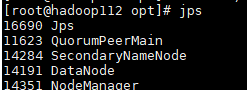
- 是Secondary的备用节点
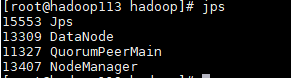
- 不是Secondary的备用节点
八、Hadoop关闭顺序
- 关闭Hive,在hive界面输出:
quit;退出hive - 关闭Hbase,输入:
/opt/hbase/bin/stop-hbase.sh - 关闭zookeeper,在各zookeeper节点上运行:
/opt/zookpr/bin/zkServer.sh stop - 关闭HDFS,输入:
stop-all.sh















 6031
6031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









