







 超级会员免费看
超级会员免费看

3.方法
其基本目标是在生产系统和并行计算优化中提高神经网络的运行速度,而不是低计算量理论指标(BFLOP)。我们提出了实时神经网络的两种选择:
对于GPU,我们在卷积层中使用少量的组(1 - 8):CSPResNeXt50 / CSPDarknet53
对于VPU -我们使用群卷积,但我们不使用挤压和兴奋(SE)块-具体来说,这包括以下模型:EfficientNet-lite / MixNet [76] / GhostNet [21] / MobileNetV3

3.1架构选择
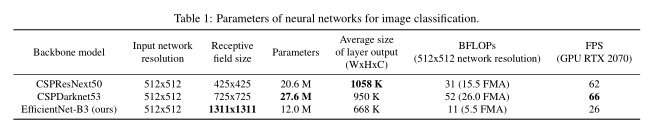
我们的目标是在输入网络分辨率、卷积层数、参数数(filter size2* filters * channel / groups)和层输出数(filters)之间找到最优平衡。例如,我们的大量研究表明,在ILSVRC2012 (ImageNet)数据集

 订阅专栏 解锁全文
订阅专栏 解锁全文

















04-19
 1万+
1万+
1万+
06-26
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











